作者:凌逆戰
博客地址:https:////www.cnblogs.com/LXP-Never/p/11614053.html
從事深度學習的研究者都知道,深度學習代碼需要設計海量的資料,需要很大很大很大(重要的事情說三遍)的計算量,以至于CPU算不過來,需要通過GPU幫忙,但這必不意味著CPU的性能沒GPU強,CPU是那種綜合性的,GPU是專門用來做影像渲染的,這我們大家都知道,做影像矩陣的計算GPU更加在行,應該我們一般把深度學習程式讓GPU來計算,事實也證明GPU的計算速度比CPU塊,但是(但是前面的話都是廢話)我們窮,買不起呀,一塊1080Ti現在也要3500左右,2080Ti要9000左右,具體價格還要看顯存大小,因此本文給大家帶來了福利——Google免費的GPU Colaboratory,
Google Colab簡介
Google Colaboratory是谷歌開放的一款研究工具,主要用于機器學習的開發研究,這款工具現在可以免費使用,但是不是永久免費暫時還不確定,Google Colab最大的好處是給廣大開發AI者提供免費的GPU使用!GPU型號是Tesla K80,你可以在上面輕松地跑例如:Keras、Tensorflow、Pytorch等框架,
Colabortory是一個jupyter notebook環境,它支持python2和python3,還包括TPU和GPU加速,該軟體與Google云盤硬碟集成,用戶可以輕松共享專案或將其他共享專案復制到自己的帳戶中,
Colaboratory使用步驟
1、登錄谷歌云盤
https://drive.google.com/drive/my-drive(沒有賬號的可以注冊一個)
(1)、右鍵新建檔案夾,作為我們的專案檔案夾,
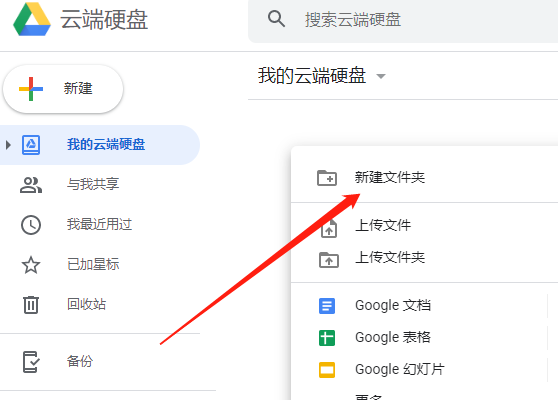
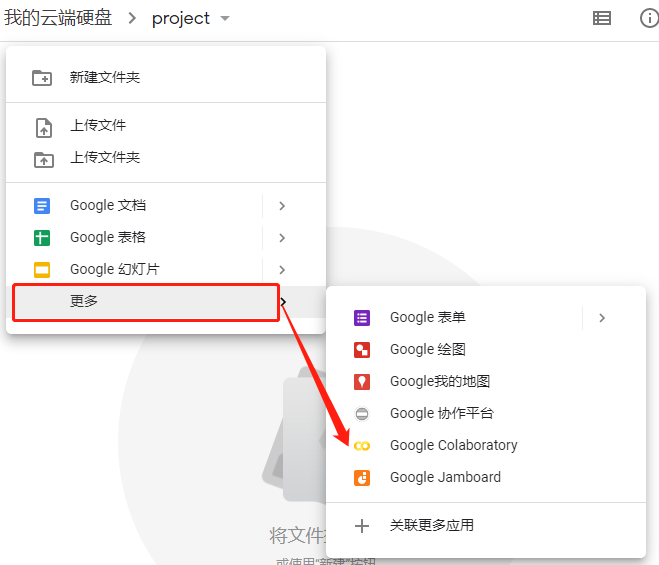
2、創建Colab檔案
右鍵在更多里面選擇google Colaboratry(如果沒有Colaboratory需要在關聯更多應用里面關聯Colaboratory)
3、選擇配置環境
我們大家肯定會疑慮,上述方法跑的那段程式是不是用GPU跑的呢?不是,想要用GPU跑程式我們還需要配置環境,
點擊工具列“修改”,選擇筆記本設定
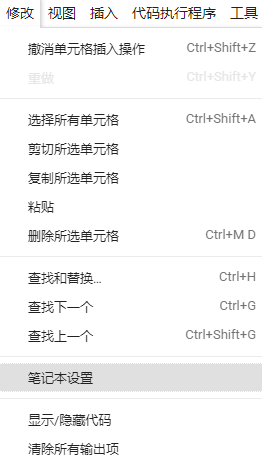
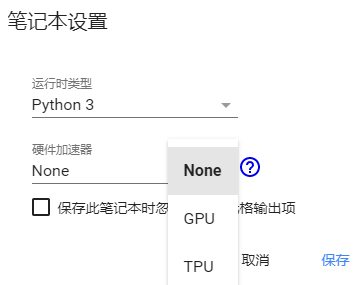
在運行時型別我們可以選擇Python 2或Python 3,硬體加速器我們可以選擇GPU或者TPU(后面會講到),或者None什么都不用,
4、開始使用
這時候會直接跳轉到Colaboratory界面,這個界面很像Jupyter Notebook,Jupyter的命令在Colaboratory一樣適用,值得一提的是,Colab不僅可以運行Python代碼,只要在命令前面加一個" !",這條命令就變成了linux命令,比如我們可以" ! ls"查看檔案夾檔案,還可以!pip安裝庫,以及運行py程式!python2 temp.py
可以寫一段代碼進行測驗
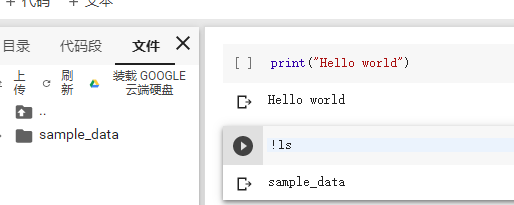
