本文將會以插入排序為例,介紹演算法與資料結構的基礎部分,
插入排序
排序可以說是整個演算法中最為基礎,最為重要的一部分,而插入排序正是排序演算法中最簡單的一種解決辦法,
什么是排序問題?
輸入:n個數的一個序列 \(<a_{1}, a_{2}, a_{3} ... a_{n}>\),
輸出:輸入序列的一個排列 \(<b_{1},b_{2},b_{3} ... b_{n}>\),同時滿足 \(b_{1} \leq b_{2} \leq b_{3} \leq ... \leq b_{n}\),
而插入排序的思路和我們平時打撲克時整理排序的思路非常類似,開始時,我們手中沒有牌,然后我們每次從桌上拿走一張牌,并將其插入到手中正確的位置,直到我們將牌整理完成,何為正確的位置?用規范一點的描述,可以認為,將第 n 張牌插入到已經排好序的 n-1 張牌中,并保證插入后依然保持有序,這就是插入排序的核心理念,
從感性上來說,我們需要整理多少張牌,就對應著需要插入幾次,當然第一次插入時,因為手中沒有牌,所以無需考慮什么地方是正確的位置,
如下圖是一個插入排序的展示:
我們可以使用如下代碼實作:
#include <stdio.h>
// 輸出陣列結果
int PrintArray(int* array, int array_length){
int i;
for(i = 0; i < array_length; i++){
printf("%d ", array[i]);
}
printf("\n");
}
// 插入排序,結果按升序排列
int InsertionSort(int* array, int array_length){
int i, j; // 回圈使用的臨時變數
int num_to_insert; // 陣列排序使用的臨時變數
for(i = 1; i < array_length; i++){
num_to_insert = array[i];
j = i - 1;
// 將array[i]插入至已經排好序的array[0 ~ i-1]之間
while(j >= 0 && array[j] > num_to_insert){ // 我是21行~
array[j + 1] = array[j];
j--;
}
array[j + 1] = num_to_insert;
}
return 0;
}
int main() {
int array_to_sort[10] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
InsertionSort(array_to_sort, 10);
PrintArray(array_to_sort, 10);
return 0;
}
一個演算法最為重要的要求是正確性,在正確性的前提下盡量降低時間復雜度和空間消耗,
正確性分析
通常來說,一個值得我們研究的演算法的核心部分是回圈或者遞回(因為如果不包含回圈和遞回,那么就意味著這個演算法是線性的,那么關于這個演算法也就沒有性能上的區別了,那么就可以說這是一個不值得我們研究的演算法),為了能夠論證這個演算法的回圈部分(遞回也是可以利用回圈實作的)是正確的,我們通常會使用一種叫做回圈不變式的概念,
利用回圈不變式論證演算法的正確性,主要分為三個步驟:
初始化:回圈的第一次迭代之前,它為真,
保持:如果回圈的某次迭代之前它為真,那么下次迭代之前它仍為真,
終止:回圈終止時,不變式為我們提供了一個有用的性質,該性質有助于證明此演算法是正確的,
看到這里,相比很多讀者已經意識到,這就是數學中的“數學歸納法”,那么將這三步用于上文中的插入排序,效果會是如何呢?
初始化:在第一次迭代之前,即當 i = 1 時,回圈不變式成立,因為子陣列此時僅由1個元素組成,即array[0],此陣列必然是有序的,
保持:當前 i 個元素組成的子陣列已經有序后,我們準備插入第 i+1 個元素,代碼的第21-24行的部分,保證了所有大于第 i+1 個元素的資料均在此元素右方,所有小于等于第 i+1 個元素的資料均在此元素左方,則當插入此元素后,前 i+1 個元素組成的子陣列有序,
終止:回圈終止的條件是 i == array_length,即前 array_length 個元素組成的子陣列有序,即整個陣列有序,
通過這三步分析,我們證明了這個演算法的正確性,以后的文章我們提到的所有演算法,均可以通過此方法分析其正確性,雖然我們在后期可能會更加強調一個演算法的運行效率,對于一些顯而易見的正確性可能會略過不講,但這并不意味著正確性分析不重要,僅憑作者的經驗來看,很多學習演算法的同學容易陷入一個怪圈,只著眼于運行效率而忽略了演算法本身正確性,
