作者|SUBHASH MEENA
編譯|VK
來源|Analytics Vidhya
概述
-
假設檢驗是統計學、分析學和資料科學中的一個關鍵概念
-
了解假設檢驗的作業原理、Z檢驗和t檢驗之間的區別以及其他統計概念
介紹
冠狀病毒大流行使我們大家都成了一個統計學家,我們不斷地核對數字,對大流行將如何發展做出自己的假設,并對何時出現“高峰”提出假設,
不僅是我們在進行假設構建,媒體也在這方面蓬勃發展,
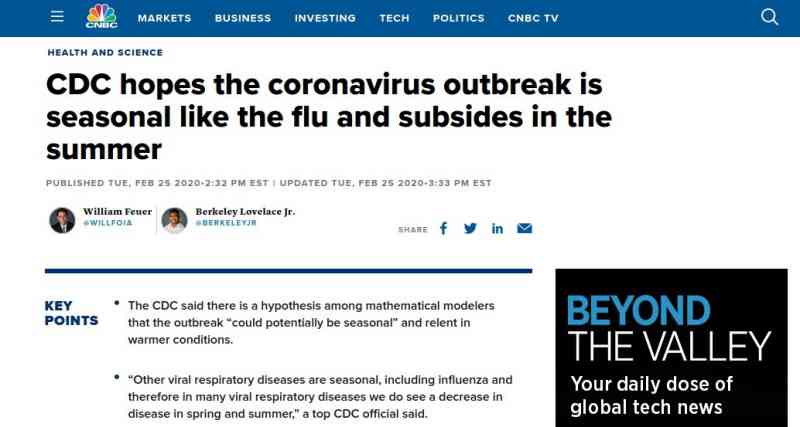
幾天前,我讀到一篇新聞文章,其中提到這次疫情“可能是季節性的”,在溫暖的環境下會有所緩解:
所以我開始想,關于冠狀病毒,我們還能假設什么呢?
- 成人是否更容易受到冠狀病毒爆發的影響?
- 相對濕度如何影響病毒的傳播?
有什么證據支持這些說法,我們如何檢驗這些假設呢?
作為一個統計愛好者,所有這些問題都挖掘了我對假設檢驗基本原理的舊知識,本文將討論假設檢驗的概念以及Z檢驗與t檢驗的區別,
然后,我們將使用COVID-19案例研究總結我們的假設檢驗學習,
目錄
-
假設檢驗基礎
- 基本概念-零假設、替代假設、型別1錯誤、型別2錯誤和顯著性水平
- 進行假設檢驗的步驟
- 定向假設
- 非定向假設檢驗
-
什么是Z檢驗?
- 單樣本Z檢驗
- 雙樣本Z檢驗
-
什么是t檢驗?
- 單樣本t檢驗
- 雙樣本t檢驗
-
Z檢驗和t檢驗的決定
-
案例研究:Python冠狀病毒的假設檢驗
假設檢驗基礎

讓我們舉一個例子來理解假設檢驗的概念,
一個人因刑事犯罪正在接受審判,法官需要對他的案件作出判決,現在,在這種情況下有四種可能的組合:
-
第一種情況:此人是無辜的,法官認定此人是無辜的
-
第二種情況:此人無罪,法官認定此人有罪
-
第三種情況:此人有罪,法官認定此人無罪
-
第四種情況:此人有罪,法官認定此人有罪
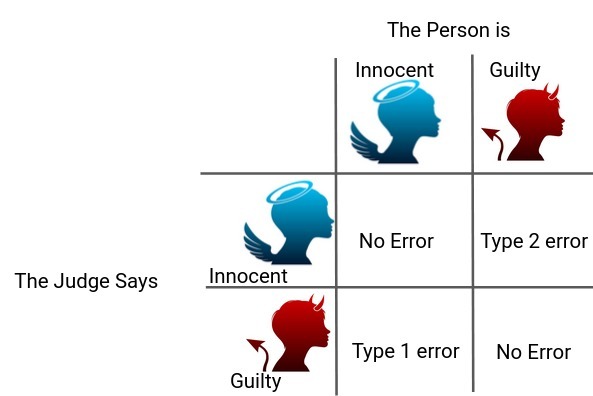
正如你可以清楚地看到的,在判決中有兩種型別的錯誤,
- 第一種錯誤:當判決是針對無辜的人時
- 第二種錯誤:當判決是有利于有罪的人時
根據無罪推定,該人在被證明有罪之前被視為無罪,這意味著法官必須找到使他“毫無疑問”的證據,
這種“毫無疑問”的現象可以理解為概率(法官判定有罪|人無罪)應該很小,
假設檢驗的基本概念實際上相當類似于這種情況,
我們認為零假設是正確的,直到我們找到有力的證據反對它,那么,我們接受另一種假設,
我們還確定了顯著性水平(?),這可以理解為(法官判定有罪|人是無罪的)在前面的例子中的概率,
因此,如果?較小,則需要更多的證據來拒絕零假設,別擔心,我們稍后會用一個案例來討論所有這些,

