1. 什么是XLNet
XLNet 是一個類似 BERT 的模型,而不是完全不同的模型,總之,XLNet是一種通用的自回歸預訓練方法,它是CMU和Google Brain團隊在2019年6月份發布的模型,最終,XLNet 在 20 個任務上超過了 BERT 的表現,并在 18 個任務上取得了當前最佳效果(state-of-the-art),包括機器問答、自然語言推斷、情感分析和檔案排序,
作者表示,BERT 這樣基于去噪自編碼器的預訓練模型可以很好地建模雙向語境資訊,性能優于基于自回歸語言模型的預訓練方法,然而,由于需要 mask 一部分輸入,BERT 忽略了被 mask 位置之間的依賴關系,因此出現預訓練和微調效果的差異(pretrain-finetune discrepancy),
基于這些優缺點,該研究提出了一種泛化的自回歸預訓練模型 XLNet,XLNet 可以:
- 通過最大化所有可能的因式分解順序的對數似然,學習雙向語境資訊;
- 用自回歸本身的特點克服 BERT 的缺點;
- 此外,XLNet 還融合了當前最優自回歸模型 Transformer-XL 的思路,
2. 自回歸語言模型(Autoregressive LM)
在ELMO/BERT出來之前,大家通常講的語言模型其實是根據上文內容預測下一個可能跟隨的單詞,就是常說的自左向右的語言模型任務,或者反過來也行,就是根據下文預測前面的單詞,這種型別的LM被稱為自回歸語言模型,GPT 就是典型的自回歸語言模型,ELMO盡管看上去利用了上文,也利用了下文,但是本質上仍然是自回歸LM,這個跟模型具體怎么實作有關系,ELMO是做了兩個方向(從左到右以及從右到左兩個方向的語言模型),但是是分別有兩個方向的自回歸LM,然后把LSTM的兩個方向的隱節點狀態拼接到一起,來體現雙向語言模型這個事情的,所以其實是兩個自回歸語言模型的拼接,本質上仍然是自回歸語言模型,
自回歸語言模型有優點有缺點:
缺點是只能利用上文或者下文的資訊,不能同時利用上文和下文的資訊,當然,貌似ELMO這種雙向都做,然后拼接看上去能夠解決這個問題,因為融合模式過于簡單,所以效果其實并不是太好,
優點其實跟下游NLP任務有關,比如生成類NLP任務,比如文本摘要,機器翻譯等,在實際生成內容的時候,就是從左向右的,自回歸語言模型天然匹配這個程序,而Bert這種DAE模式,在生成類NLP任務中,就面臨訓練程序和應用程序不一致的問題,導致生成類的NLP任務到目前為止都做不太好,
3. 自編碼語言模型(Autoencoder LM)
自回歸語言模型只能根據上文預測下一個單詞,或者反過來,只能根據下文預測前面一個單詞,相比而言,Bert通過在輸入X中隨機Mask掉一部分單詞,然后預訓練程序的主要任務之一是根據背景關系單詞來預測這些被Mask掉的單詞,如果你對Denoising Autoencoder比較熟悉的話,會看出,這確實是典型的DAE的思路,那些被Mask掉的單詞就是在輸入側加入的所謂噪音,類似Bert這種預訓練模式,被稱為DAE LM,
這種DAE LM的優缺點正好和自回歸LM反過來,它能比較自然地融入雙向語言模型,同時看到被預測單詞的上文和下文,這是好處,缺點是啥呢?主要在輸入側引入[Mask]標記,導致預訓練階段和Fine-tuning階段不一致的問題,因為Fine-tuning階段是看不到[Mask]標記的,DAE嗎,就要引入噪音,[Mask] 標記就是引入噪音的手段,這個正常,
