本文主要詳細講述常見的八種排序演算法的思想、實作以及復雜度,
冒泡排序
要點
冒泡排序是一種交換排序,
什么是交換排序呢?
交換排序:兩兩比較待排序的關鍵字,并交換不滿足次序要求的那對數,直到整個表都滿足次序要求為止,
演算法思想
它重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來,走訪數列的作業是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成,
這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端,故名,
假設有一個大小為 N 的無序序列,冒泡排序就是要每趟排序程序中通過兩兩比較,找到第 i 個小(大)的元素,將其往上排,
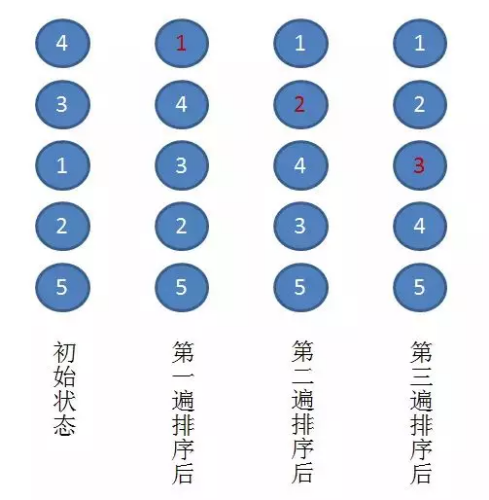
以上圖為例,演示一下冒泡排序的實際流程:
假設有一個無序序列 { 4. 3. 1. 2, 5 }
第一趟排序:通過兩兩比較,找到第一小的數值 1 ,將其放在序列的第一位,
第二趟排序:通過兩兩比較,找到第二小的數值 2 ,將其放在序列的第二位,
第三趟排序:通過兩兩比較,找到第三小的數值 3 ,將其放在序列的第三位,
至此,所有元素已經有序,排序結束,
要將以上流程轉化為代碼,我們需要像機器一樣去思考,不然編譯器可看不懂,
假設要對一個大小為 N 的無序序列進行升序排序(即從小到大),
每趟排序程序中需要通過比較找到第 i 個小的元素,
所以,我們需要一個外部回圈,從陣列首端(下標 0) 開始,一直掃描到倒數第二個元素(即下標 N - 2) ,剩下最后一個元素,必然為最大,
假設是第 i 趟排序,可知,前 i-1 個元素已經有序,現在要找第 i 個元素,只需從陣列末端開始,掃描到第 i 個元素,將它們兩兩比較即可,
所以,需要一個內部回圈,從陣列末端開始(下標 N - 1),掃描到 (下標 i + 1),
1 public void bubbleSort(int[] list) { 2 int temp = 0; // 用來交換的臨時數 3 4 // 要遍歷的次數 5 for (int i = 0; i < list.length - 1; i++) { 6 // 從后向前依次的比較相鄰兩個數的大小,遍歷一次后,把陣列中第i小的數放在第i個位置上 7 for (int j = list.length - 1; j > i; j--) { 8 // 比較相鄰的元素,如果前面的數大于后面的數,則交換 9 if (list[j - 1] > list[j]) { 10 temp = list[j - 1]; 11 list[j - 1] = list[j]; 12 list[j] = temp; 13 } 14 } 15 16 System.out.format("第 %d 趟:\t", i); 17 printAll(list); 18 } 19 }
演算法分析
冒泡排序演算法的性能
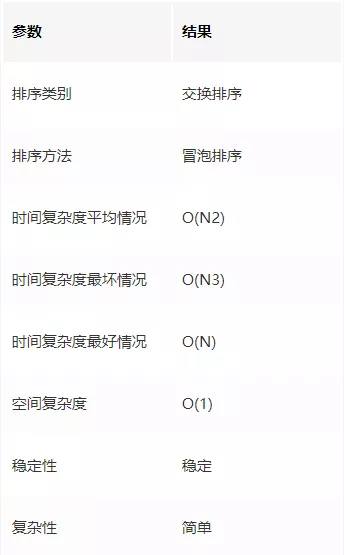
時間復雜度
若檔案的初始狀態是正序的,一趟掃描即可完成排序,所需的關鍵字比較次數 C 和記錄移動次數 M 均達到最小值:Cmin = N - 1, Mmin = 0,所以,冒泡排序最好時間復雜度為 O(N),
若初始檔案是反序的,需要進行 N -1 趟排序,每趟排序要進行 N - i 次關鍵字的比較(1 ≤ i ≤ N - 1),且每次比較都必須移動記錄三次來達到交換記錄位置,在這種情況下,比較和移動次數均達到最大值:
Cmax = N(N-1)/2 = O(N2)
Mmax = 3N(N-1)/2 = O(N2)
冒泡排序的最壞時間復雜度為 O(N2),因此,冒泡排序的平均時間復雜度為 O(N2),
總結起來,其實就是一句話:當資料越接近正序時,冒泡排序性能越好,
演算法穩定性
冒泡排序就是把小的元素往前調或者把大的元素往后調,比較是相鄰的兩個元素比較,交換也發生在這兩個元素之間,
所以相同元素的前后順序并沒有改變,所以冒泡排序是一種穩定排序演算法,
優化
對冒泡排序常見的改進方法是加入標志性變數 exchange,用于標志某一趟排序程序中是否有資料交換,
如果進行某一趟排序時并沒有進行資料交換,則說明所有資料已經有序,可立即結束排序,避免不必要的比較程序,