進行假設檢驗的步驟
進行假設檢驗有四個步驟:
-
設定假設
-
設定決策的重要程度和標準
-
計算測驗統計
-
做決策
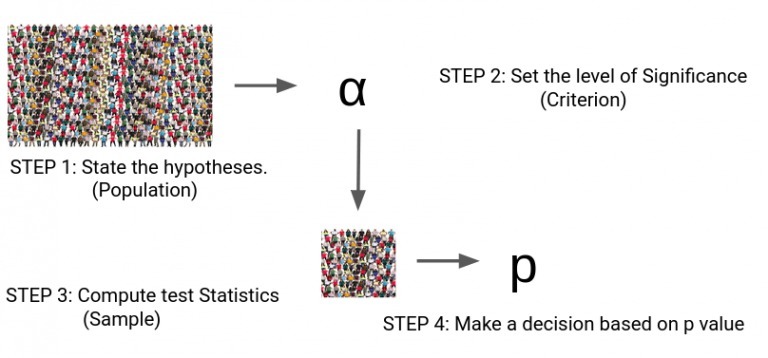
步驟1到步驟3是非常不言而喻的,但是我們可以根據什么在步驟4中做出決定?這個p值表示什么?
我們可以把這個p值理解為衡量辯護律師論點的標準,如果p值小于?,則拒絕零假設;如果p值大于?,則不拒絕零假設,
臨界值,p值
讓我們用正態分布的圖形表示來理解假設檢驗的邏輯,
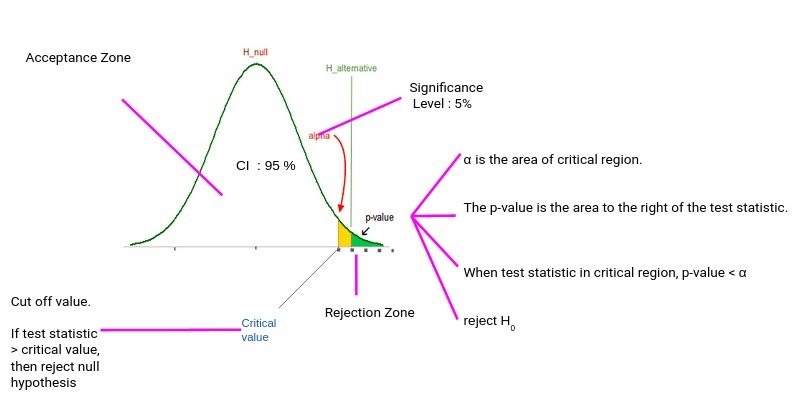
通常,我們將顯著性水平設定為10%、5%或1%,
如果我們的測驗分數在可接受范圍內,我們就不能拒絕零假設,如果我們的測驗分數在臨界區,我們拒絕零假設,接受替代假設,
臨界值是驗收區和拒收區之間的截止值,我們將我們的測驗分數與臨界值進行比較,如果測驗分數大于臨界值,則意味著我們的測驗分數位于拒絕區域,我們拒絕零假設,
另一方面,如果測驗分數小于臨界值,則意味著測驗分數位于接受區,我們無法拒絕零假設,
但是,當我們可以根據測驗分數和臨界值拒絕/接受假設時,為什么我們需要p值?
p值的好處是我們只需要一個值就可以對假設做出決定,我們不需要計算兩個不同的值,比如臨界值和測驗分數,
使用p值的另一個好處是,我們可以通過直接將其與顯著性水平進行比較,在任何期望的顯著性水平上進行測驗,

