在騰訊,已經有很多產品已使用或者正在嘗試使用istio來作為其微服務治理的基礎平臺,不過在使用istio時,也有一些對通信性能要求較高的業務會對istio的性能有一些擔憂,由于envoy sidecar的引入,使兩個微服務之間的通信路徑變長,導致服務延時受到了一些影響,istio社區一直以來也有這方面的聲音,基于這類抱怨,我們希望能夠對這一通信程序進行優化,以更好的滿足更多客戶的需求,
首先,我們看一下istio資料面的通信模型,來分析一下為什么會對延時有這么大的影響,可以看到,相比于服務之間直接通信,在引入istio 之后,通信路徑會有明顯增加,主要包括多出了兩次本地行程之間的tcp連接通信和用戶態網路代理envoy對資料的處理,所以我們的優化也分為了兩部分進行,
內核態轉發優化
那么對于本地行程之間的通信優化,我們能做些什么呢?
其實在開源社區已經有了這方面的探索了,istio官方社區在2019年1月的時候已經有了這方面討論,在檔案里面提到了使用ebpf的技術來做socket轉發的資料代理,使資料在socket層進行轉發,而不需要再往下經過更底層的TCP/IP協議堆疊的一個處理,從而減少它在資料鏈路上的通信鏈路長度,
另外,網路開源專案cilium也在這方面有一個比較深入的實踐,同樣也是使用了ebpf的技術,不過在cilium中本地網路加速只是其中的一個模塊,沒有作為一個獨立的服務進行開發實踐,在騰訊云內部沒法直接使用,這也促使了我們開發一個無依賴的解決方案,
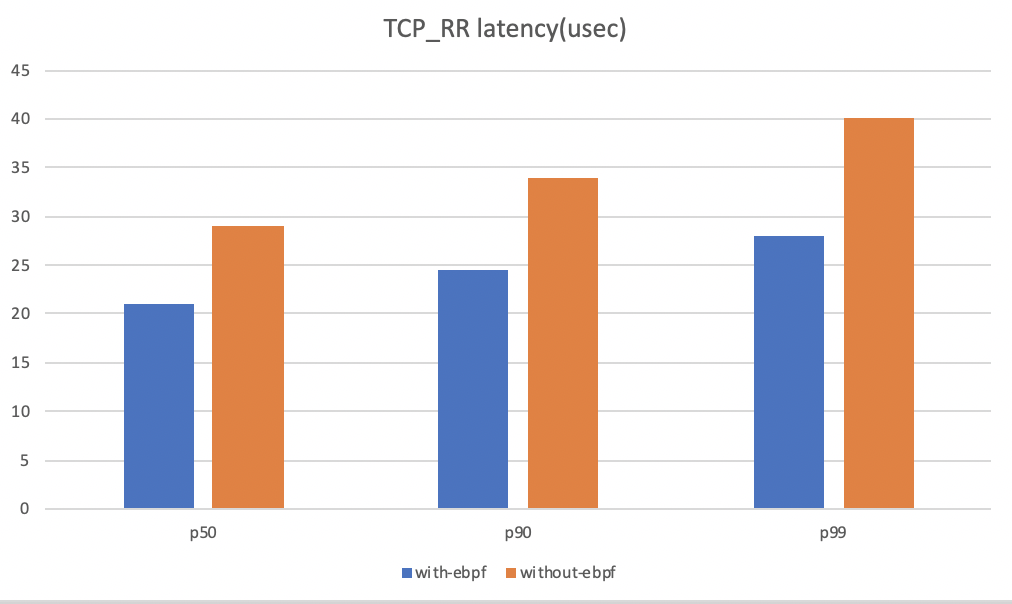
當然在初期的時候,我們也對ebpf的技術進行了一個驗證,從驗證結果中可以看到,在使用了ebpf的技術之后,它的延時大概有20%到30%的提升,說明ebpf的技術應用在本地通訊上還是有一定優化能力的,
簡單介紹一下ebpf,看一下它是怎么做到加速本地通訊的,首先ebpf可以看作是一個運行在內核里面的虛擬機,用戶撰寫的ebpf程式可以被加載到內核里面進行執行,內核的一個verify組件會保證用戶的ebpf程式不會引發內核的crash,也就是可以保證用戶的ebpf程式是安全的,目前ebpf程式主要用來追蹤內核的函式呼叫以及安全等方面,下圖可以看到,ebpf可以用在很多內核子系統當中做很多的呼叫追蹤,