核心代碼
1 // 對 bubbleSort 的優化演算法 2 public void bubbleSort_2(int[] list) { 3 int temp = 0; // 用來交換的臨時數 4 boolean bChange = false; // 交換標志 5 6 // 要遍歷的次數 7 for (int i = 0; i < list.length - 1; i++) { 8 bChange = false; 9 // 從后向前依次的比較相鄰兩個數的大小,遍歷一次后,把陣列中第i小的數放在第i個位置上 10 for (int j = list.length - 1; j > i; j--) { 11 // 比較相鄰的元素,如果前面的數大于后面的數,則交換 12 if (list[j - 1] > list[j]) { 13 temp = list[j - 1]; 14 list[j - 1] = list[j]; 15 list[j] = temp; 16 bChange = true; 17 } 18 } 19 20 // 如果標志為false,說明本輪遍歷沒有交換,已經是有序數列,可以結束排序 21 if (false == bChange) 22 break; 23 24 System.out.format("第 %d 趟:\t", i); 25 printAll(list); 26 } 27 }
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
快速排序
要點
快速排序是一種交換排序,
快速排序由 C. A. R. Hoare 在 1962 年提出,
演算法思想
它的基本思想是:
通過一趟排序將要排序的資料分割成獨立的兩部分:分割點左邊都是比它小的數,右邊都是比它大的數,
然后再按此方法對這兩部分資料分別進行快速排序,整個排序程序可以遞回進行,以此達到整個資料變成有序序列,
詳細的圖解往往比大堆的文字更有說明力,所以直接上圖:
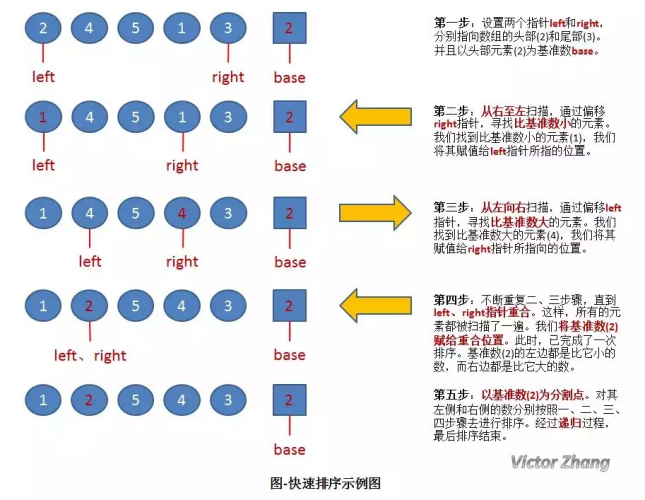
上圖中,演示了快速排序的處理程序:
-
初始狀態為一組無序的陣列:2、4、5、1、3,
經過以上操作步驟后,完成了第一次的排序,得到新的陣列:1、2、5、4、3,
-
-
新的陣列中,以 2 為分割點,左邊都是比 2 小的數,右邊都是比 2 大的數,
-
-
因為 2 已經在陣列中找到了合適的位置,所以不用再動,
-
2 左邊的陣列只有一個元素 1,所以顯然不用再排序,位置也被確定,(注:這種情況時,left 指標和 right 指標顯然是重合的,因此在代碼中,我們可以通過設定判定條件 left 必須小于 right,如果不滿足,則不用排序了),
-
而對于 2 右邊的陣列 5、4、3,設定 left 指向 5,right 指向 3,開始繼續重復圖中的一、二、三、四步驟,對新的陣列進行排序,
核心代碼
1 public int division(int[] list, int left, int right) { 2 // 以最左邊的數(left)為基準 3 int base = list[left]; 4 while (left < right) { 5 // 從序列右端開始,向左遍歷,直到找到小于base的數 6 while (left < right && list[right] >= base) 7 right--; 8 // 找到了比base小的元素,將這個元素放到最左邊的位置 9 list[left] = list[right]; 10 11 // 從序列左端開始,向右遍歷,直到找到大于base的數 12 while (left < right && list[left] <= base) 13 left++; 14 // 找到了比base大的元素,將這個元素放到最右邊的位置 15 list[right] = list[left]; 16 } 17 18 // 最后將base放到left位置,此時,left位置的左側數值應該都比left小; 19 // 而left位置的右側數值應該都比left大, 20 list[left] = base; 21 return left; 22 } 23 24 private void quickSort(int[] list, int left, int right) { 