XLNet的出發點就是:能否融合自回歸LM和DAE LM兩者的優點,就是說如果站在自回歸LM的角度,如何引入和雙向語言模型等價的效果;如果站在DAE LM的角度看,它本身是融入雙向語言模型的,如何拋掉表面的那個[Mask]標記,讓預訓練和Fine-tuning保持一致,當然,XLNet還講到了一個Bert被Mask單詞之間相互獨立的問題,
4. XLNet模型
4.1 排列語言建模(Permutation Language Modeling)
Bert的自編碼語言模型也有對應的缺點,就是XLNet在文中指出的:
- 第一個預訓練階段因為采取引入[Mask]標記來Mask掉部分單詞的訓練模式,而Fine-tuning階段是看不到這種被強行加入的Mask標記的,所以兩個階段存在使用模式不一致的情形,這可能會帶來一定的性能損失;
- 另外一個是,Bert在第一個預訓練階段,假設句子中多個單詞被Mask掉,這些被Mask掉的單詞之間沒有任何關系,是條件獨立的,而有時候這些單詞之間是有關系的,
上面兩點是XLNet在第一個預訓練階段,相對Bert來說要解決的兩個問題,
其實思路也比較簡潔,可以這么思考:XLNet仍然遵循兩階段的程序,第一個階段是語言模型預訓練階段;第二階段是任務資料Fine-tuning階段,它主要希望改動第一個階段,就是說不像Bert那種帶Mask符號的Denoising-autoencoder的模式,而是采用自回歸LM的模式,就是說,看上去輸入句子X仍然是自左向右的輸入,看到Ti單詞的上文Context_before,來預測Ti這個單詞,但是又希望在Context_before里,不僅僅看到上文單詞,也能看到Ti單詞后面的下文Context_after里的下文單詞,這樣的話,Bert里面預訓練階段引入的Mask符號就不需要了,于是在預訓練階段,看上去是個標準的從左向右程序,Fine-tuning當然也是這個程序,于是兩個環節就統一起來,當然,這是目標,剩下是怎么做到這一點的問題,
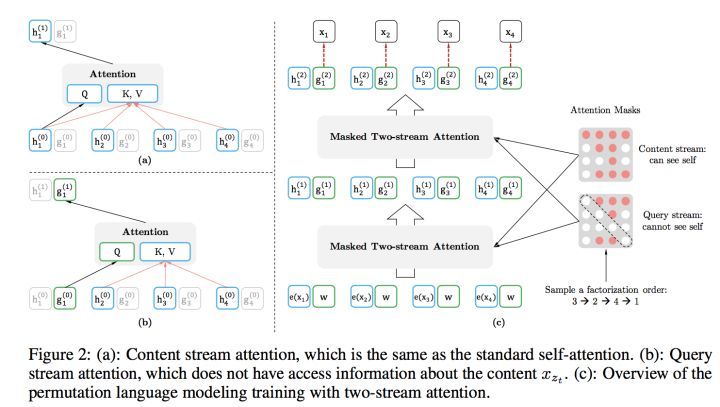
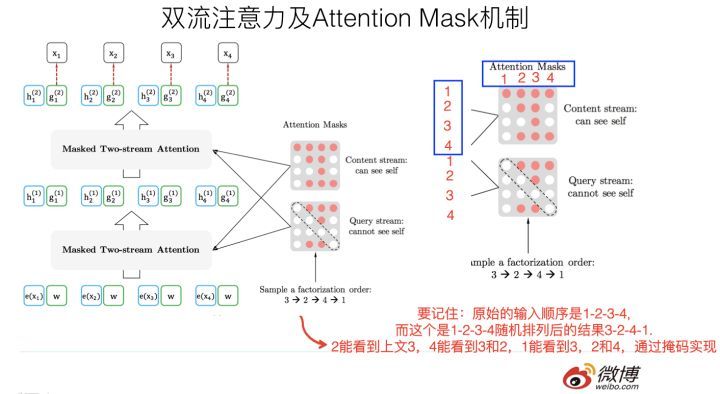
首先,需要強調一點,盡管上面講的是把句子X的單詞排列組合后,再隨機抽取例子作為輸入,但是,實際上你是不能這么做的,因為Fine-tuning階段你不可能也去排列組合原始輸入,所以,就必須讓預訓練階段的輸入部分,看上去仍然是x1,x2,x3,x4這個輸入順序,但是可以在Transformer部分做些作業,來達成我們希望的目標,
具體而言,XLNet采取了Attention掩碼的機制,你可以理解為,當前的輸入句子是X,要預測的單詞Ti是第i個單詞,前面1到i-1個單詞,在輸入部分觀察,并沒發生變化,該是誰還是誰,但是在Transformer內部,通過Attention掩碼,從X的輸入單詞里面,也就是Ti的上文和下文單詞中,隨機選擇i-1個,放到Ti的上文位置中,把其它單詞的輸入通過Attention掩碼隱藏掉,于是就能夠達成我們期望的目標(當然這個所謂放到Ti的上文位置,只是一種形象的說法,其實在內部,就是通過Attention Mask,把其它沒有被選到的單詞Mask掉,不讓它們在預測單詞Ti的時候發生作用,如此而已,看著就類似于把這些被選中的單詞放到了上文Context_before的位置了),
