一、模型可解釋性
????近年來,機器學習(深度學習)取得了一系列驕人戰績,但是其模型的深度和復雜度遠遠超出了人類理解的范疇,或者稱之為黑盒(機器是否同樣不能理解?),當一個機器學習模型泛化性能很好時,我們可以通過交叉驗證驗證其準確性,并將其應用在生產環境中,但是很難去解釋這個模型為什么會做出此種預測,是基于什么樣的考慮?作為機器學習從業者很容易想清楚為什么有些模型存在性別歧視、種族歧視和民族仇恨言論(訓練樣本的問題),但是很多場景下我們需要向模型使用方作出解釋,讓其清楚模型為什么要做出此種預測,如模型替代醫生判斷病情,給出病人合理的解釋至關重要,在商業場景中,模型為公司做出決策,需要給出令管理層信服的解釋,另外,給出解釋也可以幫助我們進一步改善模型,優化特征,提高泛化性,
????本文就LIME( Local Interpretable Model-Agnostic Explanations, LIME)方法如何解釋黑盒模型作出簡要的介紹和公式推導,介紹其優缺點,文末附上自己的一些簡單思考
二、 LIME
????LIME的主要思想是利用可解釋性模型(如線性模型,決策樹)區域近似目標黑盒模型的預測,此方法不深入模型內部,通過對輸入進行輕微的擾動,探測黑盒模型的輸出發生何種變化,根據這種變化在興趣點(原始輸入)訓練一個可解釋性模型,值得注意的是,可解釋性模型是黑盒模型的區域近似,而不是全域近似,這也是其名字的由來,
????LIME的數學表示如下:
\[explanation(x)=arg\min_{g\in G}L(f,g,\pi_x)+\Omega(g) \]
????對于實體\(x\)的解釋模型\(g\),我們通過最小化損失函式來比較模型\(g\)和原模型\(f\)的近似性,其中,\(\Omega (g)\)代表了解釋模型\(g\)的模型復雜度,\(G\)表示所有可能的解釋模型(例如我們想用線性模型解釋,則\(G\)表示所有的線性模型),\(\pi_{x}\) 定義了\(x\)的鄰域,我們通過最小化\(L\)使得模型\(f\)變得可解釋,其中,模型\(g\),鄰域范圍大小,模型復雜度均需要定義,
????下面對于結構化資料型別,簡要說明LIME的作業流程,
????對于結構化資料,首先確定可解釋性模型,興趣點x,鄰域的范圍,LIME首先在全域進行采樣,然后對于所有采樣點,選出興趣點x的鄰域,然后利用興趣點的鄰域范圍擬合可解釋性模型,如下圖\(^1\)
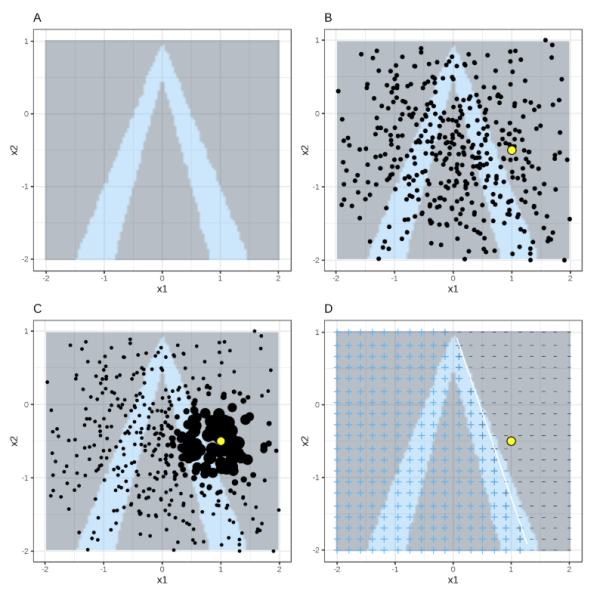
其中,背景灰色為負例,背景藍色為正例,黃色為興趣點,小粒度黑色點為采樣點,大粒度黑點為鄰域范圍,右下圖為LIME的結果,
????LIME的優點我們很容易就可以看到,原理簡單,適用范圍廣,可解釋任何黑箱模型,但是在實際應用中,存在幾個問題:
- 需要確定鄰域范圍;鄰域范圍不同,得到的區域可解釋性模型可能會有很大的差別,如下圖
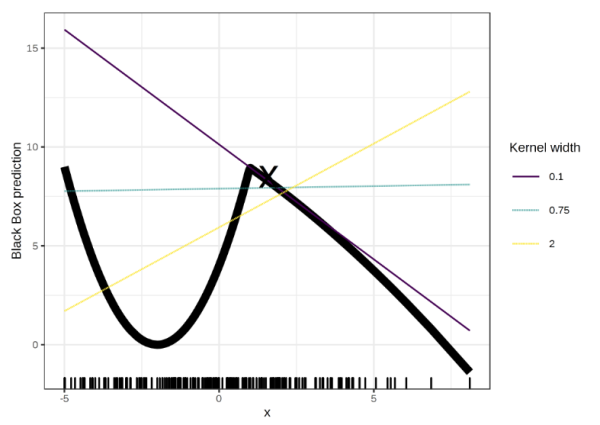
????對于x=1.6,不同的鄰域范圍(0.1,0.75,2)對應的可解釋性模型是完全不同的,甚至相悖,
-
采樣是全樣本集采樣,采樣是利用高斯分布進行采樣,忽略了特征之間的關系,這可能導致一些不大可能出現的樣本點來解釋模型,
-
解釋模型的復雜度需要提前定義,
-
解釋的不穩定性,利用相同引數相同方法進行的重復解釋,得到的結果可能完全不同.\(^5\)
三、總結
????模型可解釋性作為目前機器學習領域研究的熱門,LIME的成果是很有啟發性的,通過對黑盒模型某區域點的無限次探測,擬合出一個區域可解釋性的簡單模型,但是其缺點同樣明顯,這些缺點也導致了LIME方法難以大規模應用,
????后續將介紹基于Shapley值的SHAP方法(現在在研讀,就是有點看不懂,看懂了再寫)
參考鏈接:
- https://christophm.github.io/interpretable-ml-book/lime.html
- https://blog.csdn.net/a358463121/article/details/52313585
- https://cloud.tencent.com/developer/article/1096716
- 論文地址:https://arxiv.org/pdf/1602.04938v1.pdf
- Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).)
本文由飛劍客原創,如需轉載,請聯系私信聯系知乎:@AndyChanCD
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/69695.html
標籤:其他