本文盡量避免數學公式,使用文字解釋列生成演算法的原理,爭取讓讀者能形成直觀上的理解,
為什么需要了解列生成演算法的原理
- 列生成演算法無法簡單地呼叫第三方庫來使用,必須根據具體問題,構造不同的演算法模型,
- 只有了解了原理,才能在踩到各種坑時,有所針對地去優化各種細節,不然只能抓瞎或者抓腮,
列生成演算法原理
列生成演算法可以從兩個視角來理解:對偶角度和單純形演算法角度,
對偶角度
啥是對偶
這里簡單過一下對偶的概念,
假設有個長得很標準的線性規劃問題:
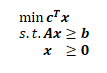
那么,它的對偶問題為:
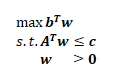
下面我們都以這個問題來討論,即說到原問題時,默認是一個最小化問題;說到對偶問題時,默認是一個最大化問題,
怎么理解這個對偶關系呢?借用經濟學方面的話來說,假設原問題的目標是讓成本最小,那么對偶就是讓收入最大,更確切地講,是:
- 原問題丶:保證收入不低于某個值的條件下,使成本最小化,
- 對偶問題:保證成本不高于某個值的條件下,使收入最大化,
那個丶純粹是為了對齊,忽略之……
可以看到,原問題和對偶問題其實就是一個問題:目標凈收益最大,只是一個是約束收入優化成本,一個是約束成本優化收入,角度不同而已,體現在公式上,就是原問題的變數對應對偶問題的約束,目標系數對應約束邊界,約束矩陣倒轉過來,
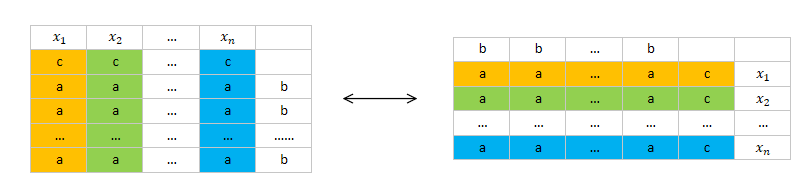
另外,關于對偶,一個比較重要的特性是:原問題的最優值與對偶問題的最優值相等,
從對偶角度看列生成演算法
列生成演算法主要用途在于求解變數多,但是大部分變數將會取值為0的線性規劃問題,總體思路是先忽略大部分變數,構造一個只使用小部分變數的模型(其余變數相當于值為0),這樣就能很快求出一個解,然后尋找模型外的變數,找到能夠讓目標值更優的變數,加入模型再次求解,重復這個程序直至找不到更好的變數,
這個程序的關鍵問題在于,怎么評估模型外的變數是否能讓目標值更優,
我們從對偶的角度來研究這個問題,
原問題的變數對應對偶問題的約束,所以原問題新增變數,相當于對偶問題新增約束,
原問題新增變數 -> 對偶問題新增約束
由于對偶問題是個最大化問題,所以對偶問題新增約束后,顯然最優值不變或變差,也就是不變或變小,從常理上看,約束越多,最優值越差嘛,
而前面提到的,原問題的最優值等于對偶問題的最優值,也就是說,如果對偶問題最優值不變,那么原問題最優值也不變;如果對偶問題最優值變小,那么原問題最優值也變小,而我們需要的正是讓原問題的最優值變小,
所以問題變為如何盡量避免新增的約束沒有改變最優值,設想一下,當加入新約束時,如果當前對偶的最優解沒有違反新的約束,那么這個解仍然會是新增約束后的對偶問題的最優解,最優值將不變,
因此,我們要找的新增的約束,要和當前最優解沖突,
整條邏輯鏈為:
新增變數后原問題最優解變小 -> 新增約束后對偶問題最優解變小 -> 新增約束前的最優解不在新增約束后的可行域 -> 新增約束前的最優解不滿足新增的約束
一行對偶問題的約束的公式為:
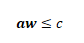
