堆疊和佇列可看作是特殊的線性表,它們是運算受限的線性表
一、堆疊
堆疊:堆疊是只能在表的一端(表尾)進行 插入和洗掉的線性表;允許插入及洗掉的一端(表尾)稱為堆疊頂(Top); . 另一端(表頭)稱為堆疊底(Bottom);當表中沒有元素時稱為空堆疊
進堆疊:在堆疊頂插入一元素;
出堆疊:在堆疊頂洗掉一元素;
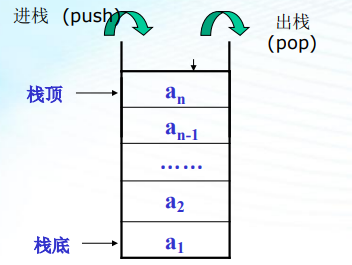
堆疊的特點:后進先出,堆疊中元素按a1,a2,a3,…an的次序進堆疊,出堆疊的第一個元素應 為堆疊頂元素,換句話說,堆疊的修改是按后進先出的原則進行的, 因此,堆疊稱為后進先出線性表(LIFO),
堆疊的用途:常用于暫時保存有待處理的資料
1、堆疊的順序實作:順序堆疊
- ● 堆疊容量——堆疊中可存放的最大元素個數;
- ● 堆疊頂指標 top——指示當前堆疊頂元素在堆疊中的位置;
- ● 堆疊空——堆疊中無元素時,表示堆疊空;
- ● 堆疊滿——陣列空間已被占滿時,稱堆疊滿;
- ● 下溢——當堆疊空時,再要求作出堆疊運算,則稱“下溢”;
- ● 上溢——當堆疊滿時,再要求作進堆疊運算,則稱“上溢”,
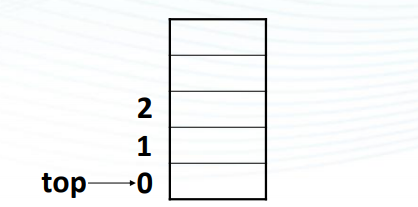
約定堆疊的第1個元素存在data[1]中, 則: s->top==0 代表順序堆疊s為空; s->top==maxsize-1 代表順序堆疊s為滿 ;
//堆疊大小 const int maxsize=6; //1、順序堆疊型別的定義 typedef struct seqstack { DataType data[maxsize]; int top; }SeqStk; //2、堆疊的初始化 int Initstack(SeqStk *stk){ stk->top=0; return 1; } //3、判斷空堆疊(堆疊空時回傳值為1,否則回傳值為0) int EmptyStack(SeqStk *stk){ if(stk->top= =0){ return 1; }else{ else return 0; } } /*4、進堆疊 資料元素x進順序堆疊sq*/ int Push(SeqStk *stk, DataType x){ /*判是否上溢*/ if(stk->top==maxsize -1){ error(“堆疊滿”);return 0; } else { stk->top++;/*修改堆疊頂指標,指向新堆疊頂*/ stk->data[stk->top]=x; /*元素x插入新堆疊頂中*/ return 1; } } /*5、出堆疊 順序堆疊sq的堆疊頂元素退堆疊*/ int Pop(SeqStk *stk){ /*判是否下溢*/ if(stk->top==0){ error(“堆疊空”); return 0; }else { stk->top-- ; /*修改堆疊頂指標,指向新堆疊頂*/ return 1; } } //6、 取堆疊頂元素 DataType GetTop(SeqStk *stk){ if(EmptyStack(stk)){ return NULLData; }else{ return stk->data[stk->top]; } }
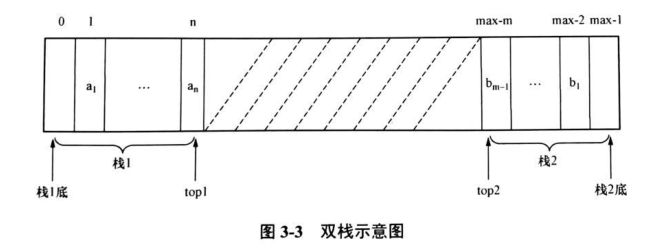
雙堆疊
在某些應用中,為了節省空間,讓兩個資料元素型別一致的堆疊共享一維陣列空間 data[max],成為雙堆疊,兩個堆疊的堆疊底分別設在陣列兩端,讓兩個堆疊彼此迎面“增長”,兩個堆疊的堆疊頂變數分別為 top1、top2,僅當兩個堆疊的堆疊頂位置在中間相遇時(top1 + 1 =top2)才發生“上溢”,判堆疊空時,兩個堆疊不同,當 top1=0 時堆疊 1 為空堆疊,top2=max-1 時堆疊 2 為空桟,雙堆疊如圖:
2、堆疊的鏈接實作:鏈堆疊
堆疊的鏈式存盤結構稱為鏈堆疊,它是運算受限的單鏈表, 插入和洗掉操作僅限制在表頭位置上進行,堆疊頂指標就是鏈 表的頭指標

