許多企業使用Kubernetes來快速發布新功能并提高服務的可靠性,Rancher使團隊能夠減少管理其云原生作業負載的操作成本——但獲得這些環境的持續可見性可能是一個挑戰,
在這篇文章中,我們將探討如何利用Rancher內置支持的Prometheus和Grafana快速開始監控編排作業負載,然后,我們將向你展示如何將Datadog與Rancher集成,通過豐富的可視化、演算法告警和其他功能,幫助你獲得對這些臨時環境更深入的可見性,
Kubernetes監控所面臨的挑戰
Kubernetes集群本質上是復雜和動態的,容器以極快的速度啟動和關閉:在對數千家組織的超過15億個容器進行調查時,Datadog發現,編排容器的周轉速度(一天)是未編排容器的兩倍(兩天),
在這種快節奏的環境中,監控你的應用程式和基礎設施比以往任何時候都重要,Rancher內置支持開源監控工具(如Prometheus和Grafana),允許你從Kubernetes集群中跟蹤基本的健康和資源指標,
Prometheus按照預設的時間間隔從Kubernetes集群收集指標,雖然Prometheus沒有可視化選項,但你可以使用Grafana內置的儀表板來顯示健康和資源指標的總體情況,例如你的pods的CPU使用情況,
然而,一些開源解決方案并不是為了監控大型、動態Kubernetes集群而設計的,此外,Prometheus要求用戶學習PromQL(這是一種專門的查詢語言)以分析和匯總他們的資料,
雖然Prometheus和Grafana可以為你的集群提供一定程度的洞察力,但它們不能讓你看到全貌,例如,你需要連接到其中一個Rancher支持的日志解決方案,以訪問你環境中的日志,而為了排除代碼級問題,你還需要部署一個應用程式性能監控解決方案,
最終,為了充分可視化你的編排集群,你需要在一個平臺上監控所有這些資料源——指標、跟蹤和日志,通過向整個企業的團隊提供詳細的、可操作的資料,一個全面的監控解決方案可以幫助減少檢測和解決的平均時間(MTTD和MTTR),

Datadog Agent:自動發現和自動伸縮服務
為了獲得Rancher解決方案中每一層的持續可見性,你需要一個專門用于實時跟蹤云原生環境的監控解決方案,Datadog Agent是一款輕量級的開源軟體,它可以從你的容器和主機中收集指標、跟蹤和日志,并將它們轉發到你的賬戶,以便進行可視化、分析和告警,
由于Kubernetes部署處于不斷變化的狀態,因此無法手動跟蹤哪些作業負載在哪些節點上運行,或者你的容器在哪里運行,為此,Datadog Agent使用Autodiscovery來檢測容器何時啟動或關閉,并自動開始收集你的容器和它們正在運行的服務的資料,如etcd和Consul,
Kubernetes內置的自動彈性伸縮功能可以根據需求(如CPU使用量激增)自動增加或減少作業負載,從而幫助提高服務的可靠性,自動伸碩訓可以通過調整基礎設施的規模來幫助管理成本,
Datadog擴展了彈性伸縮這一功能,使你能夠根據已經在Datadog中監控的任何指標(包括自定義指標)自動伸縮Kubernetes作業負載,這對于根據需求的波動來擴展集群是非常有用的,特別是在“雙十一”這樣的關鍵業務時期,假設你的公司是一家零售商,擁有繁忙的在線業務,當銷售正在起飛時,你的Kubernetes作業負載可以根據作為活動指標的自定義指標(如結賬數量)進行自動伸縮,以確保流暢的購物體驗,有關使用Datadog自動伸縮Kubernetes作業負載的更多細節,請查看以下文章:
https://www.datadoghq.com/blog/autoscale-kubernetes-datadog/