這樣我們就不需要計算每個顯著性水平的考試分數和臨界值,我們可以得到p值,并直接與顯著性水平進行比較,
定向假設
在定向假設中,如果測驗分數太大(右尾的測驗分數太小,左尾的測驗分數太小),則會拒絕零假設,因此,這種測驗的拒絕區域由一個部分組成,
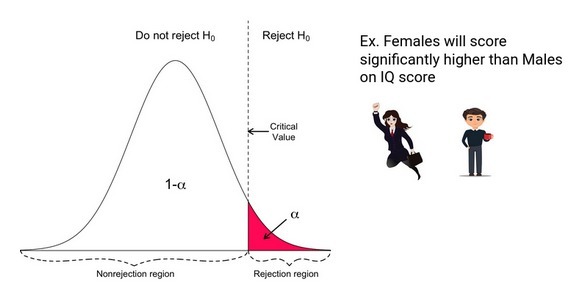
非定向假設
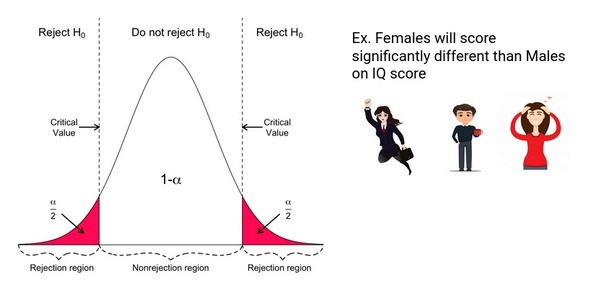
在非定向假設檢驗中,如果檢驗分數太小或太大,則拒絕零假設,因此,這種測驗的拒絕區域由兩部分組成:一部分在左側,一部分在右側,
什么是Z檢驗?
Z檢驗是檢驗假設的統計方法,當:
-
我們知道人口的變化,或者
-
我們不知道總體方差,但我們的樣本量很大n≥30
如果樣本量小于30且不知道總體方差,則必須使用t檢驗,
單樣本Z檢驗
當我們想比較樣本均值和總體均值時,我們執行單樣本Z檢驗,
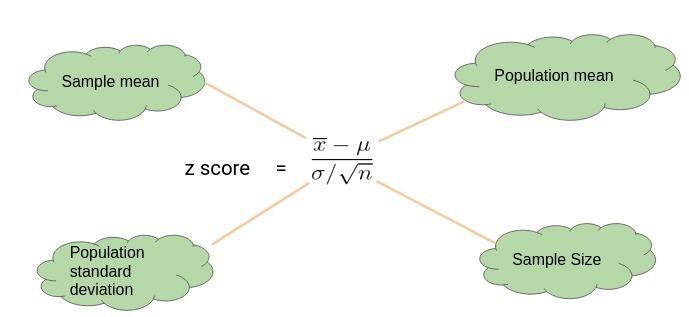
下面是一個了解單樣本Z檢驗的示例
假設我們需要確定女生在考試中的平均分是否高于600分,
- 我們得到的資訊是女生成績的標準差是100,
- 因此,我們采用隨機抽樣的方法收集了20名女生的資料,并記錄她們的成績,
- 最后,我們還將?值(顯著性水平)設定為0.05,

在本例中:
-
女生的平均分是641分
-
樣本的大小是20
-
平均是600
-
標準差為100

由于P值小于0.05,我們可以拒絕零假設,并根據我們的結果得出結論,女孩平均得分高于600,
雙樣本Z檢驗
當我們想要比較兩個樣本的平均值時,我們執行兩個樣本的Z檢驗,
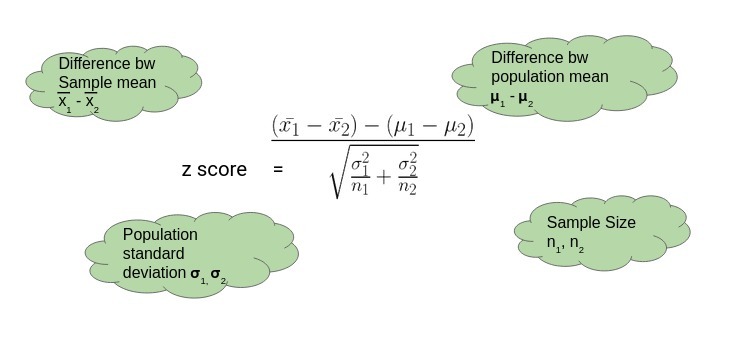
下面是一個了解雙樣本Z檢驗的示例
這里,假設我們想知道女生的平均分是否比男生高出10分,
- 我們得到的資訊是,女生成績的標準差是100,男生成績的標準差是90,
- 然后采用隨機抽樣的方法收集20名女生和20名男生的資料,記錄她們的成績,
- 最后,我們還將?值(顯著性水平)設定為0.05,

