最近都在搞這東西, 雖然市面上很多 Json2CSharp / Xml2CSharp 的東西, 不過幾乎都不對, 在生成 CSharp 型別的時候歸并得不好, 他們的邏輯大致就是根據節點名稱來生成型別, 然后如果名稱相同的話, 就歸并到一起, 可是很多時候同名節點下有同名的物件, 在它們型別不同的時候, 就完蛋了, 直接看看下面一個例子, 從 XML 結構生成 C# 代碼的 :
XML :
<?xml version="1.0" encoding="UTF-8"?> <info> <entry <!-- 測驗List --> path="E:\ModulesProjects_CheckOut\ArtistFiles\Assets" revision="553" kind="dir"> <entry name="HH"> <!-- 測驗重復型別 --> <user>ME</user> <url name="SB"></url> <!-- 測驗重復變數 --> </entry> <url>https://desktop-82s9bq9/svn/UnityProjects/ArtistFiles/Assets</url> </entry> <entry <!-- 測驗List --> revision="6" kind="dir" path="E:\ModulesProjects_CheckOut\ArtistFiles\Assets\DataConverterModules\Editor"> <entry name="HH"> <!-- 測驗重復型別 --> <user>ME</user> <url name="SB"></url> <!-- 測驗重復變數 --> </entry> <url>https://desktop-82s9bq9/svn/DataConverterModules/Assets/DataConverterModules/Editor</url> </entry> </info>
可以看到這里故意使用同名節點 <entry>/<url> 并且 <url> 節點都在 <entry> 節點下面, 并且型別不同 :
<entry path="E:\ModulesProjects_CheckOut\ArtistFiles\Assets" revision="553" kind="dir"> <entry name="HH"> <user>ME</user> <url name="SB"></url> <!-- 帶Attribute --> </entry> <url>https://desktop-82s9bq9/svn/UnityProjects/ArtistFiles/Assets</url> <!-- 普通Element --> </entry>
然后找個 Xml2CSharp 在線轉換的轉換一下(需要去掉注釋), 得到下面的代碼 (https://xmltocsharp.azurewebsites.net/) :
using System; using System.Xml.Serialization; using System.Collections.Generic; namespace Xml2CSharp { [XmlRoot(ElementName="url")] public class Url { [XmlAttribute(AttributeName="name")] public string Name { get; set; } } [XmlRoot(ElementName="entry")] public class Entry { [XmlElement(ElementName="user")] public string User { get; set; } [XmlElement(ElementName="url")] public Url Url { get; set; } // 節點下的 string 型別 url 被 URL 型別覆寫了 [XmlAttribute(AttributeName="name")] public string Name { get; set; } [XmlElement(ElementName="entry")] public Entry Entry { get; set; } [XmlAttribute(AttributeName="revision")] public string Revision { get; set; } [XmlAttribute(AttributeName="kind")] public string Kind { get; set; } [XmlAttribute(AttributeName="path")] public string Path { get; set; } } [XmlRoot(ElementName="info")] public class Info { [XmlElement(ElementName="entry")] public List<Entry> Entry { get; set; } } }
這就不對了, 即使反序列化可以運行, 可是我少了一個網址的 url 節點啊, 可以看出它的邏輯就是同名型別歸并, 看到 Entry 型別里面還包含了 Entry, 就跟 XML 節點一樣, 前面也說了, 這樣歸并下來的話, 同樣是 Url 節點, 它就沖突了, 會變成 :
public string Url {get;set;} public Url Url {get;set;}
這樣肯定不行, 上面就是后寫入的 Url 型別變數覆寫了 string 型別變數, 并且還有隱患的是節點型別 [XmlElement] 和 [XmlAttribute] 也是可能沖突的, 所以上面的簡單轉換并沒有實用價值.
先來看結論, 目前我制作的轉換工具得到的結果 :
XMLToCSharp :
using System; using System.Collections; using System.Collections.Generic; using System.Text; using System.Xml; using System.Xml.Serialization; using System.Xml.Schema; using System.IO; namespace DataConverterModules { [XmlRoot(ElementName="info")] public class info { [XmlRoot(ElementName="entry")] public class Merge_1_entry { [XmlAttribute(AttributeName="path")] public string path; [XmlAttribute(AttributeName="revision")] public string revision; [XmlAttribute(AttributeName="kind")] public string kind; [XmlElement(ElementName="entry")] public Merge_2_entry entry; // 歸并唯一性的結果, 不同的型別被分離了 [XmlElement(ElementName="url")] public string url; // 正確保留了變數 } [XmlRoot(ElementName="entry")] public class Merge_2_entry { [XmlAttribute(AttributeName="name")] public string name; [XmlElement(ElementName="user")] public string user; [XmlElement(ElementName="url")] public Merge_3_url url; } [XmlRoot(ElementName="url")] public class Merge_3_url { [XmlAttribute(AttributeName="name")] public string name; } [XmlElement(ElementName="entry")] public List<Merge_1_entry> entry; // 型別名稱跟節點名稱不同, 這是歸并唯一性的結果 } }
對于節點沖突通過另一種歸并型別的方式實作, 所有類物件節點都得到了一個唯一命名, 然后再進行歸并, 雖然這里看不出來不過保留了正確的變數...
