主成分分析(Principal Component Analysis)
- 一個非監督的機器學習演算法
- 主要用于資料的降維
- 通過降維,可以發現更便于人類理解的特征
- 其他應用:可視化、去噪
通過映射,我們可以把資料從二維降到一維:
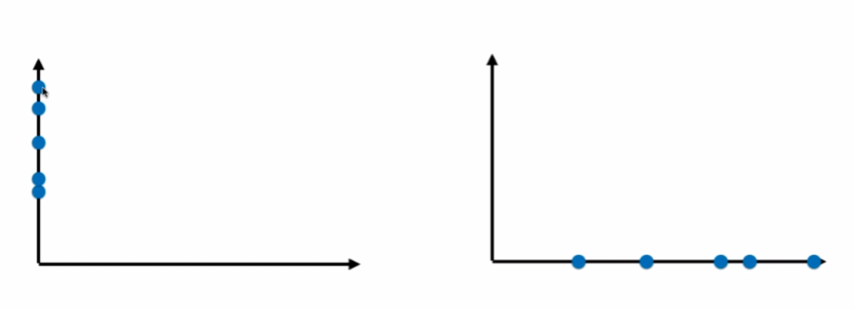
顯然,右邊的要好一點,因為間距大,更容易看出差距,
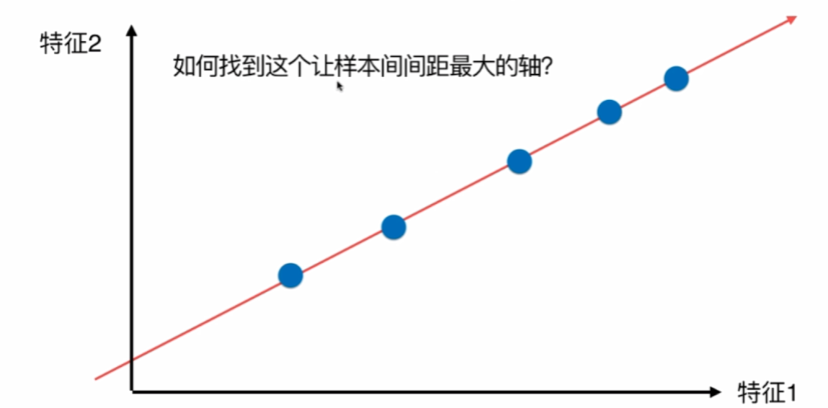
如何定義樣本間距?使用方差,因為方差越小,資料月密集,方差越大,資料月分散,
另均值為0:
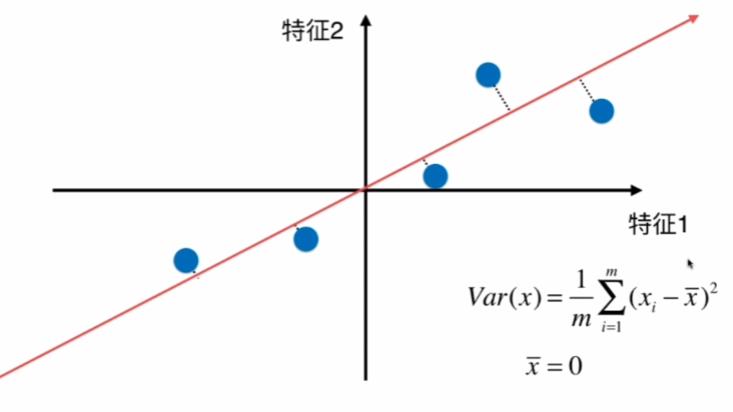

因為均值為0,w是單位向量,模為1,所以:
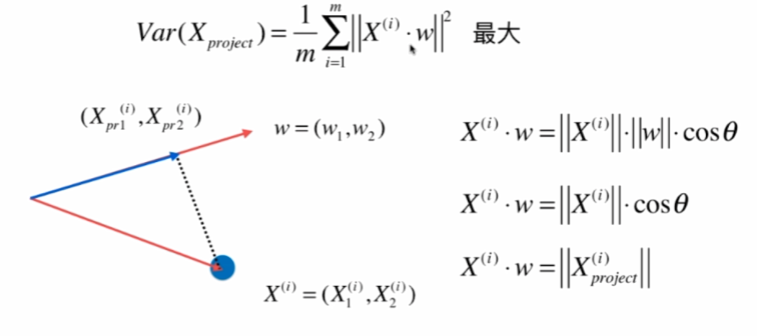

梯度上升法求解PCA問題


分析:X是mn的矩陣,m是樣本數,n是特征數,X^(i)是第i個樣本,w是n * 1 的矩陣,那么這n個∑X^(i) * w就等于Xw (m行1列)
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100個0~100的均勻分布點
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100個均值為0,標準差為10的正態分布點
plt.scatter(X[:,0],X[:,1])
plt.show()
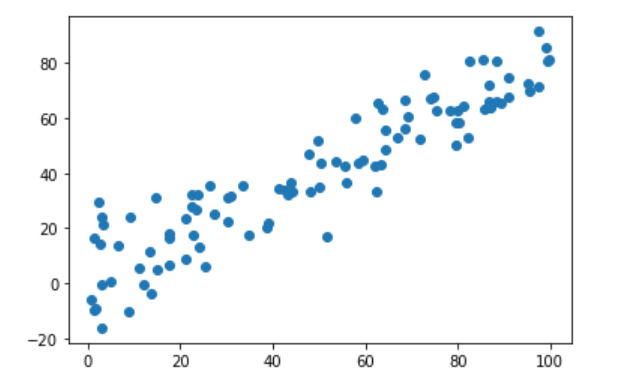
