原本今天是想要介紹堆排序的,雖然堆排序需要用到樹,但基本上也就只需要用一用樹的概念,而且還只需要完全二叉樹,實際的實作也是用陣列的,所以原本想先把主要的排序演算法講完,只簡單的說一下樹的概念,但在寫的程序中才發現,雖然是只用了一下樹的概念,但要是樹的概念沒講明白的話,其實不太好理解,所以決定先介紹一下基本的資料結構,然后下一篇文章再介紹堆排序,讀書人的事,怎么能叫鴿呢?這是戰略調整,戰略調整懂不懂?我給你說,上古大儒圖靈說過asdfghjkl!/.,;''
不鴿了不鴿了,下次一定,
鏈表
鏈表是一種非常非常非常重要的資料結構,與陣列有很多相似性,例如其中的各物件均按線性順序排列,他們最重要的區別在于,陣列是一種靜態的集合,鏈表則是一個動態的集合,我們用下圖來形象地說明兩者的區別:
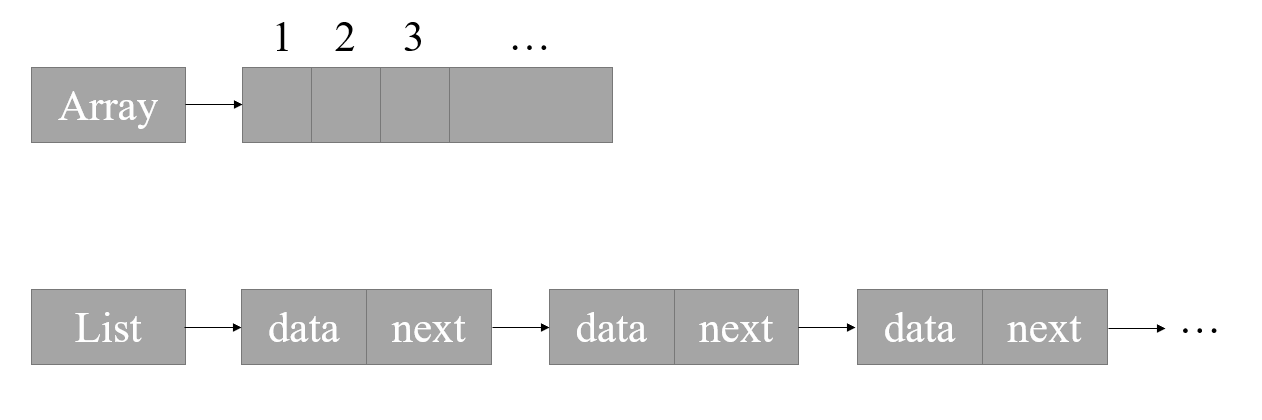
上圖分別是陣列與單向鏈表的示意圖,陣列在使用前需要宣告好需要使用的空間大小,宣告后空間大小無法變化,資料存盤是連續的,插入洗掉需要移動后面所有元素,但可以使用下標尋址;鏈表則正好與之相反,使用前無需宣告需要使用的空間,使用時可根據實際情況增刪資料個數(使用空間也隨之變化),資料存盤不連續,插入洗掉效率極高,但不可用下標尋址,
細心的同學可能發現,為什么上圖中 Array 和 List 都有箭頭指著后面的空間呢?是的,無論是陣列還是鏈表,他們本質上都是指標,上圖中所有箭頭都是指標的意思,例如當你使用 int array[20] 宣告了一個陣列時,后面所使用的 array 本質上都是一個指標,你既可以使用 array[1] 來獲取第二個資料,也可以使用 *(array + 1) 來達到同樣的效果,
那么鏈表的結構是什么樣的呢?

