前一段時間發現有一些containerd集群出現了Pod卡在Terminating的問題,經過一系列的排查發現是containerd對底層例外處理的問題,最后雖然通過一個短小的PR修復了這個bug,但是找到bug的程序和對問題的反思還是值得和大家分享的,
本文中會借由排查bug的程序來分析kubelet洗掉Pod的呼叫鏈,這樣不僅僅可以了解containerd的bug,還可以借此了解更多Pod洗掉不掉的原因,在文章的最后會對問題進行反思,來探討OCI出現的問題,
一個洗掉不掉的Pod
可能大家都會遇到這種問題,就是集群中有那么幾個Pod無論如何也洗掉不掉,看起來和下圖一樣,當然可有很多可能導致Pod卡在Terminating的原因,比如mount目錄被占用、dockerd卡死了或鏡像中有“i”屬性的檔案,因為節點上復雜的組件(docker、containerd、cri、runc)和過長的呼叫鏈,導致很難瞬間定位出現問題的位置,所以一般遇到此類問題都會通過日志、Pod的資訊和容器的狀態來逐步縮小排查范圍,

當然首先看下集群的資訊,發現沒有使用docker而直接用的cri和containerd,直接使用containerd照比使用docker會有更短的呼叫鏈和更強的魯棒性,照比使用docker應該更穩定才對(比如經常出現的docker和containerd資料不一致的問題在這里就不會出現),接下來當然是查看kubelet日志,如下(只保留了核心部分),從這條日志中可以發現貌似是kubelet呼叫cri介面,最終呼叫runc去洗掉容器時報錯導致洗掉失敗,
$ journalctl -u kubelet
Feb 01 11:37:27 VM_74_45_centos kubelet[687]: E0201 11:37:27.241794 687 pod_workers.go:190] Error syncing pod 18c3d965-38cc-11ea-9c1d-6e3e7be2a462 ("advertise-api-bql7q_prod(18c3d965-38cc-11ea-9c1d-6e3e7be2a462)"), skipping: error killing pod: [failed to "KillContainer" for "memcache" with KillContainerError: "rpc error: code = Unknown desc = failed to kill container \"55d04f7c957e81fcf487b0dd71a4e50fe138165303cf6e96053751fd6770172c\": unknown error after kill: runc did not terminate sucessfully: container \"55d04f7c957e81fcf487b0dd71a4e50fe138165303cf6e96053751fd6770172c\" does not exist\n: unknown"
接下來我們打算分析下容器當前的狀態,簡單介紹下,containerd中用container來表示容器、用task來表示容器的運行狀態,創建一個容器相當于創建container,而把容器運行起來相當于創建一個task并把task狀態置為Running,當然停掉容器就相當于把task的狀態設定為Stopped,通過ctr命令看下containerd中container和task的狀態,容器55d04f對應的container和task都還在、task狀態是STOPPED,接下來查看containerd日志,我們節選了一小部分,發現了如下現象,第一條日志是stop容器55d04f時做umount失敗,接下來都是kill容器55d04f時發現container不存在,
error="failed to handle container TaskExit event: failed to stop container: failed rootfs umount: failed to unmount target /run/containerd/io.containerd.runtime.v1.linux/k8s.io/55d04f.../rootfs: device or resource busy: unknown"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
當然得到這些資訊直徑訓認為排查方向是:
- 為何rootfs會被占用,只要找出來是誰在占用rootfs就可以解決問題了
- 既然umount報錯,我們是否可以使用lazy umount
- 反正之后containerd還會重試,再后來的重試中是否可以正確洗掉容器
第一個選項直接被排除了,看起來占用rootfs的行程并不是長期存在,等發現問題登錄到節點上排查時行程已經不在了,如果不是常駐行程問題就變得麻煩了,可能是某個周期執行的監控組件,也可能是用戶的某個日志收集容器某次收集時間較長在rootfs上多停留了一會,
處于懶惰的本能,我們先嘗試下第二個方案,剛剛我們說過容器在containerd中被定義為container和task,查看容器資訊時發現task并沒有被刪掉,于是我們直接在containerd的代碼中找到了umount容器rootfs的代碼,如下(為了閱讀體驗,已經簡化):
func (p *Init) delete(ctx context.Context) error {
err := p.runtime.Delete(ctx, p.id, nil)
// ...
