Hello,我是 Alex 007,為啥是007呢?因為叫 Alex 的人太多了,再加上每天007的生活,Alex 007就誕生了,
這幾天一直在練車,只能在中間休息的時候寫一寫博客,可憐去年報的名到現在還沒有拿到小本本,當然練車只是副技能,主技能還是coding,不斷學習才能不被淘汰,
最近在學爬蟲的 scrapy 框架,以前雖然拿 GoLang 玩過爬蟲,可惜沒有太深入,這次拿 Python 好好學一學,
學習爬蟲程序中的代碼都放在了GitHub上:https://github.com/koking0/Spider
小生才疏學淺,如有謬誤,恭請指正,
文章目錄
- 一、初探 Scrapy
- 1.Scrapy 的安裝
- 2.第一個 scrapy 專案
- 二、基本操作
- 1.持久化存盤
- (1)基于終端指令的持久化存盤
- (2)基于管道的持久化存盤
- 2.全站資料爬取
- 請求傳參
- 3.圖片下載
一、初探 Scrapy
先來看一下官網的定義:
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages.
Scrapy是一個快速的高級web抓取框架,用于抓取網站和從網頁中提取結構化資料,
It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
它可以用于廣泛的用途,從資料挖掘到監控和自動化測驗,

沒學習過爬蟲和框架的人可能就懵逼了,不知道爬蟲是什么的可以先花兩分鐘看一下網路機器人之爬蟲這篇文章,不知道框架是什么的,我簡單說一下,大佬可以螢屏向下滾動200px,
1.什么是框架?
所謂框架,顧名思義,就是一個具有很強通用性并且集成了很多功能的專案模板,可以應用在不同的專案需求中,
也就是說,框架是別人造好的輪子,一個專案的半成品,我們只需要拿過來撰寫自己的業務邏輯填空即可,
2.怎么學習框架?
對于剛接觸編程或者小白來講,一個新的框架只需要掌握該框架的作用及其各個功能的使用即可,
說白了就是會用就行,對于框架的底層實作和原理,在逐步進階中慢慢深入即可,
Scrapy 可以說在爬蟲界是非常出名也非常強悍的,為爬取網站結構性資料而生,其內部集成了諸如高性能異步下載、佇列、分布式、持久化等功能,可以說是爬蟲利器,
1.Scrapy 的安裝
- Windows 作業系統
四行代碼,復制粘貼,簡單粗暴,
pip install wheel
pip install twisted
pip install pywin32
pip install scrapy
如果安裝太慢的話可以用阿里云鏡像,
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com twisted
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com pywin32
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com scrapy
簡單解釋一下除了 scrapy 之外的兩個東西是啥:
- twisted
Twisted 是用 Python 實作的基于事件驅動的網路引擎框架,提供了允許阻塞行為但不會阻塞代碼執行的方法,比較適合異步的程式,
關于 Twisted 異步與多執行緒的比較可以參考:Scrapy與Twisted
- pywin32
pywin32 主要的作用是方便 Python 開發者快速呼叫 Windows API的一個模塊庫,
也就是說,twisted 和 pywin32 可以配合起來讓 scrapy 的異步爬取更加絲滑順暢,哈哈,開玩笑,沒這兩個庫 scrapy 根本安裝不上,三個步驟一步都不能報錯,
- Linux 作業系統
pip install scrapy
- Mac 作業系統
pip install scrapy
安裝完成后可以測驗一下安裝結果,在終端輸入 scrapy,執行后沒有報錯即安裝成功:
(venv) G:\Python\Spider>scrapy
Scrapy 2.0.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
2.第一個 scrapy 專案
使用 scrapy 大體上可以分為5個步驟,這里說的可不是代碼的撰寫,而是從專案的創建到執行需要5步:
- 創建專案
scrapy startproject firstScrapy
- 進入專案目錄
cd firstScrapy
- 創建爬蟲檔案
scrapy genspider baiDuwww.baidu.com
- 撰寫代碼
這里簡單做一個爬取百度首頁頂部選單的爬蟲,
# baiDu.py
# -*- coding: utf-8 -*-
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬蟲應用名稱
name = 'baiDu'
# 允許爬取的域名,如果不是該域名下的 url 則不會爬取
allowed_domains = ['www.baidu.com']
# 起始爬取 url
start_urls = ['http://www.baidu.com/']
# 將爬取起始 url 的結果作為 response 引數傳入該函式,函式的回傳值必須是可迭代物件或 null
def parse(self, response):
# 字串型別回應物件內容
# print(response.text)
# 位元組型別回應物件內容
# print(response.body)
# xpath 為 response 的方法,可以直接寫 xpath 運算式
aList = response.xpath('//*[@id="u1"]/a')
for item in aList:
name = item.xpath('.//text()')[0].extract()
url = item.xpath('./@href')[0].extract()
print(name, url)
