前一陣有客戶docker18.06.3集群中出現Pod卡在terminating狀態的問題,經過排查發現是containerd和dockerd之間事件流阻塞,導致后續事件得不到處理造成的,
定位問題的程序極其艱難,其中不乏大量工具的使用和大量的原始碼閱讀,本文將梳理排查此問題的程序,并總結完整的dockerd和contaienrd之間事件傳遞流程,一步一步找到問題產生的原因,特寫本文記錄分享,希望大家在有類似問題發生時,能夠迅速定位、解決,
對于本文中提到的問題,在docker19中已經得到解決,但docker18無法直接升級到docker19,因此本文在結尾參考docker19給出了一種簡單的解決方案,
洗掉不掉Pod
相信大家在解決現網問題時,經常會遇到Pod卡在terminating不動的情況,產生這種情況的原因有很多,比如《Pod Terminating原因追蹤系列之一》中提到的containerd沒有正確處理錯誤資訊,當然更常見的比如umount失敗、dockerd卡死等等,
遇到此類問題時,通常通過kubelet或dockerd日志、容器和Pod狀態、堆疊資訊等手段來排查問題,本問題也不例外,首先登錄到Pod所在節點,使用以下兩條指令查看容器狀態:
#查看容器狀態,看到容器狀態為up
docker ps | grep <container-id>
#查看task狀態,顯示task的狀態為STOPPED
docker-container-ctr --namespace moby --address var/run/docker/containerd/docker-containerd.sock task ls | grep <container-id>

可以看到在dockerd中容器狀態為up,但在containerd中task狀態為STOPPED,兩者資訊產生了不一致,也就是說由于某種原因containerd中的狀態資訊沒有同步到dockerd中,為了探究為什么兩者狀態產生了不一致,首先需要了解從dockerd到containerd的整體呼叫鏈:
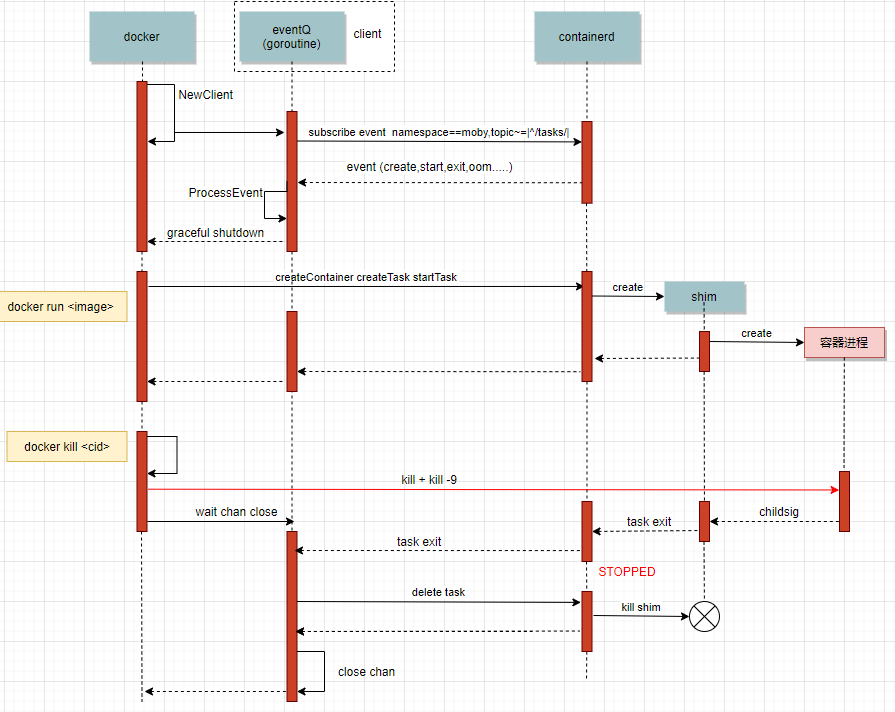