另外一個比較重要的功能,就是我們在性能優化的時候使用到的在網路上的一個能力,也就是下面提到的sockhash,sockhash本身是一個ebpf特殊的一個kv存盤結構,主要被用作內核的一個socket層的代理,它的key是用戶自定義的,而value是比較特殊的,它存盤的value是內核里面一個socket物件,存盤在sockhash中的socket在發送資料的時候,如果能夠通過我們掛在sockhash當中的一個ebpf當中的程式找到接收方的socket,那么內核就可以幫助我們把發送端的資料直接拷貝到接收端socket的一個接收佇列當中,從而可以跳過資料在更底層的處理,比如TCP/IP協議堆疊的處理,
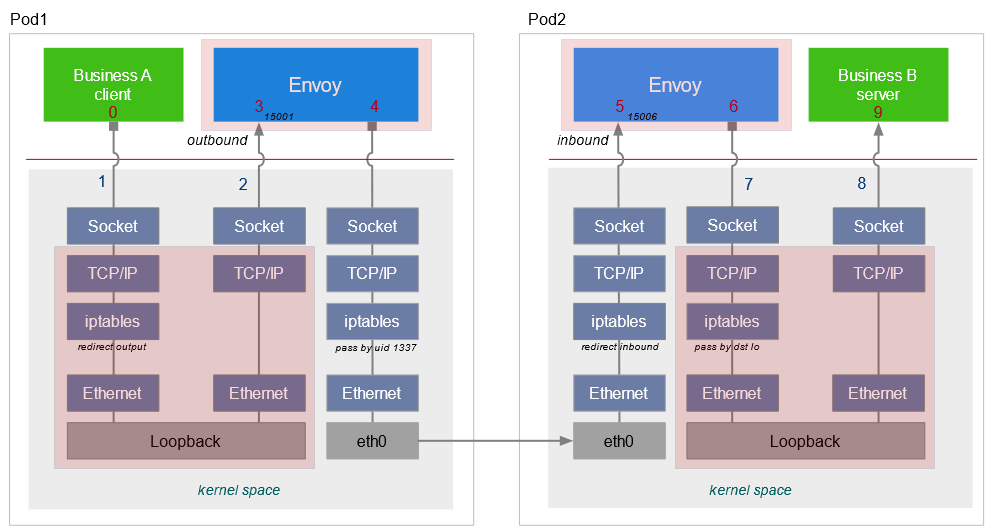
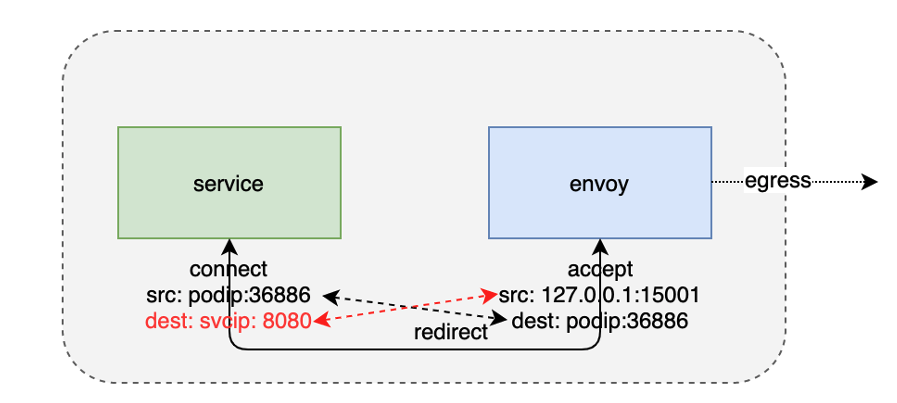
在sidecar中,socket是怎樣被識別并存盤在sockhash當中來完成一個資料拷貝的呢?我們需要分析一下資料鏈的本地通訊的流量特征,
首先從ingress來講,ingress端的通信會比較簡單一點,都是一個本地地址的通信,ingress端的envoy行程和用戶服務行程之間通信,它的原地址和目的地址剛好是一一對應的,所以我們可以利用這個地址的四元組構造它的key,把它存盤到sockhash當中,在發送資料的時候,根據這個地址資訊反向構造這個key,從sockhash當中拿到接收端的socket回傳給內核,這樣內核就可以幫我們將這個資料直接拷貝給接收端的socket,
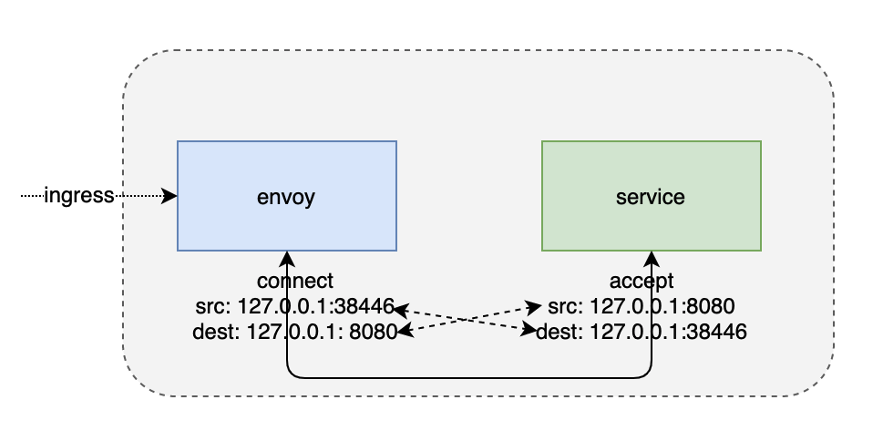
egress會稍微復雜一點,在一個egress端服務程式對外發出的請求被iptables規則重定向到了envoy監聽的一個15001的埠,在這里,發起方的源地址和接收方的目的地址是一一對應的,但是發起方的目的地址和接收端的源地址有了一個變化,主要是由于iptables對地址有一個重寫,所以我們在存盤到sockhash中的時候,需要對這部分資訊進行一個處理,由于istio的特殊性,直接可以把它改寫成envoy所監聽的一個本地服務地址,這樣再存盤到sockhash當中,它們的地址資訊還是可以反向一一對應的,所以在查找的時候,還是可以根據一端的socket地址資訊查找到另一端的socket,達到資料拷貝的目的,