if err2 := mount.UnmountAll(p.Rootfs, 0); err2 != nil {
log.G(ctx).WithError(err2).Warn("failed to cleanup rootfs mount")
if err == nil {
err = errors.Wrap(err2, "failed rootfs umount")
}
}
return err
}
func unmount(target string, flags int) error {
for i := 0; i < 50; i++ {
if err := unix.Unmount(target, flags); err != nil {
switch err {
case unix.EBUSY:
time.Sleep(50 * time.Millisecond)
continue
default:
return err
}
}
return nil
}
return errors.Wrapf(unix.EBUSY, "failed to unmount target %s", target)
}
containerd創建容器時會創建一個containerd-shim行程來管理創建出來的容器,原本containerd對容器行程的操作就轉化成了containerd對shim的RPC呼叫;而呼叫runc來操作容器的作業自然就會交給shim來做,這樣最大的好處就是可以方便的實作live-restore能力,也就是即使containerd重啟也不會影響到容器行程,
上面代碼中的 delete函式就是由containerd-shim呼叫的,函式中主要作業有兩個:呼叫runc delete刪掉容器、呼叫umount卸載掉容器的rootfs,containerd日志中第一次device busy導致的umount失敗就是在這里產生的,當然在umount函式中還是有個短暫的重試的,看來社區還是考慮到了偶爾可能會出現rootfs被占用的情況(懷疑是容器行程還沒來的急被回收,但在某些場景下,可能這個重試的時間還有點短),
這里要注意unmount的flags是0,查看docker代碼,發現docker在umount時加了MNT_DETACH,在簡單地修改了shim的代碼后,在節點上測驗,果然添加了MNT_DETACH以后就不會出現device busy了,于是自信的向社區提了PR,結果得到的回復卻是:
What typically happens in cases like this is you there is a mount marked as private that gets copied into a new mount namespace.
A new mount namespace is created for every container, for systemd services that have MountPropagation or PrivateTmp defined, and these types of things.
When those namespaces are created they get a copy of the root namespace, anything that has a private mount cannot be unmounted until all the namespaces are shut down.