當啟動dockerd時,會通過NewClient方法創建一個client,該client維護一條到containerd的gRPC連接,同時起一個協程processEventStream訂閱(subscribe)來自containerd的task事件,當某個容器的狀態發生變化產生了事件,containerd會回傳事件到client的eventQ佇列中,并通過ProcessEvent方法進行處理,processEventStream協程在除優雅退出以外永遠不會退出(但在有些情況下還是會退出,在后續會推出一篇文章,恰好是這種情況,敬請期待~),
當容器行程退出時,containerd會通過上述gRPC連接回傳一個exit的task事件給client,client接收到來自containerd的exit事件之后由ProcessEvent呼叫DeleteTask介面洗掉對應task,至此完成了一個容器的洗掉,
由于containerd一直處于STOPPED狀態,因此通過上面的呼叫鏈猜測會不會是task exit事件因為某種原因而阻塞掉了?產生的結果就是在containerd側由于發送了exit事件而進入STOPPED狀態,但由于沒有呼叫DeleteTask介面,因此本task還存在,
模擬task exit事件
通過發送task exit事件給一個卡住的Pod,來模擬容器結束的情況:
/tasks/exit {"container_id":"23bd0b1118238852e9dec069f8a89c80e212c3d039ba030cfd33eb751fdac5a7","id":"23bd0b1118238852e9dec069f8a89c80e212c3d039ba030cfd33eb751fdac5a7","pid":17415,"exit_status":127,"exited_at":"2020-07-17T12:38:01.970418Z"}
我們可以手動將上述事件publish到containerd中,但是需要注意的一點的是,在publish之前需要將上述內容進行一下編碼(參考containerd/cmd/containerd-shim/main_unix.go Publish方法),得到的結果如下圖,可以看到事件成功的被publish,也被dockerd捕獲到,但容器的狀態仍然沒有變化,
#將file檔案中的事件發送到containerd
