深入理解count*為什么這么慢
- 不同存盤引擎的實作方式
- InnoDB為什么不存起來
- MySQL的優化
- show tables status不準確
? 曾經在依次面試中被問到過這么一個問題,假設開發一個交易平臺程序中,有遇到過需要計算交易記錄總數的情況該怎么辦,可能大多數人的回答都是用select count(*) from t 不就搞定了嗎 但是,面試官又問到隨著系統中記錄數越來越多,這條陳述句執行得越來越慢,那么為什么這么慢呢,今天我們就來聊一聊原因吧,
不同存盤引擎的實作方式
?MySQL在不同的存盤引擎中,count(*)的實作方式也不相同,
- 一般來說MyISAM引擎效率比較高,因為它是把一個表的總行數存到了磁盤上,因此執行count(*)的時候回直接回傳計數值,但是如果加上where的話,MyISAM的表也不能反應這么快,
- InnoDB引擎它執行count(*)的時候比較麻煩,它需要把資料一行一行地從引擎里面讀出來,然后再進行累計計數,
InnoDB為什么不存起來
?即使同一時刻的多個查詢,由于多版本并發控制(MVCC)的原因,事務T啟動的時候會創建一個視圖read-view,InnoDB的表根據視圖進行計數的,因此不能確定應該回傳多少行,下面我們舉個例子來解釋一下:
?假設表t1有5000條記錄,三個用戶并行的會話,
- 會話1先啟動事務并查詢一次表的總行數
- 會話2先啟動事務,插入一條記錄后再查詢表的總行數
- 會話3先啟動一個單獨的陳述句,插入一條陳述句后再查詢表的總行數,
| 會話1 | 會話2 | 會話3 |
|---|---|---|
| begin; | ||
| select count(*) from t1; | ||
| insert into t1 () | ||
| begin; | ||
| insert into t1 () | ||
| select count(*) from t1(回傳5000) | select count(*) from t1(回傳5002) | select count(*) from t1(回傳5001) |
?最后,三個會話會同時查詢表t1的總行數,但拿到的結果卻不相同,這個原因其實和事務的設計有一定關系,一般默認隔離級別是可重復讀(REPATABLE-READ)