Mounts get marked private depending on the propagation defined on their root mount or if explicitly set.... so for example if you have /var/foo mounted and /var is mounted with mount private propagation, /var/foo will inherit the private propagation.In this case
MNT_DETACHonly detaches the mount and hides very real problems. Even if you remove the mountpoint the data will not be freed until (possibly?) a reboot or all other namespaces with copies of that mount in them are shut down.
大概意思就是如果你用了MNT_DETACH,會有一些真正的問題被藏起來,(這里有待測驗,我覺得社區里這個人回復的思路有問題),
看起來我們只能排查下為什么重試時還會失敗了,節點上執行洗掉Pod的流程還是比較長的,很難簡單通過幾個舉例直接說明問題,所以接下來分析下kubelet從cri到OCI洗掉容器的流程,
kubelet如何洗掉Pod中的容器
對于kubelet的分析就要從大名鼎鼎的SyncPod開始分析了,在SyncPod開始時會計算podContainerChanges,接下來整個流程都是根據podContainerChanges的情況來執行對容器的操作,我們假設change就是KillPod,而kubelet執行KillPod會先通過創建多個goroutine并發執行StopContainers,等到所有Containers都洗掉成功后再洗掉Pod的Sandbox,具體呼叫流程如下:
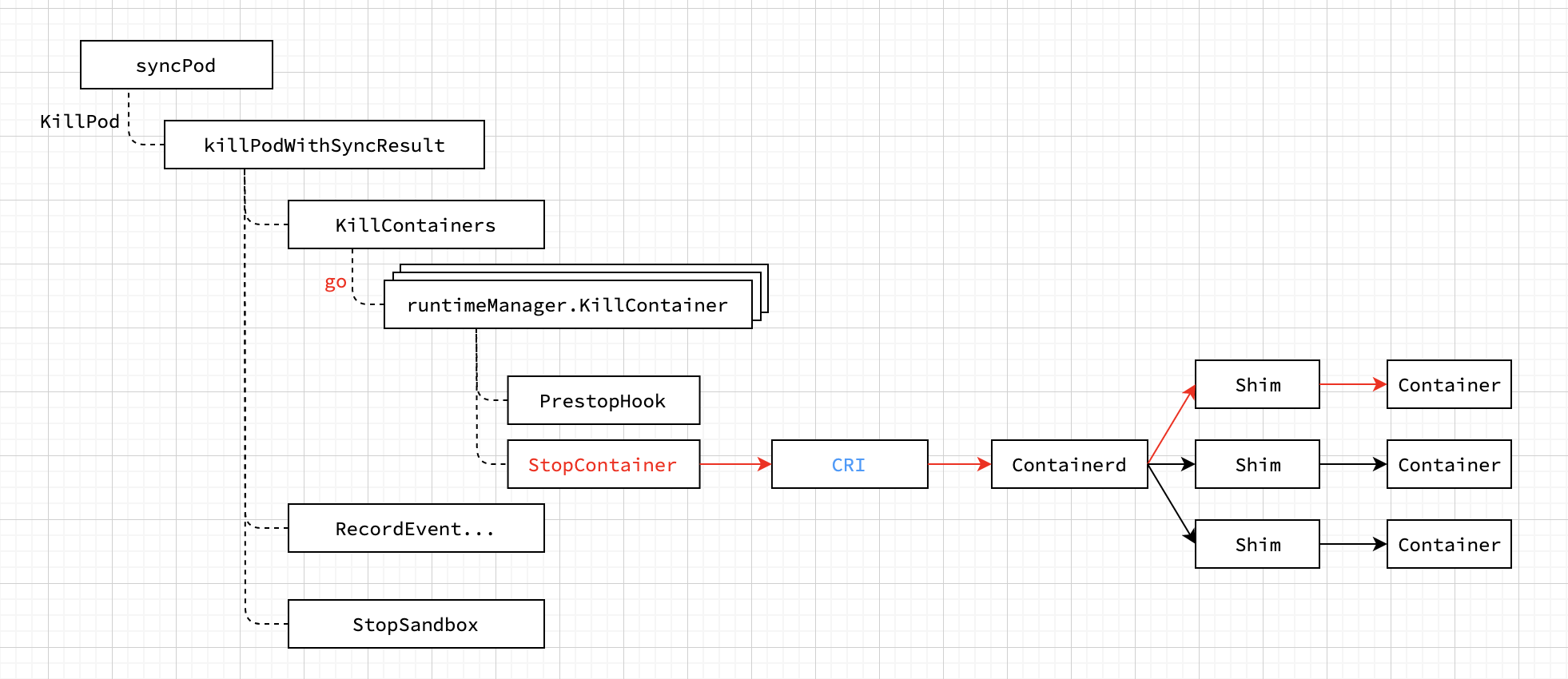
圖中用紅色標記的StopContainer其實就是最終呼叫了cri介面(container runtime interface),比如以下是兩個和洗掉容器相關的兩個cri介面,Kubernetes要求每種容器運行時都要實作cri介面,docker通過docker-shim實作了cri介面;而container通過cri插件實作了cri介面,兩者并沒區別,比如運行時是containerd時,對cri的呼叫就會通過containerd-shim最終在容器上產生影響,
// StopContainer stops a running container with a grace period (i.e., timeout).
// This call is idempotent, and must not return an error if the container has
// already been stopped.
// TODO: what must the runtime do after the grace period is reached?
StopContainer(context.Context, *StopContainerRequest) (*StopContainerResponse, error)
// RemoveContainer removes the container. If the container is running, the
// container must be forcibly removed.
// This call is idempotent, and must not return an error if the container has
// already been removed.
