這一篇文章我們首先會介紹一下歸并排序,并以歸并排序和我們上一章所說的插入排序為例,介紹時間復雜度,此系列的所有代碼均可在我的 github 上找到,
點此查看本文歸并排序的完整代碼,
分治法
在介紹歸并排序前,我們需要首先介紹一下分治法,歸并排序正是分治法的一個典型應用,
分治法:將原問題分解為多個規模較小的但類似于原問題的子問題,遞回地求解這些子問題,然后再合并這些子問題的解來建立原問題的解,
分治法一般而言分為這三步:
分解:將原問題分為若干個子問題,這些子問題是原問題的規模較小的實體,
解決:對于每一個子問題,遞回地求解其子問題(即如果要求解一個子問題,但如果這個子問題仍然很復雜,那么我們可以像對待原問題一樣,再將其分為多個子子問題),如果子問題的規模足夠小,則直接求解(例如排序問題中,如果只有一個資料需要排序,那么這個問題已經非常簡單了,已經可以直接得出這個問題的解),
合并:將這些子問題的解合并在一起,組成為原問題的解,
這其中最為重要的一步,是如何分解問題,保證其子問題與原問題除了在問題規模上,其他所有屬性均相同,
歸并排序
歸并排序完全遵照分治法的思路:
分解:將等待排序的n個元素的序列分解為各 n/2 個元素的兩個子序列,
解決:如果元素個數大于1,繼續進行分解;如果元素個數等于1,直接回傳此序列,
合并:合并兩個已排序的子序列,形成一個已排序的序列,
雖然上面這部分內容就是歸并排序的步驟,但可能很多讀者依然沒有太明白:什么?就這?這就排序好了?是的,就這,接下來我們詳細介紹一下每一步的程序,
歸并排序的合并步驟
歸并排序的合并步驟是歸并排序最重要的一步,這一步的目標是:
將兩個已經排序完成的序列合并為一個新的排序完成的序列,
具體C語言代碼如下:
// 合并兩個相鄰的陣列
// 將已經有序的陣列 array[0, array_length1 - 1] 與 array[array_length1, array_length1 + array_length2 - 1]
// 合并至 array[0, array_length1 + array_length2 - 1],并依然保證有序
int Merge(int* array, int array_length1, int array_length2){
int i, j, k; // 臨時變數
int* temp_array1 = (int*)malloc(sizeof(int) * (array_length1 + 1));
int* temp_array2 = (int*)malloc(sizeof(int) * (array_length2 + 1));
// 復制新陣列,因為原陣列將會用于儲存結果
for(i = 0; i < array_length1; i++){
temp_array1[i] = array[i];
}
temp_array1[array_length1] = INT_MAX;
for(i = 0; i < array_length2; i++){
temp_array2[i] = array[array_length1 + i];
}
temp_array2[array_length2] = INT_MAX;
// 進行合并操作
j = 0;
k = 0;
for(i = 0; i < array_length1 + array_length2; i++){ // 我是第22行
if(temp_array1[j] > temp_array2[k]){
array[i] = temp_array2[k];
k++;
} else{
array[i] = temp_array1[j];
j++;
}
}
// 釋放申請的空間