如上圖所示,一個鏈表一般分為兩個部分,一是指向串列第一個節點的 List ,一般用于指代串列,類似于陣列中陣列名的作用;另一個是串列內部真正儲存資料的節點 Node,
為什么需要分為兩個部分?請讀者們回顧一下我們上文所說,這種設計本質上是在模仿陣列的設計,比如說我現在告訴小明我定義了兩個陣列,分別叫做 array1 和 array2 ,如果他需要使用陣列1的第3個元素,那么只需要使用 array1[2] 即可,如果沒有這樣一個標志符,難道我們用 [2] 來選取這個元素嗎?那如果我要使用陣列2的第3個元素又該怎么辦呢?當然這其實只是一個小問題,理論上來說我們也可以用其他手段來解決他,但單獨定義一個頭部有另外一個更為重要的原因,我們可以在頭部 List 儲存整個串列的屬性,例如串列元素個數,是否有序等等,當我們想要知道一個串列的元素個數時,只需要從頭部直接獲取相應的資訊即可,而不用每次都掃描一遍整個串列再回傳結果,當然你說我可以把這個資訊寫在 Node 里呀?我現在只需要添加一個節點,就可以儲存整個串列的主要資訊,你卻要把他復制到每一個 Node 里去?你以為你是區塊鏈啊?還要分布式存盤?難道你還怕我 List 節點會騙你不成?要不少于51%的節點都說我們長度為10你才相信我長度真為10?
上文我們提到的鏈表是最為常用的鏈表,稱為雙向鏈表,其實意思也很簡單,鏈表的搜索方向有兩個,既可以向前搜索(指向上一個節點的 prev 指標),也可以向后搜索(指向下一個節點的 next 指標),首節點因為前面沒有其余節點,所以首節點的 prev 指標為 NULL,同理尾結點的 next 指標也為 NULL,與之相似的有單向鏈表:只有 next 或 prev 指標,只能沿著一個方向搜索,回圈鏈表,首節點的 prev 指標指向尾結點,尾結點的 next 指標指向首節點(而不是像雙向鏈表里為 NULL),只要你愿意,你可以定義出各種奇奇怪怪的鏈表,理論上來說,后面我們講到的其他資料結構其實都是一些被廣泛使用的奇怪鏈表,
下文中鏈表的完整代碼可以在我的github上找到,
鏈表的 Node 節點如下定義:
// 串列節點
typedef struct ListNode{
int data;
struct ListNode* prev;
struct ListNode* next;
}ListNode;
鏈表的 List 如下定義:
// 串列
typedef struct List{
struct ListNode* head;
int length;
}List;
初始化一個串列:
// 初始化一個串列,不包含任何資料
List* ListInit(){
List* list = (List*)malloc(sizeof(List));
list->head = NULL;
list->length = 0;
return list;
}
從鏈表中搜索并回傳指定節點:
// 在list串列中搜索data為number_to_search的第一個節點,并回傳此節點
ListNode* ListSearch(List* list, int number_to_search){
ListNode* node = list->head;
while(node != NULL && node->data != number_to_search){
node = node->next;
}
return node;
}
向鏈表插入新節點:
// 新建一個data為number_to_add的節點,并將其添加至list串列頭部
int ListAdd(List* list, int number_to_add){
// 新建節點
ListNode* node_to_add = (ListNode*)malloc(sizeof(ListNode));
node_to_add->data = https://www.cnblogs.com/AlbertShen99/p/number_to_add;
node_to_add->next = list->head;
node_to_add->prev = NULL;
// 將新節點插入至串列頭部
if(list->head != NULL){