# settings.py
from fake_useragent import UserAgent
# ......
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 設定全域 UA 偽裝
user_agent = UserAgent()
USER_AGENT = user_agent.random
# Obey robots.txt rules
# 忽略 robots 協議
ROBOTSTXT_OBEY = False
- 執行專案
scrapy crawl baiDu
如果你的代碼邏輯沒有出錯的話,可以看到如下結果:
(venv) G:\Python\Spider\6.scrapy框架\firstScrapy>scrapy crawl baiDu
2020-04-09 21:48:46 [scrapy.utils.log] INFO: Scrapy 2.0.1 started (bot: firstScrapy)
2020-04-09 21:48:46 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Py
thon 3.7.4 (default, Aug 9 2019, 18:34:13) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1f 31 Mar 2020), cryptography 2.9, Platform
Windows-10-10.0.18362-SP0
2020-04-09 21:48:46 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-04-09 21:48:46 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'firstScrapy',
'EDITOR': '~/AppData/Roaming/GitPad/GitPad.exe',
'NEWSPIDER_MODULE': 'firstScrapy.spiders',
'SPIDER_MODULES': ['firstScrapy.spiders'],
'USER_AGENT': 'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'}
2020-04-09 21:48:46 [scrapy.extensions.telnet] INFO: Telnet Password: 2ca333daee7184fb
2020-04-09 21:48:46 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Spider opened
2020-04-09 21:48:47 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-04-09 21:48:47 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-04-09 21:48:47 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.baidu.com/> from <GET http://www.baidu.com
/>
2020-04-09 21:48:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com/> (referer: None)
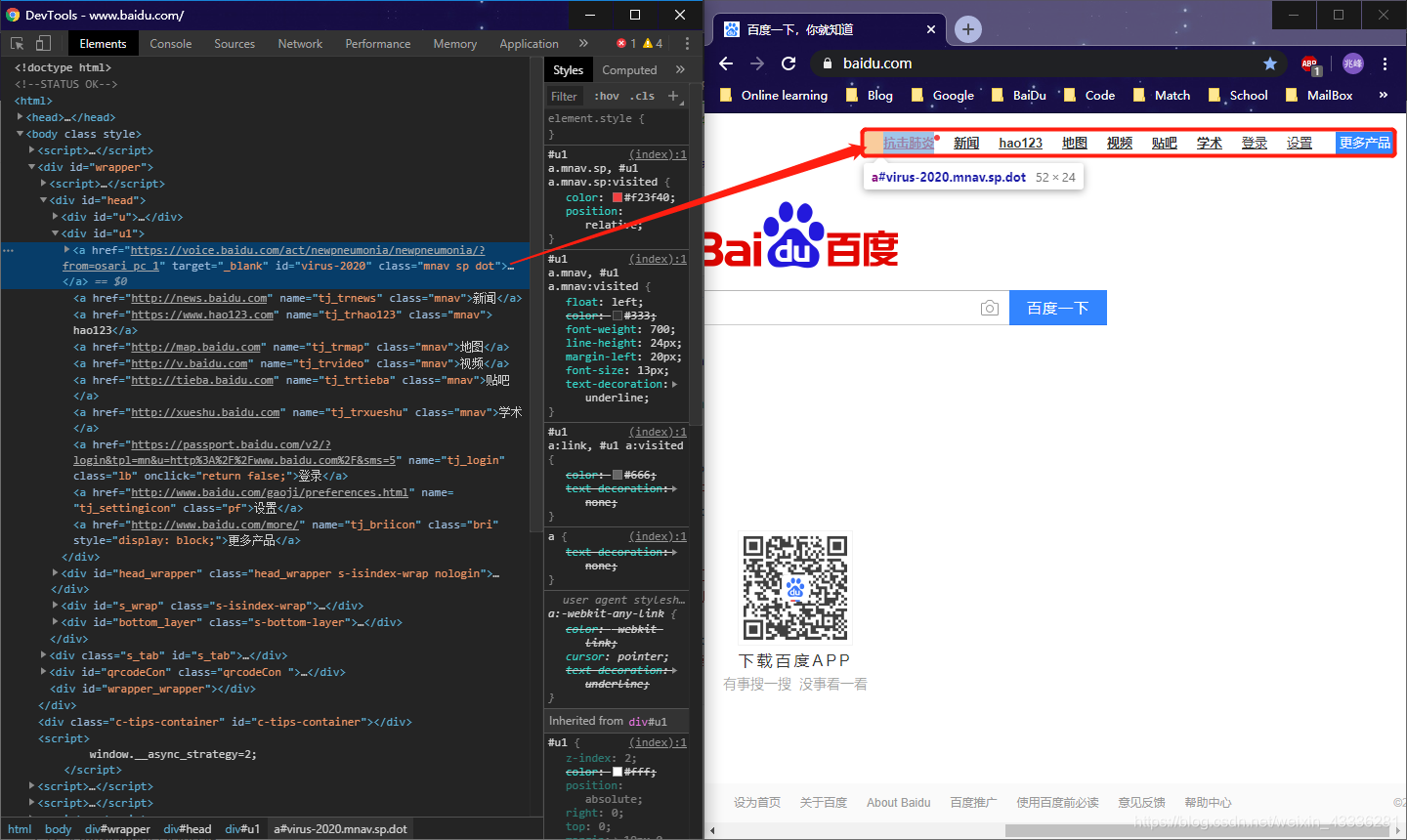