free(temp_array1);
free(temp_array2);
return 0;
}
上述代碼中,array是一個陣列,我們的目標是將已經有序的相鄰陣列 array[0, array_length1 - 1] 與 array[array_length1, array_length1 + array_length2 - 1] ,合并至 array[0, array_length1 + array_length2 - 1],并依然保證有序,如下圖所示:
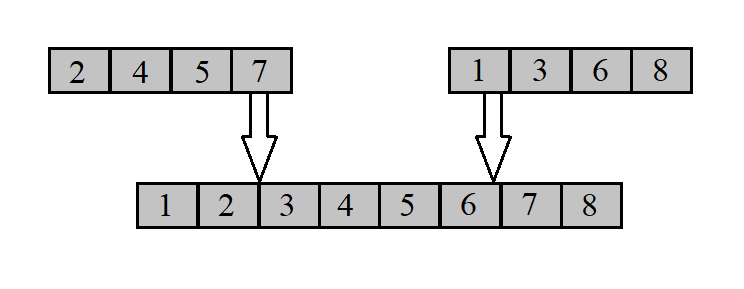
具體步驟的解釋我們仍以撲克牌為例:現在我們在桌上有兩堆牌面向上的牌,每堆都按照從小到大的順序排序完成,即最小的牌在頂部,此時我們比較這兩堆牌的頂部牌的大小,選擇較小的那一張(如果一樣大,就隨意選擇一張),將牌拿走,并將其牌面向下放在輸出牌堆,此時我們拿走的那張牌下面的牌也顯露了出來,我們重復上述程序,繼續將選出來的牌牌面向下蓋在輸出牌堆,直至將所有牌均轉移至輸出牌堆,
在合并的程序中,必定會有一個牌堆先空,此時最直接的想法是直接將另一個牌堆的所有牌 牌面向下蓋在輸出堆,但在我上文中給出的的歸并排序代碼中,為了使得代碼簡潔,我采用了另外一種策略,在兩個牌堆底部添加一張無限大的牌(由于真實計算機的限制,無法表示無限大,所以我們采用int的最大值,即INT_MAX來代替,效果也是一樣的),這樣在另一個牌堆中,除了同樣被我們人為添加進去的無限大牌以外,其余牌均小于無限大,那么必定也可以逐個將所有剩下的牌轉移至輸出堆,其實這樣會有一個bug,即如果第二個陣列中有多個數的大小是INT_MAX,那么我們會一直從第一個陣列中取值,這樣就會出現陣列越界的問題,修復這個bug就當做課后作業交給讀者們解決了,其實解決方法無非兩種,一是規定陣列中不得出現值為INT_MAX的資料,是的我就是這么懶,你來打我啊;二是判斷如果 j 已經不小于 array_length1 了,則取值 temp_array[array_length1 - 1],
上文中之所以要牌面向下僅僅是為了保證結果也是從小到大的,如果牌面向上結果則為從大到小,如果不理解這個小細節并不影響對于歸并排序演算法的理解,讀者可以在閱讀完整篇文章,理解了歸并排序后再回過頭來,應該就能馬上明白其用處,或者讀者也可以拿一副撲克牌自己親手嘗試一下,
證明合并步驟的正確性
正如我們上一篇文章所說,一個演算法最重要的是正確性,所以我們將首先進行這一步,判斷上述合并代碼的關鍵步驟:第22行~第30行的正確性,如果判斷正確性的3個步驟已經忘了,可以去回顧一下第一篇文章,同時為了方便說明,我們將第一個陣列稱為 L,第二個陣列稱為 R,同時 i 恒等于 j + k:
初始化:回圈開始前,i == 0 ,即目標陣列 array 為空,必然有序,且這個空陣列包含 L 和 R 中的 0 個最小的元素;j == k == 0,則 L[j] 和 R[k] 分別為 L 和 R 陣列中未被復制到 array 陣列的最小的元素,
保持:我們不妨假設 L[j] <= R[k],則 L[j] 是未復制到 array 陣列的最小的元素,因為 array[0, i - 1] 包含 i - 1 個最小元素且有序,所以將 L[j] 復制到 array[i] 以后,array[0, i] 包含 i 個最小元素,且有序,增加 i 值和 j 值后,L[j] 依然是 L 陣列中未被復制到 array 陣列的最小的元素,R 陣列由于未發生變化,所以R[k] 依然是 R 陣列中未被復制到 array 陣列的最小的元素,反之若 L[j] > R[k],同理可得,
