使用C#已經有好多年頭了,然后突然有一天被問到C#Dictionary的基本實作,這讓我反思到我一直處于拿來主義,能用就好,根本沒有去考慮和學習一些底層架構,想想令人頭皮發麻,下面開始學習一些我平時用得理所當然的東西,今天先學習一下字典,Dictionary
一、Dictionary原始碼學習
Dictionary實作我們主要對照原始碼來決議,目前對照的原始碼版本是.Net Framwork4.8,原始碼地址,
這邊主要介紹Dictionary中幾個比較關鍵的類和物件,然后跟著代碼來走一遍插入、洗掉和擴容的流程,
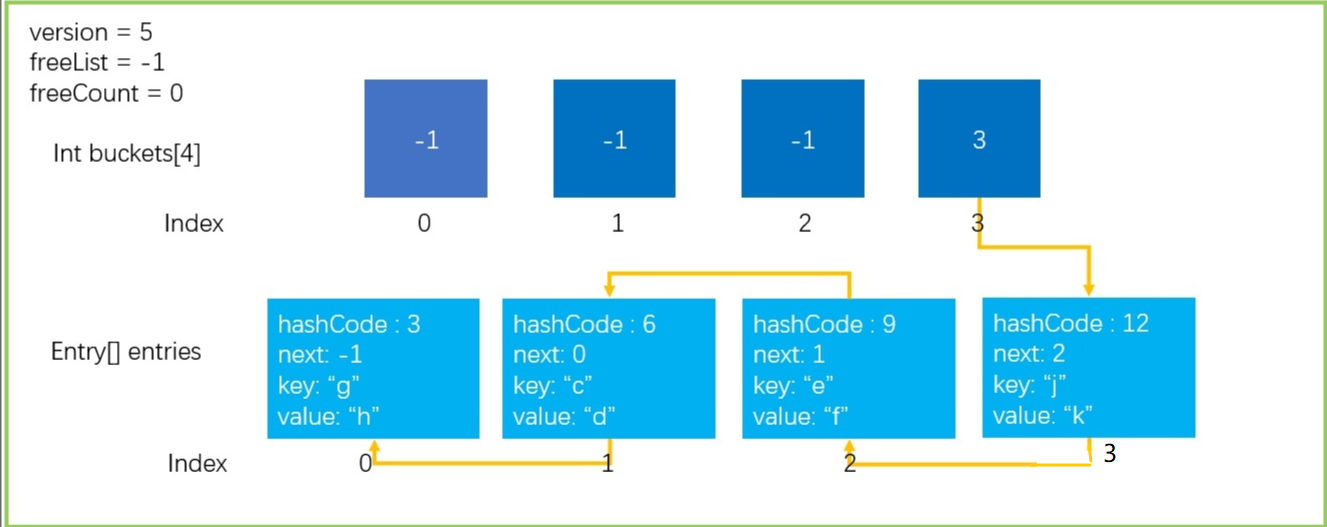
1、Entry結構體
首先,我們引入Entry這樣一個結構體,它的定義如下面代碼所示,這是Dictionary中存放資料的最小單位,呼叫Add(Key,Value)方法添加的元素都會被封裝在這樣的一個結構體中,
1 private struct Entry
2 {
3 public int hashCode; // Lower 31 bits of hash code, -1 if unused
4 public int next; // Index of next entry, -1 if last
5 public TKey key; // Key of entry
6 public TValue value; // Value of entry
7 }
2、其他關鍵私有變數
1 private int[] buckets; // Hash桶
2 private Entry[] entries; // Entry陣列,存放元素
3 private int count; // 當前entries的index位置
4 private int version; // 當前版本,防止迭代程序中集合被更改
5 private int freeList; // 被洗掉Entry在entries中的下標index,這個位置是空閑的
6 private int freeCount; // 有多少個被洗掉的Entry,有多少個空閑的位置