list->head->prev = node_to_add;
}
list->head = node_to_add;
list->length ++;
return 0;
}
洗掉鏈表中的指定節點:
// 從list串列中洗掉node節點,并free掉node節點
int ListDelete(List* list, ListNode* node){
if(node->prev == NULL){
list->head = node->next;
} else{
node->prev->next = node->next;
}
if(node->next != NULL){
node->next->prev = node->prev;
}
free(node);
list->length --;
return 0;
}
大家可以看到在代碼中,很多代碼都是在判斷邊界條件,寫著實在是不方便,那有沒有什么辦法不需要進行繁瑣的邊界判斷呢?當然有,不知道同學們有沒有回想起我們上文所說的回圈鏈表?沒錯,我們將鏈表頭部和尾部指向 NULL 的指標全部指向一個 Node 節點,我們不妨將其稱為 Nil 節點,此節點與其他 Node 節點采用完全一樣的結構,Nil 的 prev 指向尾結點,next 指向首節點,這樣就無需判斷邊界條件了,這種方式的具體實作就留給各位讀者了,
堆疊和佇列
堆疊和佇列是一種動態集合,雖然操作簡單,但卻十分有效,堆疊采用后進先出(last-in,,first-out,LIFO,這名字真的體現了一種淳樸感,哪像現在各種東西吹得天花亂墜)的策略,即字面意思,最后進入此集合的元素會被首先推出,例如我們平時使用的文本編輯器的撤銷功能,第一個撤銷的操作是你最后進行的那一個操作,這就是一個典型的堆疊的應用,佇列正好與堆疊相反,采用先進先出(first-in,first-out,FIFO)帶策略,最先進入佇列的元素會被首先推出,例如平時生活中的排隊,先開始排隊的人先排到,
堆疊和佇列的操作也非常類似,都包含插入(堆疊中稱為 PUSH、入堆疊,佇列中稱為 ENQUEUE、入隊),洗掉(堆疊中稱為 POP、出堆疊,佇列中稱為 DEQUEUE,出隊),
堆疊
隊堆疊和佇列有了一個初步的認識后,我們來詳細介紹一下堆疊,堆疊既可以用陣列實作,也可以使用鏈表實作,為了講解簡單,我們就使用陣列來實作(其實使用鏈表實作也是一樣的道理,幾乎沒有任何區別),
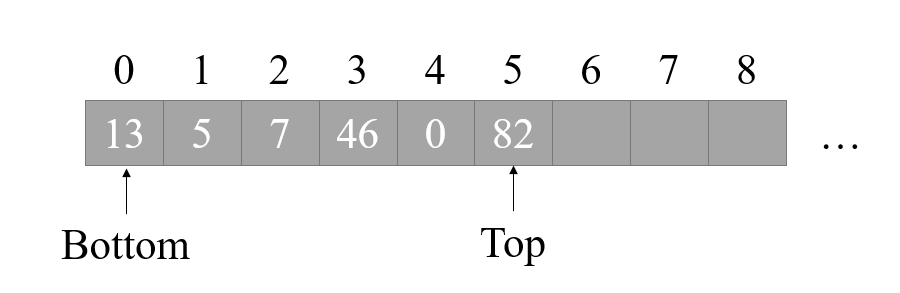
上圖就是一個堆疊的示意圖,一個堆疊包含兩個指標,分別是堆疊底指標 Bottom,堆疊頂指標 Top,每次我們進行 PUSH操作時,將 Top 指標加1,然后將資料復制到現在 Top 指標所指位置,如下圖所示:
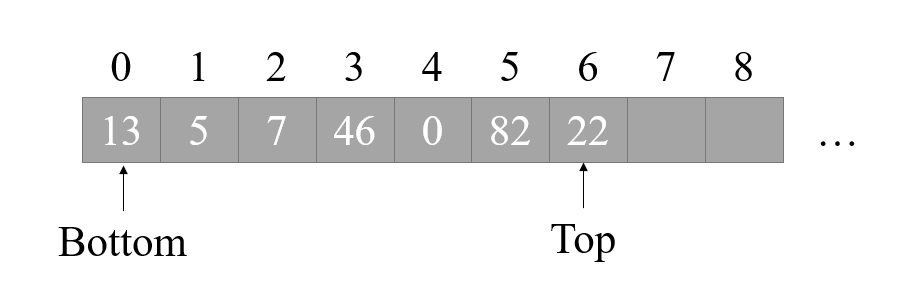
出堆疊則是此程序的逆程序,將 Top 指標減一,并回傳資料即可,
堆疊最重要的就是 PUSH 和 POP 操作,那看起來沒 Bottom 指標什么事呀?其實不然,Bottom 指標最重要的作用是標記這是堆疊開始的地方,同時也可以幫助我們判斷堆疊是否為空,并防止出堆疊時越界等問題,
同時我們也注意到出堆疊時我們只講 Top 指標減一了,可資料還在堆疊里面呀?其實無需擔心,一段空間內是否有資料,不是看里面是否真的有資料,而是根據你的解釋來判斷,計算機的資料本質上都是 0-1 串,所以其實整個計算機從拼裝好那一刻,他的空間就一直是“滿”的——因為一個 bit 不是高電平就是低電平,也就意味著不是 1 就是 0,當你在計算機里洗掉檔案時,是真的把一份檔案的資料抹去了嗎?不,只是作業系統在那做了一個標記,告訴其他程式:這些不是有用的資料,如果你們需要空間,可以直接使用這些地方,這正是誤刪檔案后,進行資料恢復的原理——只要這段空間還沒有被寫入其他資料,那么我只需要再將其標記回來,告訴大家這個地方有一個檔案,此時檔案就成功恢復了(當然還伴隨有一些其他的細節操作,比如修改檔案索引等等),所以同理,出堆疊時我們只需將 Top 指標減一即可,因為此時我們的解釋為,下標大于 Top 指標的都不屬于堆疊內的資料,再說了,你又有什么方法將這段資料抹去呢?難道將其賦值為 0 嗎?如果我本身就出堆疊了一個 0 呢?