Kubernetes特定的監控功能
無論你的環境是多云、多集群還是兩者兼而有之,Datadog高度專業化的功能都可以幫助你實時監控你的容器化作業負載,Datadog通過從Kubernetes、Docker、云服務和其他技識訓入的tag自動豐富你的監控資料,Tag為你的環境任意一層提供了持續的可見性,即使單個容器啟動、停止或在主機間移動,你都能夠獲得可視化,例如,你可以搜索所有共享一個標簽(例如,它們正在運行的服務名稱)的容器,然后使用另一個標簽(例如,可用性區域)來分解它們在不同區域的資源使用情況,
Datadog可以收集超過120個Kubernetes指標,幫助你從控制平面健康狀況跟蹤到pod級CPU限制的一切,所有這些監控資料都可以直接在應用中訪問,而無需使用查詢語言,
Datadog提供了幾個功能來幫助你探索和可視化容器基礎設施的資料,Container Map(datadoghq.com/blog/container-map/ )提供了一個Kubernetes環境的鳥瞰圖,并允許你通過任何標簽組合來過濾和分組容器,如docker_image、host和kube_deployment,
你還可以根據任何資源指標的實時值對容器進行顏色編碼,如系統CPU或RSS記憶體,這讓你可以一目了然地快速發現資源爭奪問題,例如,如果一個節點比其他節點消耗了更多的CPU,

實時容器視圖(Live Container view)可以顯示基礎架構中每個容器的流程級系統指標——以兩秒的粒度繪制,由于 CPU 利用率等指標可能非常不穩定,這種高度的顆粒度確保了重要的峰值不會在噪音中消失,
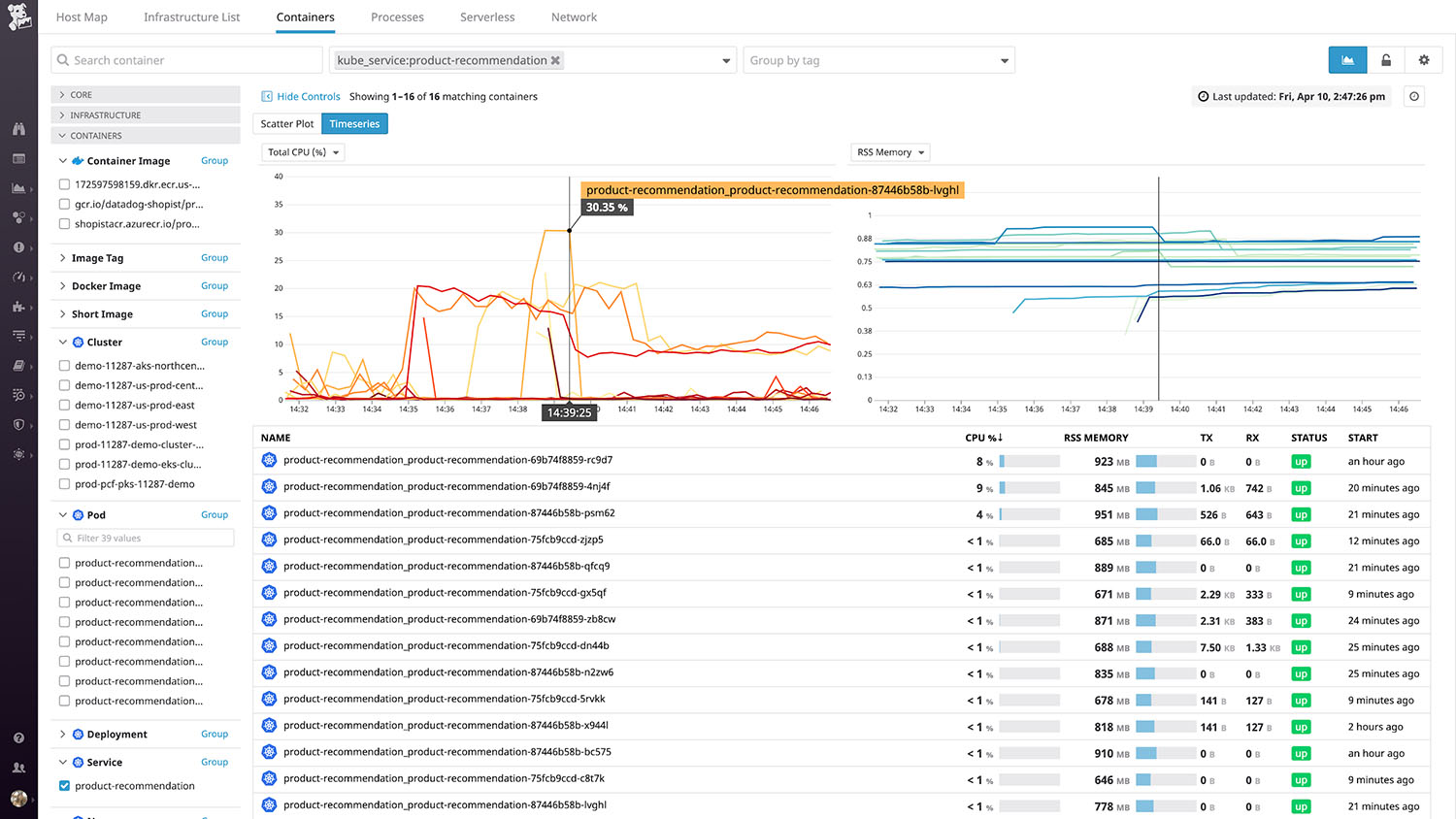
Container Map和 “實時容器 "視圖均允許你使用任意組合的標簽(如鏡像名稱或云提供商)對容器進行過濾和排序,要了解更多細節,你還可以單擊以檢查在任何單個容器上運行的行程,并查看從該容器收集的所有指標、日志和跟蹤,獲取這些資訊只需點擊幾下,這可以幫助你除錯問題,并確定是否需要調整資源的配置,
通過Datadog網路性能監控(NPM),你可以跟蹤整個Kubernetes部署的實時網路流量,并快速除錯問題,從本質上講,Docker容器只受制于可用的CPU和記憶體量,因此,單個容器可能會使網路飽和并使整個系統癱瘓,
Datadog可以幫助你輕松隔離消耗最多網路吞吐量的容器,并通過導航到該服務的相關日志或請求跟蹤來確定可能的根本原因,
Datadog+Rancher協同作業
通過Rancher的Datadog Helm chart,你的團隊可以在幾分鐘內開始監控他們的Kubernetes環境,Datadog與Rancher協同作業,可以讓你使用Rancher管理不同的協調環境,并部署Datadog來實時監控、排除故障和自動擴展環境,
此外,Datadog的演算法監控引擎Watchdog可以發現并提醒團隊成員注意性能例外(如延遲峰值或高錯誤率),這使得團隊能夠在潛在問題(例如容器重啟率例外高)升級之前解決問題,
我們已經向你展示了Datadog如何幫助你獲得Rancher環境的全面可見性,通過Datadog,工程師可以使用APM來識別單個請求中的瓶頸,并準確定位代碼級問題,收集和分析整個基礎設施中每個容器的日志等,通過在一個平臺上統一指標、日志和跟蹤,Datadog消除了切換背景關系或工具的需要,因此,可以加快團隊故障排除作業流程,并充分利用Rancher管理大規模動態集群的全部潛力,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73642.html
標籤:其他