7 private IEqualityComparer<TKey> comparer; // 比較器
8 private KeyCollection keys; // 存放Key的集合
9 private ValueCollection values; // 存放Value的集合
3、Dictionary的構造
1 private void Initialize(int capacity)
2 {
3 int prime = HashHelpers.GetPrime(capacity);
4 this.buckets = new int[prime];
5 for (int i = 0; i < this.buckets.Length; i++)
6 {
7 this.buckets[i] = -1;
8 }
9 this.entries = new Entry<TKey, TValue>[prime];
10 this.freeList = -1;
11 }
我們看到,Dictionary在構造的時候做了以下幾件事:
1、初始化一個this.buchkets=new int[prime]
2、初始化一個this.entries=new Entry<TKey,TValue>[prime]
3、Bucket和entries的容量都為大于字典容量的一個最小的質數
其中this.buckets主要用來進行Hash碰撞,this.entries用來存盤字典的內容,并且標識下一個元素的位置,
4、Dictionary——Add操作
我們以Dictionary<int,string>為例,來展示一下Dictinoary如何添加元素:
首先,我們構造一個,容量為6:
Dictionary<int, string> test = new Dictionary<int, string>(6);

Test.Add(4,"4")
根據Hash演算法:4.GetHashCode()%7=4,因此碰撞到buckets中下表為4的槽上,此時由于Count為0,因此元素放在Entries中第0個元素上,添加后,Count變為1