抗擊肺炎 https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_1
新聞 http://news.baidu.com
hao123 https://www.hao123.com
地圖 http://map.baidu.com
視頻 http://v.baidu.com
貼吧 http://tieba.baidu.com
學術 http://xueshu.baidu.com
登錄 https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5
設定 http://www.baidu.com/gaoji/preferences.html
更多產品 http://www.baidu.com/more/
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Closing spider (finished)
2020-04-09 21:48:47 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 732,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 53325,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/302': 1,
'elapsed_time_seconds': 0.491685,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 4, 9, 13, 48, 47, 901362),
'log_count/DEBUG': 2,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 4, 9, 13, 48, 47, 409677)}
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Spider closed (finished)
scrapy 給我們輸出了很多很多東西,我們的列印結果被放在了中間,其它的內容其實是日志資訊,scrapy 幫我們自動生成了日志,如果你覺得礙眼的話,可以通過 settings.py 檔案中的設定只保留錯誤資訊:
LOG_LEVEL = 'ERROR'
二、基本操作
接下來了解一下 scrapy 框架的一些基本操作,比如爬取資料的持久化存盤啦,對網站的全站爬取啦還有圖片下載等功能,
1.持久化存盤
爬取到的資料只有保存到本地的電腦上才是自己的,不然只在記憶體里,用完就沒了,
(1)基于終端指令的持久化存盤
在前邊的小試牛刀中我們可以看到控制臺的輸出,其實基于終端指令的持久化存盤就是將終端的輸出結果重定向到一個本地檔案中,
使用基于終端指令的持久化存盤必須保證爬蟲檔案中的 parse 方法中有可迭代物件回傳,通常是串列或者字典,
我們把爬取百度頂部選單欄的爬蟲 parse 方法升級一下:
def parse(self, response):
# xpath 為 response 的方法,可以直接寫 xpath 運算式
aList = response.xpath('//*[@id="u1"]/a')
data = {}
for item in aList:
name = item.xpath('.//text()')[0].extract()
url = item.xpath('./@href')[0].extract()
data[name] = url
return data
然后在 settings.py 檔案中寫一下檔案編碼的配置,保證使用的是 utf-8 編碼方式:
