作者|OngKoonHan
編譯|Flin
來源|towardsdatascience
在我大學的Android開發課程的組專案部分中,我們的團隊構建并部署了一個認證系統,通過說話人的語音組態檔進行認證,
在我上一篇文章(請參閱下一部分)描述了語音認證系統的高級體系結構之后,本文將深入探討所使用的深度學習模型的開發程序,
我以前的文章可以在這里找到(一個帶有移動部署的初級語音認證系統),
- https://medium.com/@ongkoonhan.lovefad/a-rudimentary-voice-authentication-system-with-mobile-deployment-1d41f5baa319

在這篇簡短的文章中,我將描述開發語音認證模型所涉及的不同階段,并討論在學習程序中遇到的一些問題,
這是文章的概述:
-
問題陳述
-
高級模型設計
-
資料預處理
-
對比學習語音編碼器
-
身份驗證的二進制分類器
-
模型表現
問題陳述
在開始之前,我們需要弄清楚我們是如何試圖構建語音認證問題的,
語音認證主要有兩種方式(廣義地說):說話人識別和說話人驗證,這兩種方法雖然密切相關,但在比較兩種系統的相關安全風險時,它們將導致兩個系統具有截然不同的特性,
問題定義:
說話人識別:n分類任務:給定一個輸入語音,從n個已知說話人(類)中找出正確的說話人,
說話人驗證:二元分類任務:給定一個宣告身份的說話者的輸入話語,確定該宣告身份是否正確,
我們可以看到,在說話人識別中,我們假設給定的輸入話語屬于我們已經認識的說話人(也許是辦公環境),我們試圖從n個已知的說話人(類)中選出最匹配的,
相反,在說話人驗證中,我們假設我們不知道給定輸入話語屬于誰(事實上我們不需要知道),我們關心的是給定的一對輸入話語是否來自同一個人,
準確地說,從整個說話人驗證系統的角度來看,系統“知道”說話人聲稱自己是“已知”的人,而從模型的角度來看,模型只接收一對語音樣本并判斷它們是否來自同一個人,
想象一下使用一個常規的用戶名和密碼認證系統,系統知道你聲稱是誰(用戶名),并檢索參考密碼的存盤副本,然而,密碼檢查器只檢查參考密碼是否與輸入密碼匹配,并將驗證結果回傳給驗證系統,
在此專案中,語音身份驗證問題被構造為說話者驗證問題,
旁白:
在這一點上,值得注意的是,還有另一種型別的語音分析問題,稱為說話人分類(Speaker Diarisation),它試圖分離出多人同時講話的源信號,
說話人分類涉及多人同時講話的場景(想象一下在兩張滿是人的桌子之間放一個麥克風),我們試圖分離出每一個獨特的說話人的語音音頻波形,這可能需要多個麥克風從不同的角度捕捉同一場景,或者只需要一個麥克風(最困難的問題),
我們可以看到這會變得非常復雜,一個例子是識別在給定對話的錄音中誰在講話,在試圖給說話人起名字(說話人識別)之前,必須先分離對話中每個人的語音信號(說話人分類),當然,存在混合方法,這是一個活躍的研究領域,
高級模型設計
轉換資料以進行遷移學習—對于這個任務,我希望盡可能地利用遷移學習,以避免自己構建一個復雜而高效的模型,
