tensorflow object detection API自己訓練的資料集檢測影像score很低而且檢測不出物體。
自己的訓練集和validation集是拍照之后把像素調小,大概幾百*幾百像素這種,圖片大小不一。300左右在training set,有些影像之間很類似。66張在validation set. 用labellmg標定label如下:



用的是Faster R-CNN Inception v2 原型的configuration檔案修改的,只修改了對應的路徑,其他引數是默認值。
運行的python程式是把min_score_thresh修改到很小0.00000005接近0%才能看到bounding box.
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.0000000005)
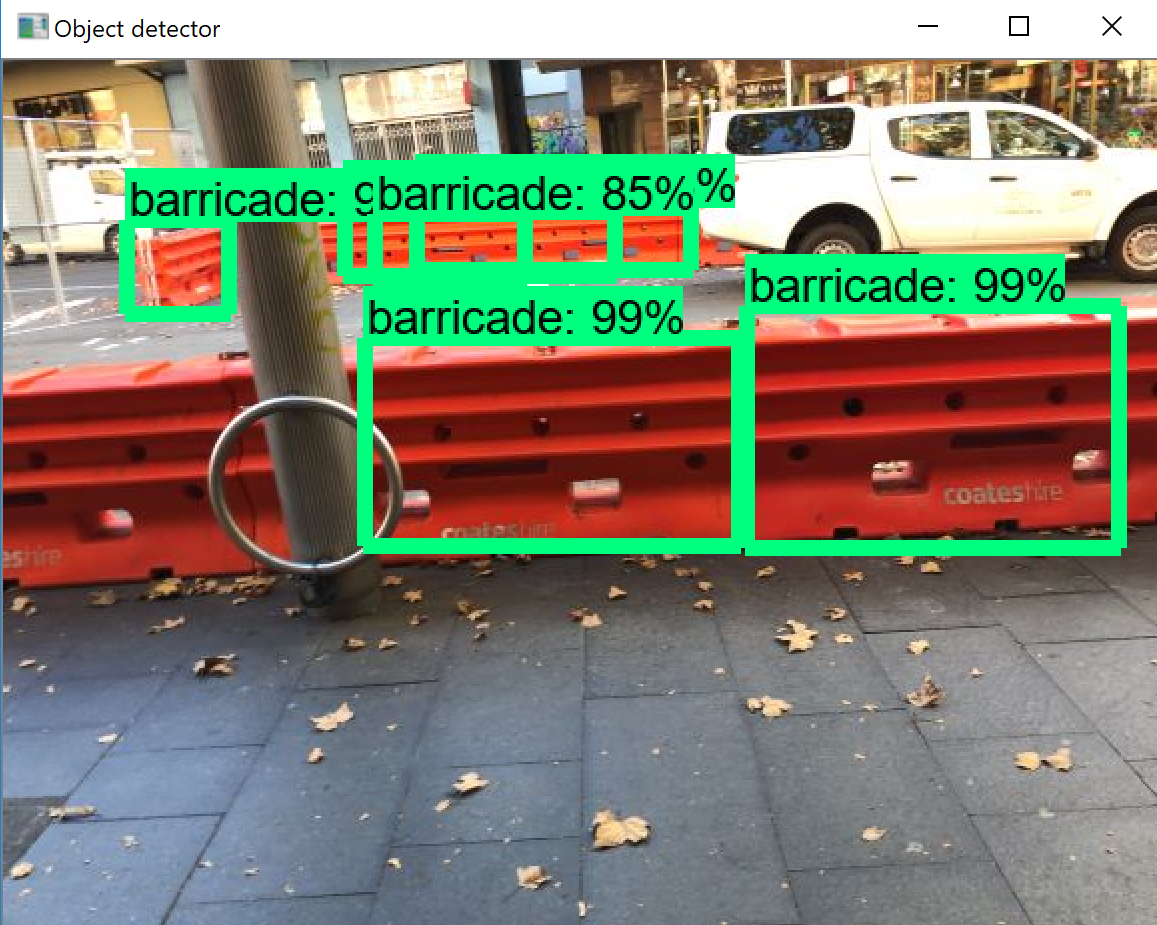
能確定程式執行沒有問題,但是懷疑可能是閾值或者影像訓練集有問題。因為這種建筑圍欄都是連在一起的,每次我只能標注label一個,周邊都是不完整的建筑圍欄,如上圖。訓練完的detector去檢測,結果如下:

應該也沒有過擬合,loss損失的影像:
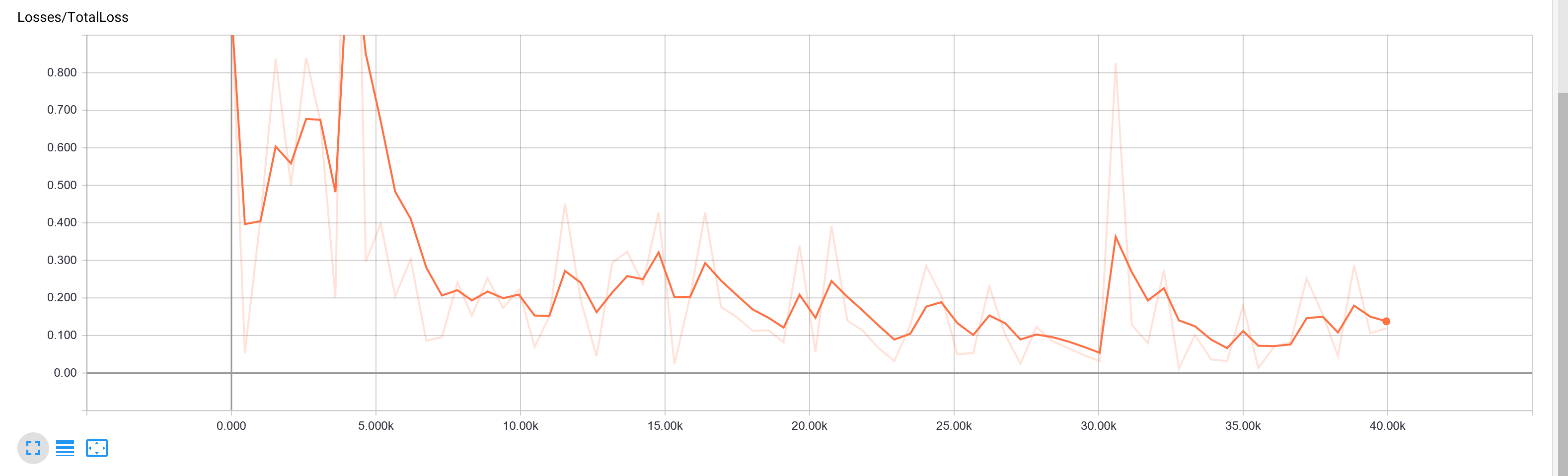
請問如何修改才能正確檢測出橙色塑料圍欄?
uj5u.com熱心網友回復:
問題解決。pre-trained model的代碼之前修改錯了。
fine_tune_checkpoint: "C:/Users/z5144967/tensorflow1/models/research/object_detection/faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt"
這句話之前被我誤注釋掉了!!一定要保留啊!!!
uj5u.com熱心網友回復:
請問是在模型組態檔.config中的嗎
uj5u.com熱心網友回復:
感謝!之前看一個帖子說要把那兩行刪掉,結果就怎么都檢測不出來物體,還好看到了你的回答。轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71926.html
標籤:機器視覺