(1)、掛載google drive
from google.colab import drivedrive.mount('/content/gdrive')# 更改作業目錄!pwd # 用 pwd 命令顯示作業路徑import os os.chdir("/content/gdrive/My Drive/deepmodel")os.getcwd()!ls # 查看的是 content 檔案夾下有哪些檔案
更改作業目錄,在Colab中cd命令是無效的,切換作業目錄使用chdir函式
重新啟動Colab:!kill -9 -1
(2)、配置環境
安裝tensorflow-gpu 1.12.0版本
!pip install tensorflow-gpu==1.12.0
安裝scipy 1.2.1版本
!pip install scipy==1.2.1
cuda降級到版本9
!wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb!dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb!apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub!apt-get update!apt-get install cuda=9.0.176-1
或者將cuda降級到版本8.0
!wget https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb!dpkg -i cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb!apt-get update!apt-get install cuda=8.0.61-1
查看TensorFlow和cuda的版本
import tensorflow as tfprint(tf.__version__)!nvcc --version
查看顯卡記憶體使用上限
from tensorflow.python.client import device_libdevice_lib.list_local_devices()
查看分配的GPU引數
!nvidia-smi
查看GPU是否在colab中
import tensorflow as tftf.test.gpu_device_name()
如果結果為空,則不能使用GPU,如果結果為/device:GPU:0
加載資料
從本地加載資料
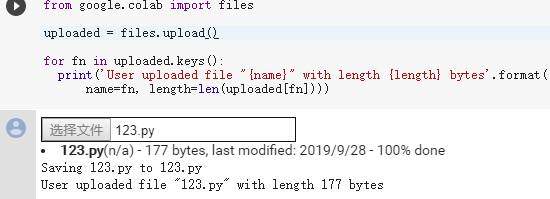
從本地上傳資料
files.upload 會回傳已上傳檔案的字典, 此字典的鍵為檔案名,值為已上傳的資料,
from google.colab import filesuploaded = files.upload()for fn in uploaded.keys(): print('用戶上傳的檔案 "{name}" 有 {length} bytes'.format( name=fn, length=len(uploaded[fn])))
我們運行該段程式之后,就會讓我們選擇本地檔案,點擊上傳后,該檔案就能被讀取了