運行效率分析
對于一個演算法的運行效率最直接的判斷方式是,將其寫為一個程式并運行測速,但在大部分情況下,這是不合理的,例如同一個演算法由不同的程式員撰寫,用不同的語言撰寫,用不同的運行環境來測驗,或者用不同的硬體設備來運行,都會有著巨大的差異,如果有的演算法非常復雜或者資料量很大,需要幾個小時甚至幾天才能運行完成,我們需要一直等它運行完成,才能評判這個演算法的運行效率嗎?顯然用實際運行并計時的方式來評判一個演算法的運行效率在大部分情況下是不合理的,
對此,我們引入了一種思想模型——隨機訪問機(RAM)來評估一個演算法的運行效率,
RAM模型包含真實計算機中常見的指令:算術指令(如加法,減法,乘法,除法,取余、向下取整,向上取整),資料移動指令(裝入、存盤、復制)和控制指令(條件跳轉,無條件跳轉,子程式呼叫與回傳),上述這些指令所需時間均為常量,即這些指令運行時間不變),同時,在實際中,計算機包含多級存盤,但為了簡化問題,我們一般不考慮高速快取,虛擬記憶體等多級存盤,簡化為只有硬碟與記憶體的區別,再說了,現在技術變的這么快,說不定以后就沒cache了呢,考慮啥呀真的是,這一段沒有看懂不要急,下面會舉一個例子,看了例子后相信大部分讀者就能明白了,
有了模型,現在就需要考慮如何進行評估,對于一個演算法,輸入規模能夠很大程度的影響運行時間,例如插入排序中對10個數進行排序和對10億個數進行排序,對此,我們引入了輸入規模與運行時間的概念,
輸入規模:輸入規模很大程度上依賴于具體問題來進行分析,例如排序中,輸入規模一般認為是需要排序的資料個數;如果分析兩個整數相乘,則輸入規模一般認為是兩個數的總位數;如果需要研究圖論問題,那么輸入規模一般認為是圖中的頂點數與邊數,什么是輸入規模沒有一個具體的規定,但一般而言就是指這個影響這個演算法運行時間的最重要的那一個屬性,這個需要讀者們多學習積累經驗,才能迅速的分析出一個問題的關鍵所在,
運行時間:這個運行時間不是指實際運行時間,而是在RAM模型中需要執行的基本操作步數,什么是基本操作步數?也就是我們上文中提到的RAM模型中的常見指令,運行一條指令就是一步,雖然不同指令的運行時間不同,但他們之間的差異都是常量級的,例如加法指令可能需要1ms運行完成,乘法指令需要10ms運行完成,他們的比例是1:10,運行100條加法指令與運行100條乘法指令所需時間比例依然是1:10,這個常數時間的差異在我們后面面對的動輒 指數級 差異的比較之下,就可以忽略不計了,
為什么我們會忽略運行時間的常數差異呢?一個很簡單的道理,如果我們的計算規模很小,例如排序十個數,不同演算法之間差距可能只有不到1ms,這點時間與你點擊運行,電腦突然卡了一下等事情需要花費的時間相比,簡直微不足道,甚至都沒必要去優化演算法了,而如果計算規模很大,例如要排序全國人民的身份證號,差一點的演算法(插入排序同學,說的就是你,別東張西望了)可能需要幾年,而好一點的演算法可能只需要幾個小時,不同演算法之間的運行時間差異甚至是指數級的,這一點常數差異真的沒有什么影響,除非兩個指令之間運行時間比例能達到百萬級之類的,那你干脆把差距這么大的指令也當做演算法來研究研究優化一下了吧,等學習深入以后,讀者們也會發現,我們大部分時候只考慮運行時間與輸入規模之間的關系,如是指數關系還是線性關系等,同時評價一個演算法好不好,大部分情況下也是考慮輸入規模較大的時候的增長趨勢,
運行效率分析案例
現在我們以上文中的插入排序代碼為例,進行一下運行效率的分析,我們此次分析會將常數差異考慮進去,以印證我們前文所說的,當輸入規模較大時,常數差異不重要的結論,
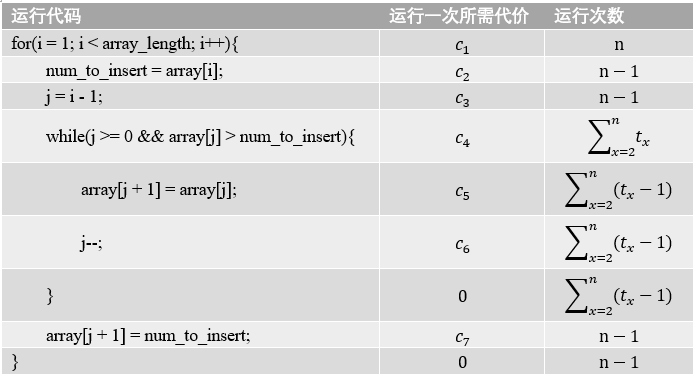
表格中 n 表示輸入規模,即array_length,\(t_{x}\) 表示執行while回圈的次數,由于 } 并不占用運行時間,故運行一次所需代價為0,
那么我們將上述所有運行時間相加,所得結果為
\[T(n)=c_{1}*n+c_{2}*(n-1)+c_{3}*(n-1)+c_{4}* \sum_{x=2}^n t_{x} +c_{5}* \sum_{x=2}^n (t_{x}-1) +c_{6}* \sum_{x=2}^n (t_{x}-1) +c_{7}*(n-1) \]
現在我們又面臨一個新的問題,對于同一規模的輸入,如果輸入不同,其運行時間也是不同的,例如在此例中,如果輸入的陣列就是已經升序的,那么