demean(每一維的樣本均值歸0):
def demean(X):
return X-np.mean(X,axis=0)#對X的每一列的每個數減去這一列的均值,即可讓X的每一列均值變為0
X_demean=demean(X)
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.show()
np.mean(X_demean[:,0])
np.mean(X_demean[:,1])
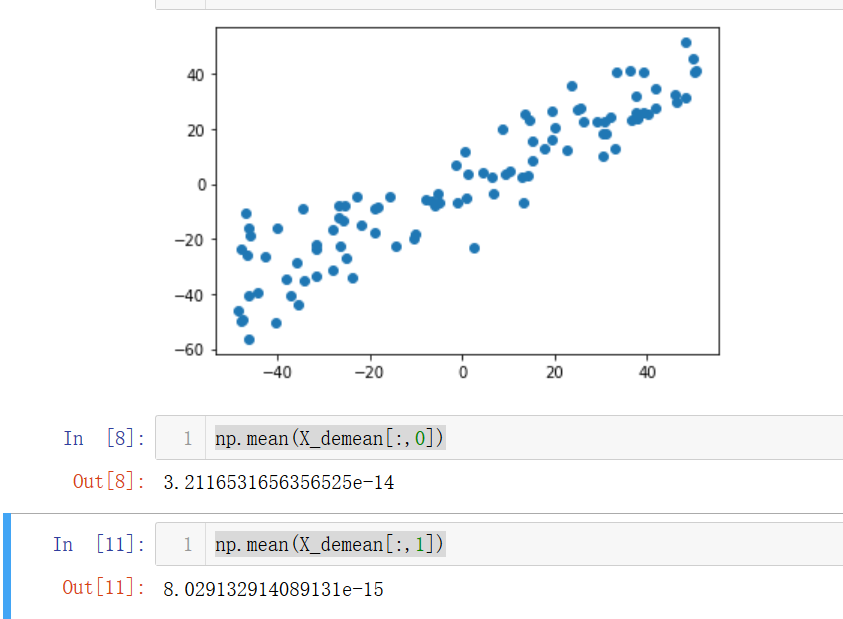
發現兩個維度的均值都幾乎為0,
梯度上升:
def f(w,X):
return np.sum((X.dot(w)**2))/len(X)
def df_math(w,X):
return X.T.dot(X.dot(w))*2./len(X)
def df_debug(w,X,epsilon=0.0001): #除錯梯度
res=np.empty(len(w))
for i in range(len(w)):
w_1=w.copy()
w_1[i]+=epsilon
w_2=w.copy()
w_2[i]-=epsilon
res[i]=(f(w_1,X)-f(w_2,X))/(2*epsilon)
return res
def direction(w):#化成單位向量
return w/np.linalg.norm(w) #除以w的模即可