下溢條件:LS->next==NULL;上溢:鏈堆疊不考慮堆疊滿現象
//1、鏈堆疊的定義 typedef struct node{ DataType data; struct node *next } LkStk; //2、鏈堆疊的初始化 void InitStack(LkStk *LS){ LS=(LkStk *)malloc(sizeof(LkStk)); LS->next=NULL; } //3、判斷堆疊空 int EmptyStack(LkStk *LS){ if(LS->next= =NULL){ return 1; } else{ return 0; } } //4、進堆疊:在堆疊頂插入一元素x:生成新結點(鏈堆疊不會有上溢情況發生);將新結點插入鏈堆疊中并使之成為新的堆疊頂結點 void Push (LkStk *LS, DataType x){ LkStk *temp; temp= (LkStk *) malloc (sizeof (LkStk)); temp->data=https://www.cnblogs.com/jalja365/p/x; temp->next=LS->next; LS->next=temp; } //5、出堆疊:在堆疊頂洗掉一元素,并回傳;考慮下溢問題;不下溢,則取出堆疊頂元素,從鏈堆疊中洗掉堆疊頂結點并將結點回歸系統 int Pop (LkStk *LS){ LkStk *temp; if (!EmptyStack (LS)){ temp=LS->next; LS->next=temp->next; free(temp); return 1; }else{ return 0; } } //6、取堆疊頂元素 DataType GetTop(LkStk *LS){ if (!EmptyStack(LS)){ return LS->next->data; }else{ return NULLData; } }
二、佇列
佇列(Queue)也是一種運算受限的線性表,
佇列:是只允許在表的一端進行插入,而在另一 端進行洗掉的線性表,
其中:允許洗掉的一端稱為隊頭(front), 允許插入的另一端稱為隊尾(rear), 佇列 Q=(a1,a2,a3,…an )

佇列特點:先進先出(FIFO);常用于暫時保存有待處理的資料
1、佇列的順序實作
佇列的順序實作:一般用一維陣列作為佇列的存盤結構
佇列容量:佇列中可存放的最大元素個數
初始: front=rear=0
進隊: rear增1,元素插入尾指標所指位置
出隊: front增1,取頭指標所指位置元素
隊頭指標front:始終指向實際隊頭元素的前一位置
隊尾指標 rear:始終指向實際隊尾元素
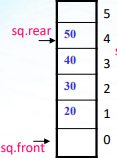
//順序佇列的構造 const int maxsize=20; typedef struct seqqueue { DataType data[maxsize]; int front, rear ; }SeqQue; SeqQue sq;
入佇列操作:sq.rear=sq.rear+1;sq.data[sq.rear]=x;
出佇列操作:sq.front=sq.front+1;
上溢條件:sq.rear = = maxsize-1 ( 隊滿 )
下溢條件:sq.rear = = sq.front (佇列空)
順序佇列的假溢位:sq.rear == maxsize-1,但佇列中實際容量并未達到最大容量的現象;極端現象:佇列中的項不多于1,也導致“上溢”.假溢位浪費空間回圈佇列可以解決該問題
2、回圈佇列
為佇列分配一塊存盤空間(陣串列示),并將 這一塊存盤空間看成頭尾相連接的,
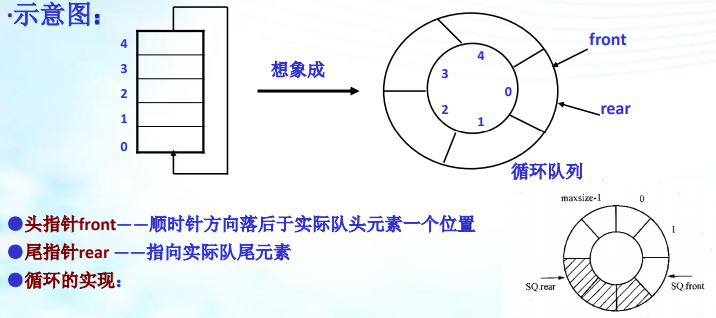
對插入即入隊: 隊尾指標增1,Sq.rear=(sq.rear+1)%maxsize
對洗掉即出隊: 隊頭指標增1,Sq.front=(sq.front+1)%maxsize
下溢條件即佇列空:CQ.front==CQ.rear
上溢條件即佇列滿:尾指標從后面追上頭指標,(CQ.rear+1)%maxsize==CQ.front(浪費一個空間,隊滿時實際隊容量=maxsize-1)
設以陣列Q[m]存放回圈佇列的元素,變數rear和queuelen分別表示回圈佇列中隊尾元素的下標位置和元素的個數,則計算該佇列中隊頭元素下標位置的公式是 (rear-queuelen+m)%m
例題:


(rear-front+n)%n=(7-8+100)%100=99
例題:


//回圈佇列的定義 typedef struct Cycqueue{ DataType data[maxsize]; int front,reat; }CycQue; CycQue CQ; //回圈佇列的初始化 void InitQueue(CycQue CQ){ CQ.front=0; CQ.rear=0; } //回圈佇列判斷空 int EmptyQueue(CycQue CQ){ if (CQ.rear==CQ.front){ return 1; } else{ else return 0; } } 入隊——在隊尾插入一新元素x ● 判上溢否?是,則上溢回傳; ● 否則修改隊尾指標(增1),新元素x插入隊尾, int EnQueue(CycQue CQ,DataType x){ if ((CQ.rear+1)%maxsize==CQ.front){ error(“佇列滿”);return 0; }else { CQ.rear=(CQ.rear+1)%maxsize; CQ.data[CQ.rear]=x; return 1; } } 出隊——洗掉隊頭元素,并回傳 ● 判下溢否?是,則下溢回傳; ● 不下溢,則修改隊頭指標,取隊頭元素, int OutQueue(CycQue CQ){ if (EmptyQueue(CQ)){ error(“佇列空”); return 0; }else { CQ.front=(CQ.front+1)%maxsize; return 1; } } //.取佇列首元素 DataType GetHead(CycQue CQ){ if (EmptyQueue(CQ)){ return NULL; }else{ return CQ.data[(CQ.front+1)%maxsize]; } }
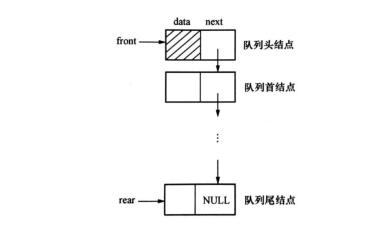
3、佇列的鏈接實作
佇列的鏈接實作實際上是使用一個帶有頭結點的單鏈表來表示佇列,稱為鏈佇列,頭指標指向鏈表的頭結點,單鏈表的頭結點的next 域指向佇列首結點,尾指標指向佇列尾結點,即單鏈表的最后一個結點;佇列的鏈式實作是動態申請空間,所以不會存在隊滿的情況,
//型別定義 typedef struct LinkQueueNode{ DataType data; struct LinkQueueNode *next; } LkQueNode; typedef struct LkQueue{ LkQueNode *front, *rear; }LkQue; LkQue LQ; 由于鏈接實作需要動態申請空間,故鏈佇列在一定范圍內不會出現佇列滿的情況,當(LQ.front==LQ.rear)成立時,佇列中無資料元素,此時佇列為空 //(1)佇列的初始化 void InitQueue(LkQue *LQ){ LkQueNode *temp; temp= (LkQueNode *)malloc (sizeof (LkQueNode)); //生成佇列的頭結點 LQ->front=temp; //佇列頭才旨針指向佇列頭結點 LQ->rear=temp; //佇列尾指標指向佇列尾結點 (LQ->front) ->next=NULL; } //判佇列空 int EmptyQueue(LkQue LQ){ if (LQ.rear==LQ.front){ return 1; //佇列為空 }else{ return 0; } } //入佇列 void EnQueue(LkQue *LQ;DataType x){ LkQueNode *temp; temp=(LkQueNode *)malloc(sizeof(LkQueNode)); temp->data=https://www.cnblogs.com/jalja365/p/x; temp->next=NULL; (LQ->rear)->next=temp; //新結點入佇列 LQ->rear=temp; //置新的佇列尾結點 } //出佇列 OutQueue(LkQue *LQ){ LkQueNode *temp; if (EmptyQueue(CQ)){ //判佇列是否為空 error(“隊空”); //佇列為空 return 0; }else { //佇列非空 temp=(LQ->front) ->next; //使 temp 指向佇列的首結點 (LQ->front) ->next=temp->next; //修改頭結點的指標域指向新的首結點 if (temp->next==NULL){ LQ->rear=LQ->front; //無首結點時,front 和 rear 都指向頭結點 } free(temp); return 1; } } //取佇列首元素 DataType GetHead (LkQue LQ){ LkQueNode *temp; if (EmptyQueue(CQ)){ return NULLData; //判佇列為空,回傳空資料標志 } else { temp=LQ.front->next; return temp->data; //佇列非空,回傳佇列首結點元素 } }
三、陣列
陣列:是線性表的推廣,其每個元素由一個值和一組下標組成,其中下標個數稱為陣列的維數
一維陣列:陣列可以看成線性表的一種推廣,一維陣列又稱向量,它由一組具有相同型別的資料元素組成,并存盤在一組連續的存盤單元中
多維陣列:若一維陣列中的資料元素又是一維陣列結構,則稱為二維陣列;依此類推,若一維陣列中的元素又是一個二維陣列結構,則稱作三維陣列,一般地,一個 n 維陣列可以看成元素為 (n-1) 維陣列的線性表,多維陣列是線性表的推廣
二維陣列Amn可以看成是由m個行向量組成的向量,也可以看成是n個列向量組成的向量,