將檔案下載到本地
from google.colab import filesfiles.download('./example.txt') # 下載檔案
從谷歌云盤加載資料
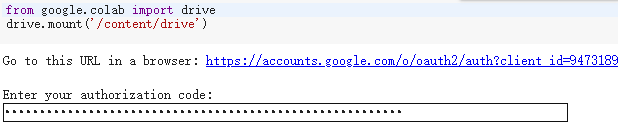
使用授權代碼在運行時裝載 Google 云端硬碟
from google.colab import drivedrive.mount('/content/gdrive')
在Colab中運行上述代碼,會出現一段鏈接,點擊鏈接,復制鏈接中的密鑰,輸入到Colab中就可以成功把Colab與谷歌云盤相連接,連接后進行路徑切換,就可以直接讀取谷歌云盤資料了,
向Google Colab添加表單
為了不每次都在代碼中更改超引數,您可以簡單地將表單添加到Google Colab,
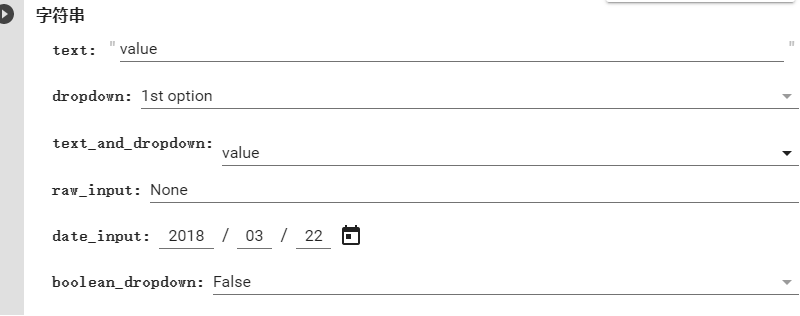
點擊之后就會出現左右兩個框,我們在左框中輸入

# @title 字串text = 'value' #@param {type:"string"}dropdown = '1st option' #@param ["1st option", "2nd option", "3rd option"]text_and_dropdown = 'value' #@param ["選項1", "選項2", "選項3"] {allow-input: true}print(text)print(dropdown)print(text_and_dropdown)

雙擊右邊欄可以隱藏代碼
Colab中的GPU
首先我們要讓Colab連上GPU,導航欄-->編輯-->筆記本設定-->選擇GPU
接下來我們來確認可以使用Tensorflow連接到GPU
import tensorflow as tfdevice_name = tf.test.gpu_device_name()if device_name != '/device:GPU:0': raise SystemError('沒有發現GPU device')print('Found GPU at: {}'.format(device_name))# Found GPU at: /device:GPU:0
我們可以在Colab上運行以下代碼測驗GPU和CPU的速度


import tensorflow as tfimport timeitconfig = tf.ConfigProto()config.gpu_options.allow_growth = Truewith tf.device('/cpu:0'): random_image_cpu = tf.random_normal((100, 100, 100, 3)) net_cpu = tf.layers.conv2d(random_image_cpu, 32, 7) net_cpu = tf.reduce_sum(net_cpu)with tf.device('/device:GPU:0'): random_image_gpu = tf.random_normal((100, 100, 100, 3)) net_gpu = tf.layers.conv2d(random_image_gpu, 