\[t_{x}==1 \]
化簡一下,
\[T(n)=c_{1}*n+c_{2}*(n-1)+c_{3}*(n-1)+c_{4}*(n-1) +c_{7}*(n-1)\\=(c_{1}+c_{2}+c_{3}+c_{4}+c_{7})*n-(c_{2}+c_{3}+c_{4}+c_{7}) \]
可以將此記為
\[an+b \]
即在插入排序的最好情況下,最后的運行時間與輸入規模之間是線性關系,
如果輸入的陣列是降序的,那么
\[\sum_{x=2}^n t_{x}= \frac{n*(n+1)}{2} -1 \]
\[\sum_{x=2}^n (t_{x}-1)= \frac{n*(n-1)}{2} \]
化簡一下,
\[T(n)=c_{1}*n+c_{2}*(n-1)+c_{3}*(n-1)+c_{4}* (\frac{n*(n+1)}{2} -1) +c_{5}* \frac{n*(n-1)}{2}+c_{6}* \frac{n*(n-1)}{2} +c_{7}*(n-1)\\=(\frac{c_{4}+c_{5}+c_{6}}{2})*n^2+(c_{1}+c_{2}+c_{3}+\frac{c_{4}-c_{5}-c_{6}+c_{7}}{2})*n-(c_{2}+c_{3}+c_{4}+c_{7}) \]
可以將此記為
\[a*n^2+b*n+c \]
即在插入排序的最壞情況下,最后的運行時間與輸入規模之間是二次函式關系,
運行效率分析總結
在我們上面的例子中,我們既研究了最佳情況,也研究了最壞情況,但一般而言,實際中我們的分析主要在于最壞情況,我們以后的文章也將會主要著眼于最壞情況的分析,對此,我們有以下理由:
- 一個演算法的最壞情況給出了任何輸入的運行時間的一個上界,我們可以保證該演算法不需要更長的時間,無需有更多擔心,
- 在實際中,最壞情況經常出現,例如我們撰寫一個網頁,用戶登錄時,我們需要將登陸資料與資料庫中的資料進行對比,在很多時候,由于用戶的錯誤輸入或者惡意輸入,資料庫中是沒有這條記錄的,所以需要檢索整個資料庫,也就是最壞情況,我們不能讓這個最壞情況太差,因為如果只是讓用戶最快登陸時間從0.1秒增加到0.2秒是可以接受的,但當一個用戶錯誤登陸時,需要所有用戶一起卡一天
,建議以“蓄意破壞計算機資訊系統罪”立即去公安機關自首或者直接擊斃, - 一般而言,平均情況與最壞情況差距不大,可能只有一個常數的差異,如插入排序中,如果插入第n個數時,平均情況下是在第n/2個數時插入,最壞情況是在第n個數插入,只有一個2倍關系,所以平均情況的運行時間只是將最壞情況的運行時間除以2而已,依然是二次函式關系,并沒有本質上的區別,
當然我覺得還有另外一個原因:最壞情況很好算!!!而平均情況很多時候真的很難算的!!!為了一個只需要花5分鐘寫完的演算法,我花了10分鐘去分析它的平均情況,我也很難的好吧,這么多時間我拿去拯救世界不香嗎,
增長量級
雖然說我們可以具體計算出一個演算法的最壞情況,但也挺花時間的,同時我們也注意到,對于一個二次函式關系,當n足夠大時,只有二次項才是影響其大小的關鍵,這也就引出了數學中的漸進分析的概念,也就是我們的增長量級,即大家常說的那個討人厭的大O符號,小O符號,具體含義我們將在下一篇文章中介紹,在這里我們只需要先知道一個結論,在實際的演算法效率分析中,我們真正感興趣的是運行時間的增長率或者增長量級,即公式中最為重要的項,例如插入排序中的二次項,因為當n真的很大的時候,低階項相對來說不太重要,而常數項在n逐漸變大的程序中,也逐漸不太重要了(在實際中,我們往往只關心數量級,例如百萬級的資料,億級的資料,在這種情況下,常數項是1還是10就沒有必要關心了,畢竟這種時候它帶來的影響連低階項都比不上了)
結語
這是演算法與資料結構系列的第一篇文章,下一章我將會以歸并排序為例介紹時間復雜度的概念,再后面就是具體的演算法與資料結構的分析了,從最基礎的時間復雜度、空間復雜度開始,一步一步深入,比如搜索,排序,基本資料結構,各種神奇的樹,圖,矩陣等等,后面應該也會介紹一些動態規劃,字串處理等常用演算法,以及一些簡單的數論演算法和數學知識吧,如果有興趣的話我大家也可以關注我一波,沒有意外情況的話,我應該可能或許說不定不會鴿吧,
原文鏈接:albertcode.info
個人博客:albertcode.info
微信公眾號:AlbertCodeInfo
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71870.html
標籤:其他
下一篇:資料結構&演算法