def gradient_ascent(df,X,initial_w,eta,n_iters=1e4,epsilon=1e-8):
#梯度上升法
w=direction(initial_w)
cur_iter=0
while cur_iter < n_iters:
gradient = df(w,X)
last_w=w
w=w+eta*gradient #變成加法
w=direction(w) #注意1:化成單位向量
if(abs(f(w,X)-f(last_w,X))<epsilon):
break
cur_iter+=1
return w
initial_w=np.random.random(X.shape[1]) #注意2:不能用0向量開始,不然求導的時候也是0
eta=0.001
#注意3:不能使用StandardScaler標準化資料,因為我們要使方差最大,而不是為1
gradient_ascent(df_debug,X_demean,initial_w,eta) #除錯求出的梯度
gradient_ascent(df_math,X_demean,initial_w,eta)#推導的公式求梯度
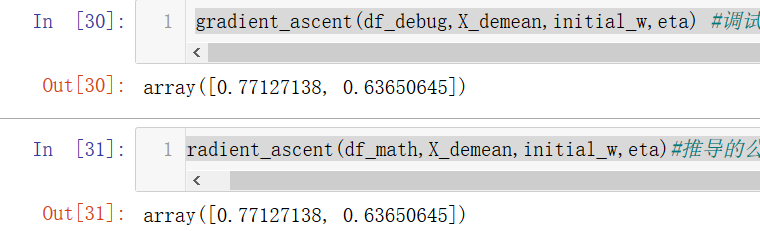
發現一模一樣,說明求導公式是正確的,
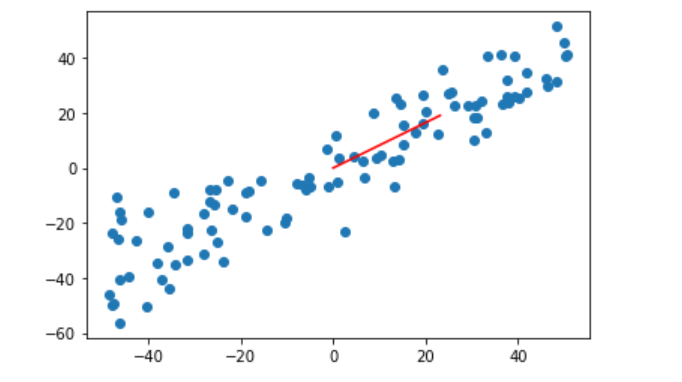
w=gradient_ascent(df_math,X_demean,initial_w,eta)#推導的公式求梯度