32, 7) net_gpu = tf.reduce_sum(net_gpu)sess = tf.Session(config=config)# 確保TF可以檢測到GPUtry: sess.run(tf.global_variables_initializer())except tf.errors.InvalidArgumentError: print( '\n\n此錯誤很可能表示此筆記本未配置為使用GPU, ' '通過命令面板(CMD/CTRL-SHIFT-P)或編輯選單在筆記本設定中更改此設定.\n\n') raisedef cpu(): sess.run(net_cpu) def gpu(): sess.run(net_gpu) # 運行一次進行測驗cpu()gpu()# 多次運行opprint('將100*100*100*3通過濾波器卷積到32*7*7*3(批處理x高度x寬度x通道)大小的影像' '計算10次運訓時間的總和')print('CPU (s):')cpu_time = timeit.timeit('cpu()', number=10, setup="from __main__ import cpu")print(cpu_time)print('GPU (s):')gpu_time = timeit.timeit('gpu()', number=10, setup="from __main__ import gpu")print(gpu_time)print('GPU加速超過CPU: {}倍'.format(int(cpu_time/gpu_time)))sess.close()# CPU (s):# 3.593296914000007# GPU (s):# 0.1831514239999592# GPU加速超過CPU: 19倍View Code
Colab中的TPU
首先我們要讓Colab連上GPU,導航欄-->編輯-->筆記本設定-->選擇TPU
接下來我們來確認可以使用Tensorflow連接到TPU
import osimport pprintimport tensorflow as tfif 'COLAB_TPU_ADDR' not in os.environ: print('您沒有連接到TPU,請完成上述操作')else: tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR'] print ('TPU address is', tpu_address) # TPU address is grpc://10.97.206.146:8470 with tf.Session(tpu_address) as session: devices = session.list_devices() print('TPU devices:') pprint.pprint(devices)
使用TPU進行簡單運算