下文中堆疊的完整代碼可以在我的github上找到,
堆疊的定義如下:
// 定義堆疊
typedef struct Stack{
int* array;
int top;
int length;
}Stack;
堆疊的初始化:
// 初始化堆疊
Stack* StackInit(int stack_length){
Stack* stack = (Stack*)malloc(sizeof(Stack));
stack->array = (int*)malloc(sizeof(int) * stack_length);
stack->top = -1;
stack->length = stack_length;
return stack;
}
常用的堆疊輔助函式:
// 判斷堆疊是否已滿
int StackIsFull(Stack* stack){
return (stack->top >= (stack->length - 1));
}
// 判斷堆疊是否為空
int StackIsEmpty(Stack* stack){
return (stack->top < 0);
}
壓堆疊操作:
// 壓堆疊
int StackPush(Stack* stack, int number_to_push){
if(StackIsFull(stack)){
return -1;
} else{
stack->top ++;
stack->array[stack->top] = number_to_push;
return 0;
}
}
出堆疊操作:
// 出堆疊
int StackPop(Stack* stack){
stack->top --;
return stack->array[stack->top + 1];
}
對于上述代碼,我們需要注意,由于C語言本身的限制,所以在出堆疊以前需要使用者自行呼叫 StackIsEmpty() 函式,在保證堆疊不為空的情況下呼叫 StackPop() 出堆疊,否則會出現越界造成不可預測的錯誤,但如果使用一些有拋出例外功能的高級語言,如 Java,則可以在堆疊空但用戶仍然進行 Pop 操作時拋出例外,以此強行避免不熟練的使用者的錯誤操作,
題外話:其實我上面的代碼寫的不是很符合C語言的規范,如果沒有特殊情況,C語言函式的回傳值都是用于判斷函式執行效果的,例如 return 0 表示操作正常,return -1 表示溢位,return -2 表示空間不足申請失敗等,資料的傳遞需要全部使用引數實作(例如傳入的資料使用普通變數,計算完成回傳的資料使用指標等),例如C語言中最簡單的輸入輸出函式 scanf() printf() 等,因為是示例代碼,所以這些細節地方我沒有太注意,
佇列