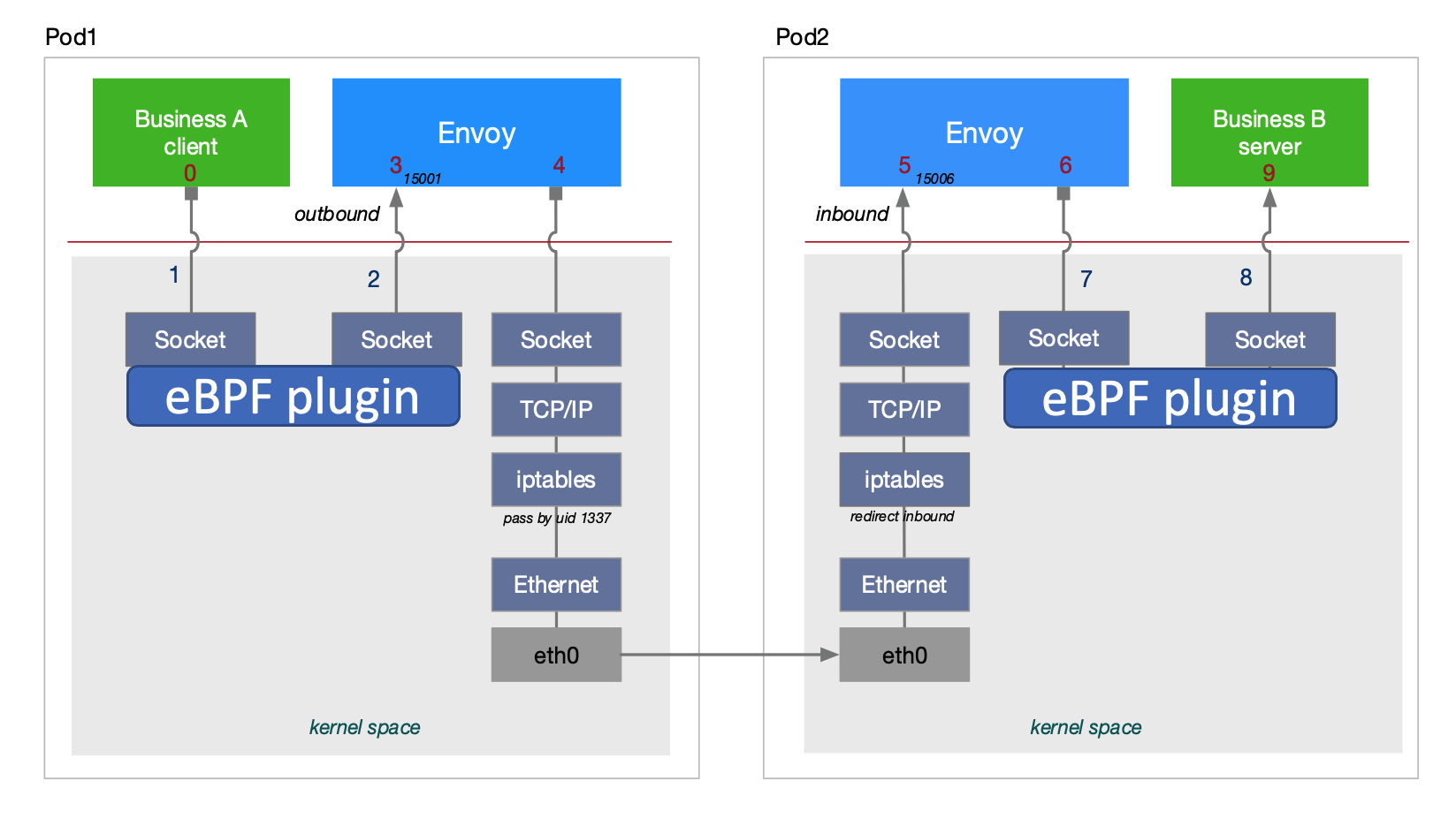
經過對ebpf加速原理的分析,我們開發出來一個ebpf的插件,這個插件可以不依賴于集群本身的網路模式,使用daemonset方式部署到k8s集群的各個節點上,其中的通信效果如下圖所示,本地行程的一個通信在socket層直接被ebpf攔截以后,就不會再往下發送到TCPIP協議堆疊了,直接在socket層就進行了一個資料拷貝,減少了資料鏈路上的一個處理流程
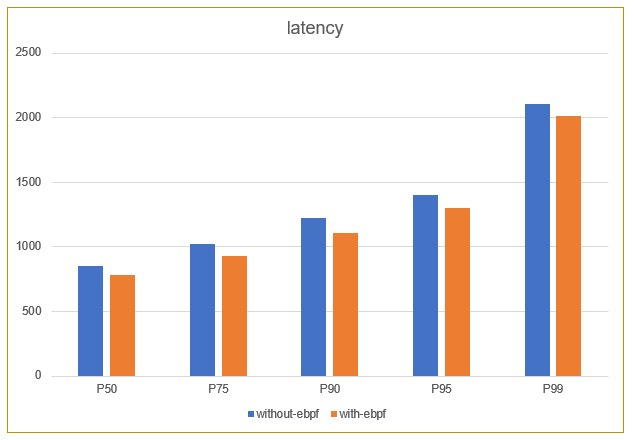
下面是對效果的一個測驗,從整體來看,它的延時有大概5到8%的延時提升,其實提升的幅度不是很大,主要原因其實在整個通信的流程當中,內核態的一個處理占整個通信處理的時間,延時其實是比較少的一部分,所以它的提升不是特別明顯,
另外ebpf還有一些缺陷,比如它對內核版本的要求是在4.18版本之后才有sockhash這個特性,另外sockhash本身還有一些bug,我們在測驗當中也發現了一些bug,并且把它提交到社區進行解決,
Envoy 性能研究與優化
前面介紹了對istio資料面對流量在內核的處理所進行的一些優化,在istio資料面的性能問題上,社區注意到比較多的是在內核態有一個明顯的轉發流程比較長的問題,因此提出了使用eBPF進行優化的方案,但是在Envoy上面沒有太多的聲音,雖然Envoy本身是一個高性能的網路代理,但我們還是無法確認Envoy本身的損耗是否對性能造成了影響,所以我們就兵分兩路,同時在Envoy上面進行了一些研究,
首先什么是Envoy?Envoy是為分布式環境而生的高性能網路代理,可以說基本上是作為服務網格的通用資料平面被設計出來的,Envoy提供不同層級的filter架構,如listenerFilter、networkFilter以及HTTPFilter,這使envoy具有非常好的可擴展性,Envoy還具有很好的可觀察性,內置有stats、tracing、logging這些子系統,可以讓我們更容易地對系統進行監控,
