開發四年只會寫業務代碼,分布式高并發都不會還做程式員?->>>
《推薦系統實踐》2.4中給了不同k值對應的召回率、準確率等,但我算出來的和書里的不同。
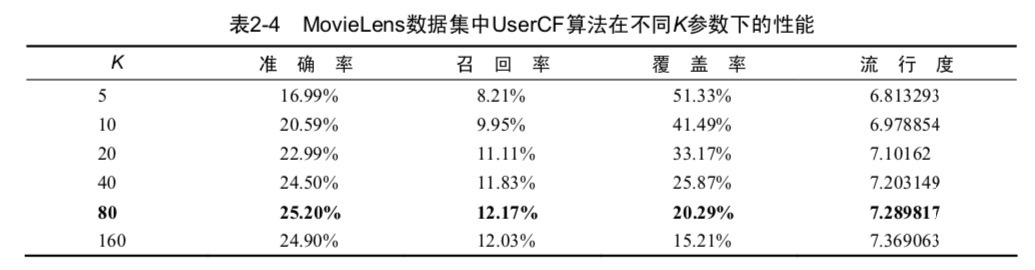
用的資料集是:https://grouplens.org/datasets/movielens/1m/ 根據書里的描述6000用戶,4000電影,100w條評分。
uj5u.com熱心網友回復:
作者使用的把100萬資料分為8分,其中7份作為訓練集,1份作為測驗集 資料集劃分的比例不同,最后得到的資料會有一些不同。當你的測驗集比例太小,得到的結果可能會偏低。
再一個得到的結果不可能完全相同,還是因為每一條資料是進入測驗集還是進入訓練集是隨機的。 完全相同反而感覺有點不能理解。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71935.html
標籤:其他技術討論專區
下一篇:刷機錯誤,求指導