陣列一旦被定義,它的維數和維界就不再改變,因此,除了結構的初始化和銷毀之外,陣列通常只有兩種基本運算:
- 讀:給定一組下標,回傳該位置的元素內容;
- 寫:給定一組下標,修改該位置的元素內容,
陣列的存盤結構
一維陣列元素的記憶體單元地址是連續的,二維陣列可有兩種存盤方法:一種是以列序為主序的存盤;另一種是以行序為主序的存盤,陣列元素的存盤位置是下標的線性函式
1. 存盤結構:順序存盤結構
由于計算機的記憶體結構是一維的,因此用一維記憶體來表示多維陣列,就必須按某種次序將陣列元素排成一列序列,然后將這個線性序列存放在存盤器中;又由于對陣列一般不做插入和洗掉操作,也就是說,陣列一旦建立,結構中的元素個數和元素間的關系就不再發生變化,因此,一般都是采用順序存盤的方法來表示陣列,


2、矩陣的壓縮存盤
為了節省存盤空間, 我們可以對這類矩陣進行壓縮存盤:即為多個相同的非零元素只分配一個存盤空間;對零元素不分配空間,
特殊矩陣:即指非零元素或零元素的分布有一定規律的矩陣,下面我們討論幾種特殊矩陣的壓縮存盤,


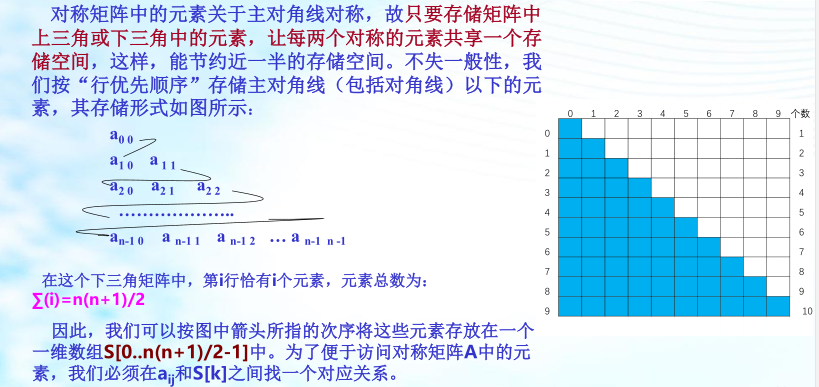
三角矩陣
以主對角線劃分,三角矩陣有上三角和下三角兩種,上三角矩陣如圖所示,它的下三角(不包括主對角線)中的元素均為常數,下三角矩陣正好相反,它的主對角線上方均為常數,如圖所示,在大多數情況下,三角矩陣常數為零,
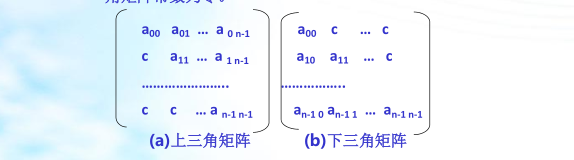
三角矩陣中的重復元素c可共享一個存盤空間,其余的元素正好有n(n+1)/2個,因此,三角矩陣可壓縮存盤到向量s[0..n(n+1)/2]中,其中c存放在向量的最后一個分量中,

稀疏矩陣
什么是稀疏矩陣:簡單說,設矩陣A中有s個非零元素,若s遠遠小于矩陣元素的總數,則稱A為稀疏矩陣,
稀疏矩陣的壓縮存盤: 即只存盤稀疏矩陣中的非零元素,由于非零元素的分布一般是沒有規律的,因此在存盤非零元素的同時,還必須同時記下它所在的行和列的位置(i,j),
反之,一個三元組(i,j,aij )唯一確定了矩陣A的一個非零元,因此,稀疏矩陣可由表示非零元的三元組及其行列數唯一確定,

稀疏矩陣的三元組順序表表示法——將矩陣中的非零元素化成三元組形式并按行的遞減次序(同行按列的遞增次序)存放在記憶體中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/67624.html
標籤:其他
上一篇:如何修改spark原始碼