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.plot([0,w[0]*30],[0,w[1]*30],color="r")
#第一個引數是橫坐標陣列,第二個引數是縱坐標陣列,因為w是單位向量,太小了,所以*30變大一點
plt.show()
測驗一下不加噪音是否正確:
X2=np.empty((100,2)) #100行2列
X2[:,0]=np.random.uniform(0.,100.,size=100) #100個0~100的均勻分布點
X2[:,1]=0.75*X2[:,0]+3.#不加噪音
plt.scatter(X2[:,0],X2[:,1])
plt.show()
X2_demean=demean(X2)
gradient_ascent(df_math,X2_demean,initial_w,eta)
w2=gradient_ascent(df_math,X2_demean,initial_w,eta)
plt.scatter(X2_demean[:,0],X2_demean[:,1])
plt.plot([0,w2[0]*30],[0,w2[1]*30],color="r")
plt.show()
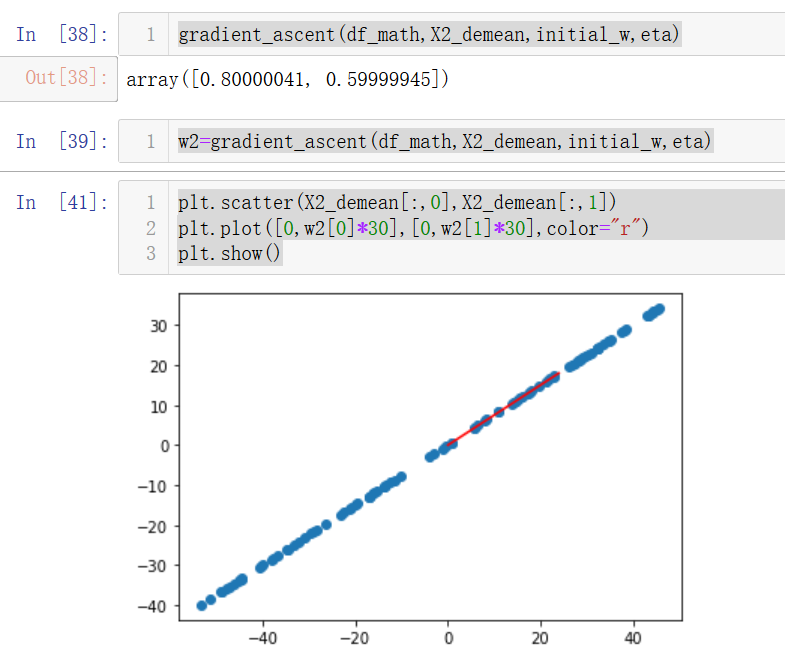
因為我們設定的斜率是0.75,而這里求出的w=[0.8,0.6],對邊/斜邊=0.75,說明梯度上升是正確的,
求資料的前n個主成分
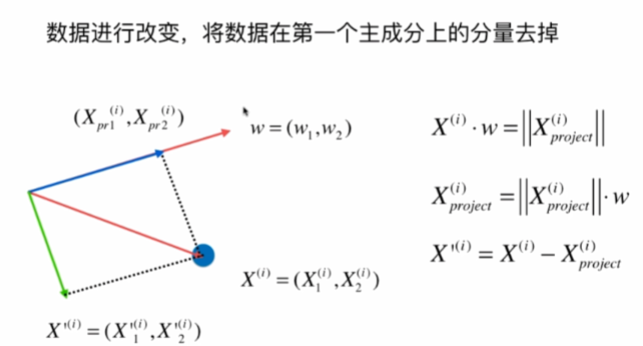
求出第一個主成分以后,如何求出下一個主成分?