進行istio資料面優化的時候,我們面對的第一個問題是Envoy在istio資料面中給訊息轉發增加了多少延時?Envoy本身提供的內置指標是很難反映Envoy本身的性能,因此,我們通過修改Envoy原始碼,在Envoy處理訊息的開始與結束的位置進行打點,記錄時間戳,可以獲得Envoy處理訊息的延時資料,Envoy是多執行緒架構,在打點時我們考慮了性能和執行緒安全問題:如何高效而又準確地記錄所有訊息的處理延時,以方便后續的進行分析?這是通過如下方法做到的:
a. 給壓測訊息分配唯一數字ID;
b. 在Envoy中預分配一塊記憶體用于保存打點資料,其資料型別是一個結構體陣列,每個元素都是同一條訊息的打點資料;
c. 提取訊息中的數字ID當作時間戳記錄的下標,將時間戳記錄到預分配的記憶體的固定位置,通過這種方式,我們安全高效地實作了Envoy內的打點記錄(缺點是需要修改Envoy以及壓測工具),
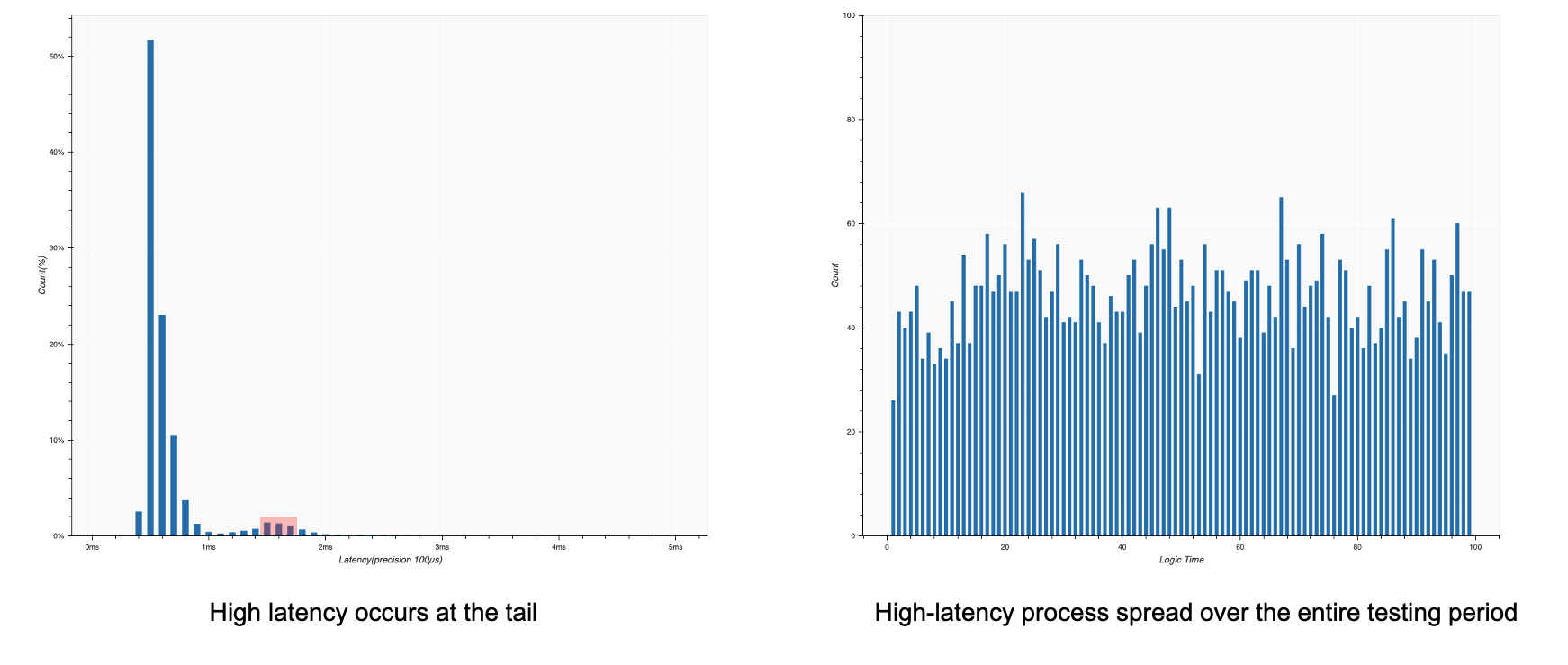
經過離線分析,我們發現了Envoy內訊息處理延時的一些分布特征,左圖是對Envoy處理延時與訊息數量分布圖,橫軸是延時,縱軸是訊息數量,可以看到在高延時部份,訊息數量有例外增加的現象,這不是典型的冪率分布,進一步對高延時部份進行分析后發現,這些高延時訊息均勻地分布于整個測驗期間(如上圖右所示), 根據我們的經驗,這通常是Envoy內部轉發訊息的worker在周期性的執行一些消耗CPU的任務,導致有一部分訊息沒辦法及時轉發而引起的,
深入研究Envoy在istio資料面的功能實作后,我們發現mixer遙測可能是導致這個問題的根本原因,Mixer是istio老版本(1.4及以前)實作遙測和策略檢查功能的一個組件,在資料面的Envoy中,Mixer會提取所有訊息的屬性,然后批量壓縮上報到mixer server,而屬性的提取和壓縮是一個高CPU的消耗的操作,這會引起延時資料分析中得到的結果:高延時訊息轉發例外增多,
在確定了原因之后,我們對Envoy的架構作了一些改進,給它增加了執行非關鍵任務的AsyncWorker執行緒,稱為異步任務執行緒,通過把遙測的邏輯拆分出來放到了AsyncWorker執行緒中去執行,就解決了worker執行緒被阻塞的問題,進而可以降低envoy轉發訊息的延時,