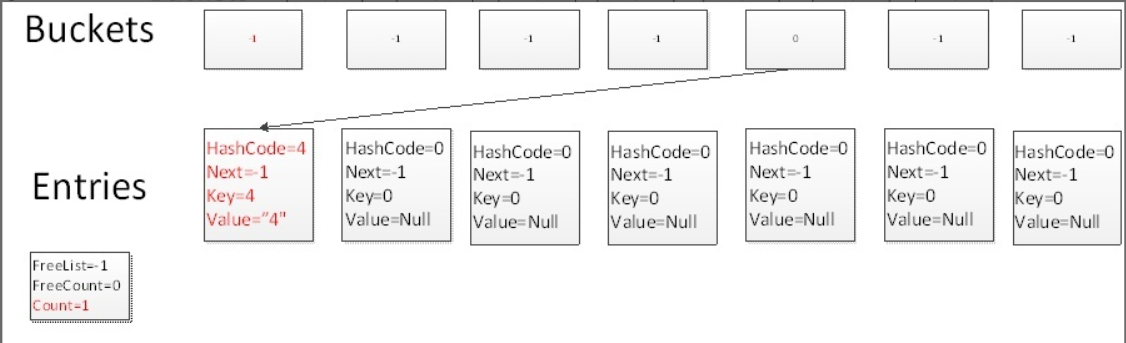
Test.Add(11,"11")
根據Hash演算法,11.GetHashCode()%7=4,因此再次碰撞到Buckets中下標為4的槽上,由于此槽上的值已經不是-1,此時Count=1,因此把這個新加的元素放到entries中下標為1的陣列中,并且讓Buckets槽指向下表為1的entries中,下標為1的entry之下下表為0的entries,
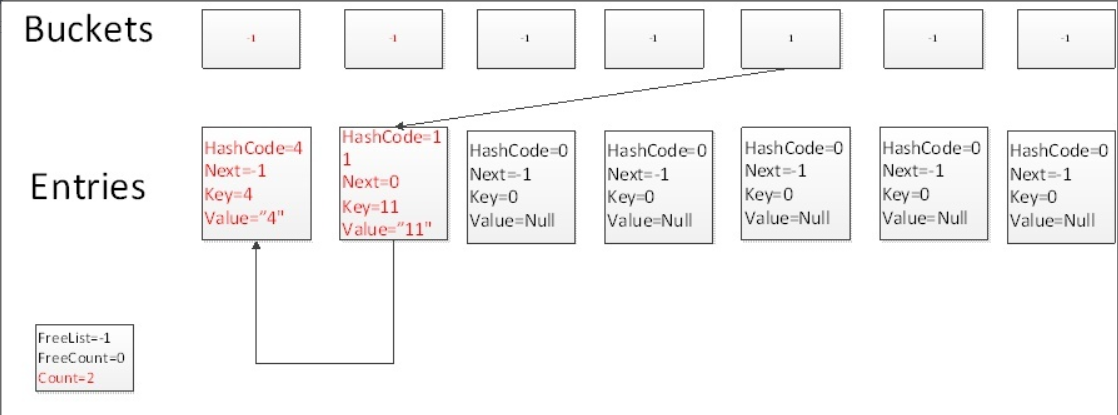
Test.Add(18,"18")
Test.Add(19,"19")
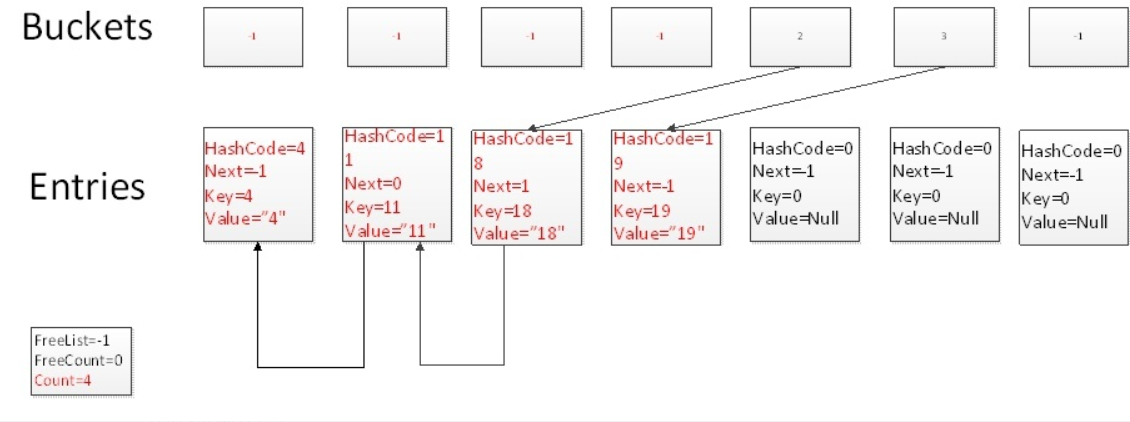
5、Dictionary——Remove操作
Test.Remove(4)
我們洗掉元素時,通過一次碰撞,并且沿著鏈表尋找3次,找到key為4的元素所在的位置,洗掉當前元素,并且把FreeList的位置指向當前洗掉元素的位置,FreeCount置為1,

洗掉的資料會形成一個FreeList的鏈表,添加資料的時候,優先向FreeList鏈表中添加資料,FreeList為空則按照count一次排序,
6、Dictionary——Resize操作(擴容)
有細心的小伙伴可能看過Add操作后就想問了,buckets、entries不就是兩個陣列么,那萬一陣列放滿了怎么辦?接下來就是我要介紹的Resize(擴容)這樣一種操作,對我們的buckets、entries進行擴容,
6.1 擴容操作的觸發條件
首先我們需要直到在什么情況下,會發生擴容操作:
第一種情況自然就是陣列已經滿了,沒有辦法繼續存放新的元素,如下圖所示,
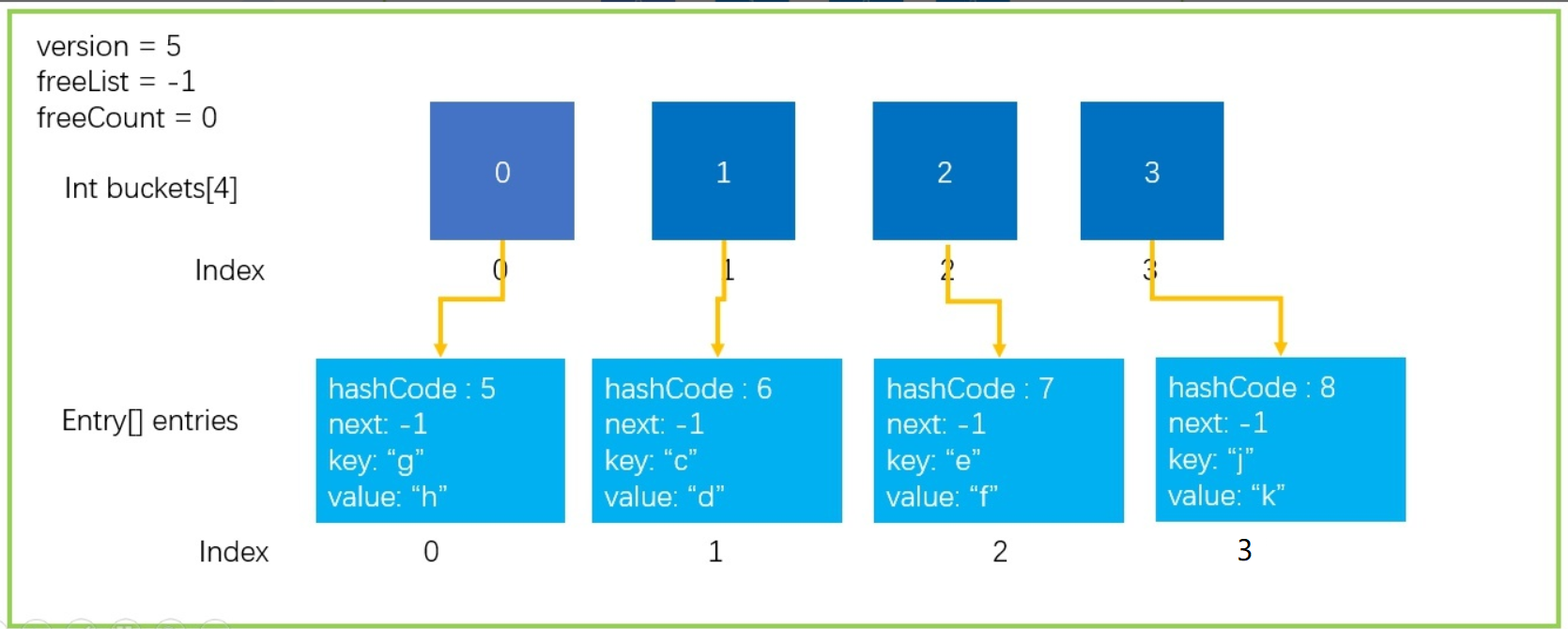
第二種,Dictionary中發生的碰撞次數太多,會嚴重影響性能,也會出發擴容操作,