docker-containerd --address var/run/docker/containerd/docker-containerd.sock publish --namespace moby --topic /tasks/exit < ~/file
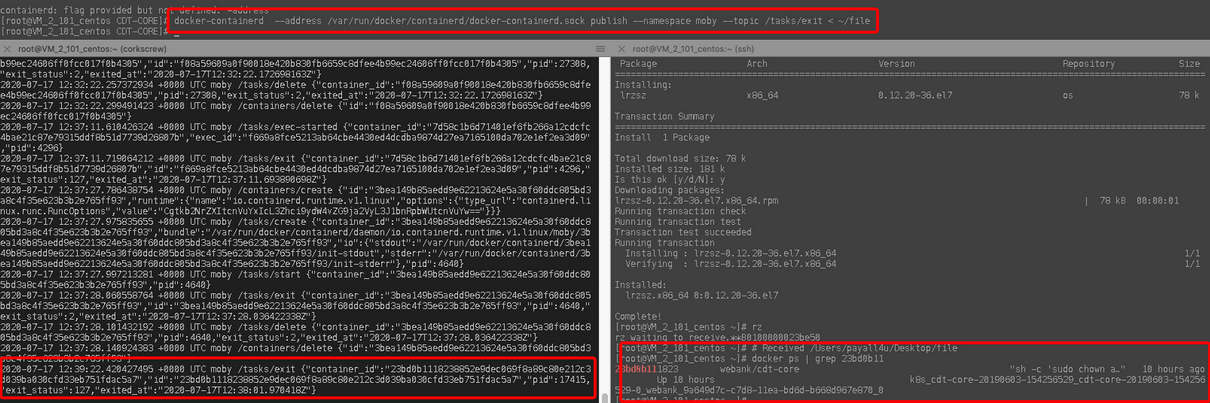
當我們查看docker堆疊日志(向dockerd行程發送SIGUSR1信號),發現有大量的Goroutine卡在append方法,每次publish新的exit事件都會增加一個append方法的堆疊資訊:
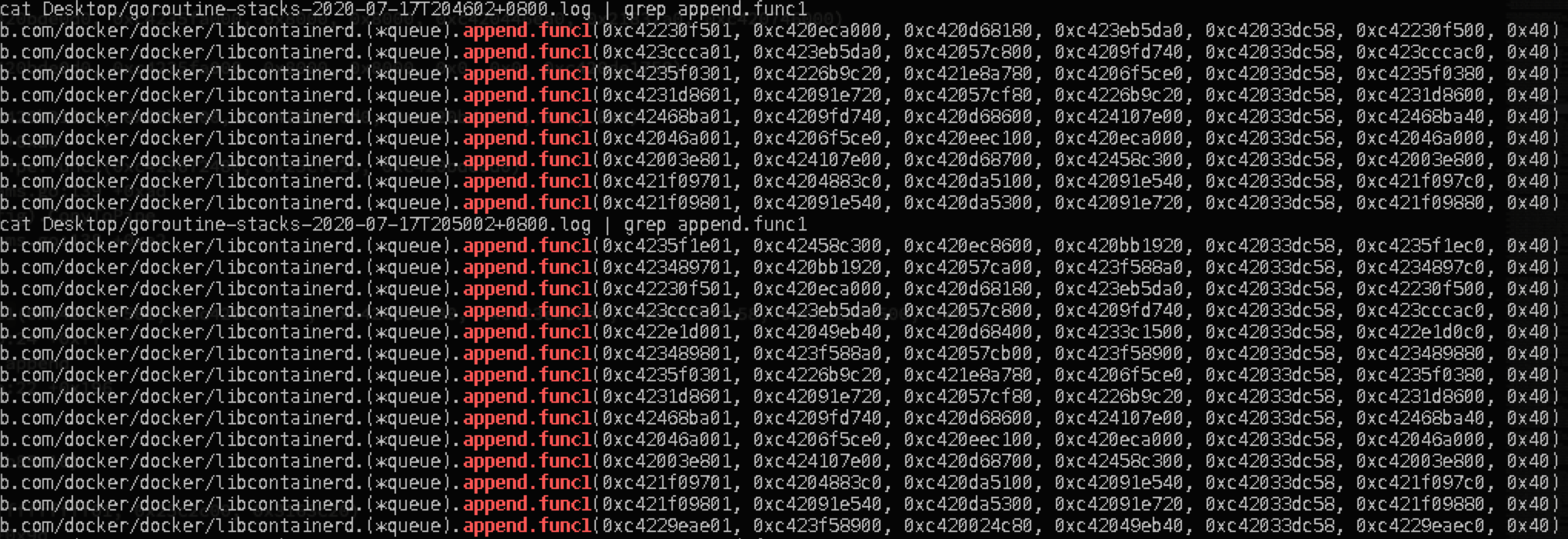
通過查看append方法的原始碼發現,append方法負責將收到的containerd事件放入eventQ,并執行回呼函式,對收到的不同型別事件進行處理:
func (q *queue) append(id string, f func()) {
q.Lock()
defer q.Unlock()
if q.fns == nil {
q.fns = make(map[string]chan struct{})
}
done := make(chan struct{})
fn, ok := q.fns[id]
q.fns[id] = done
go func() {
if ok {
<-fn
}
f()
close(done)
q.Lock()
if q.fns[id] == done {
delete(q.fns, id)
}
q.Unlock()
}()
}
形參中的id為container的id,因此對于同一個container它的事件是串行處理的,只有前一個事件處理結束才會處理下一個事件,且沒有超時機制,
因此只要eventQ中有一個事件發生了阻塞,那么在它后面所有的事件都會被阻塞住,這也就解釋了為什么每次publish新的對于同一個container的exit事件,都會在堆疊中增加一條append的堆疊資訊,因為它們都被之前的一個事件阻塞住了,
深入原始碼定位問題原因
為了找到阻塞的原因,我們找到阻塞的第一個exit事件append的堆疊資訊再詳細的看一下:
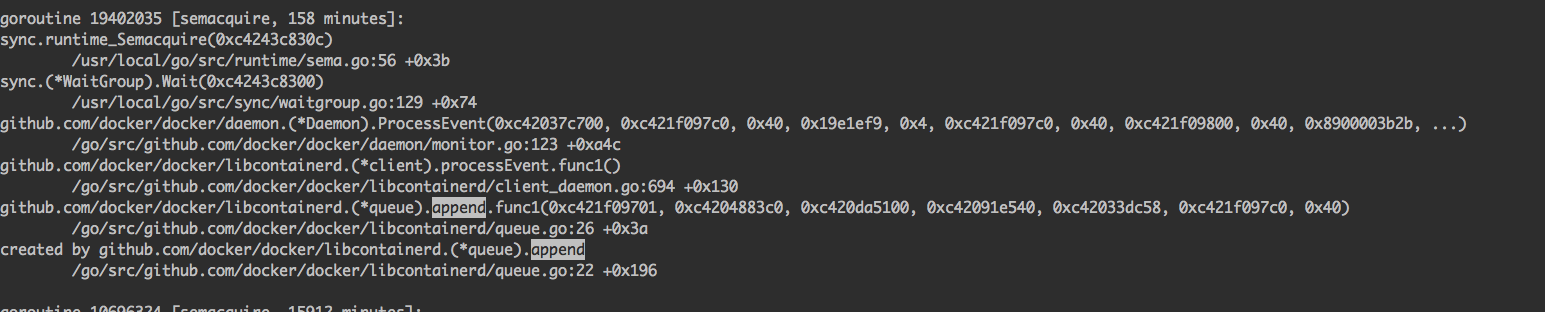