25 26 // 左下標一定小于右下標,否則就越界了 27 if (left < right) { 28 // 對陣列進行分割,取出下次分割的基準標號 29 int base = division(list, left, right); 30 31 System.out.format("base = %d:\t", list[base]); 32 printPart(list, left, right); 33 34 // 對“基準標號“左側的一組數值進行遞回的切割,以至于將這些數值完整的排序 35 quickSort(list, left, base - 1); 36 37 // 對“基準標號“右側的一組數值進行遞回的切割,以至于將這些數值完整的排序 38 quickSort(list, base + 1, right); 39 } 40 }
演算法分析
快速排序演算法的性能
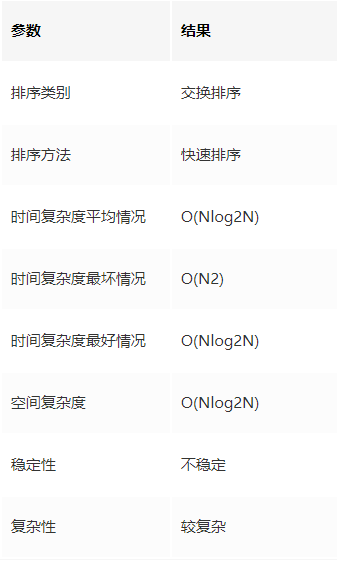
時間復雜度
當資料有序時,以第一個關鍵字為基準分為兩個子序列,前一個子序列為空,此時執行效率最差,
而當資料隨機分布時,以第一個關鍵字為基準分為兩個子序列,兩個子序列的元素個數接近相等,此時執行效率最好,
所以,資料越隨機分布時,快速排序性能越好;資料越接近有序,快速排序性能越差,
空間復雜度
快速排序在每次分割的程序中,需要 1 個空間存盤基準值,而快速排序的大概需要 Nlog2N 次的分割處理,所以占用空間也是 Nlog2N 個,
演算法穩定性
在快速排序中,相等元素可能會因為磁區而交換順序,所以它是不穩定的演算法,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
插入排序
要點
直接插入排序是一種最簡單的插入排序,
插入排序:每一趟將一個待排序的記錄,按照其關鍵字的大小插入到有序佇列的合適位置里,知道全部插入完成,
演算法思想
在講解直接插入排序之前,先讓我們腦補一下我們打牌的程序,

先拿一張 5 在手里,
再摸到一張 4,比 5 小,插到 5 前面,
摸到一張 6,嗯,比 5 大,插到 5 后面,
摸到一張 8,比 6 大,插到 6 后面,
,,,
最后一看,我靠,湊到的居然是同花順,這下牛逼大了,
以上的程序,其實就是典型的直接插入排序,每次將一個新資料插入到有序佇列中的合適位置里,
很簡單吧,接下來,我們要將這個演算法轉化為編程語言,
假設有一組無序序列 R0, R1, … , RN-1,
我們先將這個序列中下標為 0 的元素視為元素個數為 1 的有序序列,
然后,我們要依次把 R1, R2, … , RN-1 插入到這個有序序列中,所以,我們需要一個外部回圈,從下標 1 掃描到 N-1 ,
接下來描述插入程序,假設這是要將 Ri 插入到前面有序的序列中,由前面所述,我們可知,插入 Ri 時,前 i-1 個數肯定已經是有序了,
所以我們需要將 Ri 和 R0 ~ Ri-1 進行比較,確定要插入的合適位置,這就需要一個內部回圈,我們一般是從后往前比較,即從下標 i-1 開始向 0 進行掃描,(對于常見排序演算法更多學習,可以在Java知音公眾號回復“排序演算法聚合”)
核心代碼
1 public void insertSort(int[] list) { 2 // 列印第一個元素 3 System.out.format("i = %d:\t", 0); 4 printPart(list, 0, 0); 5 6 // 第1個數肯定是有序的,從第2個數開始遍歷,依次插入有序序列 7 for (int i = 1; i < list.length; i++) { 8 int j = 0; 9 int temp = list[i]; // 取出第i個數,和前i-1個數比較后,插入合適位置 10 11 // 因為前i-1個數都是從小到大的有序序列,所以只要當前比較的數(list[j])比temp大,就把這個數后移一位 12 for (j = i - 1; j >= 0 && temp < list[j]; j--) { 13 list[j + 1] = list[j]; 14 } 15 list[j + 1] = temp; 16 17 System.out.format("i = %d:\t", i); 18 printPart(list, 0, i); 19 } 20 }
演算法分析