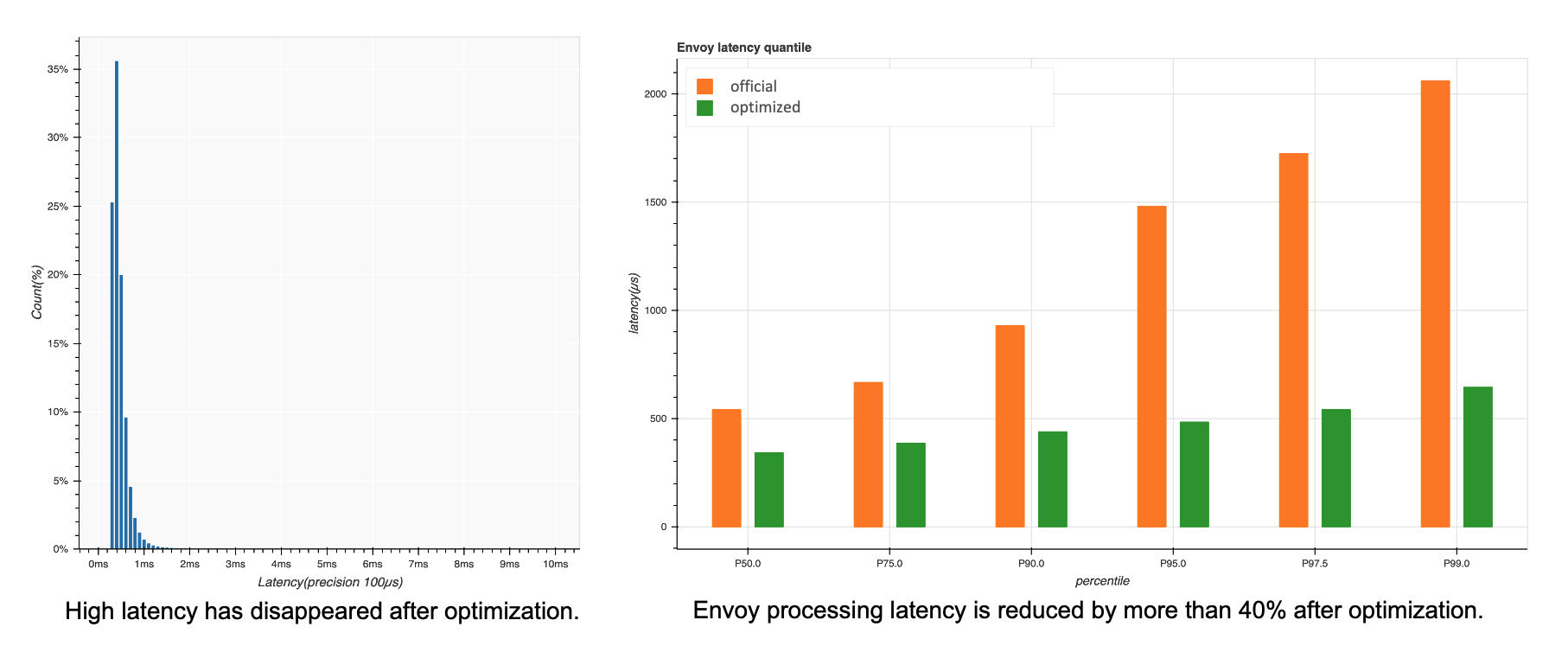
進行架構優化之后,我們也做了對比測驗,上圖左測是延時與訊息數量圖,可以看到它高延時部分得到明顯的改善,上圖右可以看出Envoy整體的延時降低了40%以上,
優化Envoy架構給我們帶來了第一手的經驗,首先CPU是影響Istio資料面性能的關鍵資源,它的瓶頸主要出現在CPU上面,而不是網路IO操作,第二,我們對Envoy進行架構優化,可以降低延時,但是沒有解決根本問題,因為CPU的使用沒有降低,只是遙測邏輯轉移到另外的執行緒中執行,降低Envoy轉發訊息的延時,優化CPU使用率才是資料面優化的核心,第三點,Envoy的不同組件當中,mixer消化掉了30%左右的CPU,而遙測是mixer的核心功能,因此后續遙測優化就變成了優化的重要方向,
怎么進行遙測優化呢?其實mixer實作遙測是非常復雜的一套架構,使用Istio mixer遙測的人都深有體會,幸好istio新版本中,不止對istio的控制面作了大的調整,在資料面mixer也同樣被移除了,意味著Envoy中高消耗的遙測就不會存在了,我們是基于istio在做內部的service mesh,從社區得到這個訊息之后,我們也快速跟進,引入適配新的架構,
沒有Mixer之后,遙測是如何實作的,Envoy提供了使用wasm對其進行擴展的方式,以保持架構的靈活性,而istio社區基于Wasm的擴展開發了一個stats extension擴展,實作了一個新的遙測方案,與mixer遙測相比,這個stats extension不再上報全量資料到mixer server,只是在Envoy內的stats子系統中生成遙測指標,遙測系統拉取Envoy的指標,就可以獲得整個遙測資料,會大大降低遙測在資料面的性能消耗,
然后我們對istio 1.5使用Wasm的遙測,做了一個性能的測驗,發現整個Envoy代理在同樣測驗條件下,它的CPU降低10%,而使用mixer的遙測其實占用了30%的CPU,里面大部分邏輯是在執行遙測,按我們的理解,Envoy至少應該有20%的CPU下降,但是實際效果只有10%左右,這是為什么呢?