通過堆疊可以發現代碼卡在了docker/daemon/monitor.go檔案的123行(省略了不重要的代碼):
func (daemon *Daemon) ProcessEvent(id string, e libcontainerd.EventType, ei libcontainerd.EventInfo) error {
......
case libcontainerd.EventExit:
......
if execConfig := c.ExecCommands.Get(ei.ProcessID); execConfig != nil {
......
123行 execConfig.StreamConfig.Wait()
if err := execConfig.CloseStreams(); err != nil {
logrus.Errorf("failed to cleanup exec %s streams: %s", c.ID, err)
}
......
} else {
......
}
......
return nil
}
可以看到收到的事件為exit事件,并在第123行streamConfig在等待一個wg,這里的streamconfig為一個記憶體佇列,負責收集來自containerd的輸出回傳給客戶端,具體是如何處理io的在后面會細講,這里先順藤摸瓜查一下wg在什么時候add的:
func (c *Config) CopyToPipe(iop *cio.DirectIO) {
copyFunc := func(w io.Writer, r io.ReadCloser) {
c.Add(1)
go func() {
if _, err := pools.Copy(w, r); err != nil {
logrus.Errorf("stream copy error: %v", err)
}
r.Close()
c.Done()
}()
}
if iop.Stdout != nil {
copyFunc(c.Stdout(), iop.Stdout)
}
if iop.Stderr != nil {
copyFunc(c.Stderr(), iop.Stderr)
}
.....