假設最優解為w*,那么違反約束的條件為:
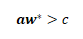
變換一下,變成:
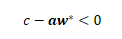
左側的式子,叫做的reduced cost,也叫做檢驗數,
通過分析,我們知道,只要加入reduced cost小于0的對偶約束(從而加入了原問題對應的變數)即可,
很自然的想法是,我們更傾向于找到reduced cost最小的一個或幾個變數加入,也就是最好能找到最小化reduced cost的新約束:
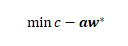
這里就出現了一個新的最優化問題,這個問題叫做列生成的子問題(sub problem),其中w*是已知的,未知量是c和a,c和a是和問題的應用場景有關的,需要根據實際場景來構造c和a的約束條件,所以子問題無法通用地求解,只能根據具體問題選擇不同的方法求解,
當所有未加入模型的變數的reduced cost都大于等于0時,目標值無法再優化,說明我們已得到最優解,
另外,熟悉對偶問題經濟學含義的同學會知道,reduced cost是指產品的差額成本,那么顯然要新增的是差額成本為負的產品了,這是另一種理解列生成的思路,
單純形演算法角度
對偶角度給出了一個偏感性的方式來理解列生成演算法,換個視角,從單純形演算法角度上看,則是單純形演算法本身,為了更高效地求解包含大量變數的問題,自然地擴展為列生成演算法,
相信有不少人被單純形演算法虐得有心理陰影——公式復雜,手工計算量也巨大……
其實,如果我們先不看細節,單純形的核心原理并沒有那么難以理解,下面講解時不會很嚴謹,理解演算法框架就夠了,嚴謹的程序請參閱運籌學相關書籍,
單純形演算法
眾所周知,單純形演算法有一個幾何上的解釋:
- 線性規劃是一個凸優化問題,區域最優解就是全域最優解,
- 線性規劃的解空間是一個n維的凸多面體,最優解在這個凸多面體的某個頂點上,
- 單純形演算法從一個初始頂點開始,不斷沿著鄰邊找更好的頂點,
- 當一個頂點四周沒有更好的頂點時,這個頂點就是最優解,
整個程序就像水沿著一條蜿蜒的溝渠流下,最侄訓聚到最低點一樣,
問題是,這里面的幾何概念和代數公式怎么對應?
這里用不嚴謹(但更容易理解)的語言說明一下:
- 邊界:解空間是由不等式約束(包括變數非負這些約束)圍起來的一塊空間區域,當點p使得若干個不等式取等號時,那么點p就在約束邊界的超平面上,這個邊界可能是一個面、邊、頂點,
- 頂點:頂點會讓盡量多的約束取等號,也就是說,頂點是由若干個改為等號的約束組成的方程組的解,我們叫這個方程組為約束邊界方程組,
- 沿著邊:約束邊界方程組去掉一個方程,其解集就變成與頂點鄰接的一條邊,再取一條原方程組外的約束條件加入,所得到的解就是相鄰的頂點,簡單說,就是約束邊界方程組中替換掉一個方程,形成的新方程組解出來就是相鄰的頂點,
這里涉及到通過讓約束取等號來求邊界的操作,而不等式亂糟糟地混在方程型的約束和變數非負約束里,會使這里的分析比較困難,所以使用單純形演算法之前,都會通過引入松弛變數、剩余變數和人工變數等方法(這一步在這里不重要,不詳細展開了),將線性規劃轉換成如下標準形式:
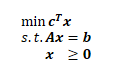
標準形式中只有變數非負約束包含不等式,其他約束都是等式,這樣我們就可以很容易地做邊界相關的計算了,假設變數數量為n,等式約束數量為m,通過轉換而來的標準形式都會有n > m,那么,我們知道,只要讓n-m個變數等于0,剩下的m個變數就可以通過這m個等式聯立方程組(約束邊界方程組)求出一個解(簡單起見,不考慮無解,無數解這些邊緣條件),這個解就是一個頂點,
這里約束邊界方程組中的m個變數叫作基變數,固定值為0的n-m個變數叫作非基變數,
沿著邊找相鄰頂點,就是取一個被固定為0的非負約束,也就是一個非基變數(這個操作叫入基),替換掉一個基變數(這個操作叫出基,這個變數出基后就固定值為0),然后重新求解一個頂點,
入基操作需要選擇入基變數,選擇的依據是這個變數在目標函式中的下降速度,也就是這個變數增加1時,目標值減少多少,經過推導可知,下降速度的計算公式剛好是檢驗數(reduced cost),這里就和對偶的視角聯系起來了,
出基操作這里就不細說了,大致的思路是在約束條件下,舊的基變數有一部分會隨著入基變數的增長而下降,其中最先下降到0的舊的基變數就會被選為出基變數,
整個單純形演算法的計算步驟是:
- 選取基變數和非基變數,簡單能出初始解就好,
- 計算所有非基變數的reduced cost,找到最小且為負值的那個作為入基變數,如果reduced cost都大于等于0,迭代終止,
- 選出基變數
- 解約束邊界方程組,回到步驟2
從單純形演算法角度看列生成演算法
在單純形的步驟2,需要計算所有非基變數的RC,找到最小的那個,當變數個數很多的時候,這一步就成為了演算法運行時間瓶頸,
在一些情況下,通過巧妙構造問題,可以讓這一步不需要遍歷所有變數,甚至我們都不需要知道有多少變數,只要能在每次迭代的時候生成一個或者多個變數,提升優化效果就可以了,
由于不需要遍歷所有變數,所以一開始就不需要使用所有變數,只需要使用一組能產生初始解的初始變數構成線性優化問題即可,這種只使用部分變數的模型被稱為原問題的restricted master problem(RMP),
每次迭代時,生成一個或多個讓reduced cost最小的變數加入RMP,這個生成步驟就是求解子問題,不斷加入新變數直到沒有小于0的reduced cost的變數時就達到最優解,
到這里就和對偶角度分析的結果一致了,
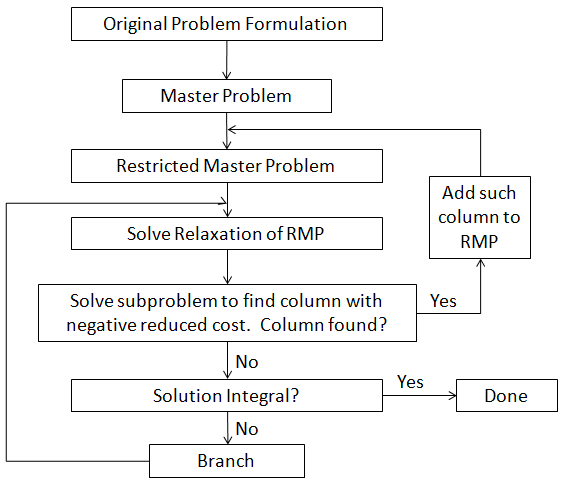
下面是單純形演算法與列生成演算法簡要流程圖的對比,可以看到,兩者的結構是一樣的,
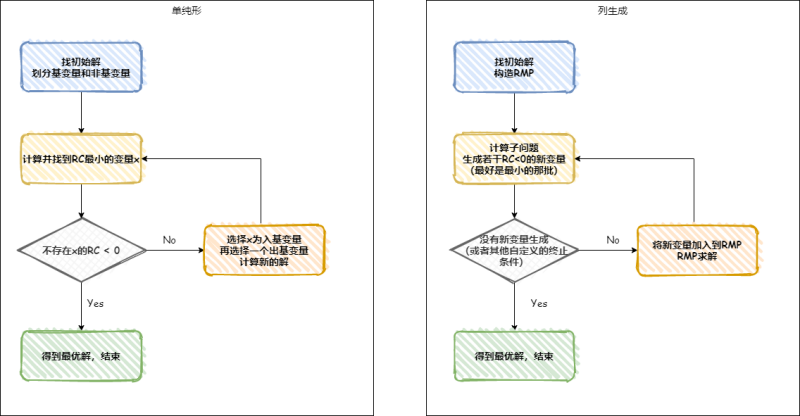
一般來說,我們不會手搓單純形演算法,所以正常都是直接呼叫單純形演算法庫解RMP,然后做列生成,再跑RMP,直到達到最優,
一個經典例子:Cutting Stock Problem
這是一個列生成演算法的經典例子,

原紙卷每個長17m,顧客們分別需要25個3m長,20個5m長,18個7m長的紙卷,
問:如何切割使消耗的原紙卷數量最少?