Hash運算會不可避免的產生沖突,Dictionary中使用拉鏈發來解決沖突的問題,但是,大家看下圖中的這種情況,所有的元素都剛好落在buckets[3]上面,結果就導致了時間復雜度O(n),查找性能會下降:
6.2 擴容操作如何進行
為了給大家演示清楚,模擬了以下這種資料結構,大小為2的Dictionary,假設碰撞的閾值為2;現在出發Hash碰撞擴容,
1、申請兩倍于現在大小的buckets、entries
2、將現有的元素拷貝到新的entries
3、如果時Hash碰撞擴容,使用新HashCode函式重新計算Hash值
4、對entries每個元素bucket=newEntries[i].hashCode%newSize確定新buckets位置
5、重建hash鏈,newEntries[i].next=buckets[bucket];buckets[bucket]=i;
關注點
對于Dictionary的實作原理,其中有兩個關鍵的演算法,1、Hash演算法,2、用于對應Hash碰撞沖突解決演算法,
二、Hash演算法
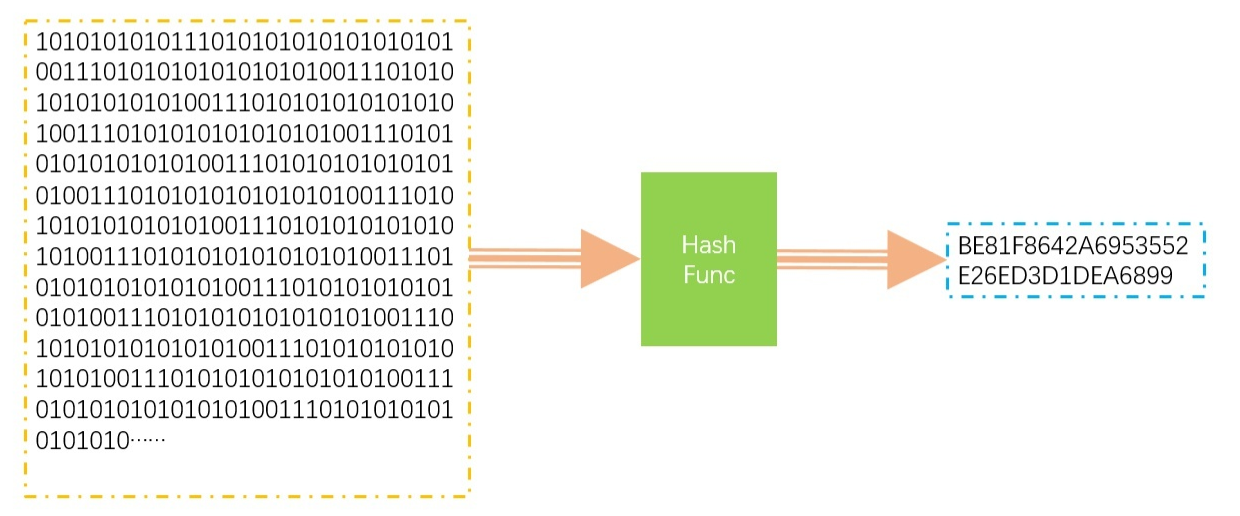
Hash演算法是一種術宇摘要演算法,它將能不定長度的二進制資料集給映射到一個較短的二進制長度資料集,
實作了Hash演算法的函式我們叫它Hash函式,Hash函式有以下幾點特征,
1、相同的資料進行Hash運算,得到的結果一定是相同的,HashFunc(key1)==HashFunc(key1)
2、不同的資料進行Hash運算,其結果也可能會相同,(Hash會產生碰撞),key1!=key2=>HashFunc(key1)==HashFunc(key2),
3、Hash運算是不可逆的,不能由key獲取原始的資料,key1=>hashCode但是hashCode==>key1
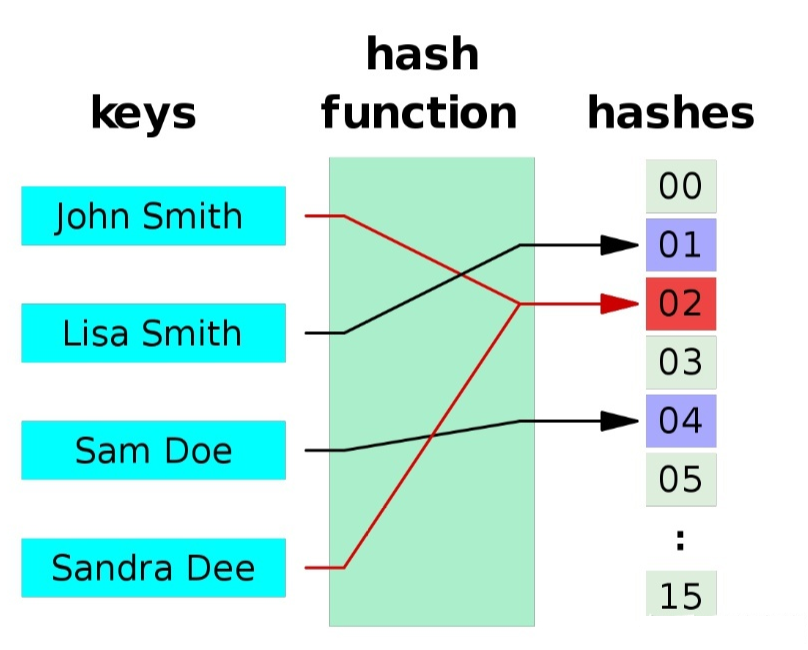
關于Hash碰撞下圖很清晰的就解釋了,可從圖中得知Sandra Dee 和 John Smith 通過hash運算后,落到了02位置,產生了碰撞和沖突,
常見的構造Hash函式的演算法有以下幾種,