資料進行改變,將資料在第一個主成分上的分量去掉,再在新的資料求第一主成分,
numpy中一維陣列的運算的一些奇妙的地方:
https://blog.csdn.net/xo3ylAF9kGs/article/details/78623276
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100個0~100的均勻分布點
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100個均值為0,標準差為10的正態分布點
def demean(X):
return X-np.mean(X,axis=0)#對X的每一列的每個數減去這一列的均值,即可讓X的每一列均值變為0
X=demean(X)
def f(w,X):
return np.sum((X.dot(w)**2))/len(X)
def df(w,X):
return X.T.dot(X.dot(w))*2./len(X)
def direction(w):#化成單位向量
return w/np.linalg.norm(w) #除以w的模即可
def first_component(X,initial_w,eta,n_iters=1e4,epsilon=1e-8):
#梯度上升法
w=direction(initial_w)
cur_iter=0
while cur_iter < n_iters:
gradient = df(w,X)
last_w=w
w=w+eta*gradient #變成加法
w=direction(w) #注意1:化成單位向量
if(abs(f(w,X)-f(last_w,X))<epsilon):
break
cur_iter+=1
return w
initial_w=np.random.random(X.shape[1])
eta=0.01
w=first_component(X,initial_w,eta)
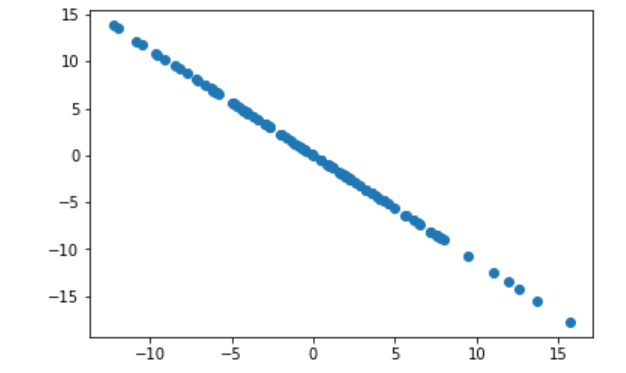
X2=X-X.dot(w).reshape(-1,1)*w #點積后變成m行1列再和w陣列(n個元素)每個元素對應相乘,形成m行n列的矩陣
plt.scatter(X2[:,0],X2[:,1])
plt.show()
對第二維主成分分析的結果:
w2=first_component(X2,initial_w,eta)
w2
w.dot(w2)
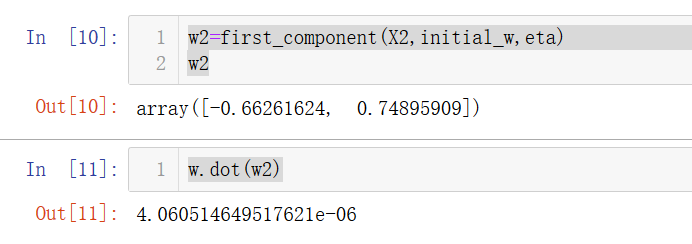
點積之后幾乎為0,說明是正確的,因為兩個方向是垂直的,
求前n個主成分:
def first_n_components(n,X,eta=0.01,n_iters=1e4,epsilon=1e-8):
X_pca=X.copy()
X_pca=demean(X_pca)
res=[]
for i in range(n):
initial_w=np.random.random(X_pca.shape[1])
w=first_component(X_pca,initial_w,eta)
res.append(w)
X_pca=X_pca-X_pca.dot(w).reshape(-1,1)*w
return res
first_n_components(2,X)

高維資料向低維資料映射
將n為資料映射到k維
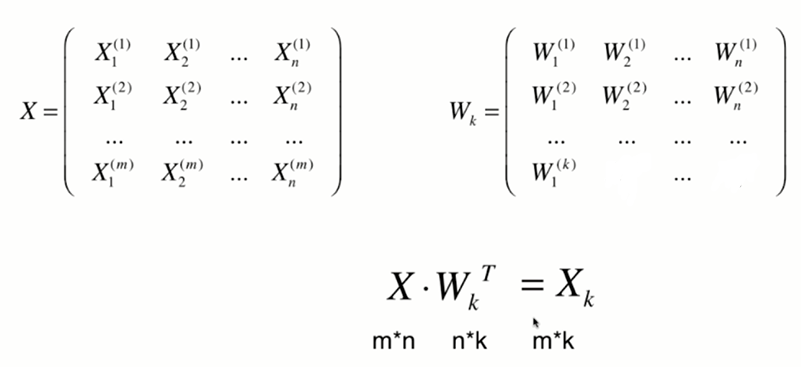
將k維資料恢復到n維:

import numpy as np
class PCA:
def __init__(self, n_components):
"""初始化PCA"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""獲得資料集X的前n個主成分"""
assert self.n_components <= X.shape[1], \
"n_components must not be greater than the feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
self.components_[i,:] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""將給定的X,映射到各個主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""將給定的X,反向映射回原來的特征空間"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100個0~100的均勻分布點
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100個均值為0,標準差為10的正態分布點
