小白寫了一個隊號碼活躍度評分的模型,在IDEA上跑是沒有問題的,跑100條號碼大概幾十秒。但是一放到集群上面,代碼便一直運行半小時左右,最后就運行失敗,查看日志顯示就是記憶體溢位。請問有大神遇到過這個問題嗎?求解決,已經困惑兩天了,以前練習mlib的時,里面有兩個方法也存在這種問題,本地能跑,集群上記憶體溢位。
網上查看說浭水spark-defaults.conf里面的spark.driver.extraJavaOptions -XX:PermSize=128M -XX:MaxPermSize=256M ,我改了可還是錯。
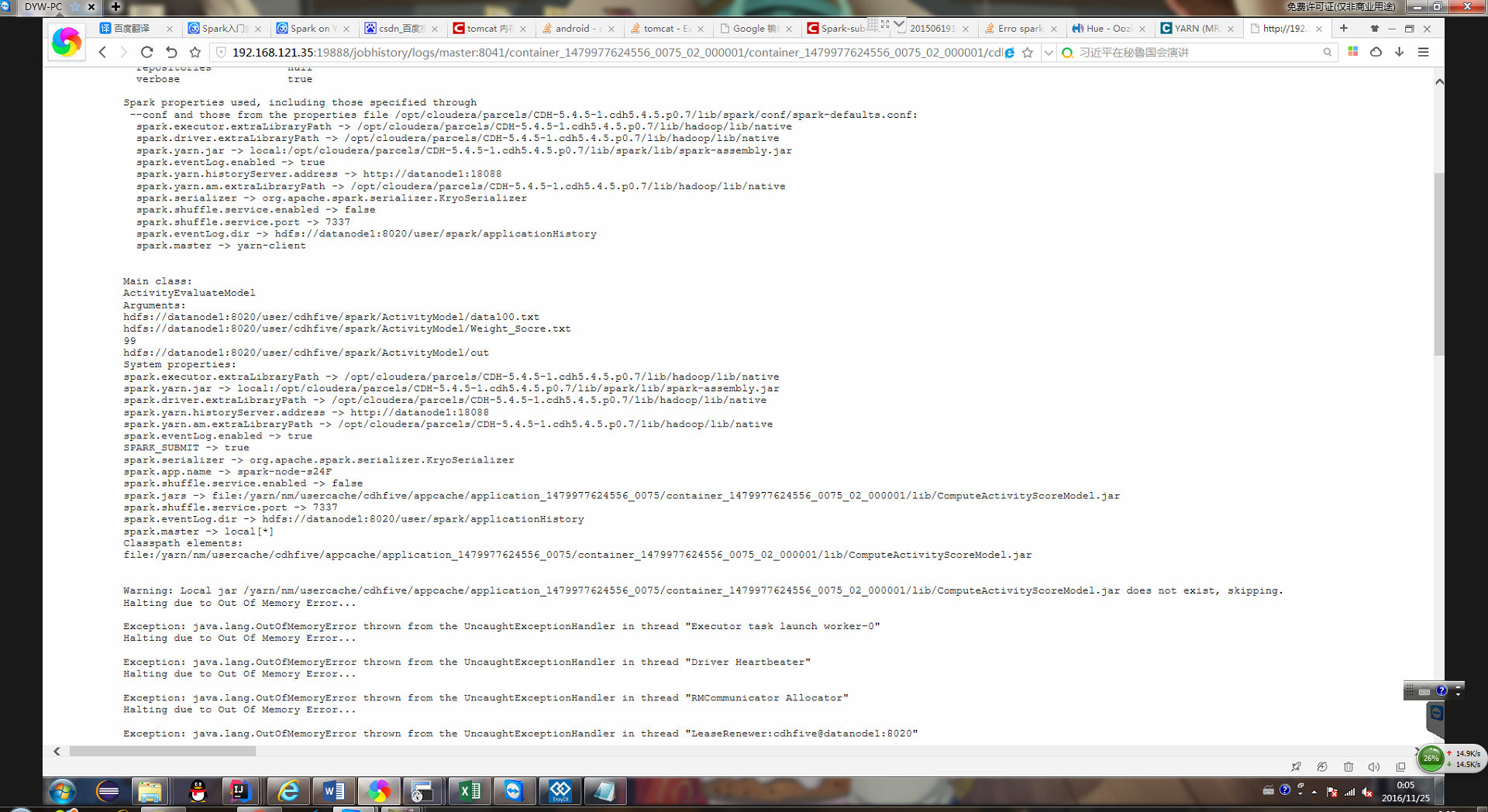
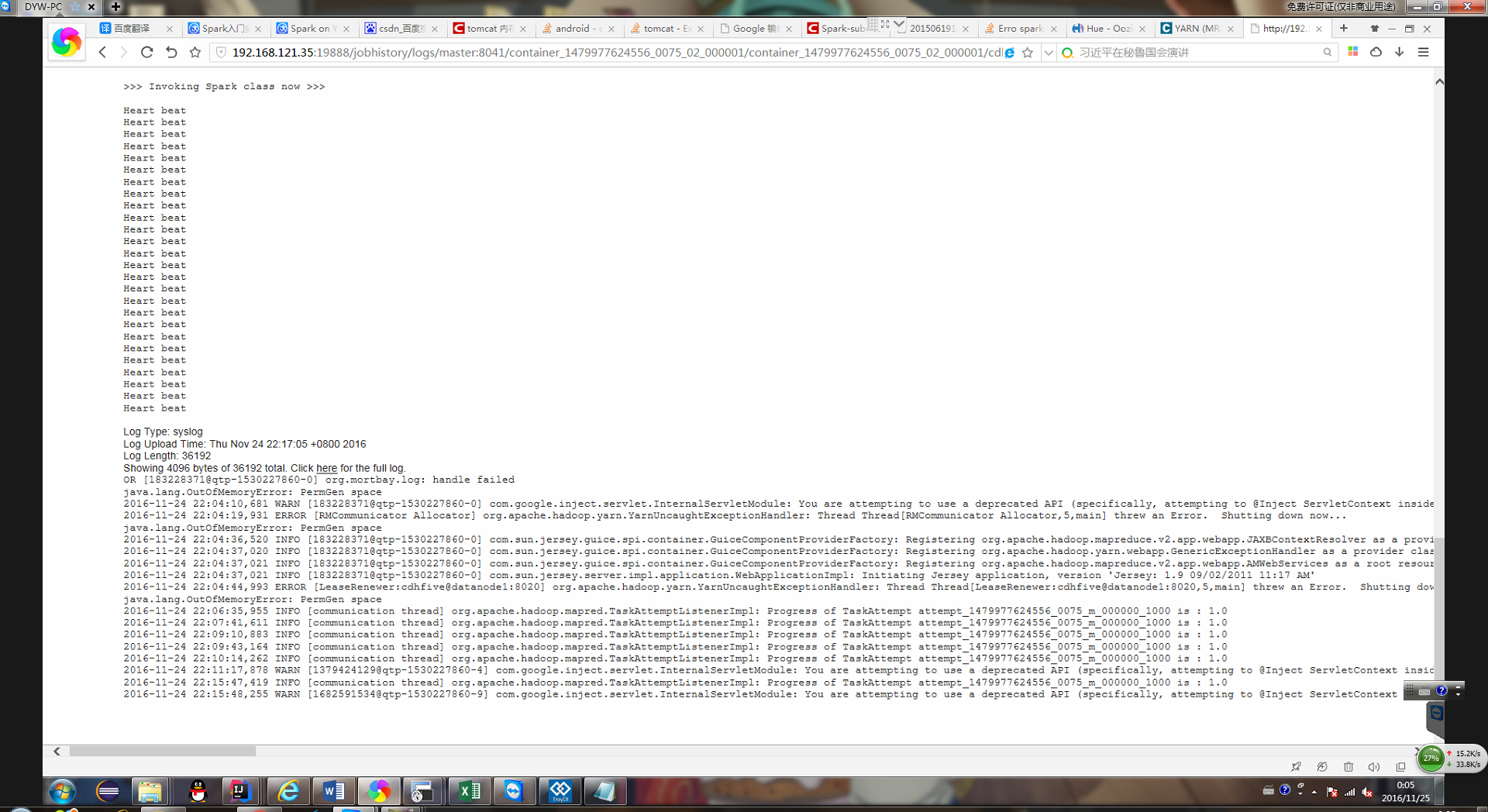
日志內容如下:
uj5u.com熱心網友回復:
抱歉,由于個人能力有限,幫不了你。

uj5u.com熱心網友回復:
集群上每個節點分配的記憶體空間是多少,一般默認是1g。另外需要檢查driver memory設定的大小uj5u.com熱心網友回復:
driver一般是512M-1G,executor有公式可以計算。一般是核心數:記憶體是1:2或1:4。單個Worker節點可以分配多個Worker實體,一般是核心數/4。這些在spark-env.sh里面配置另外你這是什么復雜模型?100條可以跑那么久。。。考慮下優化代碼吧
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/70400.html
標籤:Spark
上一篇:C/C++描述 LeetCode 4. 尋找兩個正序陣列的中位數
下一篇:云存盤決議