1、直接尋址法:取keyword或者keyword的某個線性函式值為散列地址,即H(key)=key或者H(key)=a·key+b,當中a和b為常數(這樣的散列函式叫做自身函式),這個的應用就是,比如我們世界地圖的掩碼,直接用坐標x*1000+坐標y,得到key,
2、數字分析法:找出數字的規律,盡可能利用這些資料來構造沖突幾率較低的散列地址,分析一組資料,比方一組員工的出生年月日,這時,我們發現出生年月日的前幾位數字大體相同,這種話,出現沖突的幾率就會非常大,可是我們發現年月日的后幾位表示月份和詳細日期的數字區別非常大,假設用后面的數字來構造散列地址,則沖突幾率就會明顯減少,
3、平方取中法:取keyword平方后的中間幾位作為散列地址,
4、折疊法:將keyword切割成位數同樣的幾部分,最后一部分分數能夠不同,然后取這及部分的疊加和(去除進位)作為散列地址,
5、亂數法:選擇一隨機函式,取keyword的隨機值作為散列地址,通常適用于keyword長度不同的場合,
6、除留余數法:取keyword被某個不大于散串列表長m的數p除后所得的余數為散列地址,即H(key)=key MOP p , p<=m,不僅能夠對keyword直接取模,也可在折疊、平方取中等運算后取模,對p的選擇非常重要,一般取素數或m,若p選的不好,容易產生碰撞,
三、Hash桶演算法
說到Hash演算法大家就會想到Hash表,一個Key通過Hash函式運算后可快速的得到hashCode,通過hashCode的映射可以直接Get到Value,但是hashCode一般取值都是非常大的,經常是2^32以上,不可能對每個hashCode都指定一個映射,因為這樣的一個問題,所以人們就將生成的HashCode以分段的形式來映射,把每一段稱之為一個Bucket(桶),一般常見的Hash桶就是直接對結果取余,
假設將生成的hashCode可能取值有2&32個,然后將其切分成一段一段,使用8個桶來映射,那么就可以通過bucketIndex=HashFunc(key1)%8 這樣一個演算法來確定這個hashCode映射到具體哪個桶中,