令一個原紙卷的切割方案集合為:
P = {(a, b, c) | 3a + 5b + 7c <= 17}
其中,a是一個原紙卷切割出的3m紙卷數量,b是5m紙卷數量,c是7m紙卷數量,
我們用變數x(abc)表示使用切割方案(a, b, c)的原紙卷數量,
顯然,一個變數與一個原紙卷切割方案一一對應,建模如下:
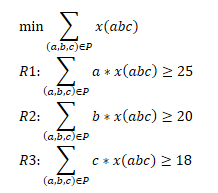
這里故意不適用傳統的下標序號標記,意在突出我們不需要對變數編號,只需要知道變數在對應在什么集合上,如何通過集合中的元素生成變數就行了,
初始解很好找,比如說我們可以取25個原紙卷按照方案(1, 0, 0)切割,20個原紙卷按照方案(0, 1, 0)切割,18個原紙卷按照方案(0, 0, 1)切割,這當然會有很多浪費,但是初始解可行就可以了,浪費的部分會在下面的迭代中優化掉,
接下來要生成變數,變數與切割方案一一對應的,所以是要找出一個切割方案(a, b, c),使得reduced cost最小,
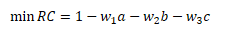
其中w1、w2和w3分別為約束R1、R2和R3的對偶值,
約束條件除了a、b、c非負外,還需要滿足切割后的紙卷長度綜合小于或者等于原紙卷的長度,
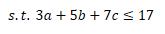
這樣子問題就構造好了,求解子問題得到新增變數,然后迭代直到最優,具體計算這里不展開了,
整數規劃求解
前面提到的單純形演算法和列生成演算法求解的都是線性規劃,在實際應用中,一般還會需要求解整數規劃,也就是變數都約束為整數的線性規劃,
這里先提一個概念:整數規劃的線性松弛,整數規劃問題,不考慮整數約束,剩下的約束條件和目標組成的線性規劃問題,
其實我們并沒有很好的方法直接求解整數規劃,通常都是不斷地調整并求解線性松弛,最后找到最優整數解,
分支定界
分支定界是一個用來求整數優化問題的框架,其實思路很簡單,就是采用類似二分法的技巧,在線性解空間中暴力搜索整數解,
首先,求解線性松弛得到線性解,取一個變數x進行分支,比如x線性解值為1.2,那么產生 x <= 1 和 x >= 2 兩個分支,將這兩個條件分別加入到線性松弛,得到兩個線性規劃,再求解這兩個線性規劃,兩個又分別分支……直到求得最優解,
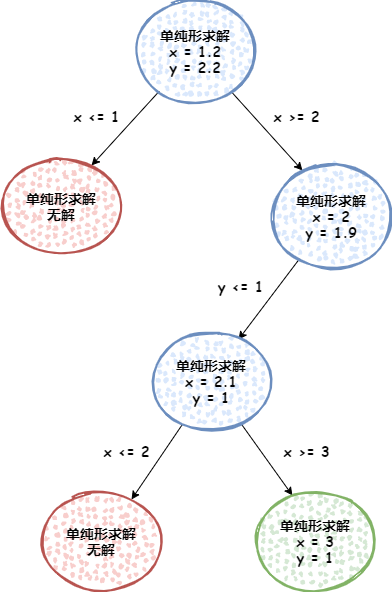
有些情況下判斷一個解是否為最優解是有方法的,所以不用搜索所有分支,但是,分支定界在最壞情況下的時間復雜度仍是指數級,為了防止運行時間過長,一般使用分支定界時還會額外加一些終止條件,比如回溯次數限制、運行時間限制、找到第一個整數解就結束等,
分支定價
分支定價就是在分支定界框架中,使用列生成演算法來求解每個分支節點的演算法,
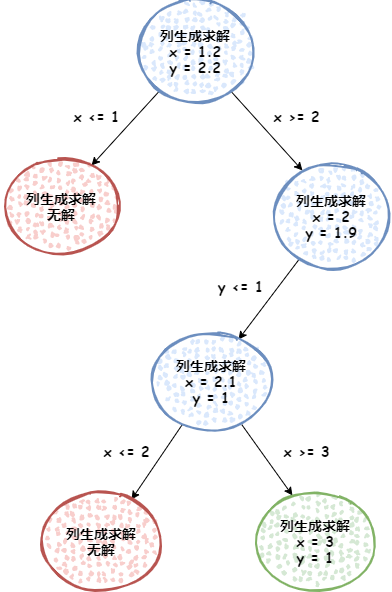
不過這里,除了根節點,其他節點不用從頭開始生成新變數,繼承父節點用到的變數即可,這樣可以節省很多重復生成變數的程序,
在01整數規劃中,還有更簡化的方法,每次列生成得到線性松弛的最優解后,找出值最接近1的變數,新加這些變數等于1的約束,繼續跑列生成,直到找出所以值為1的變數,剩下的自然都是0了,這個方法可以加入回溯,也可以不回溯,出現無解就直接結束……據說不回溯也很少出現無解的情況,
