先貼錯誤:
[root@master spark-2.0.1-bin-hadoop2.7]# ./sbin/start-all.sh
org.apache.spark.deploy.master.Master running as process 3530. Stop it first.
slaver1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/spark-2.0.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slaver1.out
slaver2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/spark-2.0.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slaver2.out
slaver1: failed to launch org.apache.spark.deploy.worker.Worker:
slaver1: at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:693)
slaver1: at org.apache.spark.deploy.worker.Worker.main(Worker.scala)
slaver1: full log in /usr/spark/spark-2.0.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slaver1.out
slaver2: failed to launch org.apache.spark.deploy.worker.Worker:
slaver2: at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:693)
slaver2: at org.apache.spark.deploy.worker.Worker.main(Worker.scala)
slaver2: full log in /usr/spark/spark-2.0.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slaver2.out
我的spark-env.sh如下:
export JAVA_HOME=/usr/java/jdk1.8.0_101
export SCALA_HOME=/usr/scala/scala-2.11.8
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=0.5g
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SPARK_WORKER_CORES=1
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_DIRS=/usr/spark/spark-2.0.1
#set ipython start
PYSPARK_DRIVER_PYTHON=ipython
當我在Hadoop上啟動./sbin/start-all.sh時,各個節點都可以正常運行。
但是在spark上啟動./sbin/start-all.sh時,就報了上面的錯。
我三個虛擬機記憶體是2個g,系統是紅帽5.
啟動Hadoop時,192.168.183.70:50070網頁的內容如下:
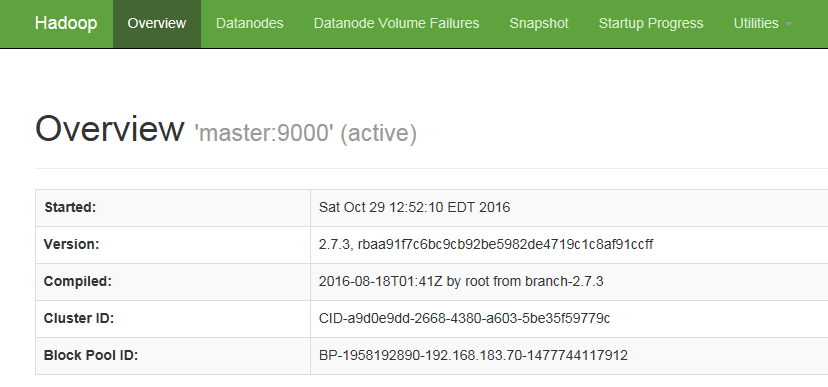
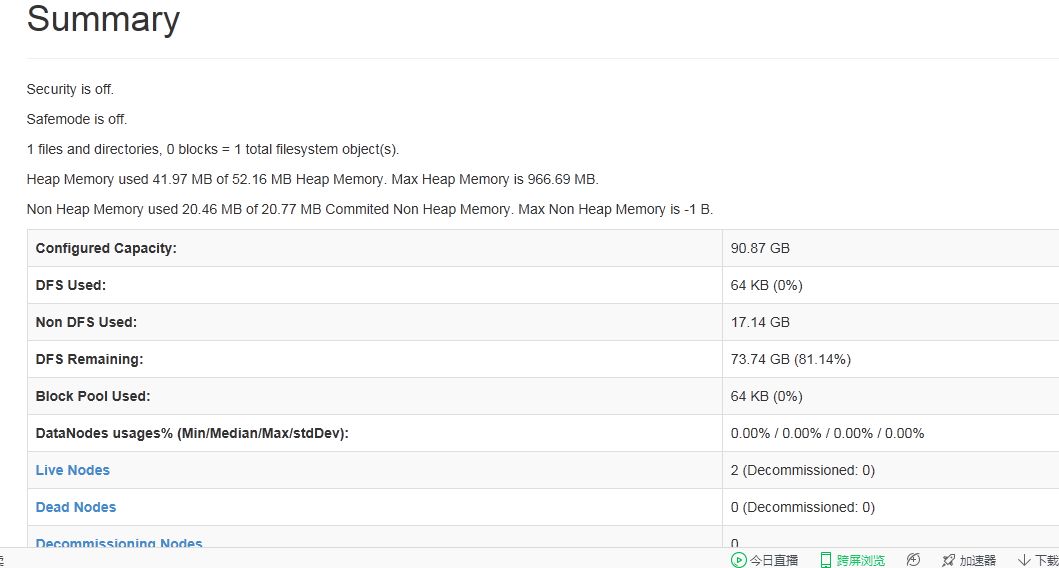
求大神指教,該怎么做。
uj5u.com熱心網友回復:
slaver1: full log in /usr/spark/spark-2.0.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slaver1.out你要把worker的日志貼上來才知道具體問題在哪
uj5u.com熱心網友回復:
3個虛擬機,live node 也應該是3個轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/70393.html
標籤:Spark
上一篇:2020寧波銀行總行金融科技部研發崗秋招面試(C/C++)
下一篇:虛擬化技術在互聯網+的應用