新架構下我們遇到了新的問題,我們對新架構進行了一些實作原理和技術細節上的分析,發現Envoy使用Wasm的擴展方式,雖然帶來了靈活性和可擴展性,但是對性能有一定的影響,
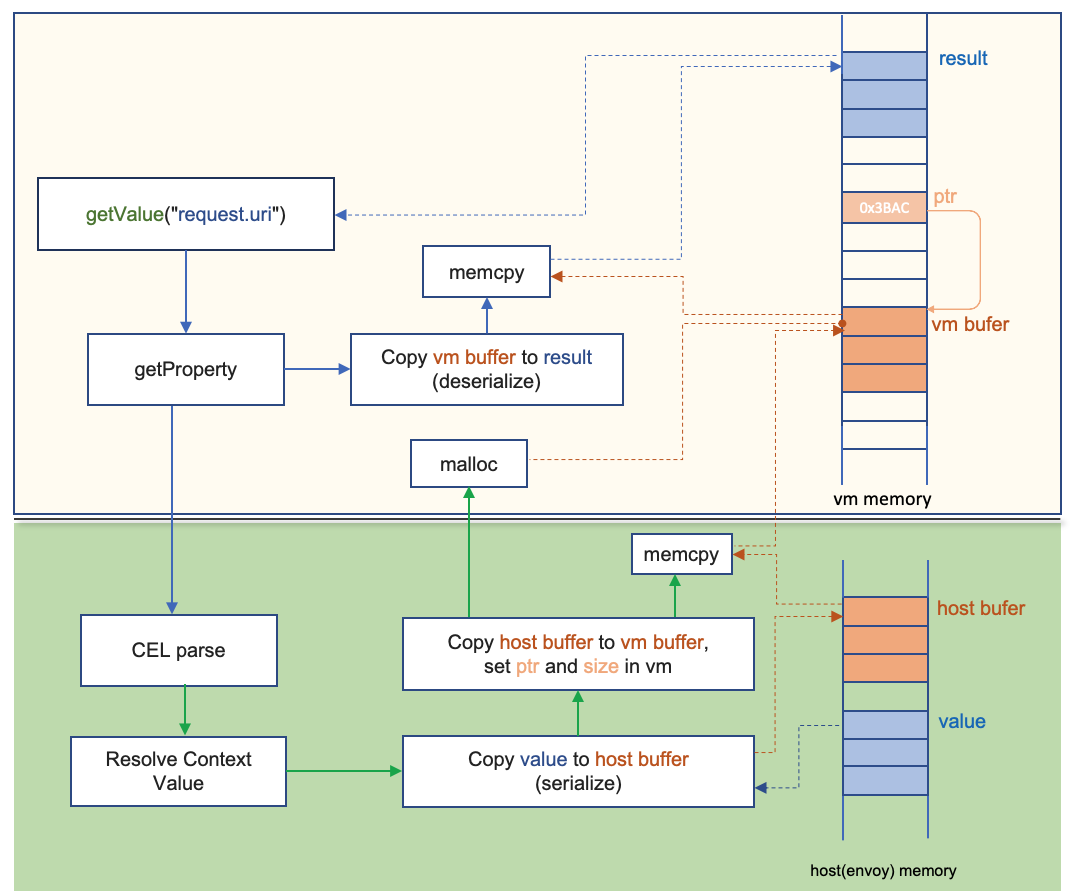
首先,Wasm擴展機制跟Envoy host環境是通過記憶體拷貝的方式進行通信,這是Wasm虛擬機的隔離性機制決定的,Envoy為了保持架構靈活性的同時保證性能,使設計了一個非Wasm虛擬機運行擴展(如stats extension)的模式,即NullVM模式,它是一個假的Wasm虛擬機,實際上運行的擴展還是被編譯在Envoy內部,但它也逃離不掉Wasm架構帶來的記憶體拷貝影響,
其次,在實作extension與Envoy的通信時,一個屬性的獲取要經過多次的記憶體拷貝,是一個非常復雜的程序,如上圖所示,獲取request.url這個屬性需要在Envoy的記憶體和Wasm虛擬機記憶體之間進行一個復雜的拷貝操作,這種方式的消耗遠大于通過參考或指標提取屬性,
第三,在實作遙測的時候,有大量的屬性需要獲取,通常有十幾二十個屬性,因此Wasm擴展帶來的總體額外損耗非常可觀,
另外,Wasm實作的遙測功能還需要另外一個叫做metadata_exchange擴展的支持,metadata_exchange用來獲得呼叫對端的一些節點資訊,而metadata_exchange擴展運行在另外一個虛擬機當中,通過Envoy的Filter state機制與stats 擴展進行通信,進一步增加了遙測的額外消耗,
那么如何去優化呢?簡單對Wasm插件優化是沒有太大幫助,因為它的底層Wasm機制已經決定了它有不少的性能損耗,所以我們就開發了一個新的遙測插件tstats,
tstats使用Envoy原生的擴展方式開發,在tstats擴展內部,實作了遙測和metadata_exchange的結合,消除了Wasm帶來的性能弊端,Tstats遙測與社區遙測兼容,生成相同的指標,tstats基于istio控制面的EnvoyFilter CRD進行部署,用戶可以平滑升級,當用戶發現tstats的功能沒有滿足需求或者出現一些問題時,也可以切換使用到社區提供的遙測擴展,
在tstats擴展還優化了遙測指標的計算程序,在計算指標的時候有許多維度資訊需要填充,(目前大指標有二十幾個維度的填充),這其實是一個比較復雜的操作,其實,有很多指標的維度都是節點資訊,就是發起服務呼叫的客戶端和服務端的一些資訊,如服務名、版本等等,其實我們可以將它進行一些快取,加速這些指標的計算,
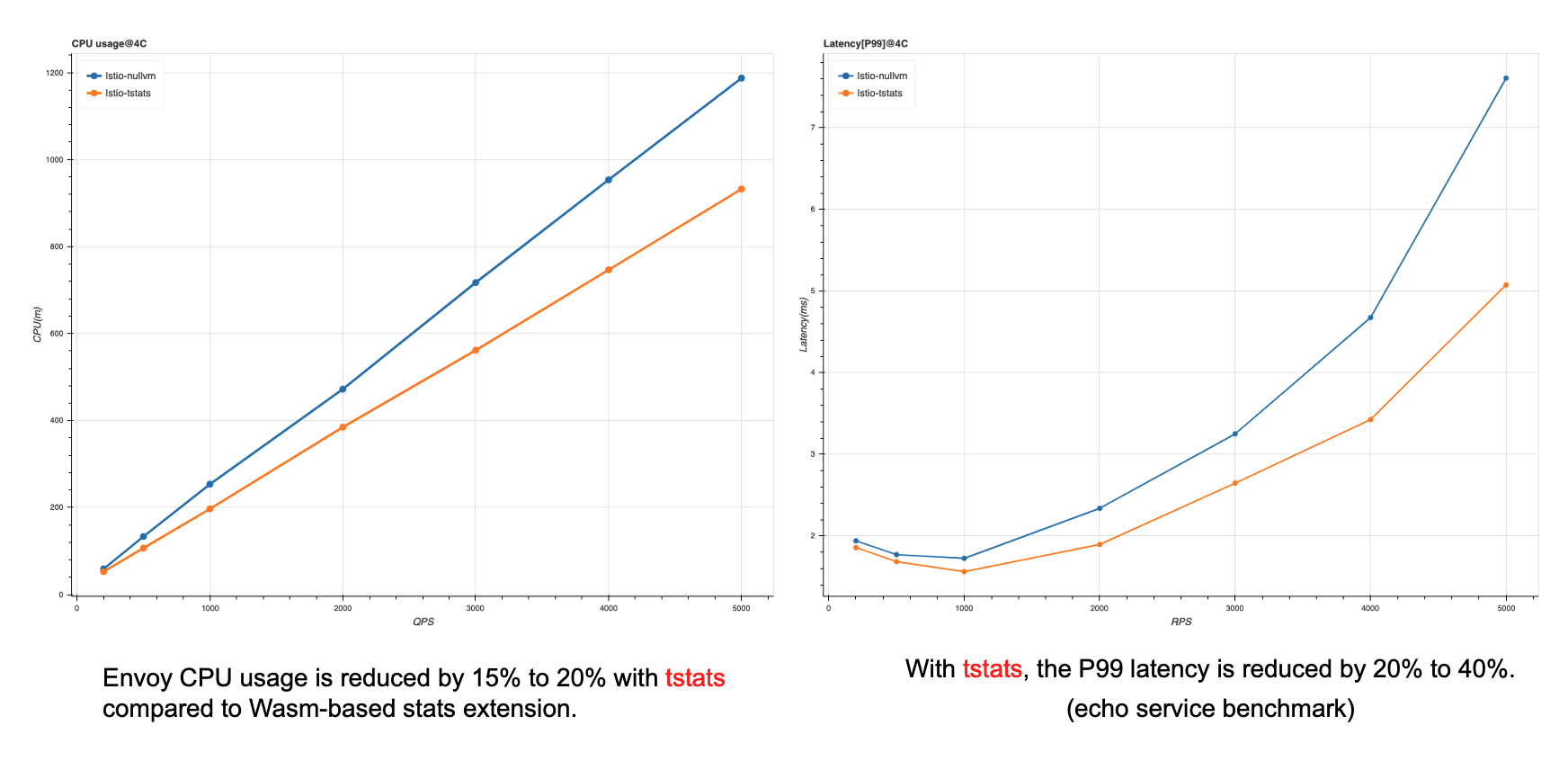