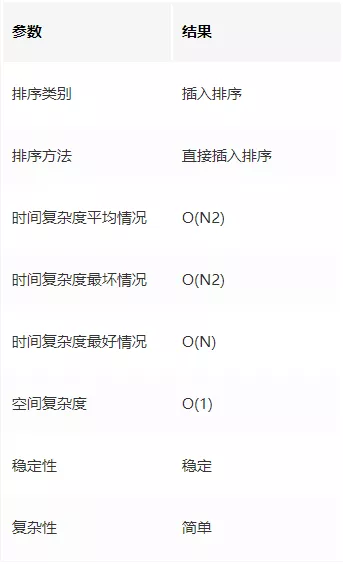
直接插入排序的演算法性能
時間復雜度
當資料正序時,執行效率最好,每次插入都不用移動前面的元素,時間復雜度為 O(N),
當資料反序時,執行效率最差,每次插入都要前面的元素后移,時間復雜度為 O(N2),
所以,資料越接近正序,直接插入排序的演算法性能越好,
空間復雜度
由直接插入排序演算法可知,我們在排序程序中,需要一個臨時變數存盤要插入的值,所以空間復雜度為 1 ,
演算法穩定性
直接插入排序的程序中,不需要改變相等數值元素的位置,所以它是穩定的演算法,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
希爾排序
要點
希爾(Shell)排序又稱為縮小增量排序,它是一種插入排序,它是直接插入排序演算法的一種威力加強版,
該方法因 DL.Shell 于 1959 年提出而得名,
演算法思想
希爾排序的基本思想是:
把記錄按步長 gap 分組,對每組記錄采用直接插入排序方法進行排序,
隨著步長逐漸減小,所分成的組包含的記錄越來越多,當步長的值減小到 1 時,整個資料合成為一組,構成一組有序記錄,則完成排序,
我們來通過演示圖,更深入的理解一下這個程序,
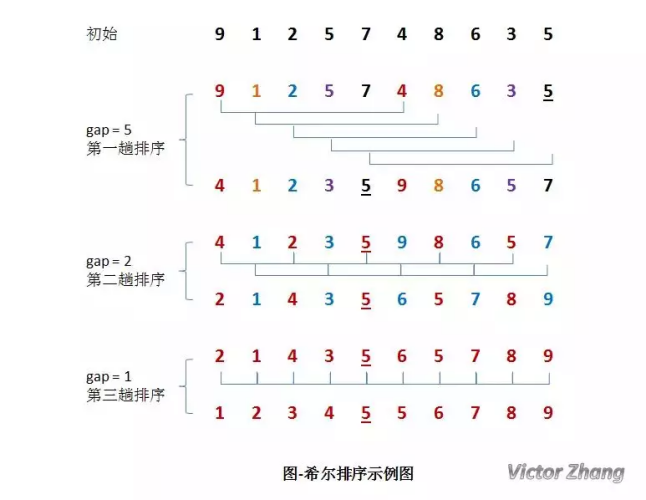
在上面這幅圖中:
初始時,有一個大小為 10 的無序序列,
在第一趟排序中,我們不妨設 gap1 = N / 2 = 5,即相隔距離為 5 的元素組成一組,可以分為 5 組,
接下來,按照直接插入排序的方法對每個組進行排序,
在** 第二趟排序中**,我們把上次的 gap 縮小一半,即 gap2 = gap1 / 2 = 2 (取整數),這樣每相隔距離為 2 的元素組成一組,可以分為 2 組,
按照直接插入排序的方法對每個組進行排序,
在第三趟排序中,再次把 gap 縮小一半,即 gap3 = gap2 / 2 = 1,這樣相隔距離為 1 的元素組成一組,即只有一組,
按照直接插入排序的方法對每個組進行排序,此時,排序已經結束,
需要注意一下的是,圖中有兩個相等數值的元素 5 和 5 ,我們可以清楚的看到,在排序程序中,兩個元素位置交換了,
所以,希爾排序是不穩定的演算法,
核心代碼
1 public void shellSort(int[] list) { 2 int gap = list.length / 2; 3 4 while (1 <= gap) { 5 // 把距離為 gap 的元素編為一個組,掃描所有組 6 for (int i = gap; i < list.length; i++) { 7 int j = 0; 8 int temp = list[i]; 9 10 // 對距離為 gap 的元素組進行排序 11 for (j = i - gap; j >= 0 && temp < list[j]; j = j - gap) { 12 list[j + gap] = list[j]; 13 } 14 list[j + gap] = temp; 15 } 16 17 System.out.format("gap = %d:\t", gap); 18 printAll(list); 19 gap = gap / 2; // 減小增量 20 } 21 }
演算法分析
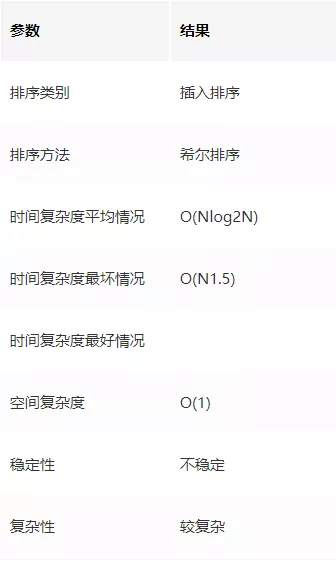
希爾排序的演算法性能
時間復雜度
步長的選擇是希爾排序的重要部分,只要最終步長為 1 任何步長序列都可以作業,
演算法最開始以一定的步長進行排序,然后會繼續以一定步長進行排序,最終演算法以步長為 1 進行排序,當步長為 1 時,演算法變為插入排序,這就保證了資料一定會被排序,
Donald Shell 最初建議步長選擇為 N/2 并且對步長取半直到步長達到 1,雖然這樣取可以比 O(N2)類的演算法(插入排序)更好,但這樣仍然有減少平均時間和最差時間的余地,可能希爾排序最重要的地方在于當用較小步長排序后,以前用的較大步長仍然是有序的,
比如,如果一個數列以步長 5 進行了排序然后再以步長 3 進行排序,那么該數列不僅是以步長 3 有序,而且是以步長 5 有序,如果不是這樣,那么演算法在迭代程序中會打亂以前的順序,那就不會以如此短的時間完成排序了,