為了實作這一目標,語音音頻信號被轉換成類似某種影像的聲譜圖,將音頻轉換為聲譜圖后,我便可以使用PyTorch中可用的任何流行影像模型,例如MobileNetV2,DenseNet等,
其中一個演講者的聲譜圖
事后,我意識到我可以使用基于小波變換(WT)的方法來代替基于傅立葉變換變換(FT)的Melspectrogram來獲得“更清晰”的光譜圖影像,
Youtube視頻中的一個演示(https://youtu.be/g8MfWGibjT8) 比較了心臟心電信號的小波變換和傅立葉變換在“影像質量”上的差異,結果表明,小波變換得到的聲譜圖在視覺上比傅立葉變換更“清晰”,
對比學習的杠桿作用:大家都熟悉的對比學習的經典例子是使用三重態損失的設定,此設定每次編碼3個樣本:參考樣本、正樣本和負樣本(2個候選樣本),目標是減小參考樣本和正樣本之間編碼向量的距離,同時增加參考樣本和負樣本之間編碼向量的距離,
在我的方法中,我不想將候選樣本的數量限制在2個,相反,我使用了一種類似于SimCLR(Chen等人,2020)的方法,即使用多個候選樣本,其中一個樣本是正樣本,然后“對比分類器”被迫從一堆候選樣本中選出正樣本,
兩階段遷移學習法:為了解決說話人驗證問題,我們將分兩個階段訓練模型,
首先,通過對比學習對說話人語音編碼器進行訓練,如前所述,對比學習將涉及多個候選樣本,而不是通常的三重態損失設定的正負對,
其次,在預先訓練好的語音編碼器上訓練二元分類器,這將允許語音編碼器在用于此傳輸學習任務(二進制分類器)之前單獨進行訓練,
資料預處理
VoxCeleb1資料集:為了訓練模型識別說話人的語音組態檔(無論他/她說了什么),我選擇使用VoxCeleb1公共資料集,
VoxCeleb1資料集包含多個揚聲器在野外的音頻片段,也就是說,這些揚聲器在“自然”或“常規”設定下講話,對資料集中的演講者進行訪談,并對資料集中的音頻片段進行管理,使每個片段都包含演講者正在談話的訪談片段,
這個資料集包含了每個說話人在不同的訪談設定下的多個訪談,并且使用了不同型別的設備,這給了我希望語音認證系統配合使用的可變性,
對于這個專案,只使用音頻資料(視頻資料可用),還有其他的認證系統試圖合并多種資料模式(比如視頻和音頻結合起來,以檢測語音是否在現場生成),但我認為這超出了我的專案范圍,
音頻波形到聲譜圖:為了能夠利用流行的影像模型架構,語音音頻信號被轉換成類似某種影像的聲譜圖,
首先,將來自同一揚聲器的多個短音頻樣本組合成一個長音頻樣本,由于mel譜圖是基于短時傅里葉變換(STFT)的,因此可以將整個長音頻樣本一次性轉換成mel譜圖,并從長譜圖中得到更小的譜片,
由于長音頻樣本是由單個唯一說話人的較小音頻樣本組成的,因此從長樣本中提取片段應該會迫使模型專注于從每個單獨說話的人的語音組態檔中找出獨特的特征,
來自一個揚聲器的串聯音頻樣本:

接下來,使用LibROSA(Librosa)庫將長音頻樣本轉換為頻譜圖,以下是使用的關鍵引數:
-
Target sampling rate(目標采樣率): 22050
-
STFT window: 2048
-
STFT hop length: 512
-
Mels: 128