經過優化之后,對比tstats遙測和官方的基于Wasm的遙測的性能,我們發現CPU降低了10到20%,相對于老版本的mixer來說降低了20%以上,符合了我們對envoy性能調研的一個預期,上圖右可以看到在延時上有一個明顯的降低,即使在P99在不同的QPS下,也會有20%到40%的總體降低(這個延時是使用echo service做End-to-End壓測得到的),
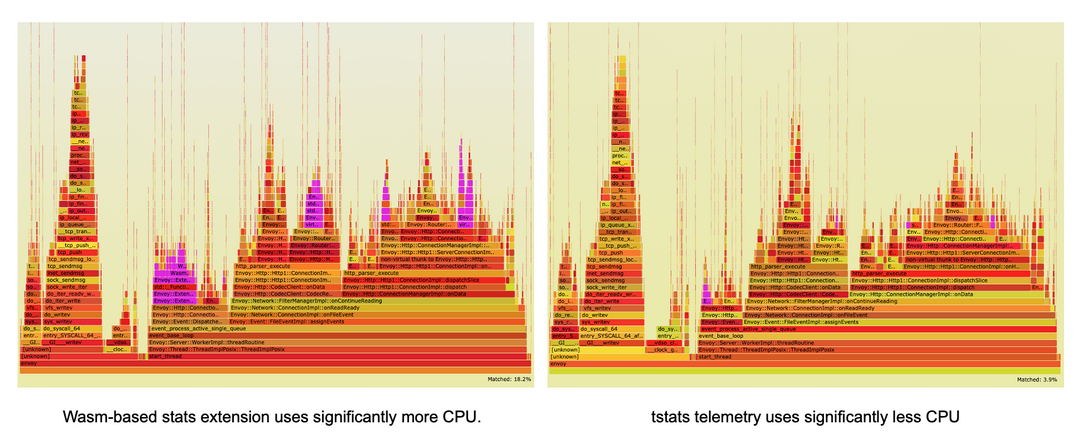
使用火焰圖重新觀察一下Envoy內部的CPU使用分布,我們發現tstats遙測插件占用CPU的比例明顯更少,而使用wasm的遙測插件有一個明顯的CPU占用來實作遙測,這也證明了tstats優化是有效果的,
總結
前面我們分享了在優化istio資料面程序當中,在內核態和Envoy內探索的一些經驗,這是我們優化的主要內容,當然還有一些其它的優化點,例如:
- 使用XDP進行加速,因為由于istio proxy的引入,Pod和Pod之間的訪問實際上是不需要經過主機上的iptables規則處理,基于這一點,我們可以利用XDP的快速轉發能力直接將包發送到對應的網卡,完成快速轉發,
- 鏈路跟蹤在Envoy中消耗的CPU也比較可觀,即使在1%的采樣率下也消耗了8%的CPU,是可以進行優化的,所以我們也在做這部分的作業,
- Envoy內部有非常多的內置統計,Istio的一些指標與Envoy內置的指標有一部分重復,可以考慮進行一些裁剪優化,或者增加一些特性開關,當不需要使用的時候對它進行關閉,
總體來說,Istio資料面性能的損耗分布在各個環節,并不是單獨的內核態訊息轉發或者用戶態Envoy就消耗特別多,在使用Mixer架構的Istio版本中,Envoy內一個明顯的性能熱點, mixer遙測,這也在版本迭代中逐步解決了,
最后,在進行Istio資料面優化的時候需要綜合考慮各個環節,這也是我們目前總體上對Istio資料面性能的一個認識,通過這次分享,希望社區和大家都會在更注重Istio資料面的性能,幫助ServiceMesh更好地落地,騰訊云基于Istio提供了云上ServiceMesh產品TCM,大家有興趣可以來體驗,
問題
-
怎么判斷專案需要使用服務網格?
服務網格解決的最直接的場景就是你的服務需要進行微服務治理,但是你們之前可能有多個技術堆疊,沒有一個統一的技術框架,比如沒有使用SpringCloud等,缺少微服務治理能力,但是又想最低成本獲得鏈路跟蹤、監控、流量管理、熔斷等這樣的能力,這個時候可以使用服務網格實作,
-
這次優化有沒有考慮到回歸到社區?
其實我們也考慮過這個問題,我們在進行mixer優化的時候,當時考慮到需要對Envoy做比較多的改動,并且了解到社區規劃從架構中去掉mixer,所以這個并沒有回歸到社區,異步任務執行緒架構的方案目前保留在內部,對于第二點開發的tstats擴展,它的功能和社區的遙測是一樣的,如果提交到社區我們覺得功能會有重疊,所以沒有提交給社區,
-
服務網格資料調優給現在騰訊的業務帶來了哪些改變?