已知的最好步長序列是由 Sedgewick 提出的(1, 5, 19, 41, 109,…),該序列的項來自這兩個算式,
這項研究也表明“比較在希爾排序中是最主要的操作,而不是交換,”用這樣步長序列的希爾排序比插入排序和堆排序都要快,甚至在小陣列中比快速排序還快,但是在涉及大量資料時希爾排序還是比快速排序慢,
演算法穩定性
由上文的希爾排序演算法演示圖即可知,希爾排序中相等資料可能會交換位置,所以希爾排序是不穩定的演算法,
直接插入排序和希爾排序的比較
直接插入排序是穩定的;而希爾排序是不穩定的,
直接插入排序更適合于原始記錄基本有序的集合,
希爾排序的比較次數和移動次數都要比直接插入排序少,當 N 越大時,效果越明顯,
在希爾排序中,增量序列 gap 的取法必須滿足:**最后一個步長必須是 1 ,**
直接插入排序也適用于鏈式存盤結構;希爾排序不適用于鏈式結構,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,(對于常見排序演算法更多學習,可以在Java知音公眾號回復“排序演算法聚合”)
簡單選擇排序
要點
簡單選擇排序是一種選擇排序,
選擇排序:每趟從待排序的記錄中選出關鍵字最小的記錄,順序放在已排序的記錄序列末尾,直到全部排序結束為止,
演算法思想
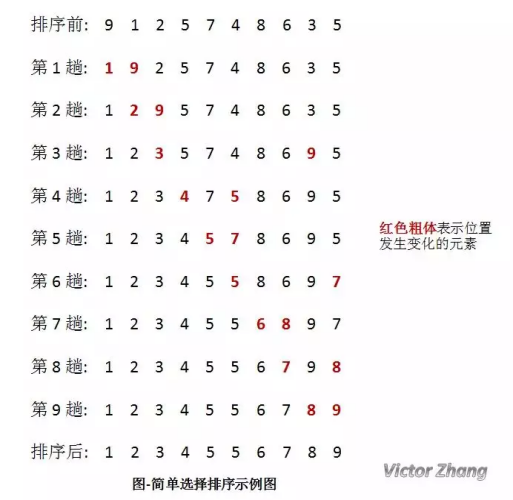
從待排序序列中,找到關鍵字最小的元素;
如果最小元素不是待排序序列的第一個元素,將其和第一個元素互換;
從余下的 N - 1 個元素中,找出關鍵字最小的元素,重復 1、2 步,直到排序結束,
如圖所示,每趟排序中,將當前**第 i 小的元素放在位置 i **上,
演算法分析
簡單選擇排序演算法的性能
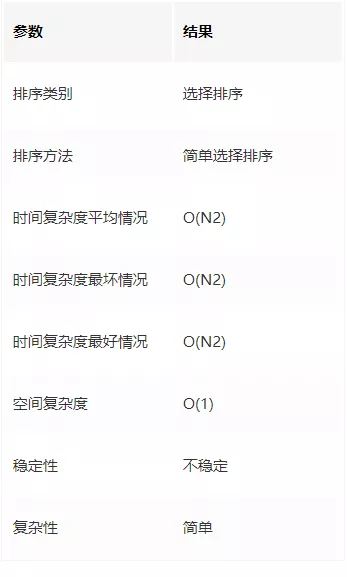
時間復雜度
簡單選擇排序的比較次數與序列的初始排序無關,假設待排序的序列有 N 個元素,則**比較次數總是 N (N - 1) / 2 **,
而移動次數與序列的初始排序有關,當序列正序時,移動次數最少,為 0,
當序列反序時,移動次數最多,為 3N (N - 1) / 2,
所以,綜合以上,簡單排序的時間復雜度為 O(N2),
空間復雜度
簡單選擇排序需要占用一個臨時空間,在交換數值時使用,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
堆排序
要點
在介紹堆排序之前,首先需要說明一下,堆是個什么玩意兒,
堆是一棵順序存盤的完全二叉樹,
其中每個結點的關鍵字都不大于其孩子結點的關鍵字,這樣的堆稱為小根堆,
其中每個結點的關鍵字都不小于其孩子結點的關鍵字,這樣的堆稱為大根堆,
舉例來說,對于 n 個元素的序列 {R0, R1, … , Rn} 當且僅當滿足下列關系之一時,稱之為堆:
Ri <= R2i+1 且 Ri <= R2i+2 (小根堆)
Ri >= R2i+1 且 Ri >= R2i+2 (大根堆)
其中 i=1,2,…,n/2 向下取整;
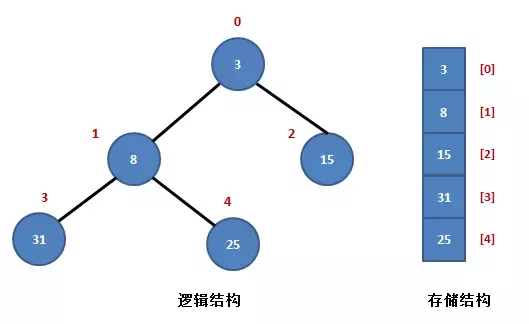
如上圖所示,序列 R{3, 8,15, 31, 25} 是一個典型的小根堆,
堆中有兩個父結點,元素 3 和元素 8,
元素 3 在陣列中以 R[0] 表示,它的左孩子結點是 R[1],右孩子結點是 R[2],
元素 8 在陣列中以 R[1] 表示,它的左孩子結點是 R[3],右孩子結點是 R[4],它的父結點是 R[0],可以看出,它們滿足以下規律:
設當前元素在陣列中以 R[i] 表示,那么,
它的左孩子結點是:R[2*i+1];
它的右孩子結點是:R[2*i+2];
它的父結點是:R[(i-1)/2];
R[i] <= R[2*i+1] 且 R[i] <= R[2i+2],
演算法思想
首先,按堆的定義將陣列 R[0..n]調整為堆(這個程序稱為創建初始堆),交換 R[0]和 R[n];
然后,將 R[0..n-1]調整為堆,交換 R[0]和 R[n-1];
如此反復,直到交換了 R[0]和 R[1]為止,
以上思想可歸納為兩個操作:
根據初始陣列去構造初始堆(構建一個完全二叉樹,保證所有的父結點都比它的孩子結點數值大),
每次交換第一個和最后一個元素,輸出最后一個元素(最大值),然后把剩下元素重新調整為大根堆,
當輸出完最后一個元素后,這個陣列已經是按照從小到大的順序排列了,