import numpy as npdef add_op(x, y): return x + y x = tf.placeholder(tf.float32, [10,])y = tf.placeholder(tf.float32, [10,])tpu_ops = tf.contrib.tpu.rewrite(add_op, [x, y]) session = tf.Session(tpu_address)try: print('Initializing...') session.run(tf.contrib.tpu.initialize_system()) print('Running ops') print(session.run(tpu_ops, {x: np.arange(10), y: np.arange(10)})) # [array([ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.], dtype=float32)]finally: # 目前,tpu會話必須與關倍訓話分開關閉, session.run(tf.contrib.tpu.shutdown_system()) session.close()
在Colab中運行Tensorboard
想要在Google Colab中運行Tensorboard,請運行以下代碼
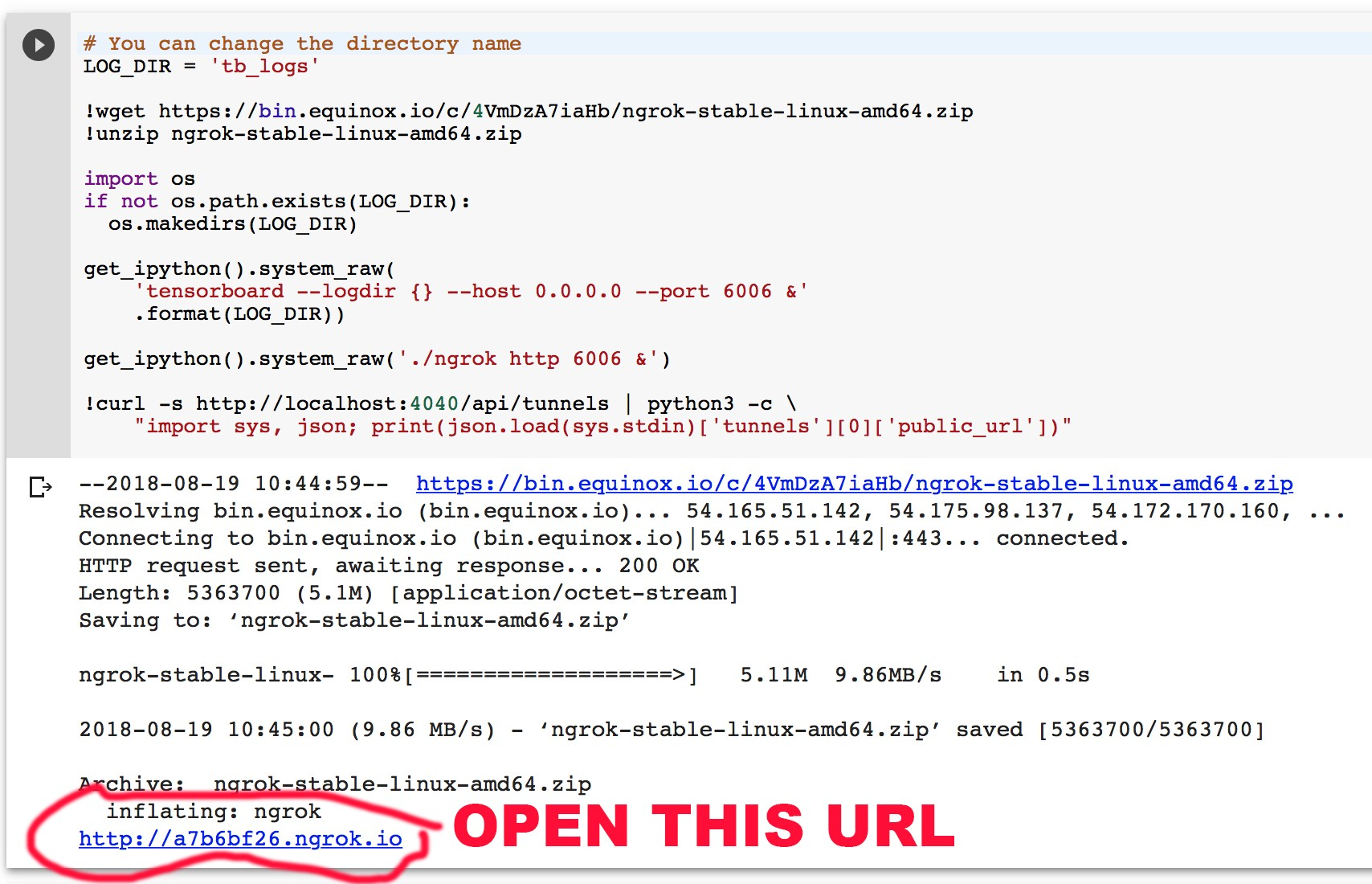
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip!unzip ngrok-stable-linux-amd64.zip# 添加TensorBoard的路徑import oslog_dir = 'tb_logs'if not os.path.exists(log_dir): os.makedirs(log_dir)# 開啟ngrok service,系結port 6006(tensorboard)get_ipython().system_raw('tensorboard --logdir {} --host 0.0.0.0 --port 6006 &'.format(log_dir))get_ipython().system_raw('./ngrok http 6006 &')# 產生網站,點擊網站訪問tensorboard!curl -s http://localhost:4040/api/tunnels | python3 -c \ "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
您可以使用創建的ngrok.io URL 跟蹤Tensorboard日志,您將在輸出末尾找到URL,請注意,您的Tensorboard日志將保存到tb_logs目錄,當然,您可以更改目錄名稱,
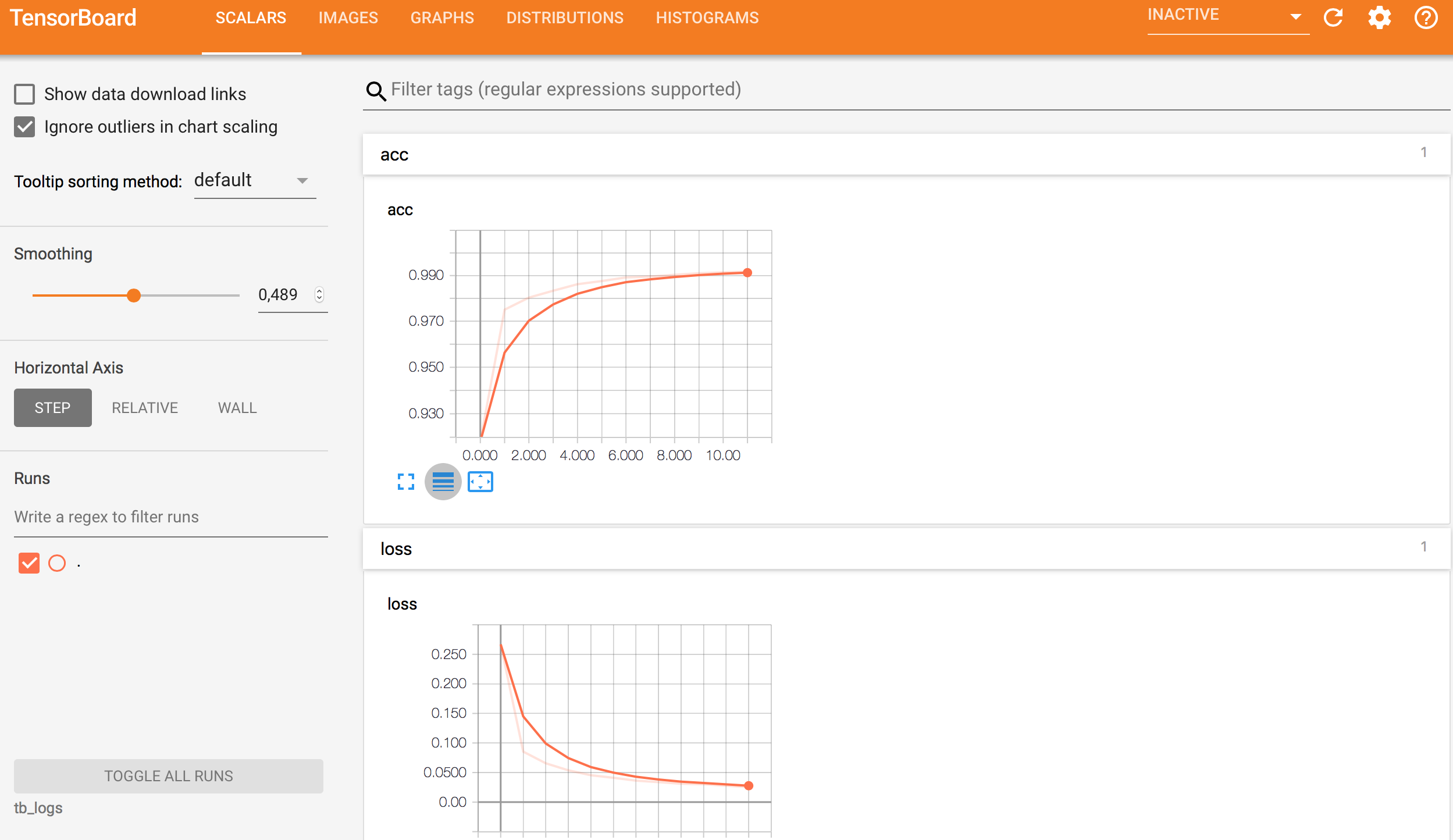
之后,我們可以看到Tensorboard發揮作用!運行以下代碼后,您可以通過ngrok URL跟蹤Tensorboard日志,