當然這是個中期結果, 只達到了正確性的要求, 其它問題比如自動命名物件的非穩定性, 像 Merge_1_entry 這樣的歸并型別, 它剛好這次生成給它的 ID 是 1, 下次如果是 2 的話就會變成 Merge_2_entry, 名稱會變, 如果大量被參考的話, 就是個慘案... 還有就是一個節點同時有 Attribute 和子節點重名的時候, 仍然有覆寫問題, 不過這是資料設計問題, 本來這些資料結構就是松散的, 強物件語言的強型別是沒有辦法表現出來的, 不用糾結.
其實邏輯就是 :
1. 所有的 XmlElement 節點都可以分為兩種 :
一是純粹節點, 下面沒有任何 Attribute 和其它節點, 那它就可以作為一個變數使用, 就像上面的 <user> 節點 :
<entry name="HH"> <user>ME</user> <url name="SB"></url> </entry>
生成的代碼 :
[XmlElement(ElementName="user")] public string user;
二是有子節點或 Attribute 的情況, 它就可以作為一個類物件使用, 就像 <url name="SB"> 節點 :
<url name="SB"></url>
生成的代碼 :
[XmlRoot(ElementName="url")] public class Merge_3_url { [XmlAttribute(AttributeName="name")] public string name; }
一般都是這樣界定 XmlElement 型別的.
2. 在同級節點中有并列節點的情況的, 可以視為該級節點存在陣列的情況, 將之合并為陣列或 List 物件, 就像上面的 <info> 下的 <entry> 節點那樣 :
<info> <entry ...> ... </entry> <entry ...> ... </entry> </info>
生成的代碼 :
[XmlRoot(ElementName="info")] public class info { [XmlElement(ElementName="entry")] public List<Merge_1_entry> entry; // List }
在正常資料結構的情況下, 應該是對的.
3. 每個 Attribute 或簡單 XmlElement 中的變數, 直接使用 string 型別即可, 不過我這里有自己實作的多變數方案 DataTable, 通過實作介面 IXmlSerializable 可以對 XmlElement 變數進行型別轉換, 可是在 Attribute 型別轉換上失敗了, 原因不明, 參考如下 :
// DataTable 代替基礎型別 bool / int / string... 等 public struct DataTable : IEqualityComparer<DataTable>, IXmlSerializable { ...略 // 實作IXmlSerializable介面, 能正確序列化和反序列化 public XmlSchema GetSchema() { return null; } public void ReadXml(XmlReader reader) { reader.MoveToContent(); var isEmptyElement = reader.IsEmptyElement; reader.ReadStartElement(); if(false == isEmptyElement) { _userData = reader.ReadString(); dataType = DataType.String; // 無關代碼 reader.ReadEndElement(); } } public void WriteXml(XmlWriter writer) { writer.WriteString(this.ToString()); } } // xml 反序列化物件 ...略 [XmlElement(ElementName="user")] public DataTable user; // Element 物件正確 [XmlAttribute(AttributeName="name")] public DataTable name; // Attribute 物件不正確 [XmlAttribute(AttributeName="name")] public string name; // 必須使用 string // 使用 XmlSerializer 反序列化 public static T ToObject<T>(string xml) { T retVla = default(T); var serializer = new XmlSerializer(typeof(T)); using(var stream = new StringReader(xml)) { using(var reader = System.Xml.XmlReader.Create(stream)) { try { var obj = serializer.Deserialize(reader); retVla = (T)obj; } catch(System.Exception ex) { Debug.LogError(ex.Message); } } } return retVla; }
本著萬物皆可 string 的原則, 通用資料物件對于資料合并非常有用.