先通過詳細的實體圖來看一下,如何構建初始堆,
設有一個無序序列 { 1, 3,4, 5, 2, 6, 9, 7, 8, 0 },
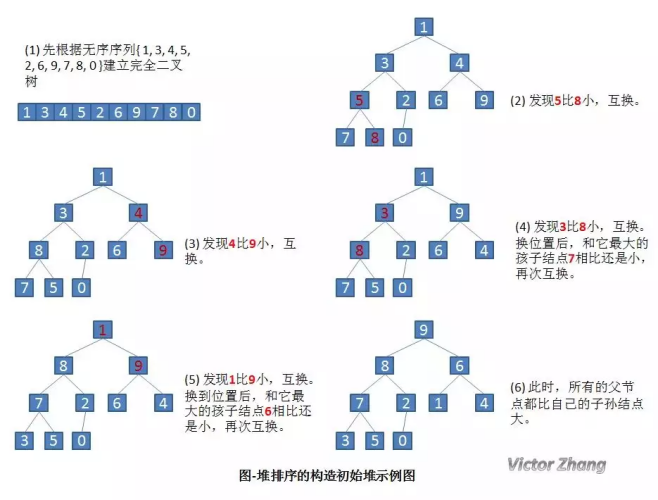
構造了初始堆后,我們來看一下完整的堆排序處理:
還是針對前面提到的無序序列 { 1,3, 4, 5, 2, 6, 9, 7, 8, 0 } 來加以說明,

相信,通過以上兩幅圖,應該能很直觀的演示堆排序的操作處理,
核心代碼
1 public void HeapAdjust(int[] array, int parent, int length) { 2 int temp = array[parent]; // temp保存當前父節點 3 int child = 2 * parent + 1; // 先獲得左孩子 4 5 while (child < length) { 6 // 如果有右孩子結點,并且右孩子結點的值大于左孩子結點,則選取右孩子結點 7 if (child + 1 < length && array[child] < array[child + 1]) { 8 child++; 9 } 10 11 // 如果父結點的值已經大于孩子結點的值,則直接結束 12 if (temp >= array[child]) 13 break; 14 15 // 把孩子結點的值賦給父結點 16 array[parent] = array[child]; 17 18 // 選取孩子結點的左孩子結點,繼續向下篩選 19 parent = child; 20 child = 2 * child + 1; 21 } 22 23 array[parent] = temp; 24 } 25 26 public void heapSort(int[] list) { 27 // 回圈建立初始堆 28 for (int i = list.length / 2; i >= 0; i--) { 29 HeapAdjust(list, i, list.length); 30 } 31 32 // 進行n-1次回圈,完成排序 33 for (int i = list.length - 1; i > 0; i--) { 34 // 最后一個元素和第一元素進行交換 35 int temp = list[i]; 36 list[i] = list[0]; 37 list[0] = temp; 38 39 // 篩選 R[0] 結點,得到i-1個結點的堆 40 HeapAdjust(list, 0, i); 41 System.out.format("第 %d 趟: \t", list.length - i); 42 printPart(list, 0, list.length - 1); 43 } 44 }
演算法分析
堆排序演算法的總體情況

時間復雜度
堆的存盤表示是順序的,因為堆所對應的二叉樹為完全二叉樹,而完全二叉樹通常采用順序存盤方式,
當想得到一個序列中第 k 個最小的元素之前的部分排序序列,最好采用堆排序,
因為堆排序的時間復雜度是 O(n+klog2n),若 k ≤ n/log2n,則可得到的時間復雜度為 O(n),
演算法穩定性
堆排序是一種不穩定的排序方法,
因為在堆的調整程序中,關鍵字進行比較和交換所走的是該結點到葉子結點的一條路徑,因此對于相同的關鍵字就可能出現排在后面的關鍵字被交換到前面來的情況,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
歸并排序
要點
歸并排序是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide and Conquer)的一個非常典型的應用,
將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
演算法思想
將待排序序列 R[0…n-1] 看成是 n 個長度為 1 的有序序列,將相鄰的有序表成對歸并,得到 n/2 個長度為 2 的有序表;將這些有序序列再次歸并,得到 n/4 個長度為 4 的有序序列;如此反復進行下去,最后得到一個長度為 n 的有序序列,
綜上可知:
歸并排序其實要做兩件事:
“分解”——將序列每次折半劃分,
“合并”——將劃分后的序列段兩兩合并后排序,
我們先來考慮第二步,如何合并?