FEED_EXPORT_ENCODING = 'UTF8'
接下來,在啟動專案的時候可以用如下指令:
scrapy crawl baiDu -o baidu.json
這樣就可以將爬取的結果持久化存盤到 baidu.json 檔案中:

類似的方法還有:
scrapy crawl spiderName-o xxxx.txt
scrapy crawl spiderName-o xxxx.xml
scrapy crawl spiderName-o xxxx.csv
(2)基于管道的持久化存盤
使用終端保存檔案的方式在 Windows 作業系統貌似不是很常見,Linux 下倒是正常操作,
scrapy 框架中集成了高效、便捷的持久化存盤功能,并且在創建專案的時候也幫我們自動創建好了檔案:
1.items.py:資料結構模板,定義存盤資料的欄位
2.pipelines.py:管道檔案,接收資料(item)進行持久化存盤
基于管道的持久化存盤流程:
- 將爬蟲檔案爬取到的資料封裝到 items 物件中
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class FirstscrapyItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 存盤選單名
url = scrapy.Field() # 存盤選單 url
pass
- 使用 yield 將 items 物件提交給 pipelines 管道持久化存盤
baiDu.py
def parse(self, response):
# xpath 為 response 的方法,可以直接寫 xpath 運算式
aList = response.xpath('//*[@id="u1"]/a')
for data in aList:
# 將決議到的資料封裝到 items 物件中
item = FirstscrapyItem()
item["name"] = data.xpath('.//text()')[0].extract()
item["url"] = data.xpath('./@href')[0].extract()
yield item
- 管道檔案中的 process_item 方法接收并處理爬蟲檔案提交過來的 item 物件
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class FirstscrapyPipeline(object):
def __init__(self):
self.fp = None
def open_spider(self, spider):
"""開啟爬蟲時執行一次"""
print("爬蟲啟動!")
self.fp = open("data.txt", "w")
def process_item(self, item, spider):
self.fp.write(f'{item["name"]}:{item["url"]}\n')
return item # 注意:一定要有 return item 這一步
def close_spider(self, spider):
"""結束爬蟲時執行一次"""
self.fp.close()
print("爬蟲結束!")
- 組態檔 settings.py 中開啟管道
取消兩行注釋即可,后邊的300表示優先級,值越小優先級越高:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
}
如此這般,當我們再次執行 scrapy 專案的時候:
(venv) G:\Python\Spider\6.scrapy框架\firstScrapy>scrapy crawl baiDu
爬蟲啟動!
爬蟲結束!