(2020.08.27)
對于名稱沖突的 Attribute 和 Element 節點, 也通過修改變數名稱的方式來進行支持, 如下 :
<?xml version="1.0" encoding="UTF-8"?> <info> <entry path="E:\ModulesProjects_CheckOut\ArtistFiles\Assets"> <path>ElementPath1</path> <path>ElementPath2</path> </entry> </info>
<entry> 節點有 path 的屬性, 以及<path> 的節點, 生成的代碼 :
using System; using System.Collections; using System.Collections.Generic; using System.Text; using System.Xml; using System.Xml.Serialization; using System.Xml.Schema; using System.IO; namespace DataConverterModules { [XmlRoot(ElementName="info")] public class info { [XmlRoot(ElementName="entry")] public class info_entry { [XmlAttribute(AttributeName="path")] public string path_attribute; [XmlElement(ElementName="path")] public List<DataTable> path_element; } [XmlElement(ElementName="entry")] public info_entry entry; } }
還好正常情況下 Attribute 都是名稱唯一的, 這樣雖然名稱變了, 不過也比較直觀. XML 的轉換邏輯基本就完成了...
然后是 Json 的, 要比 XML 復雜一些, 因為 XML 本身序列化的可擴展性不高 ( 指的是系統自帶的反序列化器 ), 從下面的例子就能看出來 :
// xml <info> <entry1>Value1</entry1> <entry2>Value1</entry2> </info> // json { "entry1" : "Value1", "entry2" : "Value2" }
上面兩種資料, 如果看成同樣的資料結構的話, XML 只能生成一種 C# 結構 :
[XmlRoot(ElementName="info")] public class info { [XmlElement(ElementName="entry1")] public string entry1; [XmlElement(ElementName="entry2")] public string entry2; }
而 Json 可以生成兩種結構 :
// json 第一種 public class CSharpClass { public string entry1; public string entry2; } // json 第二種 public class CSharpClass : Dictionary<string, string> { }
可以看出泛用性的差別, 根據不同需求的擴展性的差別. Xml 序列化天生不支持 Dictionary 型別, 并且 [XmlAttribute] 屬性反序列化為 DataTable 會拋出例外, 感覺限制太大...
再來看看 Json 序列化, Json 比較符合強型別的邏輯, 它有哈希表和串列的區別, 像下面這樣會導致報錯 :
{ "key" : "Value1", "key" : "Value2" }
隨便找個在線 Json2CSharp 網站進行代碼轉換 ( https://json2csharp.com/ ) , 可以看到它剛好是跟 XML 相反, 是完全不進行型別歸并, 得到很多冗余的型別, 在結果上是正確的, 因為它把型別全都唯一了, 看看例子 :
{ "Normal": { "size": { "x": 1021, "y": 988 }, "url": "xxxx" }, "Test": { "size": { "x": 222, "y": 988 }, "url": "xxxx" } }
在線轉換給出的代碼 :
public class Size { public int x { get; set; } public int y { get; set; } } public class Normal { public Size size { get; set; } public string url { get; set; } } public class Size2 { public int x { get; set; } public int y { get; set; } } public class Test { public Size2 size { get; set; } public string url { get; set; } } public class Root { public Normal Normal { get; set; } public Test Test { get; set; } }
其實 Normal / Test 是相同的資料結構, Size / Size2 也是相同的資料結構, 都是可以歸并的, 下面是我生成的結構 :
public class CSharpClass { public class Merge_1_Normal { public Merge_2_size size; public string url; } public class Merge_2_size { public string x; public string y; } public Merge_1_Normal Normal; public Merge_1_Normal Test; }
然后像上面一樣, 對于某些資料我們可以將它簡化為 Dictionary 物件, 比如這樣 :
public class CSharpClass : Dictionary<string, CSharpClass.Merge_1_Normal> { public class Merge_1_Normal { public Merge_2_size size; public string url; } public class Merge_2_size { public string x; public string y; } }
或是這樣 :
public class CSharpClass : Dictionary<string, CSharpClass.Merge_1_Normal> { public class Merge_1_Normal { public Merge_2_size size; public string url; } public class Merge_2_size : Dictionary<string, string> { } }
相同的型別可歸并, 當 Json 是一個資料模板的時候, 可以將物件生成可擴展的 Dictionary 形式, 比較靈活, 并且 LitJson 提供了所有需要的序列化擴展, 像 DataTable 這些也直接通過注入自定義型別來完成序列化和反序列化.
基本上就是這樣了, 從上面程序也可以看到生成的代碼有些是全部放在同一級的, 有些是放在某個類中的 Nested 的, 因為多個資料結構可能有重疊名稱的物件生成, 所以我這里都是生成 Nested 這種形式的, 所以只要保證最外層型別的參考能夠正確即可 :
public class CSharpClass : Dictionary<string, CSharpClass.Merge_1_Normal>
最外層只有一個可能, 就是繼承 Dictionary 的時候繼承的型別, 雖然看起來有點怪...
