作者|Madhukara Putty
編譯|VK
來源|gitconnected

你有沒有想過Netflix是如何推薦你想看的電影的?或者亞馬遜如何向你展示你覺得需要購買的產品?
很明顯,那些網站已經知道你喜歡看什么或買什么了,他們有一段在后臺運行的代碼,可以在線收集用戶行為資料,并預測單個用戶對特定內容或產品的好惡,這種系統被稱為“推薦系統”,
一般來說,開發推薦系統有兩種方法,在一種方法中,系統考慮個人所消費內容的屬性,例如,如果你在Netflix上一天內看過黑客帝國,那么Netflix知道你喜歡科幻電影,而且更有可能推薦其他科幻電影,換言之,推薦是基于電影型別-科幻在這種情況下,
在另一種方法中,推薦系統會考慮與你口味相似的其他人的偏好,并推薦他們看過的電影,與第一種方法不同的是,建議是基于多個用戶的行為,而不是基于所消費內容的屬性,這種方法稱為協同過濾,
在這個例子中,我們認為這兩種方法都更有可能向你推薦科幻電影,但它們會采取不同的方法得出結論,
效用矩陣
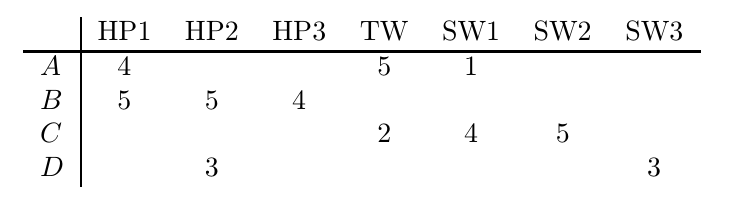
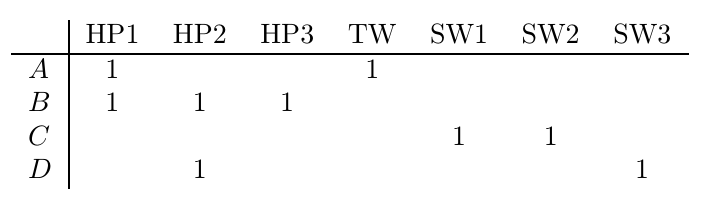
協同過濾的一個重要部分是識別具有相似偏好的觀眾,盡管Netflix采用多種方式收集用戶偏好資訊,但為了簡單起見,我們假設它要求觀眾對電影進行1-5級評分,我們還假設只有7部電影(哈利波特三部曲HP1~3、暮光之城TW和星球大戰三部曲SW1~3)需要審查,只有4位觀眾被要求對它們進行評分,
圖1顯示了我們四個精心挑選的觀眾提供的評分,這樣一個表,產品在列上,用戶在行上,叫做效用矩陣,空白意味著有些用戶還沒有給某些電影打分,
事實上,Netflix每天都有上千個節目被數以百萬計的觀眾消費,相應地,它的實際效用矩陣將有數百萬行,跨越數千列,此外,隨著系統不斷獲取用戶行為資訊,矩陣也會動態更新,
通過查看圖1中的效用矩陣,我們可以得出一些明顯的結論,
-
觀眾A喜歡《哈利波特1》和《暮光之城》,但不喜歡《星球大戰1》
-
觀眾B喜歡哈利波特三部曲的所有電影
-
觀眾C喜歡《星球大戰1》和《星球大戰2》,但不喜歡《暮光之城》
-
觀眾D不介意在無聊的一天里看《哈利波特2》和《星球大戰2》,但這兩部電影都不是她的選擇
總而言之,觀眾A和觀眾B有著相似的品味,因為他們都喜歡《哈利波特1》,相比之下,觀眾A和C有不同的口味,因為觀眾A喜歡《暮光之城》,但觀眾C一點也不喜歡,同樣,A不喜歡星球大戰,但C喜歡,推薦系統需要一種方法來比較不同觀眾的評論,并告訴我們他們的品味有多接近,
量化相似性
有不同的標準來比較兩個觀眾提供的評分,并找出他們是否有相似的品味,在本文中,我們將學習其中的兩個:Jaccard距離和余弦距離,口味相似的觀眾更接近,
Jaccard距離
Jaccard距離是另一個稱為Jaccard相似性的量的函式,根據定義,集合S和T的Jaccard相似性是S和T的交的大小與其并的大小之比,從數學上講,它可以寫成:
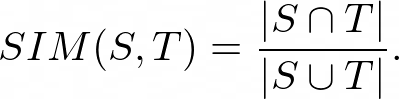
集A和集B之間的Jaccard距離d(x,y)由下式給出,
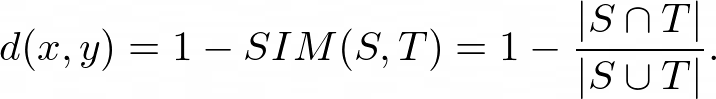
余弦距離
兩個向量A和B之間的余弦距離是角度d(A,B),由,
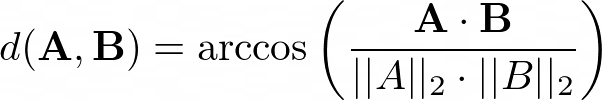
其中
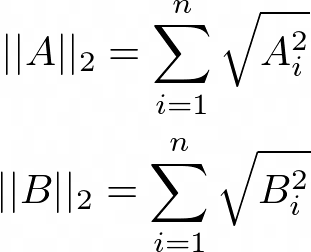
分別是向量A和向量B的\(L_2\)范數,n是要審查的產品(本例中是電影)的數量,余弦距離在0到180度之間變化,
效用矩陣距離測度的計算
為了更好地理解這些距離度量,讓我們使用效用矩陣中的資料計算距離(圖1),
計算Jaccard距離:計算Jaccard距離的第一步是以集合的形式寫入用戶給出的評分,對應于用戶A和B的集合是:
A={HP1,TW,SW1}
B={HP1,HP2,HP3}
集合A和集合B的交集是兩個集合共有的元素集合,A和B的并集是A和B中所有元素的集合,因此
A?B={HP1}
A?B={HP1,HP2,HP3,TW,SW1},
A和B之間的Jaccard距離為:
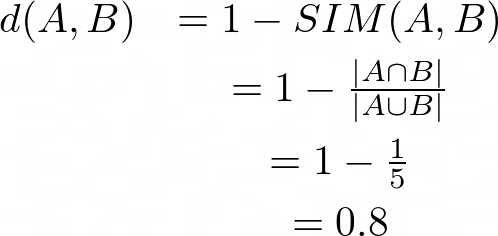
類似地,A和C之間的Jaccard距離,d(A,C)=0.5,根據這一衡量標準,觀察者A和C與觀察者A和B相比具有更多的相似性,這與對效用表的直觀分析所揭示的完全相反,因此,Jaccard距離不適合我們考慮的資料型別,
計算余弦距離:現在讓我們計算觀眾A和B之間以及觀眾A和C之間的余弦距離,為此,我們首先必須創建一個表示其評分的向量,為了簡單起見,我們假設空格等于0的等級,這是一個值得商榷的選擇,因為零分也可能代表觀眾給出的差分,對應于觀眾A、B和C的向量是:
A=[4,0,0,5,1,0,0]
B=[5,5,4,0,0,0,0]
C=[0,0,0,2,4,5,0],
A和B之間的余弦距離為:
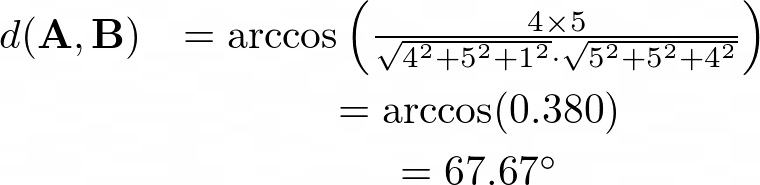
同樣,A和C之間的余弦距離為:
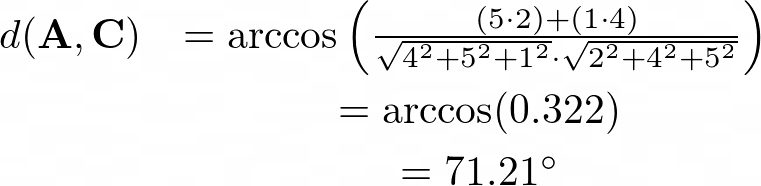
這是合理的,因為它表明A比C更接近B,
轉換評分
我們還可以通過對矩陣中的每個元素應用定義良好的規則來轉換效用矩陣中捕獲的資料,在本文中,我們將學習兩種轉換:四舍五入和標準化,
四舍五入
觀眾通常會給相似的電影提供相似的評分,例如,觀眾B對所有的哈利波特電影給予了很高的評價,而觀眾C對《星球大戰1》和《星球大戰2》給予了很高的評價,這種評分的相似性可以通過用規則將評分四舍五入來消除,例如,我們可以將規則設定為將等級3、4和5舍入為1,并將等級1和2視為空格,應用此規則后,我們的效用矩陣變成:
在評分四舍五入的情況下,對應于觀眾A和C的集合的交集為空集合,這將Jaccard相似度降低到其最小值0,并將Jaccard距離射向其最大值1,此外,對應于觀眾A和B的集合之間的Jaccard距離小于1,這使得A比C更接近B,請注意,Jaccard距離度量在使用原始用戶評分計算距離時并沒有提供對用戶行為的這種了解,用四舍五入值求余弦距離得到了同樣的結論,
標準化評分
另一種改變原始評分的方法是使其標準化,通過標準化,我們的意思是從每個評分中減去每個觀眾的平均評分,例如,讓我們為平均評分為10/3的觀眾A找到標準化的評分,因此,她的標準化評分是,
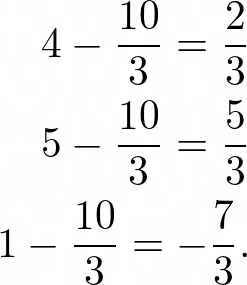
下面給出了所有值都標準化的效用矩陣,請注意,這會將較高的值轉換為正值,而將較低的值轉換為負值,

由于效用矩陣中的個別值發生了變化,我們可以期望余弦距離發生變化,但是,Jaccard距離保持不變,因為它只取決于兩個用戶對電影的評分,而不取決于給定的評分,
對于標準化值,對應于觀眾A、B和C的向量為:
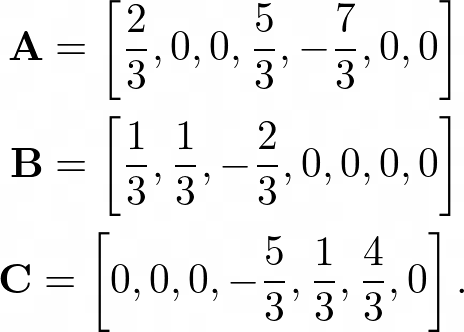
A和B以及A和C之間的余弦距離為:
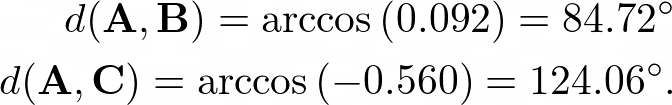
雖然標準化評分的余弦距離計算并沒有改變最初的結論(即A比C更接近B),但它確實放大了向量之間的距離,向量A和向量C似乎與標準化評分的差距特別大,盡管兩者都不是非常接近,
結論
推薦系統是互聯網經濟的核心,它們是讓我們沉迷于社交媒體、在線購物和娛樂平臺的計算機程式,推薦系統的作業是預測特定用戶可能購買或消費的內容,預測這一情況的兩種廣泛方法之一是,看看其他人——特別是那些對用戶有類似偏好的人——購買或消費了什么,這種方法的一個關鍵部分是量化用戶之間的相似性,
計算Jaccard和余弦距離是量化用戶之間相似性的兩種方法,Jaccard距離考慮了被比較的兩個用戶評分的產品數量,而不是評分本身的實際值,另一方面,余弦距離考慮的是評分的實際值,而不是兩個用戶評分的產品數量,由于計算距離的差異,Jaccard和余弦距離度量有時會導致相互沖突的預測,在某些情況下,我們可以通過根據明確的規則舍入評分來避免此類沖突,
評分也可以通過從用戶給出的每個評分中減去用戶給出的平均評分來進行轉換,這一程序稱為常態化,不影響Jaccard距離,但有放大余弦距離的趨勢,
原文鏈接:https://levelup.gitconnected.com/measuring-similarity-in-recommendation-systems-8f2aa8ad1f44
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6834.html
標籤:其他
上一篇:神經網路中的激活函式
下一篇:MNIST資料集下載及可視化