就會生成一個 data.txt 檔案:
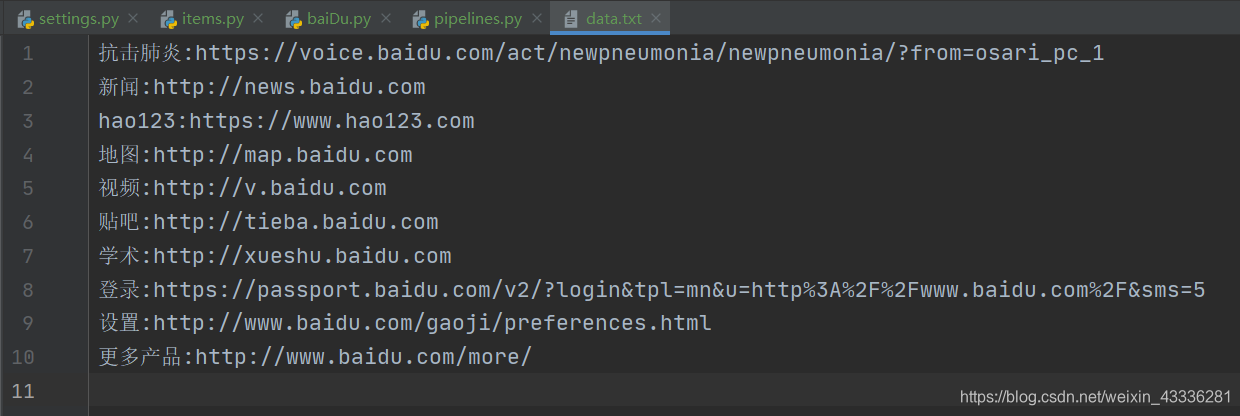
如果你想將爬取到的資料一式兩份,一份存盤到磁盤檔案中,一份存盤到資料庫中,那么就需要在 pipelines.py 檔案中再定制一個存盤到資料庫的管道類:
class DataBasePipeline(object):
def __init__(self):
self.connect, self.cursor = None, None
def open_spider(self, spider):
self.connect = pymysql.Connect(host="127.0.0.1", port=3306, user="root", password="20001001", db="test", charset="utf8")
def process_item(self, item, spider):
self.cursor = self.connect.cursor()
try:
sql = 'INSERT INTO scrapy1 VALUES ("%s", "%s");' % (item["name"], item["url"])
self.cursor.execute(sql)
self.connect.commit()
except Exception as e:
print(e)
self.connect.rollback()
return item # 注意:一定要有 return item 這一步
def close_spider(self, spider):
self.connect.close()
self.cursor.close()
然后在 settings.py 檔案中注冊該類:
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
'firstScrapy.pipelines.DataBasePipeline': 301,
}
這樣就可以將爬取到的資料存盤到資料庫中了:

2.全站資料爬取
現在大部分的網站展示的資料都進行了分頁操作,因此將所有頁碼對應的頁面進行爬取變成了普遍的要求,scrapy 也幫我們定制好了全站資料爬取的功能,
以我自己的 CSDN 博客為例,我現在想把所有我寫博客的標題和摘要爬取下來:
- Elements 分析

每一篇博客的盒子 xpath 運算式://*[@id="mainBox"]/main/div[2]/div
博客名稱 xpath 運算式:./h4/a/text()
博客摘要 xpath 運算式:./p/a/text()
- Page 分析
第一頁:https://alex007.blog.csdn.net/article/list/1
第二頁:https://alex007.blog.csdn.net/article/list/2