同理,佇列也既可以使用鏈表實作,也可以使用陣列實作,我們也使用陣列舉例,佇列與堆疊不同的是,佇列插入資料時,插入至 tail 指標所指位置,然后將 tail 指標加一,推出資料時將 head 指標加一,然后回傳原本 head 指標所指位置的資料,
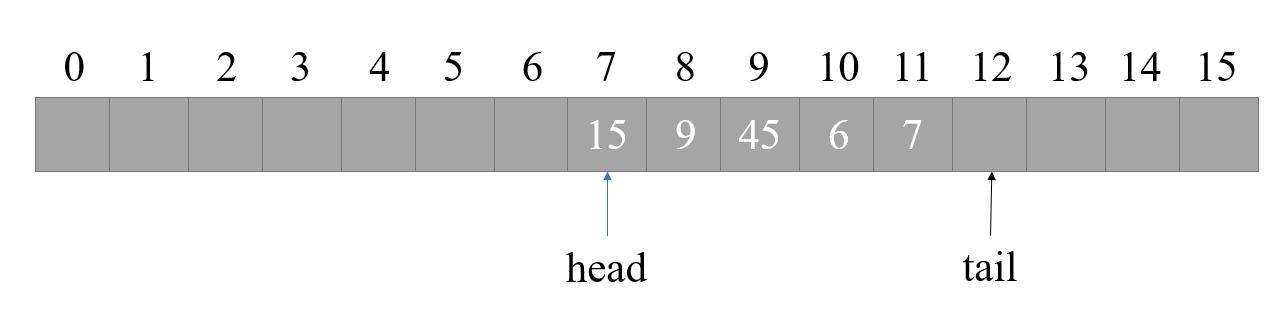
佇列與鏈表不同,設計堆疊時,我們必定是從下標為0的位置開始使用,所以陣列有多大空間,堆疊在任何時候都能使用這么大的空間,但佇列由于是先進先出,如果進行了多次操作以后,例如原本定義的陣列長度為10,我們進行了5次出隊以后,head 指標講指向下標為5的位置,難道前面的空間我們就不能再使用了嗎?當然不是,此時我們可以采用一種被稱為回圈陣列的設計:當超出了陣列下標上限時,將從下標0重新開始增加,聽著非常高大上的樣子,其實實作起來非常簡單:正常情況下,下標增加時只需簡單的進行 + 操作,而在回圈陣列中,每次 + 操作以后再將新的值對陣列長度取余,這樣當下標超過陣列長度時,將會因為被取余而等同于回到陣列下標 0 處重新增加,如果沒有理解這一段話,大家可以閱讀下文入隊函式中的操作,
佇列的完整代碼在我的github上可以看到,
佇列定義:
// 佇列定義
typedef struct Queue{
int* array;
int length;
int head;
int tail;
}Queue;
佇列初始化:
// 初始化
Queue* QueueInit(int queue_length){
Queue* queue = (Queue*)malloc(sizeof(Queue));
queue->array = (int*)malloc(sizeof(int) * (queue_length + 1));
queue->head = 0;
queue->tail = 0;
queue->length = queue_length + 1;
return queue;
}
請注意,在代碼實作中,我們申請的陣列長度比佇列長度大 1,請讀者們回顧我們上文中佇列實作的示意圖,佇列 head 指標所指位置是隊首元素,佇列 tail 指標所指位置是隊尾元素下標 + 1,如果我們申請的陣列長度與佇列長度相同,請讀者們設想一下,佇列為空和佇列滿時,head 指標和 tail 指標指向的下標是否都是相同的?這樣一來我們是無法判斷出 head == tail 時,究竟是佇列為空,還是佇列已滿,當然我們也可以利用其它標記,來使得我們可以在不額外增加長度的情況下解決這個問題,但這樣勢必會使整個問題復雜化,判斷流程過多,不僅容易出錯,運行效率也降低了,
常用佇列輔助函式:
// 判斷佇列是否已滿
int QueueIsFull(Queue* queue){
return (((queue->tail + 1) % queue->length) == queue->head);
}
// 判斷佇列是否為空