一些相關問題
退化問題/類退化問題
通過RC找的新變數不一定能讓目標值變得更好,仍然存在不變的可能,極小概率的情況下,單純形演算法可能會有入基變數和出基變數回圈出現的情況,由于我們肯定是呼叫線性規劃庫來跑單純形的,所以不用考慮這個……
列生成沒有出基操作,不會出現回圈,但是有一些改進會剔除冗余變數,這時就會有極小概率會出現回圈了,這種情況不需要費心去處理,玄學調參降低出現概率,并設定最大迭代次數等強制終止條件,確保能終止就好,
最惡心的情況是沒有回圈,但是長時間沒有提升目標值的情況,這其實是演算法卡在一個拐點上了,只要過了拐點就能開始提升,特別是在一些約束較強的問題(比如密集的排班問題)中,使用某些啟發式演算法或者手工做出來的初始解就很容易出現這種情況,
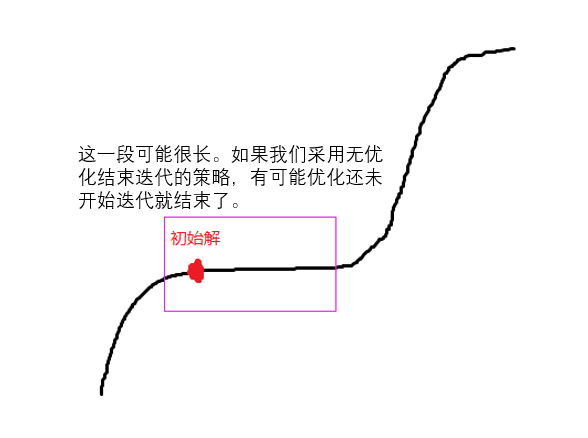
而我們為了避免演算法跑太久,通常會設定多次迭代沒有提升就結束的條件,這可能使演算法從拐點出發后,幾次迭代無優化就直接結束了,
這種情況無法完美解決,簡單的就是調參加更巧妙地設定結束條件,通過多次試驗盡量讓演算法能跨過這個拐點,還有另一個技巧是可以適當地給約束邊界加一下噪音,比如說小于等于1的約束,可以放寬到小于等于1.0001,這樣從初始解出發迭代時,由于邊界寬松了一些,變數可以有些許變化,會讓目標值有一些微小的提升,幫助判斷是否需要結束迭代,
CPLEX計算reduced cost的問題
使用CPLEX時,我們可以很方便的設定變數的上下界,比如設定 0 <= x <= 1,這時,x <= 1這部分是會影響reduced cost的值的,而CPLEX介面計算的是沒有考慮這個條件的……所以可能你自己手搓代碼出來reduced cost和CPLEX介面出來的reduced cost不相等,
更嚴重的是,可能你會忘了 x <= 1 這個條件,導致列生成的程序中算錯reduced cost,
這個問題其實影響不大,主要是會干擾一些計算程序正確性的驗算,
如何驗證子問題有沒有嚴重問題
沒有做分支操作時,線性松弛的目標值如果變差,說明子問題可能出現了一些很蠢的問題,
線性規劃求解演算法選擇
每次迭代求解線性規劃時,選用不同的演算法會影響求解時間,根據經驗:
- 增加少量列時(列生成),使用單純形演算法(Primal),
- 增加少量約束時(分支),使用對偶單純形演算法(Dual),
- 其他情況,酌情使用對偶單純形演算法或者內點法,通過試驗決定,
- 對偶單純形演算法快的時候很快,慢的時候很慢,
- 內點法速度比較穩定,
以上也并不是所有場景通用的,應當針對具體問題,反復試驗來確定使用什么演算法,
迭代中剔除冗余變數
Reduced cost可以用來評估變數的“有用”程度,越小表示變數越有用,越大表示變數越無關緊要,
列生成迭代次數較多后,變數數量會越來越多,從而每次迭代的運行速度越來越低,可以設定一個變數規模上限,當變數數量大于上限時,從模型中去掉reduced cost最大的那些變數,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6724.html
標籤:其他