第三頁:https://alex007.blog.csdn.net/article/list/3
……
第 n 頁:https://alex007.blog.csdn.net/article/list/n
在 Scrapy 中可以使用 Request 方法手動對每一個頁面發起請求,
import time
import scrapy
from myBlog.items import MyblogItem
class CsdnSpider(scrapy.Spider):
name = 'csdn'
start_urls = ['https://alex007.blog.csdn.net/']
pageNumber = 1
pageUrl = 'https://alex007.blog.csdn.net/article/list/%d'
def parse(self, response):
print(f"正在爬取第{self.pageNumber}頁,url={self.pageUrl % self.pageNumber},")
divList = response.xpath('//*[@id="mainBox"]/main/div[2]/div')
for div in divList:
item = MyblogItem()
item["name"] = ("".join(div.xpath('.//h4/a/text()').extract())).strip("\n").strip()
item["content"] = ("".join(div.xpath('.//p/a/text()').extract())).strip("\n").strip()
yield item
if self.pageNumber < 21:
self.pageNumber += 1
time.sleep(1)
url = format(self.pageUrl % self.pageNumber)
# 遞回爬起資料,callback 引數為回呼函式
yield scrapy.Request(url=url, callback=self.parse)
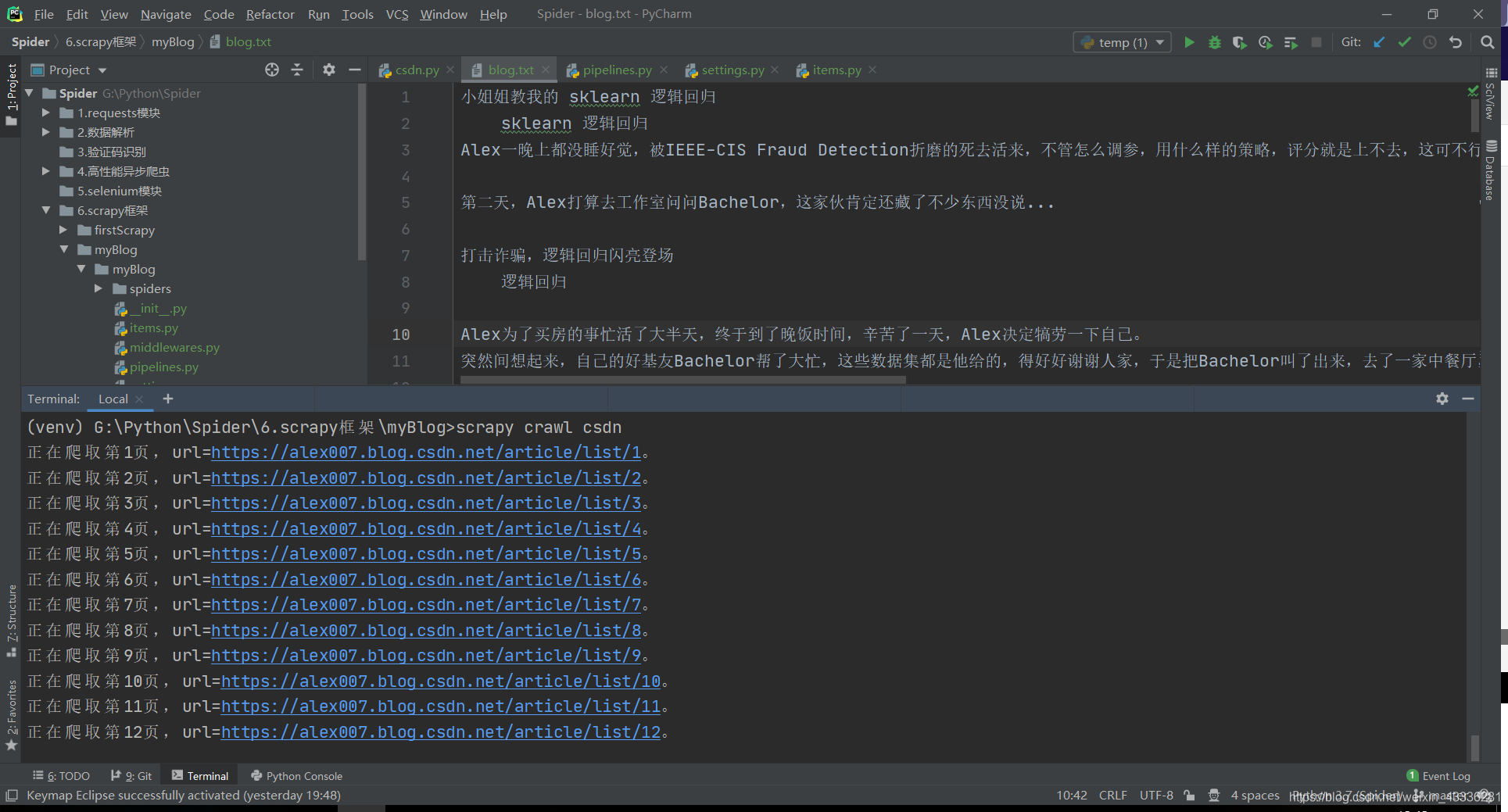
如此這般,就可以將我的所有博客文章題目和摘要都爬取下來了:
請求傳參
如果我現在的需求升級一下,對于每一篇博客,摘要不要了,替換為博客文章全部內容,這樣的話,我們就得通過在一級頁面拿到 url 訪問二級頁面,這時候就需要用到請求傳參,
也就是說,當我們使用爬蟲想要爬取的資料沒有存在于同一張頁面的時候,則必須使用請求傳參,
import time
import scrapy
from myBlog.items import MyblogItem
class CsdnSpider(scrapy.Spider):
name = 'csdn'