}
CopyToPipe是用來將containerd回傳的輸出copy到streamconfig的方法,可以看到當來自containerd的io流不為空,則會對wg add1,并開啟協程進行copy,copy結束后才會done,因此一旦阻塞在copy,則對exit事件的處理會一直等待copy結束,我們再回到docker堆疊中進行查找,發現確實有一個IO wait,并阻塞在polls.Copy函式上:
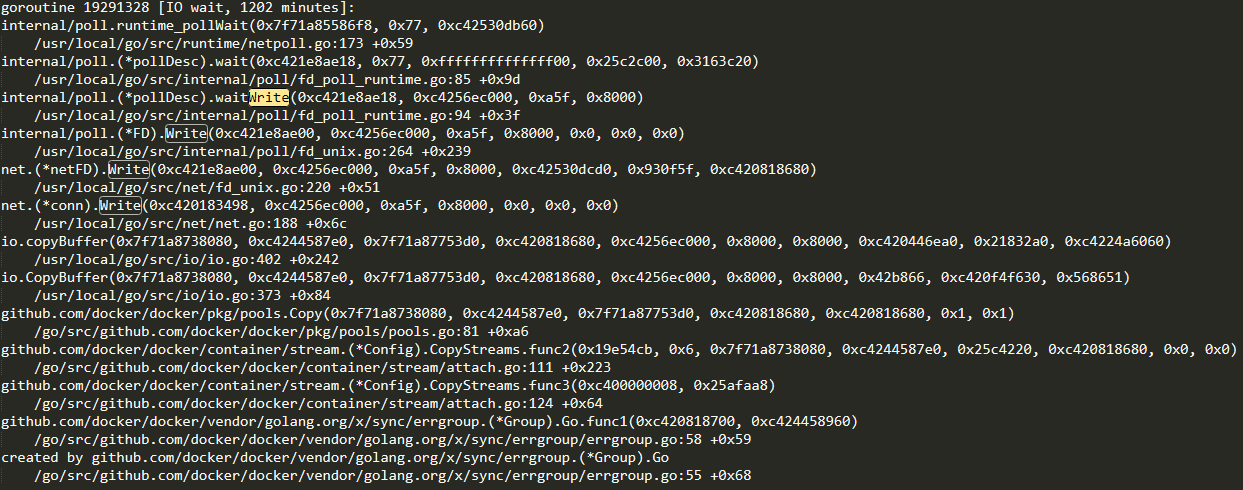
至此造成dockerd和containerd狀態不一致的原因已經找到了!我們來梳理一下,
首先通過查看dockerd和containerd狀態,發現兩者狀態不一致,由于containerd處于STOPPED狀態因此判斷在containerd發送task exit事件時可能發生阻塞,因此我們構造了task exit事件并publish到containerd,并查看docker堆疊發現有大量阻塞在append的堆疊資訊,證實了我們的猜想,
最后我們通過分析代碼和堆疊資訊,最終定位在ProcessEvent由于pools.Copy的阻塞,也會被阻塞,直到copy結束,而事件又是串行處理的,因此只要有一個事件處理被阻塞,那么后面所有的事件都會被阻塞,最終表現出的現象就是dockerd和containerd狀態不一致,
找出罪魁禍首
我們已經知道了阻塞的原因,但是究竟是什么操作阻塞了事件的處理?其實很簡單,此exit事件是由exec退出產生的,我們通過查看堆疊資訊,發現在堆疊有為數不多的ContainerExecStart方法,說明有exec正在執行,推測是客戶行為:
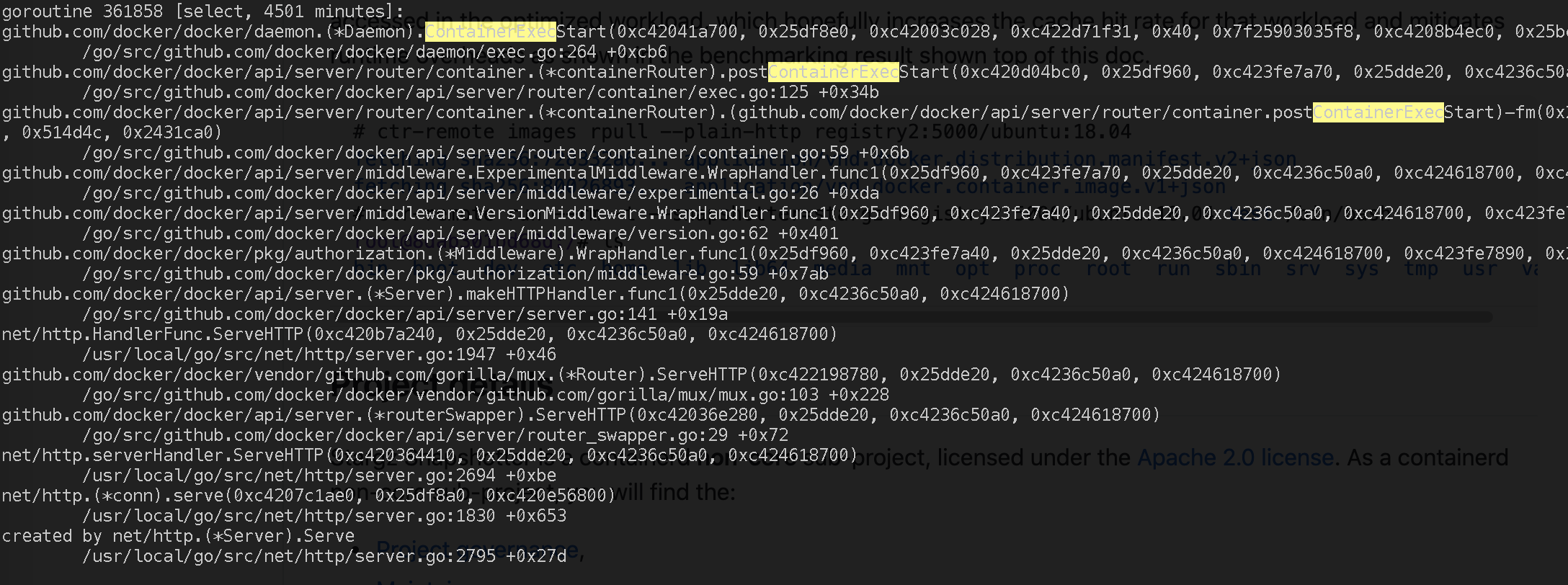
ContainerExecStart方法中第二個引數為exec的id值,因此可以使用gdb查找對應地址內容,查看其引數中的execId和terminating Pod中的容器的exexId(docker inspect可以查看execId,每個exec操作對應一個execId)是否一致,結果發現execId相同!因此可以斷定是由于exec退出,產生的exit事件阻塞了ProcessEvent的處理邏輯,通過閱讀原始碼總結出exec的處理邏輯:
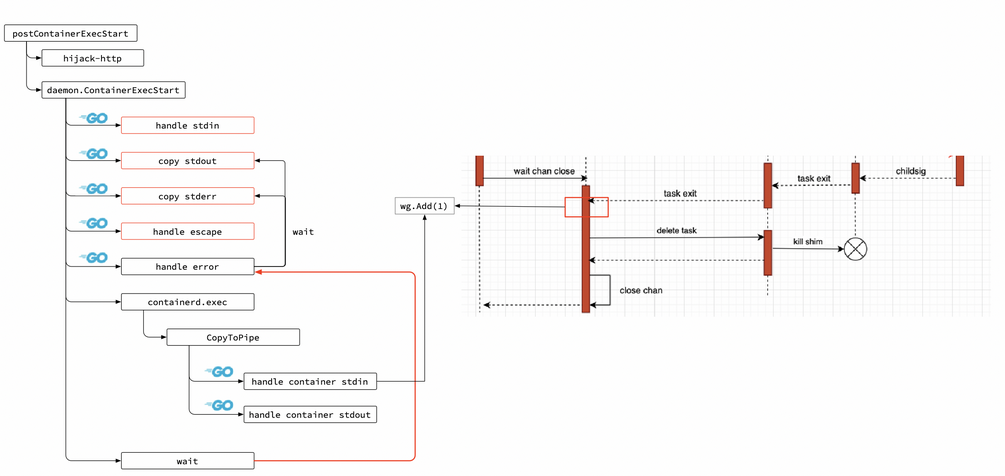
那么為什么exec的exit會導致Write阻塞呢?我們需要梳理一下exec的io處理流程看看究竟Write到了哪里,下圖為io流的處理程序:
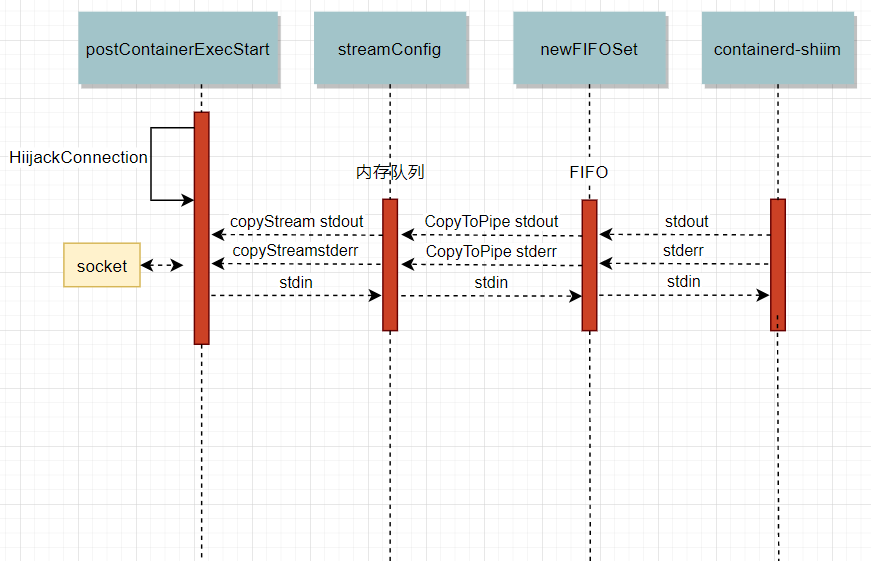
首先在exec開始時會將socket的輸出流attach到一個記憶體佇列,并啟動了?個goroutine用來把記憶體佇列中的內容輸出到socket中,除了記憶體佇列外還有一個FIFO佇列,通過CopyToPipe開啟協程copy到記憶體佇列,FIFO佇列用來接收containerd-shim的輸出,之后由記憶體佇列寫入socket,以response的方式回傳給客戶端,但我們的問題還沒有解決,還是不清楚為什么Write會阻塞住,不過可以通過gdb來定位到Write函式打開的fd,查看一下socket的狀態:
n, err := syscall.Write(fd.Sysfd, p[nn:max])
type FD struct {