具體實作的時候,XLNet是用“雙流自注意力模型”實作的,細節可以參考論文,但是基本思想就如上所述,雙流自注意力機制只是實作這個思想的具體方式,理論上,你可以想出其它具體實作方式來實作這個基本思想,也能達成讓Ti看到下文單詞的目標,
這里簡單說下“雙流自注意力機制”,一個是內容流自注意力,其實就是標準的Transformer的計算程序;主要是引入了Query流自注意力,這個是干嘛的呢?其實就是用來代替Bert的那個[Mask]標記的,因為XLNet希望拋掉[Mask]標記符號,但是比如知道上文單詞x1,x2,要預測單詞x3,此時在x3對應位置的Transformer最高層去預測這個單詞,但是輸入側不能看到要預測的單詞x3,Bert其實是直接引入[Mask]標記來覆寫掉單詞x3的內容的,等于說[Mask]是個通用的占位符號,而XLNet因為要拋掉[Mask]標記,但是又不能看到x3的輸入,于是Query流,就直接忽略掉x3輸入了,只保留這個位置資訊,用引數w來代表位置的embedding編碼,其實XLNet只是扔了表面的[Mask]占位符號,內部還是引入Query流來忽略掉被Mask的這個單詞,和Bert比,只是實作方式不同而已,
上面講的Permutation Language Model是XLNet的主要理論創新,所以介紹的比較多,從模型角度講,這個創新還是挺有意思的,因為它開啟了自回歸語言模型如何引入下文的一個思路,相信對于后續作業會有啟發,當然,XLNet不僅僅做了這些,它還引入了其它的因素,也算是一個當前有效技術的集成體,感覺XLNet就是Bert、GPT 2.0和Transformer XL的綜合體變身:
- 首先,它通過PLM(Permutation Language Model)預訓練目標,吸收了Bert的雙向語言模型;
- 然后,GPT2.0的核心其實是更多更高質量的預訓練資料,這個明顯也被XLNet吸收進來了;
- 再然后,Transformer XL的主要思想也被吸收進來,它的主要目標是解決Transformer對于長檔案NLP應用不夠友好的問題,
4.2 Transformer XL
目前在NLP領域中,處理語言建模問題有兩種最先進的架構:RNN和Transformer,RNN按照序列順序逐個學習輸入的單詞或字符之間的關系,而Transformer則接收一整段序列,然后使用self-attention機制來學習它們之間的依賴關系,這兩種架構目前來看都取得了令人矚目的成就,但它們都局限在捕捉長期依賴性上,
為了解決這一問題,CMU聯合Google Brain在2019年1月推出的一篇新論文《Transformer-XL:Attentive Language Models beyond a Fixed-Length Context》同時結合了RNN序列建模和Transformer自注意力機制的優點,在輸入資料的每個段上使用Transformer的注意力模塊,并使用回圈機制來學習連續段之間的依賴關系,
4.2.1 vanilla Transformer
為何要提這個模型?因為Transformer-XL是基于這個模型進行的改進,