終止:當 j == array_length1,k == array_length2 時,程式終止,此時 array[0, array_length1 + array_length2 - 1] 包含 L[0, array_length1 - 1] 和 R[0, array_length2] 中最小的 array_length1 + array_length2 個元素且有序,L[array_length1] 和 R[array_length2] 是我們手動加入的兩個無限大的值,
歸并排序的其他步驟
在理解了合并步驟以后,歸并排序的剩下兩個步驟就很簡單了,具體C語言代碼如下:
// 歸并排序,結果按升序排列
int MergeSort(int* array, int array_length){
// 若陣列長度為1,必然有序
if(array_length == 1){
return 0;
}
int half_array_length = array_length / 2;
// 將陣列分為兩個部分,遞回實作子陣列的排序
MergeSort(array, half_array_length);
MergeSort(array + half_array_length, array_length - half_array_length);
// 將已經排序完成的子陣列合并,實作整個陣列的排序
Merge(array, half_array_length, array_length - half_array_length);
return 0;
}
我們可以將 Merge() 函式用在 MergeSort() 中,作為一個子程式,若陣列長度為1,則直接回傳,因為一個資料必然是有序的;若陣列長度大于1,則將此陣列分解為兩個子陣列,分別進行遞回呼叫,通過這兩步后,兩個子陣列已經有序,然后將兩個陣列進行合并,形成一個新的有序陣列,
提示:可能有的讀者才入門沒有多久,無法理解為何將陣列分為兩個子陣列后,遞回呼叫完成后這兩個子陣列就分別有序了,我們以第一個子陣列為例進行分析:假設第一個子陣列(不妨稱為陣列a)長度為4,所以我們仍需將此陣列分解,分解為長度均為2的兩個子子陣列(不妨稱為 a_a 和 a_b ),對于陣列 a_a 而言,仍需分解為長度各為1的兩個子子子陣列(不妨稱為 a_a_a 和 a_a_b),由于 a_a_a 和 a_a_b 各只有一個元素,所以已經有序,直接回傳,那么陣列 a_a 已經有了兩個有序的子陣列,利用我們上文所說的合并演算法,合并為一個長度為2的有序陣列,同理陣列 a_b 也通過類似步驟成為一個長度為2的有序陣列,那么我們對陣列 a_a 和 a_b 使用上文中的合并演算法,則將陣列 a_a 和 a_b 合并為一個長度為4的有序陣列,即為a,
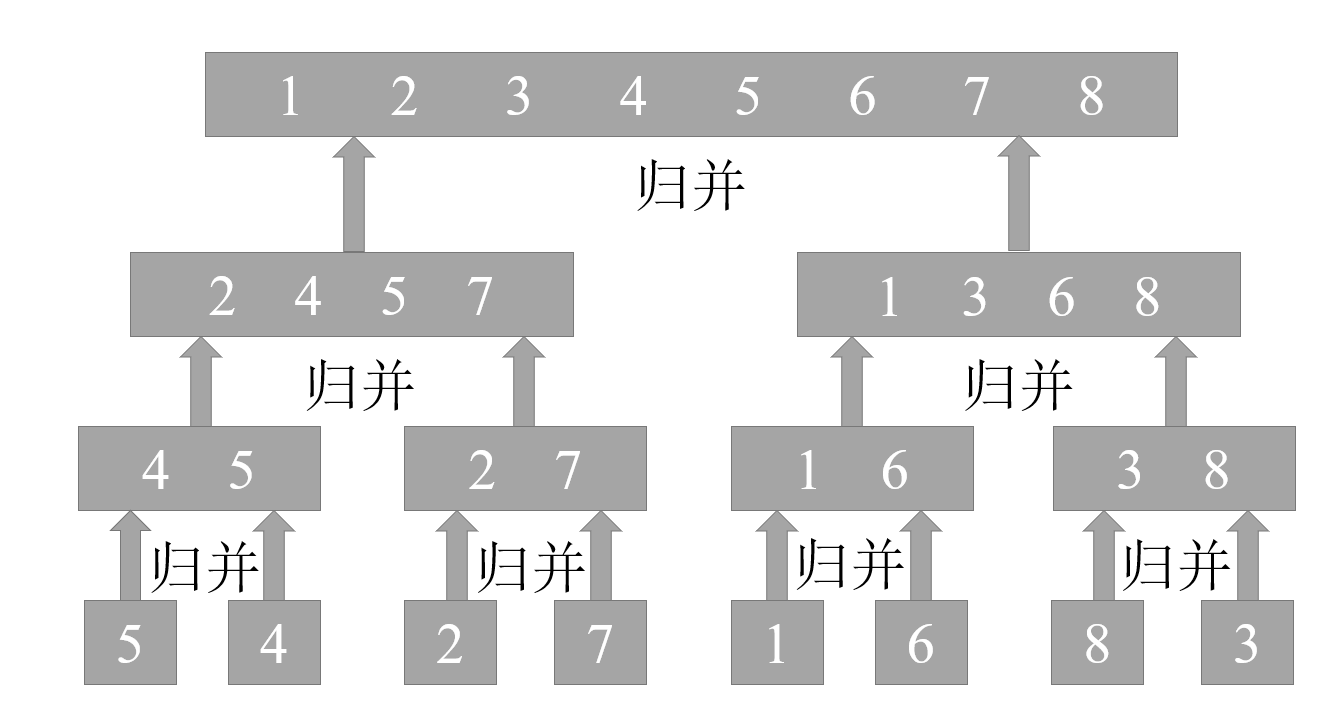
如下圖,就是一個將陣列 [5, 4, 2, 7, 1, 6, 8, 3] 進行歸并排序的樣例,
歸并排序的運行效率分析
當一個演算法包含對其自身的遞回呼叫時,我們可以使用遞回方程來描述其運行時間,我們對此進行的分析也是按照分治法的三個步驟來進行,
T(n)表示規模為n的一個問題的運行時間,當問題規模足夠小的時候,直接求解僅需要常量時間,如歸并排序時陣列長度為1時,記為\(\Theta (1)\),含義與數學中漸進分析一樣,我們通俗的理解為等于某個常數,規范解釋我們將在下文的時間復雜度中詳細介紹,
當問題規模較大是,需要進行分解,例如將原問題分解為a個子問題,每個子問題的規模是原問題的 1/b (歸并排序中 a 和 b 均等于2,但在很多其他分治法中,a 和 b 并不相同),為了求解一個規模為 n/b 的子問題,需要 T(n/b) 的時間,所以需要 a*T(n/b) 的時間來求解 a 個子問題,如果分解子問題需要時間 D(n),合并子問題的解需要時間 C(n),那么得到遞回式:
\[T(n) =\begin{cases} \Theta (1) & 若n足夠小 \\ a*T(n/b) + D(n) + C(n) & 其他\end{cases} \]
例如對于歸并排序,我們也如上進行分析,此時我們僅分析最壞情況,原因我們已經在上一篇文章中討論過了:
分解步驟僅需要計算子陣列的中間位置,需要常量時間,即 \(D(n) = \Theta(1)\),
解決問題時,我們需要遞回地求解兩個規模均為 n/2 的子問題,因此需要時間 \(2*T(n/2)\),
合并問題的解時,只需要掃描兩個子陣列各一遍,因此與問題規模成線性關系,即 \(C(n) = \Theta(n)\),
故最終的時間復雜度公式為
\[T(n) =\begin{cases} \Theta (1) & 若n=1 \\ 2*T(n/2) + \Theta(1) + \Theta(n) & 若n > 1 \end{cases} \]
如果數學基礎較好的讀者,可能已經能夠通過此運算式計算出最終的運行時間:
\[T(n) = \Theta(n*lgn) ,其中lgn表示log_{2}n \]
與數學中不同,由于計算機采用二進制,所以log默認底為2,而非10,這一點需要讀者們注意,以后的文章我們將不會強調這一點,但讀者們應該時刻記住這一關鍵點,具體的結果計算程序,由于篇幅原因,我們不再贅述,數學基礎較差的讀者可以去搜索“遞推公式求和”,如果只是想知道結論也可以直接搜索“主定理”,如果確實需要的話,大家可以給我留言,我以后專門寫一篇文章來詳細介紹一下,
從上述分析我們可以看出,歸并排序的時間復雜度遠低于插入排序,在實際中,如果一個演算法的時間復雜度已經達到 O(n*lgn),通常認為已經無需再進行優化了,因為對數的增長趨勢非常低,我們幾乎可以認為 O(n*lgn) 幾乎等同于 O(n),而一個問題,你再怎么也要把資料全部讀取一遍吧,這樣時間復雜度已經達到了 O(n),當然你要是真能做到 O(n) 的話,那我只能說一聲“大佬大佬,技不如人,甘拜下風”,
時間復雜度
我們前面說了這么久的時間復雜度,那時間復雜度究竟是一個什么東西呢?其實在看完上一篇文章和此文章前面的內容以后,相信大部分讀者只需要讀一遍下面的內容就能明白了,
之所以我們提出時間復雜度這個概念,正如我們前文所說,我們大部分時候并不需要確定一個演算法的精確運行時間,只需要知道他的增長趨勢,為了這個目的,我們將低次項與常系數忽略,只關心影響此演算法效率最為核心的部分,
漸進符號
這些符號直接使用的數學中的相關符號,含義也幾乎完全一樣,
\(\Theta\) 記號我們前面已經看到過了,讀作 Theta ,在這里,我們給出他的一個詳細定義:
對于任意給定的函式 \(g(n)\):\(\Theta(g(n)) = \{ f(n)\):存在正常量 \(c_1\)、\(c_2\) 和 \(n_0\),使得對于所有 \(n \geq n_0\),有 \(0 \leq c_1*g(n) \leq f(n) \leq c_2 * g(n) \}\),
通俗一點來說,當問題規模足夠大時,若函式 \(f(n)\) 能“夾在” \(c_1*g(n)\) 和 \(c_2*g(n)\) 之間,則 \(f(n)\) 屬于集合 \(\Theta(g(n))\),
例如 \(a*n^2 + b*n + c + d*lgn \in \Theta(n^2)\),其中 \(a \neq 0\),
第二個符號則是 O 記號,一般讀作“大O”,定義為:
對于任意給定的函式 \(g(n)\):\(O(g(n)) = \{ f(n)\):存在常量 \(c\) 和 \(n_0\),使得對于所有 \(n \geq n_0\),有 \(0 \leq f(n) \leq c*g(n) \}\),
與之相似的符號是 o 記號,一般讀作"小o",定義為:
對于任意給定的函式 \(g(n)\):\(o(g(n)) = \{ f(n)\):存在常量 \(c\) 和 \(n_0\) ,使得對于所有 \(n \geq n_0\),有 \(0 \leq f(n) < c*g(n) \}\),
與 大O 記號相反的是 \(\Omega\) 符號,讀作“大Omega”,定義為:
對于任意給定的函式 \(g(n)\):\(\Omega(g(n)) = \{ f(n)\):存在常量 \(c\) 和 \(n_0\) ,使得對于所有 \(n \geq n_0\),有 \(0 \leq c*g(n) \leq f(n) \}\),
以及 \(\omega\) 符號,讀作“小omega”,定義為:
對于任意給定的函式 \(g(n)\):\(\omega(g(n)) = \{ f(n)\):存在常量 \(c\) 和 \(n_0\) ,使得對于所有 \(n \geq n_0\),有 \(0 \leq c*g(n) < f(n) \}\),
看了這么多,你一定在想,這是什么東西?其實后面四個符號都是從 Theta 符號衍生而來的,大O和小o表示漸進上界,大Omega和小omega是漸進下界,
或者說人話,Theta表示這個演算法運行速度就是g(n)這么快;大O表示這個演算法運行速度至少和g(n)一樣快;小o表示這個演算法運行速度必定快于g(n);大Omega表示這個演算法速度至少和g(n)一樣慢;小omega表示這個演算法必定慢于g(n),一眼看來是有點亂,但相信大家多看幾遍也就明白了,
何為時間復雜度
現在我們一句話就能說清楚什么是事件復雜度了:一個演算法運行時間的大O,或者說這個演算法最差情況下的運行效率,例如
插入排序時間復雜度:\(O(n^2)\)
歸并排序時間復雜度:\(O(n*lgn)\)
為什么一定要定義這么復雜呢?其實最重要的原因是,演算法是一門對于數學和邏輯要求很高的學科,包含了大量的證明和計算,這就要求其必須有著一套嚴密的符號規定與術語,
當然對于普通人而言,最重要的是表示我是真的學了演算法的以及我能聽懂別人在說什么,同時也可以偷偷懶,例如某一天有人告訴你“我這個演算法的時間復雜度是O(n)”,你一下子就明白了,如果沒有這些定義,那么應該怎么說?“如果輸入規模是n,那么我的這個演算法在最差情況下,運行時間和n呈線性關系,什么?你不知道什么是線性關系?線性關系是xxx”,這樣一想,還是時間復雜度這五個字聽著舒服些,
結語
前面兩篇文章的數學知識可能較多,但這確實無法避免,作者已經盡量減少了數學相關的內容,數學證明也盡量使用大白話來描述了,后續將逐步介紹一些演算法和資料結構,需要使用的數學知識相較于這兩章要少很多,所以讀者們如果真的數學底子不是很好的話,也不需要擔心,但作者依然建議有時間能夠學一學數學,畢竟研究計算機的那一波祖師爺可幾乎全是數學家呢,計算機天生就和數學分不開,如果有條件的話,可以先學習一下高中數學里數列的知識,然后當某一天感覺自己達到了瓶頸時,可以學習一下離散數學,如果非常有興趣的話,可以再學一學數論,
下一篇文章將會介紹排序演算法中最為常用的“堆排序”,
原文鏈接:albertcode.info
個人博客:albertcode.info
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71904.html
標籤:其他
下一篇:SAS9.4的問題