from __future__ import print_functionimport kerasfrom keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flattenfrom keras.layers import Conv2D, MaxPooling2Dfrom keras import backend as Kfrom keras.callbacks import TensorBoardbatch_size = 128num_classes = 10epochs = 12# input image dimensionsimg_rows, img_cols = 28, 28# the data, shuffled and split between train and test sets(x_train, y_train), (x_test, y_test) = mnist.load_data()if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols)else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1)x_train = x_train.astype('float32')x_test = x_test.astype('float32')x_train /= 255x_test /= 255print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')# convert class vectors to binary class matricesy_train = keras.utils.to_categorical(y_train, num_classes)y_test = keras.utils.to_categorical(y_test, num_classes)model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dropout(0.5))model.add(Dense(num_classes, activation='softmax'))model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])tbCallBack = TensorBoard(log_dir=LOG_DIR, histogram_freq=1, write_graph=True, write_grads=True, batch_size=batch_size, write_images=True)model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=[tbCallBack])score = model.evaluate(x_test, y_test, verbose=0)print('Test loss:', score[0])print('Test accuracy:', score[1])View Code
參考
Colaboratory官方檔案
一位外國小哥寫的博客,總結的不錯
CUDA降級方法
Colab配置: 使用gpu訓練模型
利用Colab上的TPU訓練Keras模型(完整版)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73664.html
標籤:其他
上一篇:機器學習實戰_KNN(一)
下一篇:遵循統一的機器學習框架理解SVM