我想這里主要還是可觀測性上面吧,之前很多的服務和開發,他們的監控和呼叫面的上面做得都是差強人意的,但是他們在業務的壓力之下,其實是沒有很完善的方式、沒有很大的動力快速實作這些服務治理的功能,使用istio之后,有不少團隊都獲得了這樣的能力,他們給我們的反饋都是比較好的,
-
在減少延遲方面,騰訊做了哪些調整,服務網格現在是否已經成熟,對開發者是否友好?
在延遲方面,我們對性能的主要探索就是今天分享的內容,我們最開始就注意到延時比較高,然后在內核做了相應的優化,并且研究了在Envoy內為什么會有這些延遲,所以我們得出的結論,CPU是核心的資源,需要盡量降低資料面Proxy代理對CPU的使用,這是我們做所有優化最核心的出發點,當CPU降下來,延時就會降低,服務網格現在是否已經成熟,我覺得不同的人有不同答案,因為對一些團隊,目前他們使用服務網格使用得很好的,因為他們有多個技術堆疊,沒有統一的框架,他們用了之后,獲得這些流量的管理和監控等等能力,其實已經滿足了他們的需求,但是對一些成熟的比較大的服務,資料面性能上面可能會有一些影響,這個需要相應的團隊進行仔細的評估才能決定,并沒辦法說它一定就是能在任何場景下可以直接替換現有的各個團隊的服務治理的方式,
-
為什么不直接考慮1.6?
因為我們做產品化的時候,周期還是比較長的,istio社區發版本的速度還是比較快的,我們還在做1.5產品化的時候,可能做著做著,istio1.6版本就發出來了,所以我們也在不停更新跟迭代,一直在跟隨社區,目前主要還是在1.5版本上,其實我們在1.4的時候就開始做現在的產品了,
-
公司在引入多種云原生架構,包括SpringCloud和Dubbo,作為運維,有必要用Istio做服務治理嗎?另外SpringCloud和Dubbo這種架構遷移到Istio,如何調整?
目前SpringCloud和Dubbo都有不錯的服務治理功能,如果沒有非常緊迫的需求,比如你們又需要引入新的服務并且用別的語言實作,我覺得繼續使用這樣的框架,可能引入istio沒有太大的優勢,但是如果考慮進行更大規模的服務治理,包括融合SpringCloud和Dubbo,則可以考慮使用istio進行一個合并的,但是這個落地會比較復雜,那么SpringCloud和Dubbo遷移到Istio如何調整?目前最復雜的就是他們的服務注冊機制不一樣,服務注冊模型不一樣,我們之前內部也有在預研如何提供一個統一的服務注冊模型,以綜合Istio和其它技術框架如SpringCloud的服務注冊和服務發現,以及SpringCloud如何遷移進來,這個比較復雜,需要對SDK做一些改動,我覺得可以下來再進行交流,
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/71956.html
標籤:其他
上一篇:如何用cad畫箭頭