在每次合并程序中,都是對兩個有序的序列段進行合并,然后排序,
這兩個有序序列段分別為 R[low, mid] 和 R[mid+1, high],
先將他們合并到一個區域的暫存陣列R2 中,帶合并完成后再將 R2 復制回 R 中,
為了方便描述,我們稱 R[low, mid] 第一段,R[mid+1, high] 為第二段,
每次從兩個段中取出一個記錄進行關鍵字的比較,將較小者放入 R2 中,最后將各段中余下的部分直接復制到 R2 中,
經過這樣的程序,R2 已經是一個有序的序列,再將其復制回 R 中,一次合并排序就完成了,
核心代碼
1 public void Merge(int[] array, int low, int mid, int high) { 2 int i = low; // i是第一段序列的下標 3 int j = mid + 1; // j是第二段序列的下標 4 int k = 0; // k是臨時存放合并序列的下標 5 int[] array2 = new int[high - low + 1]; // array2是臨時合并序列 6 7 // 掃描第一段和第二段序列,直到有一個掃描結束 8 while (i <= mid && j <= high) { 9 // 判斷第一段和第二段取出的數哪個更小,將其存入合并序列,并繼續向下掃描 10 if (array[i] <= array[j]) { 11 array2[k] = array[i]; 12 i++; 13 k++; 14 } else { 15 array2[k] = array[j]; 16 j++; 17 k++; 18 } 19 } 20 21 // 若第一段序列還沒掃描完,將其全部復制到合并序列 22 while (i <= mid) { 23 array2[k] = array[i]; 24 i++; 25 k++; 26 } 27 28 // 若第二段序列還沒掃描完,將其全部復制到合并序列 29 while (j <= high) { 30 array2[k] = array[j]; 31 j++; 32 k++; 33 } 34 35 // 將合并序列復制到原始序列中 36 for (k = 0, i = low; i <= high; i++, k++) { 37 array[i] = array2[k]; 38 } 39 }
掌握了合并的方法,接下來,讓我們來了解如何分解,
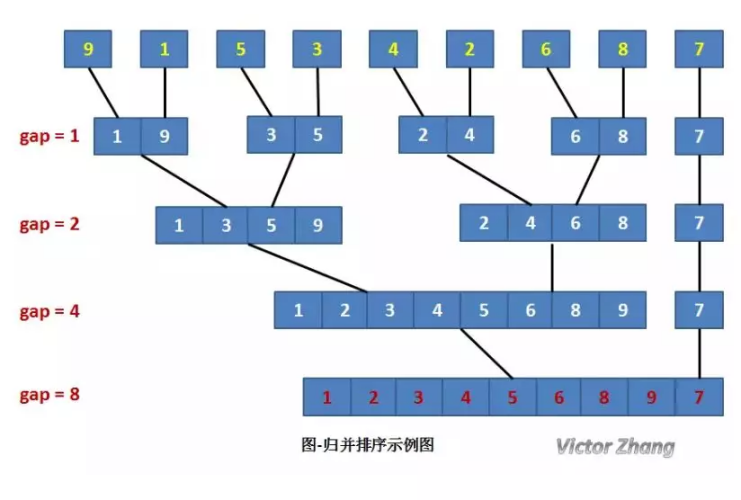
在某趟歸并中,設各子表的長度為 gap,則歸并前 R[0…n-1] 中共有 n/gap 個有序的子表:R[0…gap-1], R[gap…2gap-1], … ,
R[(n/gap)gap … n-1],
呼叫 Merge 將相鄰的子表歸并時,必須對表的特殊情況進行特殊處理,
若子表個數為奇數,則最后一個子表無須和其他子表歸并(即本趟處理輪空):若子表個數為偶數,則要注意到最后一對子表中后一個子表區間的上限為 n-1,
核心代碼
1 public void MergePass(int[] array, int gap, int length) { 2 int i = 0; 3 4 // 歸并gap長度的兩個相鄰子表 5 for (i = 0; i + 2 * gap - 1 < length; i = i + 2 * gap) { 6 Merge(array, i, i + gap - 1, i + 2 * gap - 1); 7 } 8 9 // 余下兩個子表,后者長度小于gap 10 if (i + gap - 1 < length) { 11 Merge(array, i, i + gap - 