作者|ANIRUDDHA BHANDARI
編譯|VK
來源|Analytics Vidhya
AUC-ROC曲線
你已經建立了你的機器學習模型-那么接下來呢?你需要對它進行評估,并驗證它有多好(或有多壞),這樣你就可以決定是否實作它,這時就可以引入AUC-ROC曲線了,
這個名字可能有點夸張,但它只是說我們正在計算“Receiver Characteristic Operator”(ROC)的“Area Under the Curve”(AUC),
別擔心,我們會詳細了解這些術語的含義,一切都將是小菜一碟!

現在,只需知道AUC-ROC曲線可以幫助我們可視化機器學習分類器的性能,雖然它只適用于二值分類問題,但我們將在最后看到如何擴展它來評估多類分類問題,
我們還將討論敏感性(sensitivity )和特異性(specificity )等主題,因為這些是AUC-ROC曲線背后的關鍵主題,
目錄
-
什么是敏感性和特異性?
-
預測概率
-
AUC-ROC曲線是什么?
-
AUC-ROC曲線是如何作業的?
-
Python中的AUC-ROC
-
用于多類分類的AUC-ROC
什么是敏感性和特異性?
混淆矩陣:
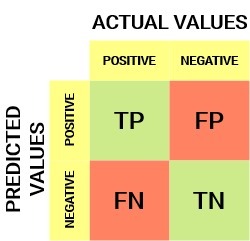
從混淆矩陣中,我們可以得到一些在前面的文章中沒有討論過的重要度量,讓我們在這里談談他們,
敏感度/真正例率/召回率
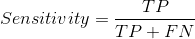
敏感度告訴我們什么比例的正例得到了正確的分類,
一個簡單的例子是確定模型正確檢測到的實際病人的比例,
假反例率
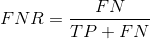
假反例率(FNR)告訴我們什么比例的正例被分類器錯誤分類,
更高的TPR和更低的FNR是可取的,因為我們希望正確地分類正類,
特異性/真反例率
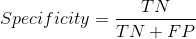
特異性告訴我們什么比例的反例類得到了正確的分類,
以敏感性為例,特異性意味著確定模型正確識別的健康人群比例,
假正例率
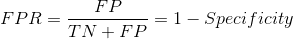
FPR告訴我們哪些負類被分類器錯誤分類,
更高的TNR和更低的FPR是可取的,因為我們想正確地分類負類,
在這些指標中,敏感性和特異性可能是最重要的,我們稍后將看到如何使用它們來構建評估指標,
但在此之前,我們先來了解一下為什么預測概率比直接預測目標類要好,
預測概率
機器學習分類模型可以直接預測資料點的實際類別或預測其屬于不同類別的概率,
后者使我們對結果有更多的控制權,我們可以確定自己的閾值來解釋分類器的結果,這更為謹慎!
為資料點設定不同的分類閾值會無意中改變模型的敏感性和特異性,
其中一個閾值可能會比其他閾值給出更好的結果,這取決于我們的目標是降低假反例還是假正例的數量,
請看下表:
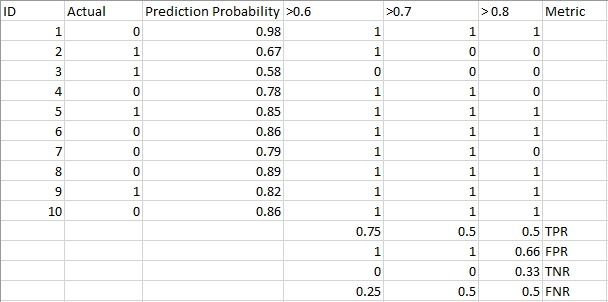
度量值隨閾值的變化而變化,我們可以生成不同的混淆矩陣,并比較上一節中討論的各種度量,
但這樣做并不明智,相反,我們所能做的是在這些度量之間生成一個圖,這樣我們就可以很容易地看到哪個閾值給了我們一個更好的結果,
AUC-ROC曲線正好解決了這個問題!