RemoveContainer(context.Context, *RemoveContainerRequest) (*RemoveContainerResponse, error)
當請求到了cri后,剩下的任務就都交給了containerd和containerd-cri,cri以插件的方式運行在containerd中,本質和containerd是同一個行程,因此可以通過containerd提供的client直接通過函式呼叫containerd提供的service,正常情況下整個呼叫鏈如下圖所示,
另外,cri插件中存在一個eventloop專門處理從containerd中獲取的event,比如當容器洗掉后,會收到TaskExit事件,這是cri會做清理作業;比如當容器oom時,會收到OOMKill事件,cri除了清理還會更新Reason,接下來我們了解下整個洗掉流程
- 當kubelet呼叫cri的StopContainer介面后,cri會呼叫containerd的
task.Kill介面(這里的task就是containerd中用來表示容器運行狀態的模塊),containerd收到請求后會呼叫containerd-shim的kill介面,而containerd-shim會通過命令列工具runc來kill掉容器行程,runc雖然不是守護行程,但是也有部分資料會被持久化到檔案系統中,執行runc kill后,不只會給容器行程發送信號,同時還會修改runc的持久化資料,另外,當容器行程被干掉后,會被父行程shim回收掉, - shim成功干掉容器后,會給cri發送TaskExit的事件,當cri收到事件后會呼叫containerd的
task.Delete介面,這個介面會先通過shim清理runc保留的容器持久化資料和容器運行時所用的rootfs,當兩者都被清理后,shim留著也沒用了,這時干脆直接發信號kill掉shim,并清理掉containerd保存的task資訊,這時containerd中和容器狀態相關的資訊就都消失了,當然containerd中的container還完好無損, - 哪怕代碼中不存在bug,這么長的呼叫鏈也可能會遇到系統問題,eventLoop呼叫
task.Delete如果回傳錯誤會把當前的event放到一個backoff佇列,等過一段時間拿出來重試,這樣就保證哪怕當前對一個容器的操作失敗了,過段時間還可以重試,