// Lock sysfd and serialize access to Read and Write methods.
fdmu fdMutex
// System file descriptor. Immutable until Close.
Sysfd int
......
}
Write為系統呼叫,其引數中第一位即打開的fd號,但需要注意,Sysfd并非FD結構體的第一個引數,因此需要加上偏移量16位元組(fdMutex占16位元組)
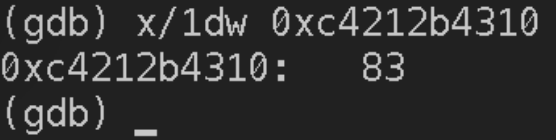
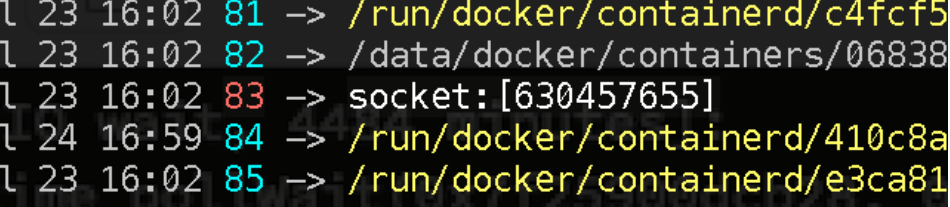
發現該fd為一個socket連接,使用ss查看一下socket的另一端是誰:
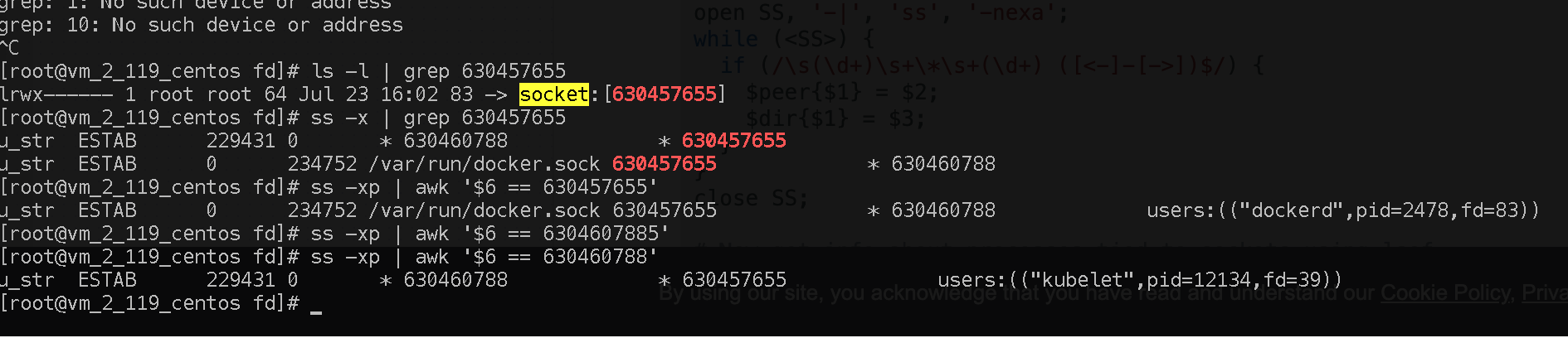
發現該fd為來自kubelet的一個socket連接,且沒有被關閉,因此可以判斷Write阻塞的原因正是客戶端exec退出以后,該socket沒有正常的關閉,使Write不斷地向socket中寫資料,直到寫滿阻塞造成的,
通過詢問客戶是否使用過exec,發現客戶自己寫了一個客戶端并通過kubelet exec來訪問Pod,與上述排查結果相符,因此反饋客戶可以排查下客戶端代碼,是否正確關閉了exec的socket連接,
修復與反思
其實docker的這個事件處理邏輯設計并不優雅,客戶端的行為不應該影響到服務端的處理,更不應該造成服務端的阻塞,因此本打算提交pr修復此問題,發現在docker19中已經修復了此問題,而docker18的集群無法直接升級到docker19,因為docker會持久化資料到硬碟上,而docker19不支持docker18的持久化資料,
雖然不能直接升級到docker19,不過我們可以參考docker19的實作,在docker19中通過添加事件處理超時的邏輯避免事件一直阻塞,在docker18中同樣可以添加一個超時的邏輯!
對exit事件添加超時處理:
#/docker/daemon/monitor.go
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
execConfig.StreamConfig.WaitWithTimeout(ctx)
cancel()
#/docker/container/stream/streams.go
func (c *Config) WaitWithTimeout(ctx context.Context) {
done := make(chan struct{}, 1)
go func() {
c.Wait()
close(done)
}()
select {
case <-done:
case <-ctx.Done():
if c.dio != nil {
c.dio.Cancel()
c.dio.Wait()
c.dio.Close()
}
}
}
這里添加了一個2s超時時間,超時則優雅關閉來自containerd的事件流,
至此一個棘手的Pod terminating問題已經解決,后續也將推出小版本修復此問題,雖然修復起來比較簡單,但問題分析的程序卻無比艱辛,希望本篇文章能夠對大家今后的問題定位打開思路,謝謝觀看~
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71948.html
標籤:其他
上一篇:二叉樹基本操作問題