AUC-ROC曲線是什么?
ROC曲線是二值分類問題的一個評價指標,它是一個概率曲線,在不同的閾值下繪制TPR與FPR的關系圖,從本質上把“信號”與“噪聲”分開,
曲線下面積(AUC)是分類器區分類的能力的度量,用作ROC曲線的總結,
AUC越高,模型在區分正類和負類方面的性能越好,
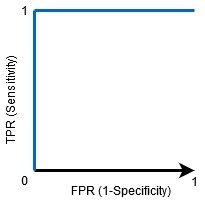
當AUC=1時,分類器能夠正確區分所有的正類點和負類點,然而,如果AUC為0,那么分類器將預測所有的否定為肯定,所有的肯定為否定,
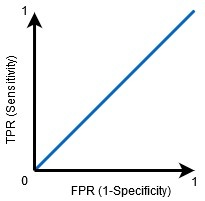
當0.5<AUC<1時,分類器很有可能區分正類值和負類值,這是因為與假反例和假正例相比,分類器能夠檢測更多的真正例和真反例,
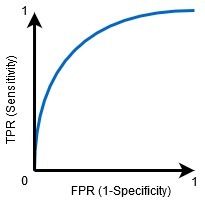
當AUC=0.5時,分類器無法區分正類點和負類點,這意味著分類器要么預測所有資料點的隨機類,要么預測常量類,
因此,分類器的AUC值越高,其區分正類和負類的能力就越好,
AUC-ROC曲線是如何作業的
在ROC曲線中,較高的X軸值表示假正例數高于真反例數,而Y軸值越高,則表示真正例數比假反例數高,
因此,閾值的選擇取決于在假正例和假反例之間進行平衡的能力,
讓我們深入一點,了解不同閾值下ROC曲線的形狀,以及特異性和敏感性的變化,
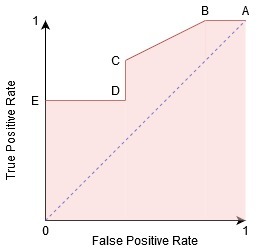
我們可以嘗試通過為每個對應于閾值的點生成混淆矩陣來理解此圖,并討論分類器的性能:
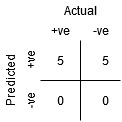
A點是敏感性最高,特異性最低的地方,這意味著所有的正類點被正確分類,所有的負類點被錯誤分類,
事實上,藍線上的任何一點都對應于真正例率等于假正例率的情況,
這條線上的所有點都對應于屬于正類的正確分類點的比例大于屬于負類的錯誤分類點的比例的情況,
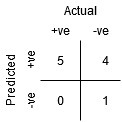
雖然B點與A點具有相同的敏感性,但具有較高的特異性,這意味著錯誤的負類點數量比上一個閾值要低,這表明此閾值比前一閾值好,
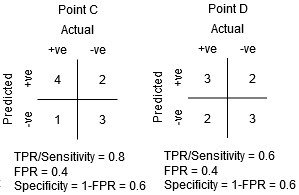
在C點和D點之間,在相同特異度下,C點的敏感性高于D點,這意味著,對于相同數量的錯誤分類的負類點,分類器預測的正類點數量更高,因此,C點的閾值優于D點,
現在,取決于我們要為分類器容忍多少錯誤的分類點,我們將在B點和C點之間進行選擇,以預測你是否可以在PUBG中擊敗我,
“錯誤的希望比恐懼更危險,”——J.R.R.托爾金

E點是特異性最高的地方,也就是說沒有假正例被模型分類,該模型能對所有的負類點進行正確的分類!如果我們的問題是給用戶提供完美的歌曲推薦,我們會選擇這一點,
按照這個邏輯,你能猜出一個完美的分類器對應的點在圖上的什么位置嗎?
