直接上簡化后的代碼:
class TestClass extends Serializable {
val map=Map[String,String]();
private def addItem(s:String){
val sArr=s.split(",");
map(sArr(0))=sArr(1);
println("***TEST item added: "+sArr(0)+"->"+sArr(1));
println("***TEST map size: "+map.size);
}
def test(){
val itemsFile = spark.sparkContext.textFile("./items.txt");
itemsFile.foreach( addItem(_) );
//問題:下行代碼輸出為0!
println("***TEST map size is "+map.size);
}
}
addItem()就是把一個(K,v)加到一個類成員變數map里。test()本意是,讀入一個檔案(里面每一行是一個(k,v)對)到RDD,然后處理每一行,把相應的(k,v)加到類成員變數map里。
呼叫test()時,可以看到addItem()每次都被成功呼叫,類成員變數map的size也一直增長。但到執行最后一行代碼的時候,map被清空了!size為0。。。
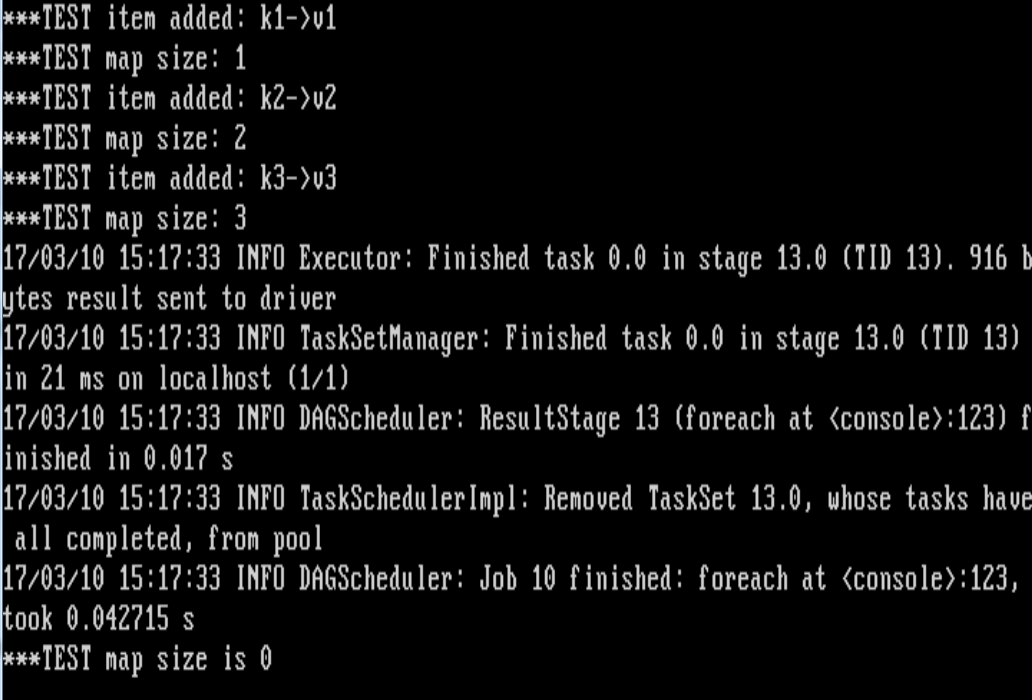
注意:如果我不用定義一個類來實作,而是直接寫additem,test方法,運行就沒問題。
求為什么會這樣?怎么解決?謝謝!
uj5u.com熱心網友回復:
You misunderstand the distribution meaning in Spark.The map instance running in your method addItem() is NOT the same as in your driver, which you try to print in the test().
Change your code to print the map instance identityHashCode will prove it:
class TestClass extends Serializable {
val map=Map[String,String]();
private def addItem(s:String){
val sArr=s.split(",");
map(sArr(0))=sArr(1);
println("***TEST item added: "+sArr(0)+"->"+sArr(1));
println("***TEST map size: "+map.size);
println(s"identityHashCode of map is ${System.identityHashCode(map)")
}
def test(){
val itemsFile = spark.sparkContext.textFile("./items.txt");
itemsFile.foreach( addItem(_) );
//問題:下行代碼輸出為0!
println("***TEST map size is "+map.size);
println(s"identityHashCode of map is ${System.identityHashCode(map)")
}
}
See the 2 lines I added, when you run in the cluster, you will find the identityHashCode printed in 2 methods are NOT the same.
uj5u.com熱心網友回復:
謝謝您的回復!那請問如何得到spark的處理結果?(就是test()方法里itemsFile.foreach( addItem(_) );)剛開始學習spark,的確對spark的運行機制、本質知之甚少。不過用spark的分布式處理能力處理變數,卻不能方便的保留結果,感覺spark應該提供相關機制這樣才更方便啊。
uj5u.com熱心網友回復:
Spark 當然可以保留結果. I will demo in English, hope you don't mind, as typing Chinese is too slow for me.You basically has 2 ways to keep your result:
1) Bring the data back to driver (using collect() API. This works on both RDD and DATAFRAME). But keep in mind that this will bring whole dataset back to driver (one node), so if the dataset is very big, then you will have memory pressure for that one node.
2) Saving the result dataset into a distributed storage. This is a normal way in most case. You can save your result into HDFS, S3, Cassandra, Hbase etc.
It looks like your originally code is trying to do in RDD api, so I demo in RDD api too, but even though RDD API is more powerful, but it misses the catalyst optimization, so its performance is not as good as DataFrame API in most cases.
It looks like your originally code is trying to dedup of the data (Since you are using MAP), but I have to warn you that it is dangerous to do what you tried to do. Keep in mind that in Spark or any distribution framework, the ORDER is never promised, unless you sort the data first (But it is a very expensive operation).
For example, if your text data is liking:
1,value1
2,value2
3,value3
1,valueNew
There is not promise that the last value "1, valueNew" will replace "1,value1", as they could be read by different machine at totally different time, so "1, valueNew" could read on machine 2 before "1,value1" read on machine1, then using "valueNew" to replace "value1" is never good idea, unless your data has one more field to give the order, like following:
1,value1,1
2,value2,2
3,value3,3
1,valueNew,4
So we can use the 3rd column to tell us which should replace which, or use "offset" bytes from the file as the ordering column too.
Anyway, the following example show you how to group them together and using "collect" bring them back to the driver
scala> spark.version
res2: String = 2.1.0
scala> val textFile = sc.makeRDD(Array("1,value1", "2,value2", "3,value3", "1,valueNew"))
textFile: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> val keyvalue = textFile.map(s => (s.split(",")(0), s.split(",")(1)))
keyvalue: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at map at <console>:26
scala> keyvalue.groupByKey.collect.foreach(println)
(2,CompactBuffer(value2))
(3,CompactBuffer(value3))
(1,CompactBuffer(value1, valueNew))
uj5u.com熱心網友回復:
非常感謝您的回復!以后spark的學習中還要多多向您請教!已關注您的ID :D
uj5u.com熱心網友回復:
不客氣,如果你的英文不錯的話,可以考慮自己上這個課:https://www.coursera.org/learn/scala-spark-big-data
It is online, free, and give you clear picture about how Spark/Distribution works.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/67613.html
標籤:Spark
上一篇:為什么在Flume中加入自定義interceptor會報出ClassNotFoundException
下一篇:資料結構(四):佇列