int QueueIsEmpty(Queue* queue){
return (queue->head == queue->tail);
}
入隊:
// 入隊
int QueueEnqueue(Queue* queue, int number_to_enqueue){
if(QueueIsFull(queue)){
return -1;
}
queue->array[queue->tail] = number_to_enqueue;
queue->tail = (queue->tail + 1) % queue->length;
return 0;
}
出隊:
// 出隊
int QueueDequeue(Queue* queue){
int return_value = https://www.cnblogs.com/AlbertShen99/p/queue->array[queue->head];
queue->head = (queue->head + 1) % queue->length;
return return_value;
}
有根樹
我們上文介紹的鏈表幾乎可以實作所有的資料結構,包括樹,
由于樹這個家族過于龐大,不可能在一篇文章中講解完成,所以我們將僅僅簡單地介紹一下樹的概念,方便我們后續的學習,并不實際在代碼層面實作,我們將在學習更加深入后,在合適的時間對樹這個家族進行詳細的介紹并在代碼層面實作,
一個樹節點通常包含三個部分,資料,父節點指標,子節點指標,我們首先以最簡單的二叉樹為例進行介紹,下文的介紹中,為了突出主要問題,所有的圖示中都將省略樹節點的資料部分,
二叉樹
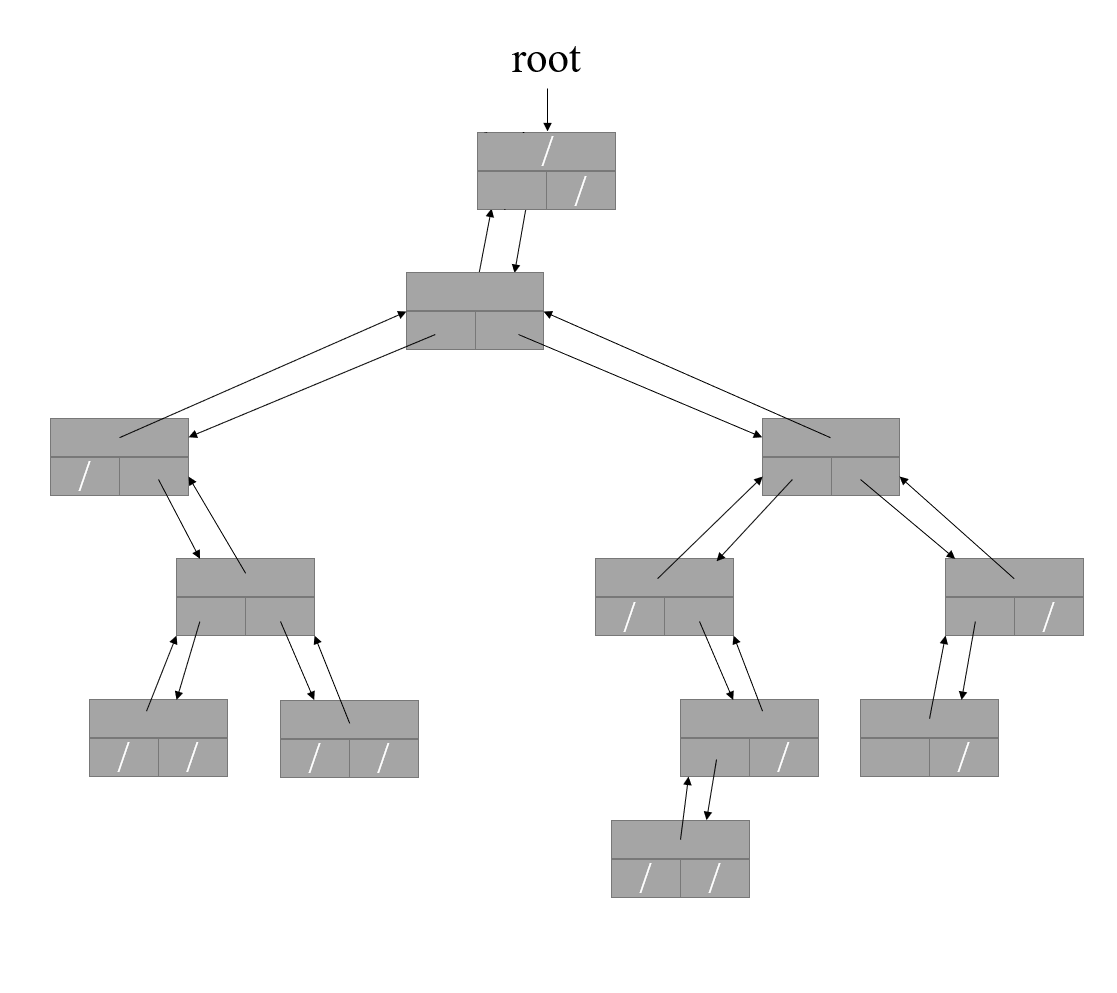
如上圖,這是一個二叉樹的示意圖,最上面的那個節點稱為樹根,這也是我們為什么將其稱為有根樹,由于版面有限,我們在圖中省略了每個節點的資料部分,一個二叉樹的每個節點包含一個父節點指標和兩個子節點指標(分別稱為左孩子和右孩子),如果節點沒有父節點(這種情況只會出現在樹根節點),那么其父節點指標為 NULL,如果沒有左孩子,則左孩子指標為 NULL,當沒有右孩子時同理,這樣的一種資料結構被我們形象地稱為樹,不過和自然界中的樹不一樣,我們的樹一般而言是倒著的,最上面的是跟節點,最下面的是葉子節點,
分支無限制的有根樹
二叉樹是我們平時使用頻率最高,也是最簡單的樹,那么相對應的就會有多叉樹,那么我們應該如何表示多叉樹呢?難道向二叉樹一樣,有幾個孩子節點就有幾個孩子指標?當然這也是一種實作方式,但不太合理——二叉樹的使用頻率非常高,為其單獨設計一種結構很合理,但除了二叉樹以外的其他樹并沒有什么是非常常用的,不同的程式之間的樹結構幾乎沒有通用性,而且,如果我說我需要一個 100 萬叉樹,難道你需要在代碼里把孩子節點的代碼復制 100 萬遍嗎?