Al-Rfou等人基于Transformer提出了一種訓練語言模型的方法,來根據之前的字符預測片段中的下一個字符,例如,它使用 \(x_1,x_2,...,x_{n-1}\) 預測字符 \(x_n\),而在 \(x_n\) 之后的序列則被mask掉,論文中使用64層模型,并僅限于處理 512個字符這種相對較短的輸入,因此它將輸入分成段,并分別從每個段中進行學習,如下圖所示, 在測驗階段如需處理較長的輸入,該模型會在每一步中將輸入向右移動一個字符,以此實作對單個字符的預測,
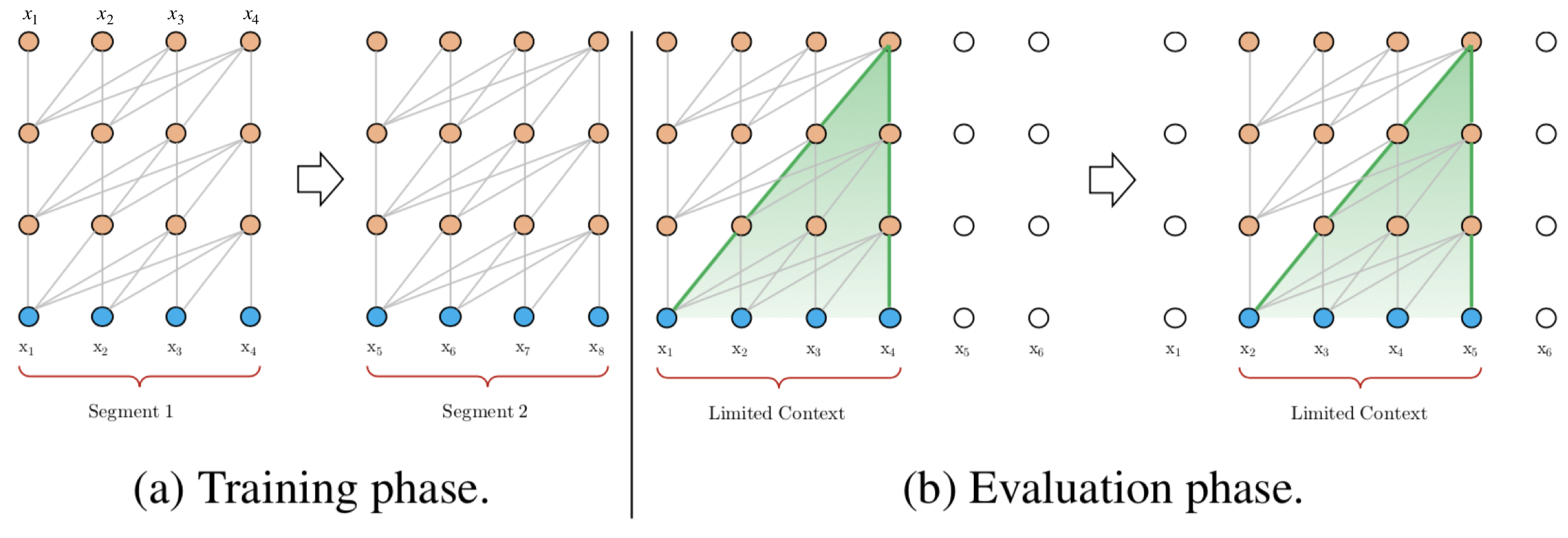
該模型在常用的資料集如enwik8和text8上的表現比RNN模型要好,但它仍有以下缺點:
- 背景關系長度受限:字符之間的最大依賴距離受輸入長度的限制,模型看不到出現在幾個句子之前的單詞,
- 背景關系碎片:對于長度超過512個字符的文本,都是從頭開始單獨訓練的,段與段之間沒有背景關系依賴性,會讓訓練效率低下,也會影響模型的性能,
- 推理速度慢:在測驗階段,每次預測下一個單詞,都需要重新構建一遍背景關系,并從頭開始計算,這樣的計算速度非常慢,
4.2.2 Transformer XL
Transformer-XL架構在vanilla Transformer的基礎上引入了兩點創新:回圈機制(Recurrence Mechanism)和相對位置編碼(Relative Positional Encoding),以克服vanilla Transformer的缺點,與vanilla Transformer相比,Transformer-XL的另一個優勢是它可以被用于單詞級和字符級的語言建模,
-
引入回圈機制
與vanilla Transformer的基本思路一樣,Transformer-XL仍然是使用分段的方式進行建模,但其與vanilla Transformer的本質不同是在于引入了段與段之間的回圈機制,使得當前段在建模的時候能夠利用之前段的資訊來實作長期依賴性,如下圖所示:
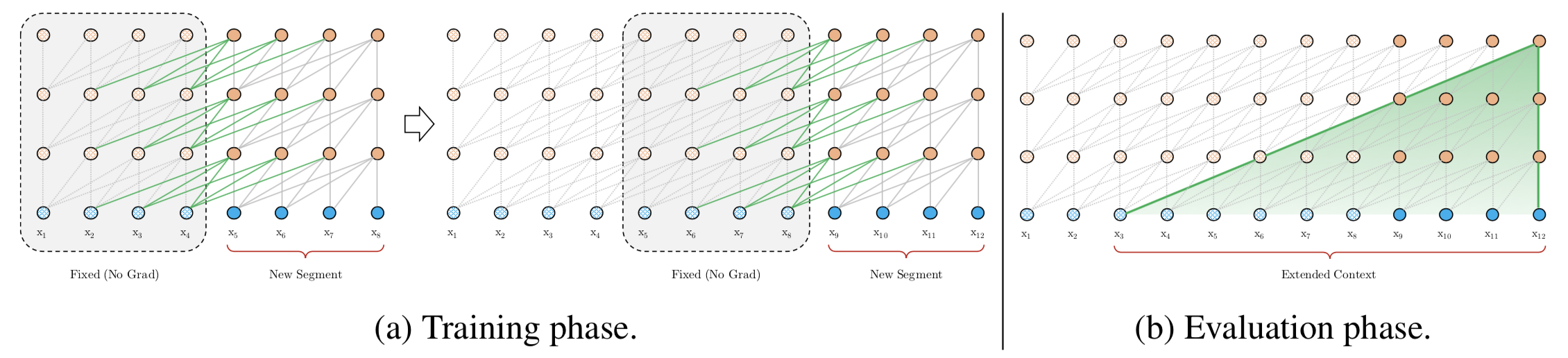
在訓練階段,處理后面的段時,每個隱藏層都會接收兩個輸入:
- 該段的前面隱藏層的輸出,與vanilla Transformer相同(上圖的灰色線),
- 前面段的隱藏層的輸出(上圖的綠色線),可以使模型創建長期依賴關系,
這兩個輸入會被拼接,然后用于計算當前段的Key和Value矩陣,
該方法可以利用前面更多段的資訊,測驗階段也可以獲得更長的依賴,在測驗階段,與vanilla Transformer相比,其速度也會更快,在vanilla Transformer中,一次只能前進一個step,并且需要重新構建段,并全部從頭開始計算;而在Transformer-XL中,每次可以前進一整個段,并利用之前段的資料來預測當前段的輸出,
-
相對位置編碼
在Transformer中,一個重要的地方在于其考慮了序列的位置資訊,在分段的情況下,如果僅僅對于每個段仍直接使用Transformer中的位置編碼,即每個不同段在同一個位置上的表示使用相同的位置編碼,就會出現問題,比如,第i?2i-2i?2段和第i?1i-1i?1段的第一個位置將具有相同的位置編碼,但它們對于第iii段的建模重要性顯然并不相同(例如第i?2i-2i?2段中的第一個位置重要性可能要低一些),因此,需要對這種位置進行區分,
論文對于這個問題,提出了一種新的位置編碼的方式,即會根據詞之間的相對距離而非像Transformer中的絕對位置進行編碼,從另一個角度來解讀公式的話,可以將attention的計算分為如下四個部分:
- 基于內容的“尋址”,即沒有添加原始位置編碼的原始分數,
- 基于內容的位置偏置,即相對于當前內容的位置偏差,
- 全域的內容偏置,用于衡量key的重要性,
- 全域的位置偏置,根據query和key之間的距離調整重要性,
詳細公式見:Transformer-XL解讀(論文 + PyTorch原始碼)
5. XLNet與BERT比較
盡管看上去,XLNet在預訓練機制引入的Permutation Language Model這種新的預訓練目標,和Bert采用Mask標記這種方式,有很大不同,其實你深入思考一下,會發現,兩者本質是類似的,
區別主要在于:
- Bert是直接在輸入端顯示地通過引入Mask標記,在輸入側隱藏掉一部分單詞,讓這些單詞在預測的時候不發揮作用,要求利用背景關系中其它單詞去預測某個被Mask掉的單詞;
- 而XLNet則拋棄掉輸入側的Mask標記,通過Attention Mask機制,在Transformer內部隨機Mask掉一部分單詞(這個被Mask掉的單詞比例跟當前單詞在句子中的位置有關系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),讓這些被Mask掉的單詞在預測某個單詞的時候不發生作用,
所以,本質上兩者并沒什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet則把這個程序隱藏在了Transformer內部而已,這樣,就可以拋掉表面的[Mask]標記,解決它所說的預訓練里帶有[Mask]標記導致的和Fine-tuning程序不一致的問題,至于說XLNet說的,Bert里面被Mask掉單詞的相互獨立問題,也就是說,在預測某個被Mask單詞的時候,其它被Mask單詞不起作用,這個問題,你深入思考一下,其實是不重要的,因為XLNet在內部Attention Mask的時候,也會Mask掉一定比例的背景關系單詞,只要有一部分被Mask掉的單詞,其實就面臨這個問題,而如果訓練資料足夠大,其實不靠當前這個例子,靠其它例子,也能彌補被Mask單詞直接的相互關系問題,因為總有其它例子能夠學會這些單詞的相互依賴關系,
當然,XLNet這種改造,維持了表面看上去的自回歸語言模型的從左向右的模式,這個Bert做不到,這個有明顯的好處,就是對于生成類的任務,能夠在維持表面從左向右的生成程序前提下,模型里隱含了背景關系的資訊,所以看上去,XLNet貌似應該對于生成型別的NLP任務,會比Bert有明顯優勢,另外,因為XLNet還引入了Transformer XL的機制,所以對于長檔案輸入型別的NLP任務,也會比Bert有明顯優勢,
6. 代碼實作
中文XLNet預訓練模型
【機器學習通俗易懂系列文章】
7. 參考文獻
- XLNet原理解讀
- XLNet:運行機制及和Bert的異同比較
- Transformer-XL解讀(論文 + PyTorch原始碼)
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
歡迎大家加入討論!共同完善此專案!群號:【541954936】

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73653.html
標籤:其他