%run f:\python3玩轉機器學習\PCA與梯度上升法\PCA.py
pca=PCA(n_components=2)
pca.fit(X)
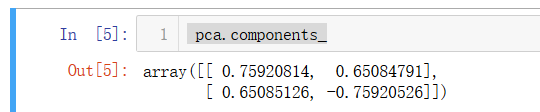
pca=PCA(n_components=1)
pca.fit(X)
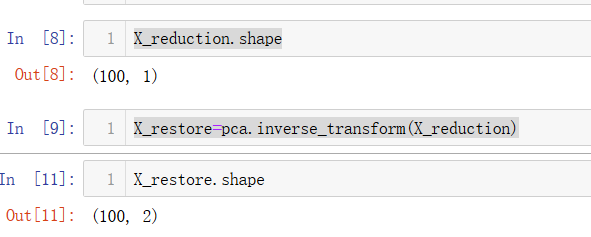
X_reduction=pca.transform(X)
X_restore=pca.inverse_transform(X_reduction)
plt.scatter(X[:,0],X[:,1],color="b",alpha=0.5)
plt.scatter(X_restore[:,0],X_restore[:,1],color='r',alpha=0.5)
plt.show()
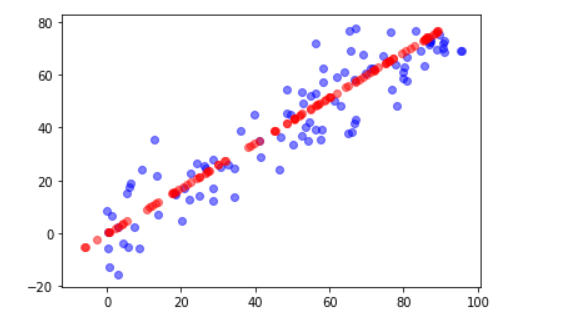
紅色的線是恢復后的資料,可見丟失了一些資訊,
scikit-learn中的PCA
先接著用上面的資料,
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)
pca.components_

咦?怎么跟我們上面求的第一主成分不太一樣,但是斜率是差不多的,這是因為scikit-learn中的PCA是通過數學推導的,不是我們上面用的梯度上升法,
X_reduction=pca.transform(X)
X_restore=pca.inverse_transform(X_reduction)
plt.scatter(X[:,0],X[:,1],color="b",alpha=0.5)
plt.scatter(X_restore[:,0],X_restore[:,1],color="r",alpha=0.5)
plt.show()
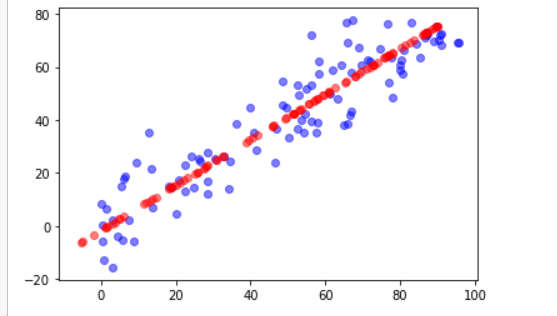
最后繪制出來的圖跟上面的方法是差不多的,
再玩一下手寫字母識別這個資料集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits=datasets.load_digits()
X=digits.data
y=digits.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666)
%%time
from sklearn.neighbors import KNeighborsClassifier
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train,y_train)

knn_clf.score(X_test,y_test)

直接降到二維試試(斜眼笑):
from sklearn.decomposition import PCA
pca=PCA(n_components=2) #從64維降到2維
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
%%time
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)

哇!居然只用了1ms,
knn_clf.score(X_test_reduction,y_test)
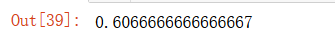
但這正確率也太低了吧,,,雖然運行速度提高了,但精度低了,
pca.explained_variance_ratio_ #這兩維顯示所占的方差比,大概只有28%,所以精度很低

先直接算一下64維各維方差占比的情況:
pca=PCA(n_components=X_train.shape[1])
pca.fit(X_train)
pca.explained_variance_ratio_ #從大到小排序的
plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
plt.show()
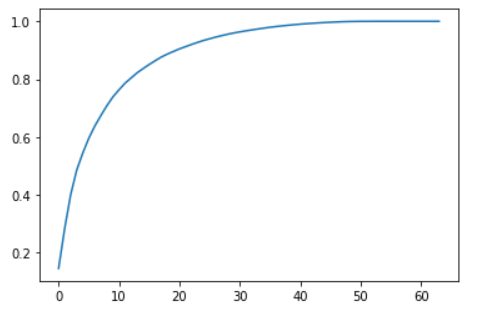
橫軸為維度,縱軸為我們需要的方差占比,
如果我們想要方差占比0.95:
pca=PCA(0.95)
pca.fit(X_train)
pca.n_components_
輸出28,所以我們要用PCA降到28維:
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
%%time
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)

好快啊!