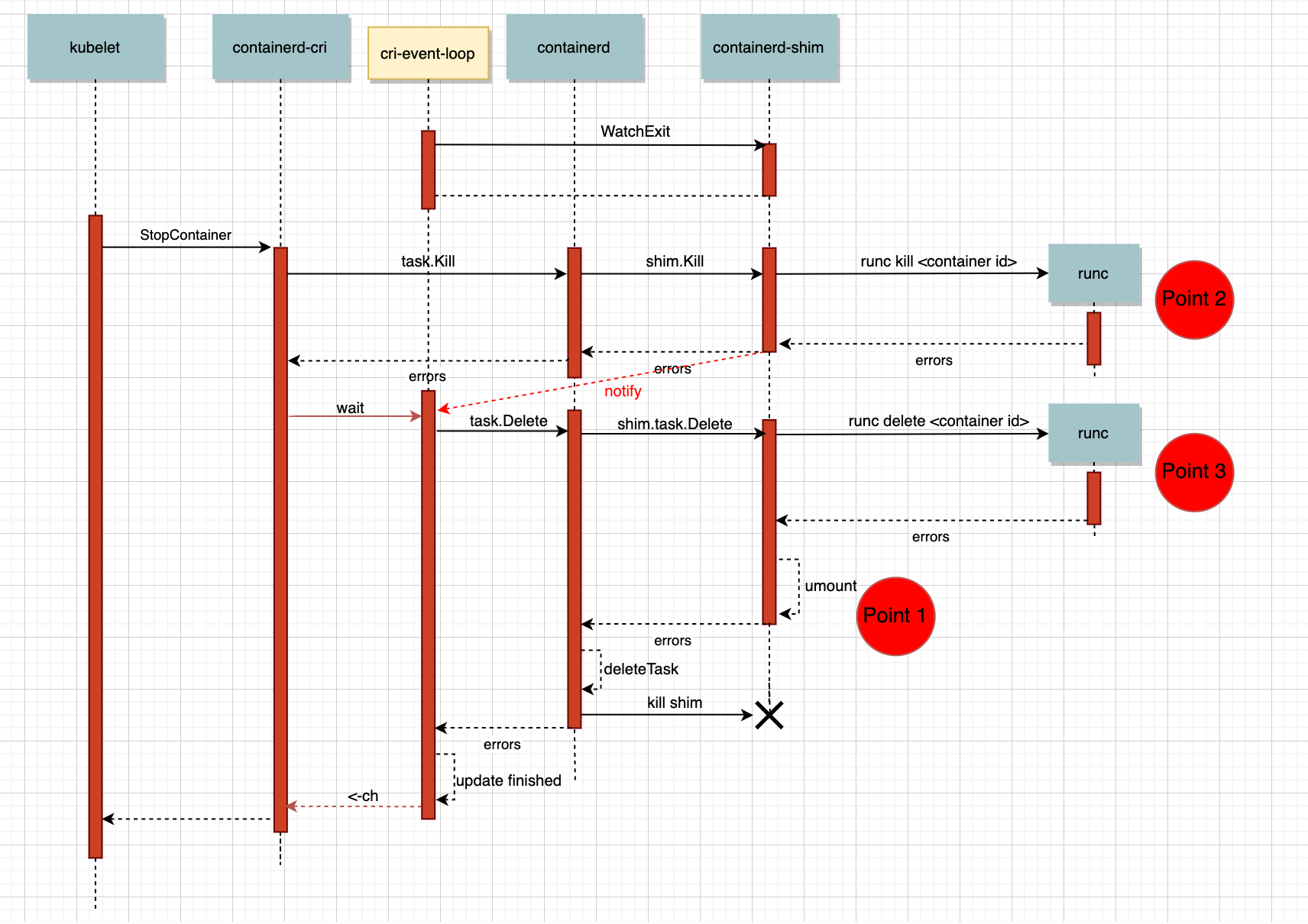
回到之前的問題上,可能有些聰明的同學通過上面的流程圖和分析之前的日志就可以猜到答案了,沒猜到也沒關系,現在和大家一起分析下,還記的當時containerd的日志分成兩部分么,首先是執行umount報錯device busy,之后反復出現unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist",這兩部分和我們上面說的“delete task時清理rootfs,如果失敗了會隔段時間進行重試”這個表述很接近,我們再把呼叫的流程圖畫的更細點,這下應該就可以在圖中找到答案了,
當容器被kill掉之后還一切正常,cri收到了容器退出的信號,呼叫containerd的task.Delete()時,可以注意到,這里多了個withKill選項(上面的流程中其實也有,只不過被省略掉了),添加這個選項會在呼叫shim的Delete介面之前再次呼叫Kill,這樣可以防止Delete了正在運行的容器,算是“悲觀”的決定,
在第一次task Delete的流程中,一切運行的都很順暢,runc kill掉一個已經掛掉的容器也沒什么問題,直到umount容器的rootfs,發現rootfs被占用了,而且在umount的50次重試中占用rootfs的行程并沒有退出,shim只好通過containerd向cri回傳一個錯誤,cri會在之后的一段時間里重新嘗試處理剛剛的這個event,
在接下來重試 task Delete中,會和第一次執行一樣,都會在delete之前執行kill,但由于第一次runc delete成功的洗掉了runc所持久化的容器資訊,重試時執行runc kill會報錯container does not exist,不巧的是shim和containerd并沒有特別處理這個錯誤資訊,而是直接回傳給了cri,這就導致了cri洗掉容器會失敗,并且再也無法umount容器的rootfs了,cri中的容器無法被刪掉,自然發起洗掉流程的syncPod也會出現問題,這樣最終就導致了Pod卡在了Terminating,
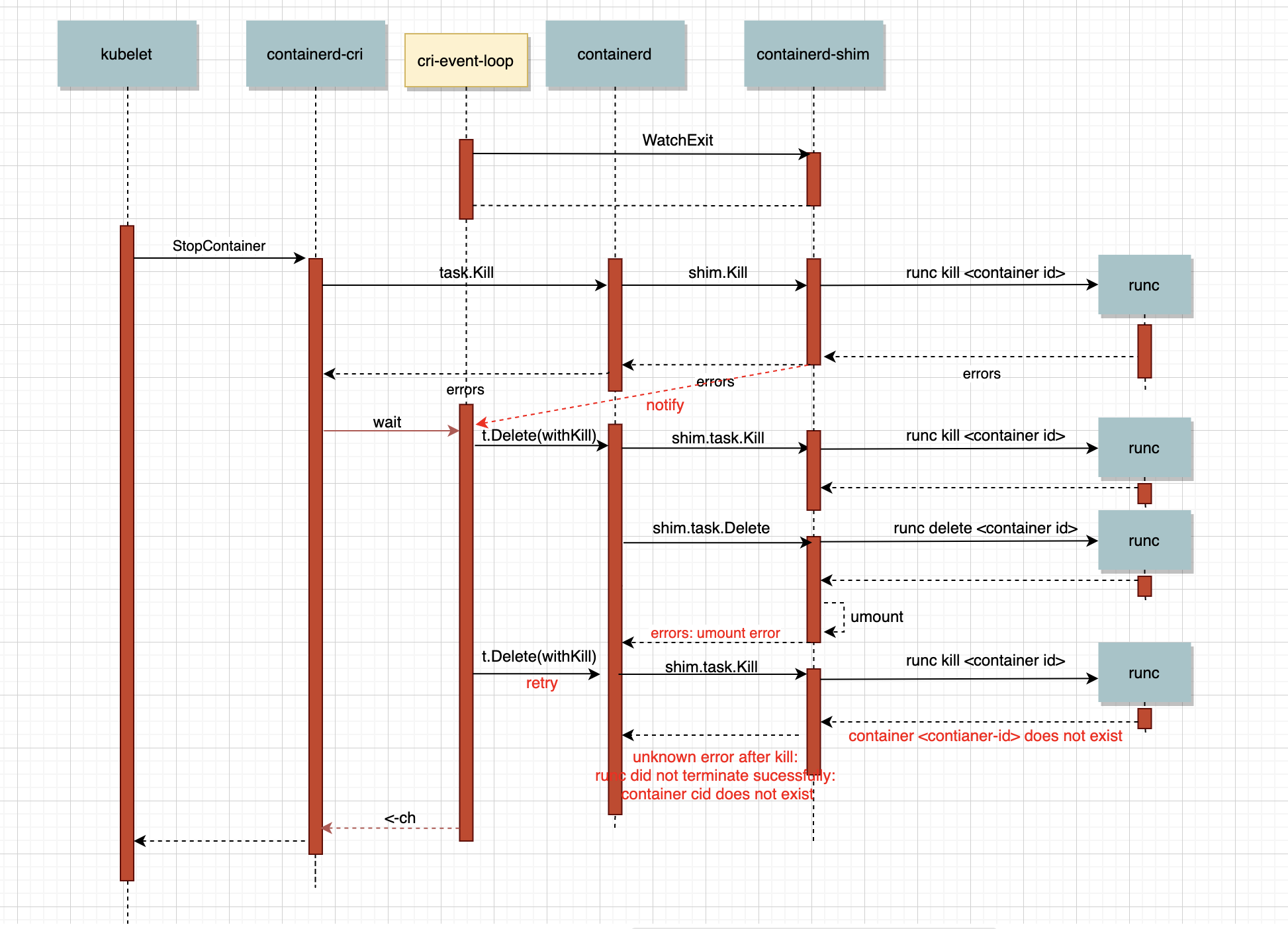
最終修復與反思