start_urls = ['https://alex007.blog.csdn.net/']
pageNumber = 1
pageUrl = 'https://alex007.blog.csdn.net/article/list/%d'
def parse(self, response):
print(f"正在爬取第{self.pageNumber}頁,url={self.pageUrl % self.pageNumber},")
divList = response.xpath('//*[@id="mainBox"]/main/div[2]/div')
for div in divList:
item = MyblogItem()
item["name"] = ("".join(div.xpath('.//h4/a/text()').extract())).strip("\n").strip()
contentUrl = div.xpath('.//h4/a/@href').extract_first()
print(f"正在爬取第文章{item['name']},url={contentUrl},")
time.sleep(2)
yield scrapy.Request(url=contentUrl, callback=self.parseContent, meta={'item': item})
if self.pageNumber < 2:
self.pageNumber += 1
url = format(self.pageUrl % self.pageNumber)
# 遞回爬起資料,callback 引數為回呼函式
yield scrapy.Request(url=url, callback=self.parse)
def parseContent(self, response):
item = response.meta["item"]
item["content"] = "".join(response.xpath('//*[@id="content_views"]//text()').extract())
yield item
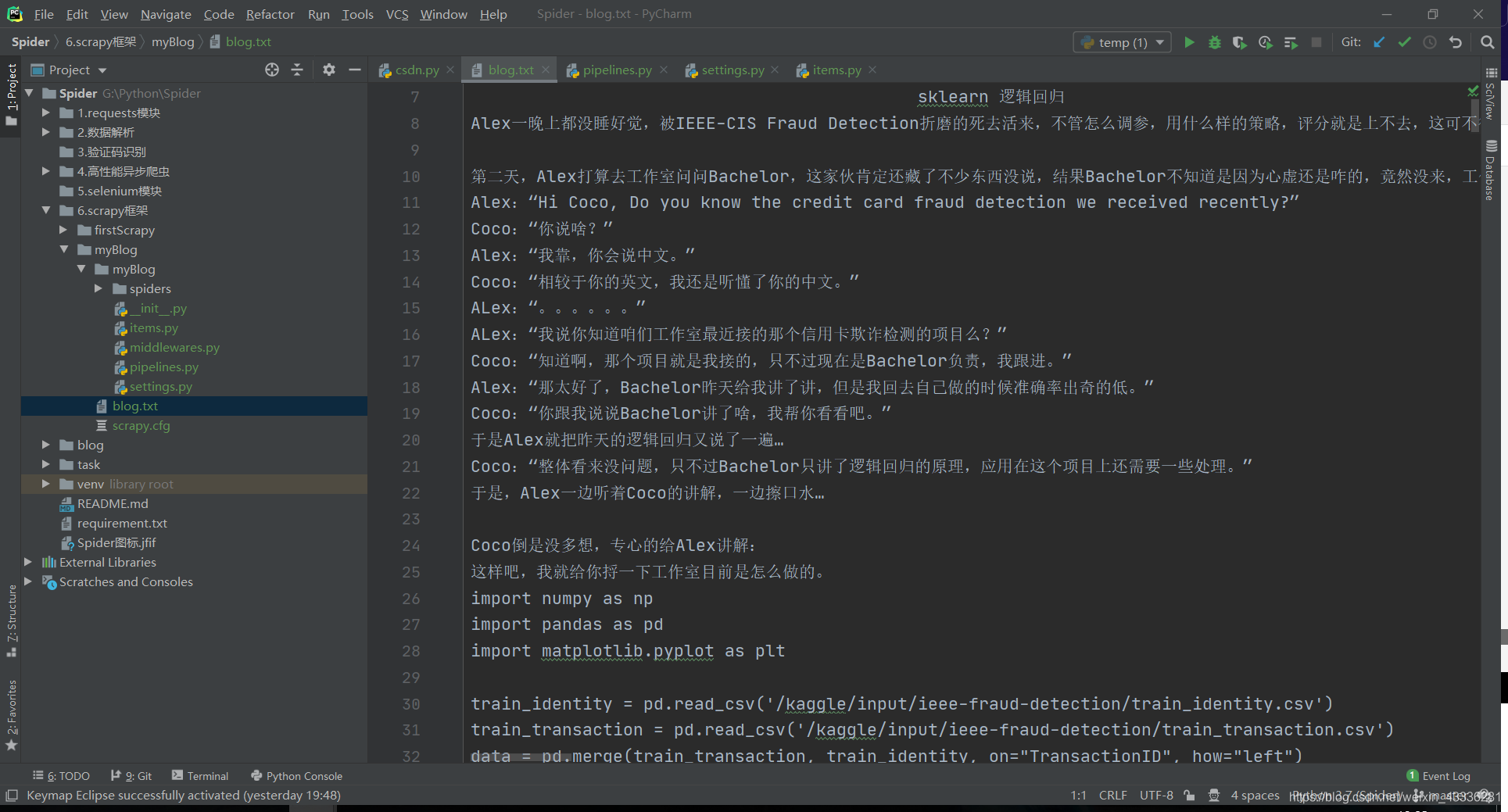
我們通過meta={'item': item}將item傳遞給處理二級頁面函式,然后直接在其中yield item就可以將結果傳遞給管道函式,爬取結果如下:
3.圖片下載
圖片下載也是爬蟲的基本需求,那么 Scrapy 當然也幫我們封裝好了一個專門基于圖片請求和持久化存盤的管道類 ImagesPipeline,
- 在爬蟲檔案中決議出圖片的地址
# -*- coding: utf-8 -*-
import scrapy
from beauty.items import BeautyItem
class ImagesSpider(scrapy.Spider):
name = 'images'