1, length - 1); 12 } 13 } 14 15 public int[] sort(int[] list) { 16 for (int gap = 1; gap < list.length; gap = 2 * gap) { 17 MergePass(list, gap, list.length); 18 System.out.print("gap = " + gap + ":\t"); 19 this.printAll(list); 20 } 21 return list; 22 }
演算法分析
歸并排序演算法的性能

時間復雜度
歸并排序的形式就是一棵二叉樹,它需要遍歷的次數就是二叉樹的深度,而根據完全二叉樹的可以得出它的時間復雜度是 O(n*log2n),
空間復雜度
由前面的演算法說明可知,演算法處理程序中,需要一個大小為 n 的臨時存盤空間用以保存合并序列,
演算法穩定性
在歸并排序中,相等的元素的順序不會改變,所以它是穩定的演算法,
歸并排序和堆排序、快速排序的比較
若從空間復雜度來考慮:首選堆排序,其次是快速排序,最后是歸并排序,
若從穩定性來考慮,應選取歸并排序,因為堆排序和快速排序都是不穩定的,
若從平均情況下的排序速度考慮,應該選擇快速排序,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
基數排序
要點
基數排序與本系列前面講解的七種排序方法都不同,它不需要比較關鍵字的大小,
它是根據關鍵字中各位的值,通過對排序的 N 個元素進行若干趟“分配”與“收集”來實作排序的,
不妨通過一個具體的實體來展示一下,基數排序是如何進行的,
設有一個初始序列為: R {50, 123, 543, 187, 49, 30,0, 2, 11, 100},
我們知道,任何一個阿拉伯數,它的各個位數上的基數都是以 0~9 來表示的,
所以我們不妨把 0~9 視為 10 個桶,
我們先根據序列的個位數的數字來進行分類,將其分到指定的桶中,例如:R[0] = 50,個位數上是 0,將這個數存入編號為 0 的桶中,
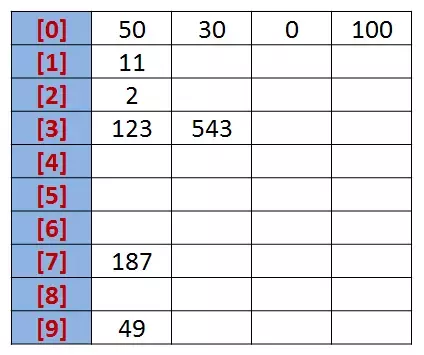
分類后,我們在從各個桶中,將這些數按照從編號 0 到編號 9 的順序依次將所有數取出來,
這時,得到的序列就是個位數上呈遞增趨勢的序列,
按照個位數排序:{50, 30, 0, 100, 11, 2, 123,543, 187, 49},
接下來,可以對十位數、百位數也按照這種方法進行排序,最后就能得到排序完成的序列,
演算法分析
基數排序的性能
時間復雜度
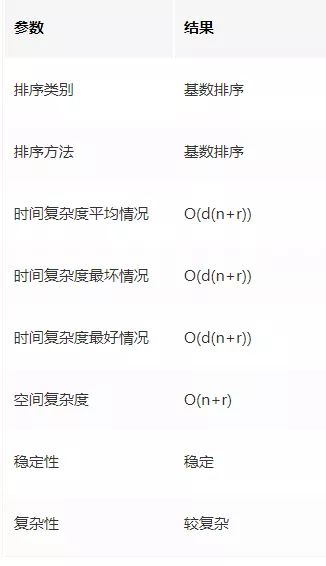
通過勺ò干知,假設在基數排序中,r 為基數,d 為位數,則基數排序的時間復雜度為 O(d(n+r)),
我們可以看出,基數排序的效率和初始序列是否有序沒有關聯,
空間復雜度
在基數排序程序中,對于任何位數上的基數進行“裝桶”操作時,都需要 n+r 個臨時空間,
演算法穩定性
在基數排序程序中,每次都是將當前位數上相同數值的元素統一“裝桶”,并不需要交換位置,所以基數排序是穩定的演算法,
示例代碼
https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
樣本包含:陣列個數為奇數、偶數的情況;元素重復或不重復的情況,且樣本均為隨機樣本,實測有效,
文章轉載自:《java那些事》微信公眾號,附公眾號地址:

感謝公眾號好文分享!本文僅限于演算法學習轉載,不做其它用途,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6735.html
標籤:其他