import re
from urllib import request
from io import BytesIO
import gzip
# 爬蟲目的性明確,主播人氣排行
# 在google瀏覽器中查找現在的HTML的相關資訊F12,點擊第一個選項element
# 找人數HTML資訊,小箭頭,滑鼠懸停在人數
# 需要抓取的資訊1人數2主播的名字
# 模擬HTTP請求,向服務器發送這個請求,獲取服務器回傳給我們的HTML
# 用正則運算式提取我們要的資料(名字,人氣)
# VScode中除錯代碼
class Spider():
url = 'https://www.douyu.com/g_LOL'
root_pattern = '<div class="DyListCover-content">([\s\S]*?)</div>'
# ?表示非貪婪,\s\S表示說有字符,*表示匹配0次或者無窮多次
def __fetch_content(self):
r = request.urlopen(Spider.url)
# 私有方法
# bytes
htmls = r.read()
buff = BytesIO(htmls)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
return htmls
def __analysis(self, htmls):
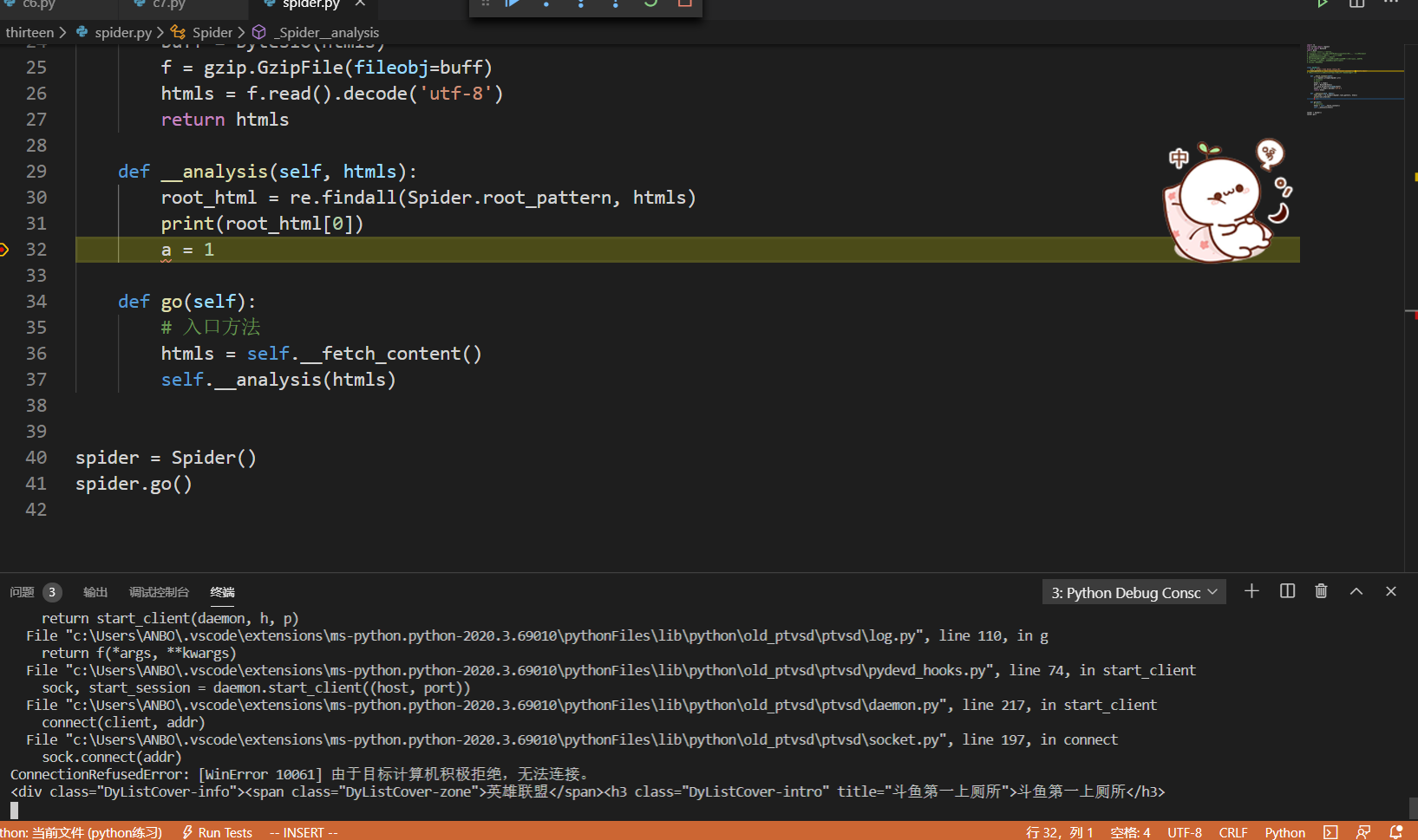
root_html = re.findall(Spider.root_pattern, htmls)
print(root_html[0])
a = 1
def go(self):
# 入口方法
htmls = self.__fetch_content()
self.__analysis(htmls)
spider = Spider()
spider.go()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/68407.html
下一篇:fortran