當然這里的修復也很簡單,只需要在呼叫runc kill后添加特殊判斷就可以了,具體修復的pr見https://github.com/containerd/containerd/pull/4214,目前已經合并到主干,并且回溯到1.2的版本中了,很多時候發現問題遠比修復問題要復雜的多,雖然最終修復bug的代碼很簡單,但是整個為了發現bug,我們用了好幾天時間來分析梳理整個流程,簡單看下錯誤處理的代碼,這里的error就是呼叫runc出現錯誤的回傳結果,
if strings.Contains(err.Error(), "os: process already finished") ||
strings.Contains(err.Error(), "container not running") ||
strings.Contains(strings.ToLower(err.Error()), "no such process") ||
err == unix.ESRCH {
return errors.Wrapf(errdefs.ErrNotFound, "process already finished")
} else if strings.Contains(err.Error(), "does not exist") {
// we add code here !
return errors.Wrapf(errdefs.ErrNotFound, "no such container")
}
return errors.Wrapf(err, "unknown error after kill")
}
顯而易見這坨代碼存在問題:
containerd-shim原本目的就是支持各種OCI工具,但是卻把runc的錯誤處理資訊寫死在呼叫OCI的路徑上,這樣最終可能導致shim只能為runc服務,而不好適配其他的OCI,比如完善containerd測驗時就會發現這坨代碼對crun并不work(crun是用純c語言實作的OCI工具),不可能在containerd中適配每一種OCI工具,所以問題還是出現在制定OCI規范時沒考慮到錯誤處理的情況,同樣我們也和OCI社區提了issue,
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71941.html
標籤:其他