PS : 比較有意思的是大部分 C# 編譯器都能支持中文 類名 / 變數名 / 函式名 這些, 你可以寫一大堆中文進去沒有問題, 不過在線轉換出來的代碼還是被坑在了非法字符上 :
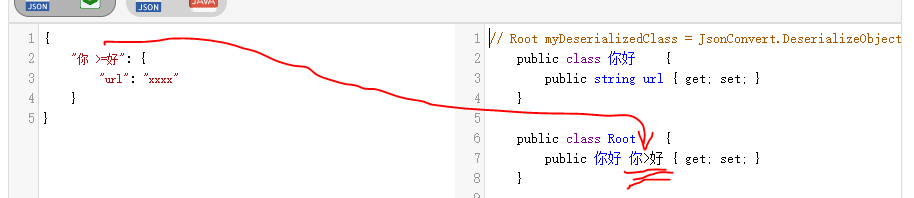
大于號沒有被洗掉, 我這里搞了個比較好玩的, 中文轉拼音, 之后再洗掉非法字符即可 :
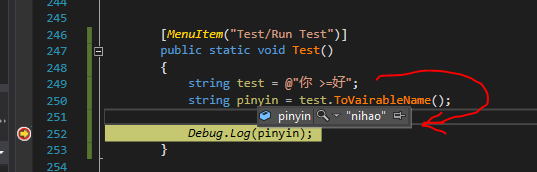
畢竟中文還涉及編碼這些問題, 還是盡量規避的好一些...
(2020.08.28)
繼續對 XML 轉換施工, 之前的 [XmlAttribute] 屬性無法進行型別轉換直接反序列化成 DataTable, 找來找去也沒有什么借口或是擴展方法來提供自定義轉換, 那么就修改一下生成代碼邏輯, 使用 get & set 邏輯來完成想要的功能吧.
還是從之前的轉換類來看 :
<info> <entry path="E:\ModulesProjects_CheckOut\ArtistFiles\Assets"> </entry> </info>
轉換的代碼 :
[XmlRoot(ElementName="info")] public class info { [XmlRoot(ElementName="entry")] public class info_entry { [XmlAttribute(AttributeName="path")] public string path; } [XmlElement(ElementName="entry")] public info_entry entry; }
而我希望它是 DataTable 型別的話, 因為 DataTable 已經實作了各種型別的隱式轉換, 所以修改原有的 path 變數作為 DataTable 的入口, 而舊的變數作為反序列化的入口修改變數名稱即可, 修改后的生成代碼如下 :
[XmlRoot(ElementName="info")] public class info { [XmlRoot(ElementName="entry")] public class info_entry { [XmlAttribute(AttributeName="path")] // 原有反序列化入口不變, 只改變成員 public string _path{ get{ return path.ToString(); } set{ path = value; } } // get & set [XmlIgnore] // 新添加變數屬性, 在序列化時不會出錯 public DataTable path; // 使用變數名稱作為用戶介面 } [XmlElement(ElementName="entry")] public info_entry entry; }
這樣既保證了用戶介面, 也保證了 XML 序列化介面, 測驗一下 :
[MenuItem("Test/Run Test")] public static void Test() { string path = @"C:\Users\CASC\Desktop\Temp\xml Test.xml"; var obj = XmlConverter.ToObject<info>(System.IO.File.ReadAllText(path)); Debug.Log((string)obj.entry.path); var toXml = XmlConverter.ToXml(obj); Debug.Log(toXml); var toObj = XmlConverter.ToObject<info>(toXml); Debug.Log((string)toObj.entry.path); }
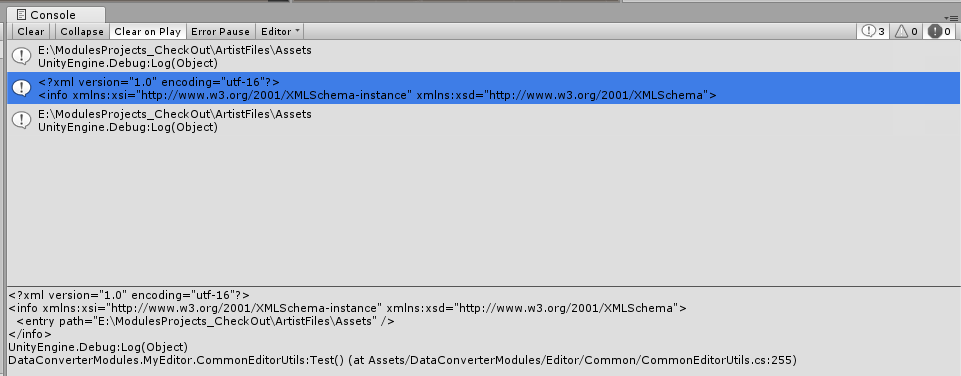
正確, 不管序列化還是反序列化, 都正常, 沒有影響到其它使用者的邏輯. 相當完美...
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/75741.html
標籤:其他