對!它將位于ROC圖的左上角,對應于笛卡爾平面中的坐標(0,1),在這里,敏感性和特異性都將是最高的,分類器將正確地分類所有的正類點和負類點,
Python中的AUC-ROC曲線
現在,要么我們可以手動測驗每個閾值的敏感性和特異性,要么讓sklearn為我們做這項作業,我們選擇sklearn
讓我們使用sklearn make_classification 方法創建任意資料:
我將在此資料集上測驗兩個分類器的性能:
Sklearn有一個非常有效的方法roc_curve(),它可以在幾秒鐘內計算分類器的roc!它回傳FPR、TPR和閾值:
可以使用sklearn的roc_auc_score()方法計算AUC得分:
0.9761029411764707 0.9233769727403157
我們還可以使用matplotlib繪制這兩種演算法的ROC曲線:
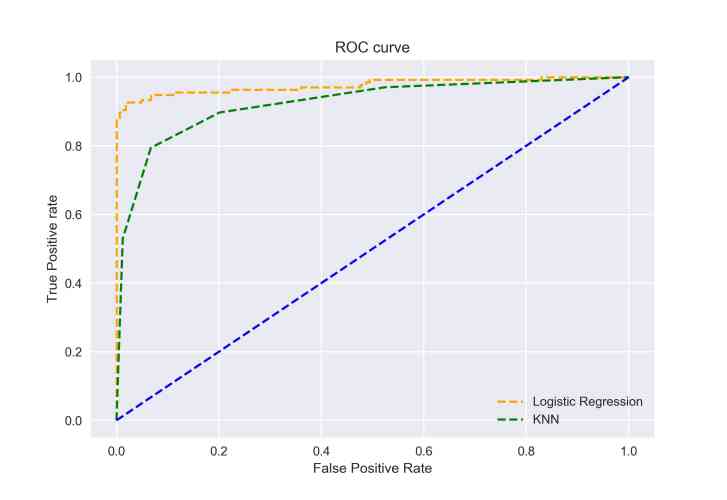
結果表明,Logistic回歸ROC曲線的AUC明顯高于KNN-ROC曲線,因此,我們可以說logistic回歸在分類資料集中的正類方面做得更好,
用于多類分類的AUC-ROC
就像我之前說過的,AUC-ROC曲線只適用于二元分類問題,但是,我們可以通過一對多技術將其擴展到多類分類問題,
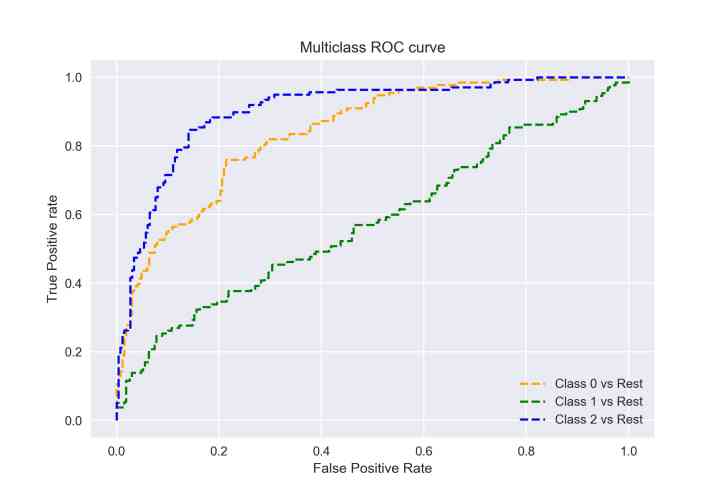
因此,如果我們有三個類0、1和2,那么class 0的ROC將如此生成,正例為類0,反例為非類0,也就是類1和類2,以此類推,
多類分類模型的ROC曲線可以確定如下:
結尾
我希望你發現本文有助于理解AUC-ROC曲線度量在衡量分類器性能方面的強大功能,你會在工業界,甚至在資料科學經常用到這個,最好熟悉一下!
原文鏈接:https://www.analyticsvidhya.com/blog/2020/06/auc-roc-curve-machine-learning/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6846.html
標籤:其他