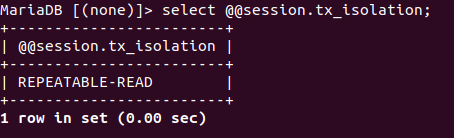
而可重復讀是通過MVCC來實作,每一行記錄都要判斷是否對這個會話可見,因此就count(*)來說,InnoDB只好把資料逐行地讀出并判斷,只有可見的行才能被用來計算表的總行數,
MySQL的優化
?MySQL實際上是做了優化的,InnoDB是索引組織表,主鍵索引樹的葉子節點是資料,而普通索引樹的葉子節點是主鍵值,因此普通索引樹比主鍵索引樹小很多,對于count(*)操作遍歷哪棵樹邏輯上來講結果都是一樣的,因此,為了遵循減少資料量遍歷的原則,MySQL的優化器會找到最小的那顆樹來進行遍歷,
? 這里提到的主鍵索引樹和普通索引樹是什么意思?我們來舉個例子:
假設有張InnoDB表t (id PK, name KEY, sex, flag)
表中有四條記錄:
1, song, m, A
3, zhang, m, A
5, li, m, A
9, wang, f, B
?則它們的索引樹如下圖所示:
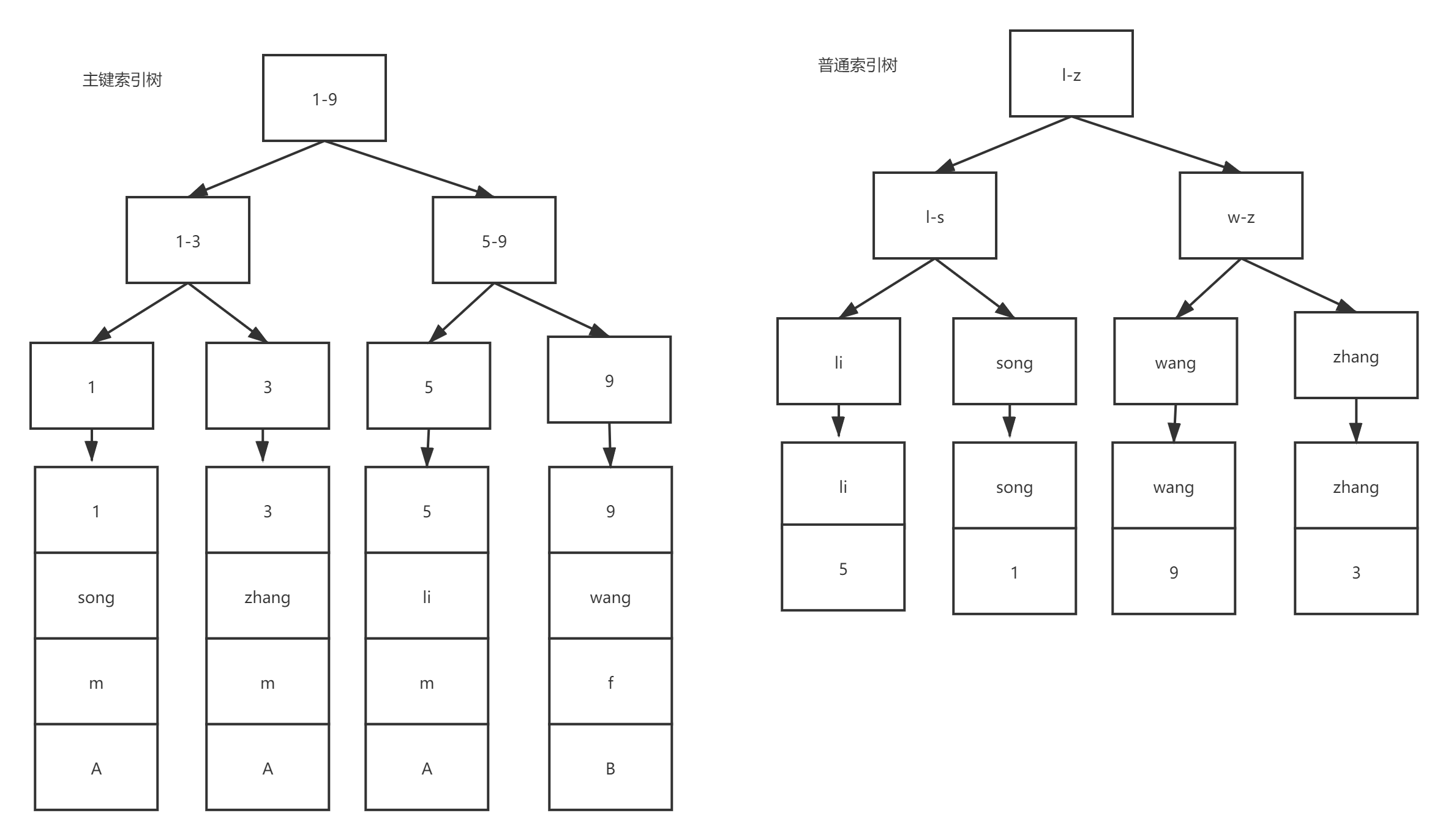
?假設要執行陳述句select * from t where name=’song’;
(1)首先在name普通索引上查詢到PK=1;
(2)再在主鍵索引樹上查詢到(1,song, m, A)的行記錄;
show tables status不準確
? 其實MySQL有條命令show tables status命令執行結果中有條Rows能用于顯示表有多少行,比如我們有張表結構是這樣的
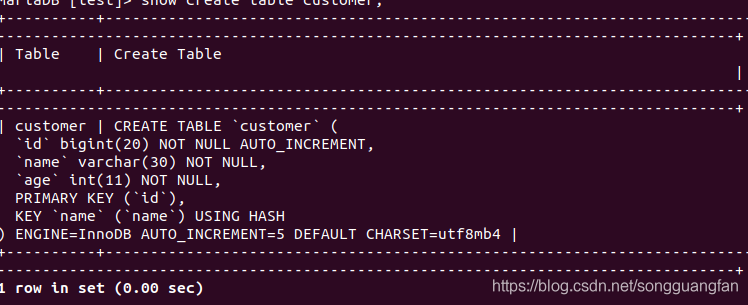
?插入資料后,執行show table status命令結果如下:
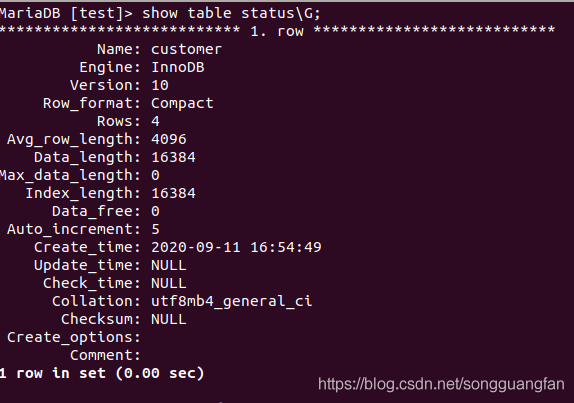
?這條命令執行比count(* )快,那用它來代替count(*)豈不是很快,但是不行,為什么呢?
?它不夠準確,因為它的值是根據MySQL采樣統計估算出來的,官方統計,誤差還是可能會達到40%-50%,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/72277.html
標籤:其他
上一篇:量子轉換值的計算
下一篇:計算機網路技術課程設計