knn_clf.score(X_test_reduction,y_test)

正確率也好高啊!!!
看來28維足以兼并精度和時間~
我們再看看PCA降到二維可視化:
pca=PCA(n_components=2)
pca.fit(X)
X_reduction=pca.transform(X)
for i in range(10):
plt.scatter(X_reduction[y==i,0],X_reduction[y==i,1],alpha=0.8)#每次回圈自動換顏色
plt.show()
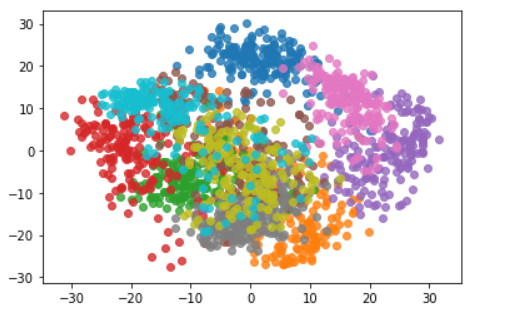
可以發現不同的類別降到二維后還是可以區分的,比如我們需要區分粉色和紫色,那么降到二維就足夠應對了,
MNIST資料集
下載MNIST資料集可能會出現超時狀況,解決辦法:https://blog.csdn.net/qq_41312839/article/details/86671939
import numpy as np
from sklearn.datasets import fetch_mldata
mnist=fetch_mldata("MNIST original")
X,y=mnist['data'],mnist['target']
X_train=np.array(X[:60000],dtype=float)#mnist資料集前60000個是訓練資料
y_train=np.array(y[:60000],dtype=float)
X_test=np.array(X[60000:],dtype=float)
y_test=np.array(y[60000:],dtype=float)
from sklearn.neighbors import KNeighborsClassifier
knn_clf=KNeighborsClassifier() #scikit-learn中的KNN對于資料大時會使用KD-tree或BALL-tree來加速
%time knn_clf.fit(X_train,y_train)
%time knn_clf.score(X_test,y_test)
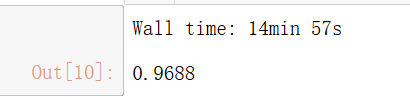
預測時間是真的太長了,,我們再看看PCA降維的結果吧:
from sklearn.decomposition import PCA
pca=PCA(0.9)#保留90%的資訊
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
knn_clf=KNeighborsClassifier()
%time knn_clf.fit(X_train_reduction,y_train)
X_test_reduction=pca.transform(X_test)
%time knn_clf.score(X_test_reduction,y_test)
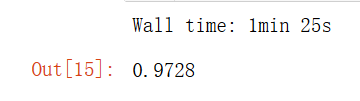
可以發現,降維后時間提高了很多,準確率居然也上升了,這是因為PCA具有降噪的功能,
PCA還可以應用于手寫識別、人臉識別領域,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73693.html
標籤:其他