在本例中:
-
女孩的平均分(樣本平均值)是641
-
男孩的平均分(樣本平均值)為613.3
-
女生標準差為100
-
男生標準差是90
-
男女樣本量均為20
-
平均分差異是10

因此,我們可以根據P值得出結論,我們不能拒絕零假設,我們沒有足夠的證據得出這樣的結論:女生的平均分比男生高出10分,很簡單,對吧?
什么是t檢驗?
t檢驗是檢驗假設的一種統計方法,當:
-
我們不知道總體方差
-
我們的樣本量很小,n < 30
一個樣本的t檢驗
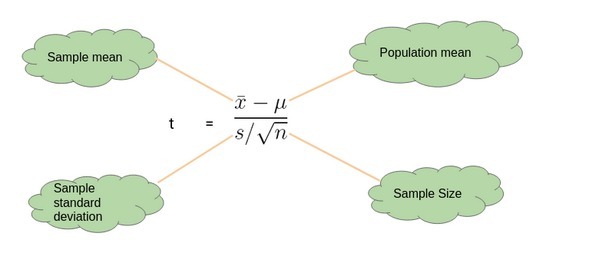
當我們想要比較樣本均值和總體均值時,我們執行一個單樣本t檢驗,與Z檢驗的不同之處在于,我們這里沒有關于總體方差的資訊,
在這種情況下,我們使用樣本標準差代替總體標準差,
下面是一個了解單樣本t檢驗的示例
假設我們想確定女生平均考試成績是否超過600分,我們沒有與女孩分數的方差(或標準差)相關的資訊,為了進行t檢驗
- 我們隨機收集了10名有分數的女孩的資料
- 選擇我們的?值(顯著性水平)為0.05進行假設檢驗,
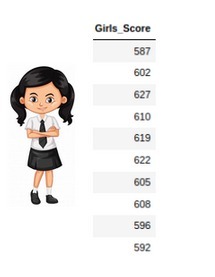
在本例中:
-
女生的平均分是606.8分
-
樣本大小是10
-
平均分是600
-
樣本的標準差為13.14

我們的P值大于0.05,因此我們無法拒絕零假設,也沒有足夠的證據來支持這樣的假設:平均來說,女孩在考試中的得分超過600分,
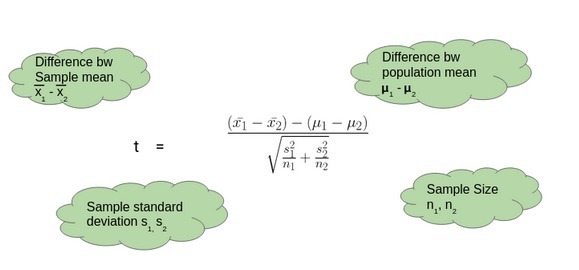
雙樣本t檢驗
當我們想要比較兩個樣本的平均值時,我們執行雙樣本t檢驗,
下面是一個理解雙樣本t檢驗的例子
這里,假設我們想確定,在考試中,男生的平均分數是否比女生高出15分,我們沒有與女孩或男孩分數的方差(或標準差)相關的資訊,為了進行t檢驗
- 我們隨機收集了10名男女學生的成績資料
- 我們選擇?值(顯著性水平)為0.05作為假設檢驗的標準

