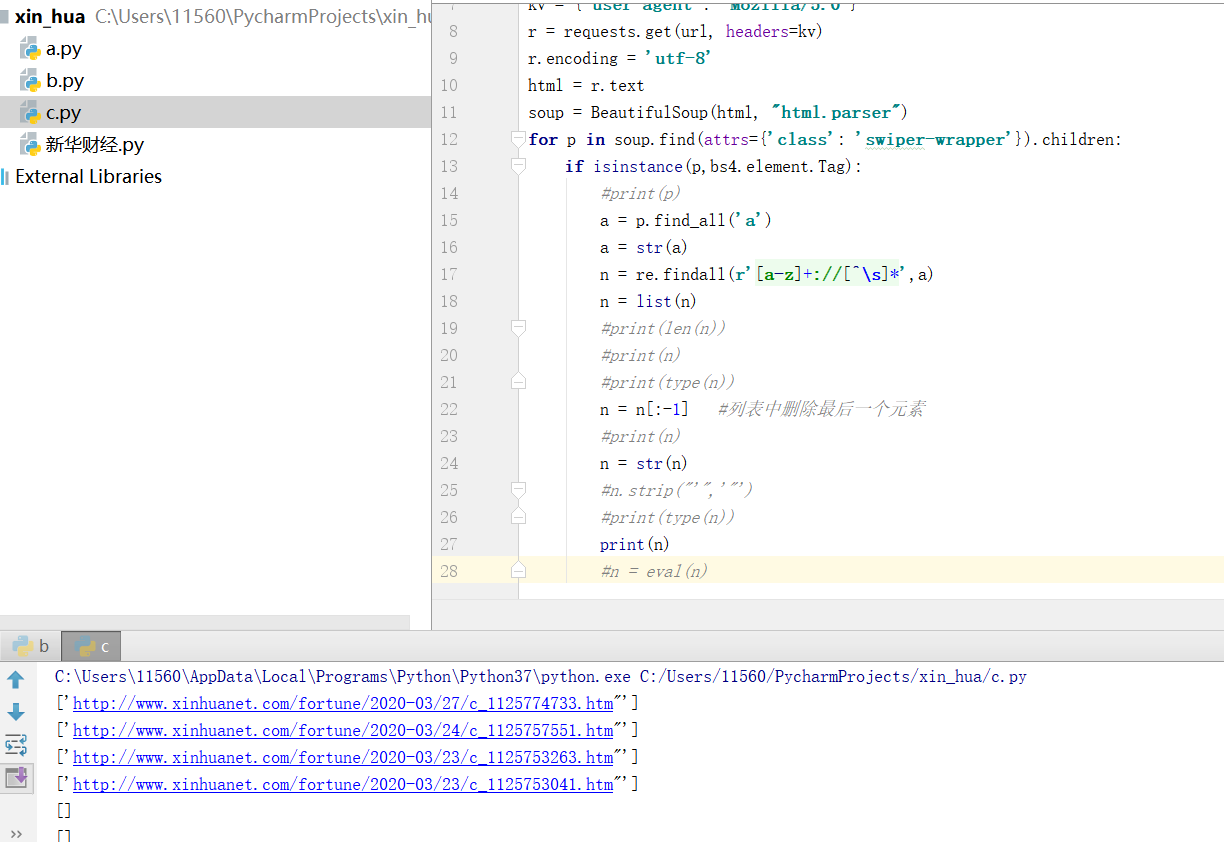
這里.find_all()方法回傳的結果,型別是<class 'list'>
我對其用字串方法時會對這七行串列都進行操作。
這樣我就沒法將后面三個帶空格的串列元素刪掉
試過也無法用eval()函式對其進行取值(我想取出其中的內容取不出來)
之后我嘗試將這個變數寫到本地檔案,操作不報錯但檔案里啥也沒寫進去
望前輩指點迷津
from bs4 import BeautifulSoup
import requests
import bs4
import re
url = "http://www.xinhuanet.com/fortune/"
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv)
r.encoding = 'utf-8'
html = r.text
soup = BeautifulSoup(html, "html.parser")
for p in soup.find(attrs={'class': 'swiper-wrapper'}).children:
if isinstance(p,bs4.element.Tag):
#print(p)
a = p.find_all('a')
a = str(a)
n = re.findall(r'[a-z]+://[^\s]*',a)
n = list(n)
#print(len(n))
#print(n)
#print(type(n))
n = n[:-1] #洗掉串列中最后一個元素
#print(n)
n = str(n)
#n.strip("'",'"')
#print(type(n))
n = n[2:62]
#print(n)
#n = n.splitlines() #回傳一個包含各行作為元素的串列
#print(type(n))
print(n)
with open("test.txt", "w", encoding='utf-8') as f:
f.write(n) # 這句話自帶檔案關閉功能,不需要再寫f.close()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/68438.html