start_urls = ['http://wuming3175.lofter.com//']
pageNumber = 1
pageUrl = "http://wuming3175.lofter.com/?page=%d"
def parse(self, response):
divList = response.xpath('/html/body/div[3]/div')
for div in divList:
item = BeautyItem()
imageSrc = div.xpath('.//div[2]/div[1]/div[1]/a/img/@src').extract_first()
if imageSrc:
item["image_urls"] = imageSrc.split("?")[0]
yield item
if self.pageNumber < 22:
self.pageNumber += 1
url = format(self.pageUrl % self.pageNumber)
yield scrapy.Request(url=url, callback=self.parse)
2.使用 ImagesPipeline 類
class BeautyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
"""用于請求方法"""
print(f'開始下載{item["image_urls"]}')
yield scrapy.Request(url=item["image_urls"])
def file_path(self, request, response=None, info=None):
"""指定檔案存盤路徑"""
return request.url.split('/')[-1]
def item_completed(self, results, item, info):
return item # 該回傳值會傳遞給下一個即將被執行的管道類
- 在 settings.py 檔案中配置管道和圖片存盤路徑
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
# ......
IMAGES_STORE = "./images"
ITEM_PIPELINES = {
'beauty.pipelines.BeautyImagesPipeline': 300,
}
好了,關于 Scrapy 的入門就先講到這里,再寫多了看著都累,如果還想看可以點贊、收藏+關注哦,
寫在最后:
小生才疏學淺,如有謬誤,恭請指正,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73548.html
標籤:其他
上一篇:老大說:誰要再用double定義商品金額,就自己收拾東西走
下一篇:Dr.VAE