在本例中:
-
男生的平均分是630.1
-
女生的平均分是606.8分
-
平均相差15分
-
男生成績的標準差是13.42
-
女生成績的標準差為13.14

因此,P值小于0.05,因此我們可以拒絕零假設,并得出結論:在考試中,男孩平均比女孩多15分,
Z檢驗和T檢驗的決定
那么我們什么時候應該做Z檢驗,什么時候應該做t檢驗呢?如果我們想掌握統計學,這是我們需要回答的一個關鍵問題,
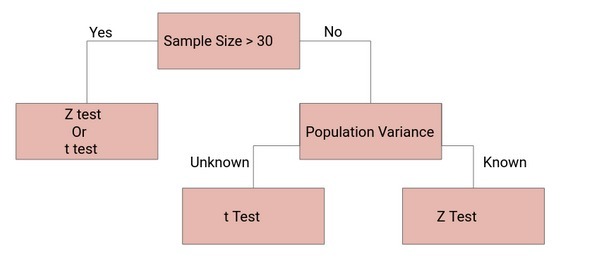
如果樣本量足夠大,那么Z檢驗和t檢驗將得出相同的結果,對于大樣本,樣本方差是對總體方差的較好估計,因此即使總體方差未知,我們也可以使用樣本方差的Z檢驗,
同樣,對于大樣本,我們有很高的自由度,由于t分布接近正態分布,z分和t分之間的差異可以忽略不計,
案例研究:用Python對冠狀病毒進行假設檢驗
現在讓我們為冠狀病毒資料集實作兩個樣本Z測驗,讓我們把理論知識付諸實踐,看看能不能做好,你可以在這里下載資料集,
https://drive.google.com/file/d/1SJHiTq9QH3GX4CHKtODY3pcmmtxx0bB9/view?usp=sharing
這個資料集取自John Hopkin的存盤庫,你可以在這里找到它的鏈接,
https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports
此資料集具有以下特征:
- Province/State
- Country/Region
- Last Update
- Confirmed
- Deaths
- Recovered
- Lattitude
- Longitude
我們還使用Python的Weather API-Pyweatherbit添加了緯度和經度的溫度和濕度特性,
關于COVID-19的一個普遍看法是,溫暖的氣候對日冕爆發更有抵抗力,我們需要通過假設檢驗來驗證這一點,那么,我們的零假設和替代假設是什么呢?
-
零假設:溫度不影響COV-19的爆發
-
替代假設:溫度確實影響COV-19的爆發
注:在我們的資料集中,溫度低于24表示寒冷氣候,高于24表示炎熱氣候,
import pandas as pd
import numpy as np
corona = pd.read_csv('Corona_Updated.csv')
corona['Temp_Cat'] = corona['Temprature'].apply(lambda x : 0 if x < 24 else 1)
corona_t = corona[['Confirmed', 'Temp_Cat']]
def TwoSampZ(X1, X2, sigma1, sigma2, N1, N2):
from numpy import sqrt, abs, round
from scipy.stats import norm
ovr_sigma = sqrt(sigma1**2/N1 + sigma2**2/N2)
z = (X1 - X2)/ovr_sigma
pval = 2*(1 - norm.cdf(abs(z)))
return z, pval
d1 = corona_t[(corona_t['Temp_Cat']==1)]['Confirmed']
d2 = corona_t[(corona_t['Temp_Cat']==0)]['Confirmed']
m1, m2 = d1.mean(), d2.mean()
sd1, sd2 = d1.std(), d2.std()
n1, n2 = d1.shape[0], d2.shape[0]
z, p = TwoSampZ(m1, m2, sd1, sd2, n1, n2)
z_score = np.round(z,8)
p_val = np.round(p,6)
if (p_val<0.05):
Hypothesis_Status = 'Reject Null Hypothesis : Significant'
else:
Hypothesis_Status = 'Do not reject Null Hypothesis : Not Significant'
print (p_val)
print (Hypothesis_Status)
0.180286
Do not reject Null Hypothesis : Not Significant
因此,我們沒有證據否定我們的零假設,即溫度不影響COV-19的爆發,
雖然我們無法找到溫度對COV-19的影響,但這個問題只是作為我們在本文中所學的概念性理解,COVID-19資料集的Z檢驗有一定的局限性:
-
樣本資料可能不能很好地代表人口資料
-
樣本方差可能不是總體方差的好估計量
-
一個州應對這種流行病的能力的變化
-
社會經濟原因
-
某些地方的早期突破
-
一些國家可能出于地緣政治原因而隱瞞這些資料
因此,我們需要更加謹慎,進行更多的研究,以確定這種流行病的模式,
結尾
本文采用逐步回歸的方法,對假設檢驗、1型誤差、2型誤差、顯著性水平、臨界值、p值、非定向假設、定向假設、Z檢驗和t檢驗的基本原理進行了研究,并對一個冠狀病毒病例進行了兩樣本Z檢驗,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/06/statistics-analytics-hypothesis-testing-z-test-t-test/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6787.html
標籤:其他