Dictionary就是這用的哈希桶演算法,
int hashCode =comparer.GetHashCode(key)&0x7FFFFFFF;
int targetBucket = hashCode %buckets.Length;
四、Hash碰撞沖突解決演算法
對于一個hash演算法,不可避免地會產生沖突,那么產生沖突以后如何處理,是一個很關鍵的地方,目前常見的沖突解決演算法有拉鏈法(Dictionary實作采用的)、開放定址法、再Hash法、公共溢位磁區法,
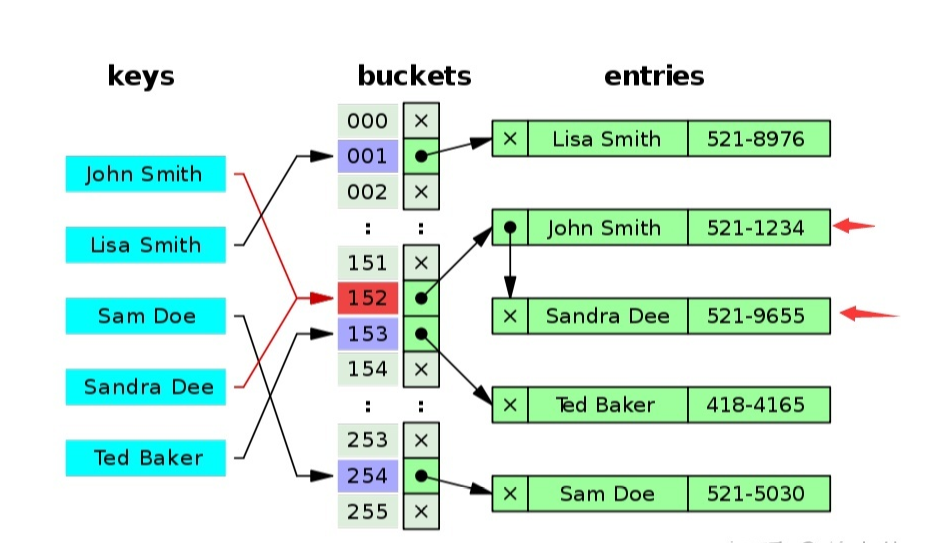
1、拉鏈法(開散列):將產生沖突的元素建立一個單鏈表,并將頭指標地址存盤之Hash表對應桶的位置,這樣定位到Hash表桶的位置后通過遍歷單鏈表的形式來查找元素,
2、開放定址法(閉散列):當發生哈希沖突時,如果哈希表未被裝滿,說明再哈希表中必然還有空位置,那么可以把key存放到沖突位置中的“下一個”空位置中去,
3、再Hash法:顧名思義就是將key使用其他的Hash函式再次Hash,直到找到不沖突的位置為止,
拉鏈法:
開放地址法:
假設現在有一個關鍵碼集合(1、4、5、6、7、9),哈希結構的容量為10,哈希函式為Hash(key)=key%10,將所有關鍵碼插入到該哈希結構中,如圖:

假如仙子啊有一個關鍵碼24要插入該結構中,使用哈希函式求得哈希地址為24,但是該地址已經存放了元素,此時發生哈希沖突,
線性探測:從發生哈希沖突的位置開始,一次向后探測,直到找到下一個空位置為止,例如上面的地址,插入關鍵碼24時,進行線性探測,插入后如下圖:

限制:
1、用該方法需要關鍵碼必須為整形才能被模,所以我們需要實作將非整形轉化為整形,
2、模的數值最好為素數,需要我們創建一個素數表,
3、增容問題,
好了,關于Dictionary的相關知識,就先介紹到這里了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/69611.html
標籤:其他