在spark集群中,服務器的配置是有差異的,其中配置稍差的服務器有時執行任務時反序列化時間會達到2分鐘,使用的序列化方式是org.apache.spark.serializer.KryoSerializer,請問這是什么原因呢?
服務器配置:32core/126G
運行方式:在yarn上運行
資源使用:不到五分之一
uj5u.com熱心網友回復:
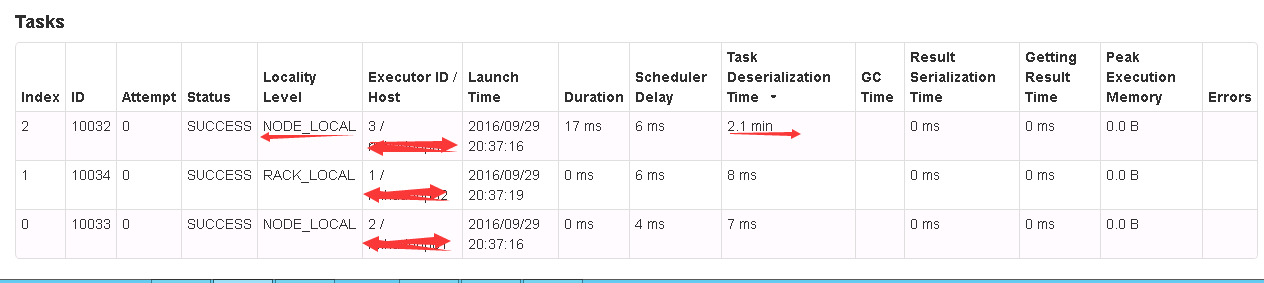
uj5u.com熱心網友回復:
剛剛看到一篇文章,可能對你有幫助這里uj5u.com熱心網友回復:
首先多謝樓上的答復。我面臨的問題是已經使用Kryo,并且也把一些類進行了注冊。然而大約在200次執行完的stag中總會有一個或兩個stage 的反序列化時間會到2分鐘以上(正常是4秒左右的處理時間),而且處理的資料并不多。
uj5u.com熱心網友回復:
那目測就是資料傾斜了,較大的磁區資料被分配到較差的節點上。解決資料傾斜有很多辦法,要視乎資料本身去處理。本質都是讓每個磁區盡可能分到相似數量的記錄。
uj5u.com熱心網友回復:
同意樓上意見 ,應該是資料傾斜了,可以增加磁區數量,或者自定義磁區方式來解決一下uj5u.com熱心網友回復:
It may not necessary be data skew. The OP already mentioned that the data volume for this task is not much different with other tasks.But OP is not clear if there is always ONE task per executor is much slower than the rest tasks due to the task deserializing much longer.
If this IS the case, that is most likely because of the time taken to ship the jars from the driver to the executors. You should only pay this cost once per spark context (assuming you are not adding more jars later on).
When you submit your spark jobs, how large is your jar file? A hundred Ks is much difference as hundred Ms.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/72727.html
標籤:Spark
上一篇:我用的是python!在sparkstreaming中,使用kafka的directstream,如何自己實作將offset更新到zookeeper?