我們通常使用如下結構實作多叉樹:
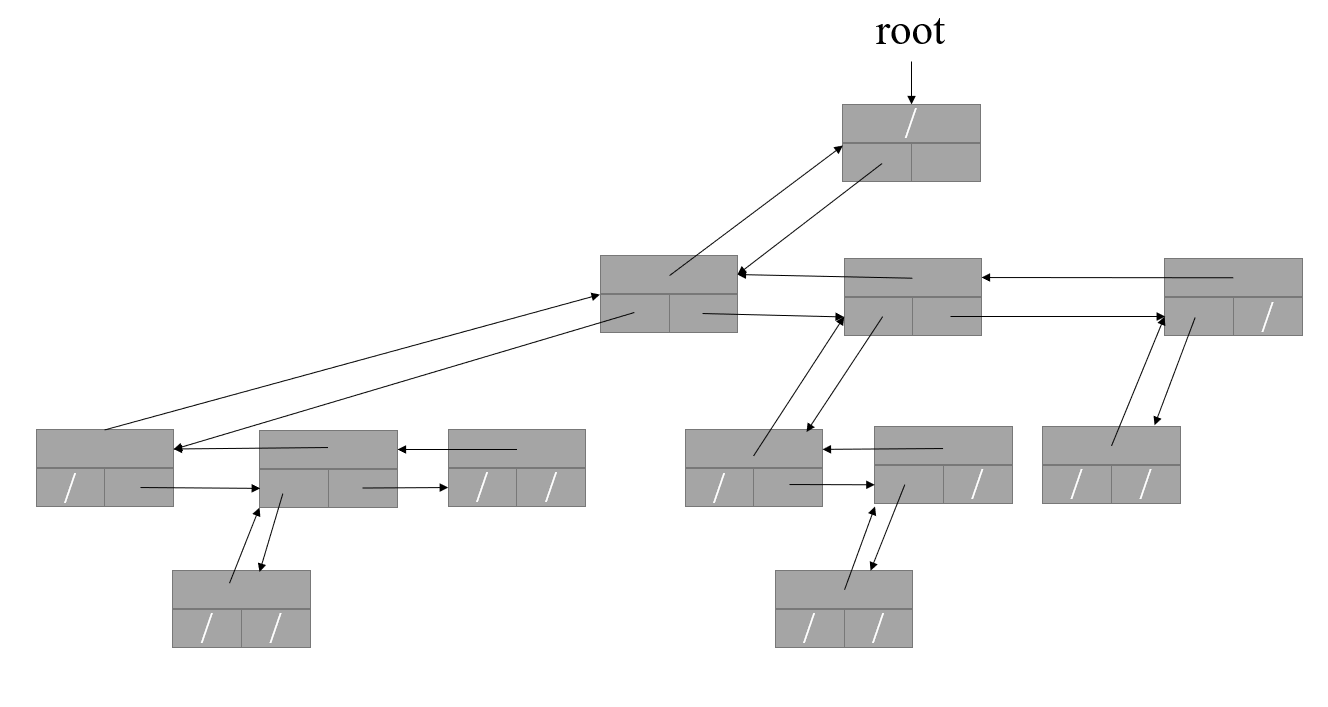
在資料結構上與二叉樹完全一樣,但在解釋上則不同,位于同一排的節點互相稱為兄弟節點,上方的是父節點,下方的是子節點,原先的左孩子變成了子節點里的“兄”,原先的右孩子變成與自己“同輩”的“弟”,“長兄”原先的父節點依然是父節點,但其他兄弟原先的父節點則變成了“兄”節點,僅僅通過不同的解釋,在完全不改變資料結構的情況下,我們就實作多叉樹,而且是任意子節點數量的多叉樹,
請讀者們仔細觀察,我們上文中所舉例的二叉樹和多叉樹實際上有沒有什么區別呢?
結語
這一篇文章介紹了四種最基本的資料結構,請讀者們一定要深入理解鏈表的概念,幾乎所有的資料結構都可以從鏈表中找到影子,下一篇文章我們將會介紹堆排序(絕對不鴿!!!),堆排序將會使用樹的概念實作,不過是一種特殊的樹——完全二叉樹,
原文鏈接:albertcode.info
個人博客:albertcode.info
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/69629.html
標籤:其他
上一篇:Buy Tickets POJ - 2828(線段樹,單點更新,區間查詢)
下一篇:雙鏈表【參照redis鏈表結構】