然后將功率譜轉換為對數級的分貝,因為我們是用影像網路分析的,所以我們希望光譜圖中的“images”特征稍微均勻分布,
一個揚聲器的混音譜圖
創建“images”:采樣是通過從長光譜圖中分割較小的光譜圖來完成的,
光譜圖“images”創建為128x128x3陣列,格式為RGB影像,在長譜圖上隨機選取一個起始點,對每個新切片滑動半步(128/2=64),得到三個128×128的譜圖切片,然后用[-1,1]之間的最大絕對值對“images”進行標準化,
最初,我復制同一個光譜片3次,將“灰度”影像轉換為“RGB”影像,然而,我決定將更多的資訊打包到每個光譜圖“images”中,為每個“RGB”影像放入3個稍有不同的切片,因為這3個通道不像普通RGB影像那樣具有通常的含義,使用這種滑動技術后,性能似乎略有改善,
對比學習語音編碼器
資料采樣 —— 以下是用于語音編碼器對比學習的資料采樣的一些詳細資訊,
[**頻譜圖切片將稱為“影像”]
對于每個時期,將200個(總共1,000個)隨機全長頻譜圖加載到記憶體中(“子樣本”)(由于資源限制,并非所有1000個全長頻譜圖都可以一次加載),
每行使用1個參考樣本和5個候選樣本,候選影像包含4個負樣本和一個正樣本(隨機混洗),并且影像是從子樣本中隨機生成的,
每個時期有2,000行,批大小為15(MobileNetV2)和6(DenseNet121),
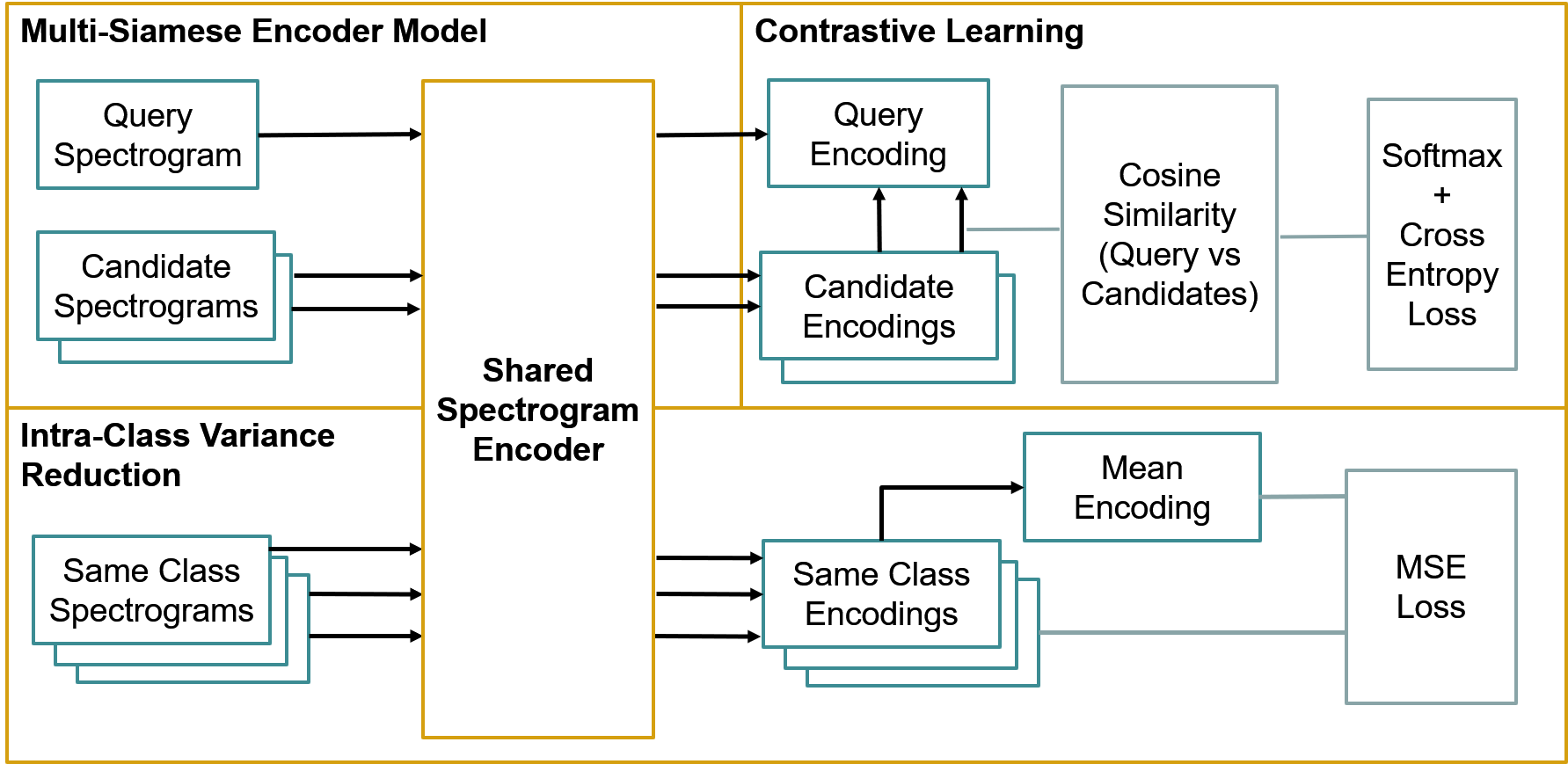
多暹羅編碼器網路 — 對于編碼器網路,使用的基本模型是MobileNetV2和DenseNet121,編碼器層大小為128(取代基本模型中的Imagenet分類器),
為了便于對比學習,建立了一個多連體編碼器模型包裝器作為torch模塊,該包裝器對每個影像使用相同的編碼器,方便了參考影像和候選影像之間的余弦相似性計算,
對比損失+類內方差減少——兩個目標,對比損失和方差減少,連續最小化(由于資源限制,理想情況下,兩個目標的損失應相加并最小化),每1批計算對比損失,每2批進行方差縮減(類內MSE),
對于對比損失,該問題被描述為一個n分類問題,模型試圖從所有候選物件中識別出正樣本,針對參考編碼計算所有候選編碼的余弦相似度,并根據余弦相似度產生的概率計算一個softmax,根據一般的n-分類問題,交叉熵損失最小,
對于類內方差減少,目的是將來自同一類的影像在編碼空間中推近,對來自同一類/同一說話人的影像進行采樣,計算平均編碼矢量,編碼的MSE損失根據平均值(類內方差)計算,并且在反向傳播之前,MSE損失按0.20進行縮放,
身份驗證的二進制分類器
資料采樣 —— 以下是用于說話人驗證二進制分類器的資料采樣的一些詳細資訊,
對于每個時期,將200個(總共1,000個)隨機全長頻譜圖加載到記憶體中(“子樣本”)(由于資源限制,并非可以一次加載所有1,000個全長頻譜圖),
對于每個參考影像,將生成2張測驗影像,其中1張為正影像,1張為負影像,對于每個參考影像,這將產生2對/行,真實對(正)和假冒者對(負),
影像是從子樣本中隨機生成的,每個時期有4,000行,并且批大小為320(MobileNetV2和DenseNet121),
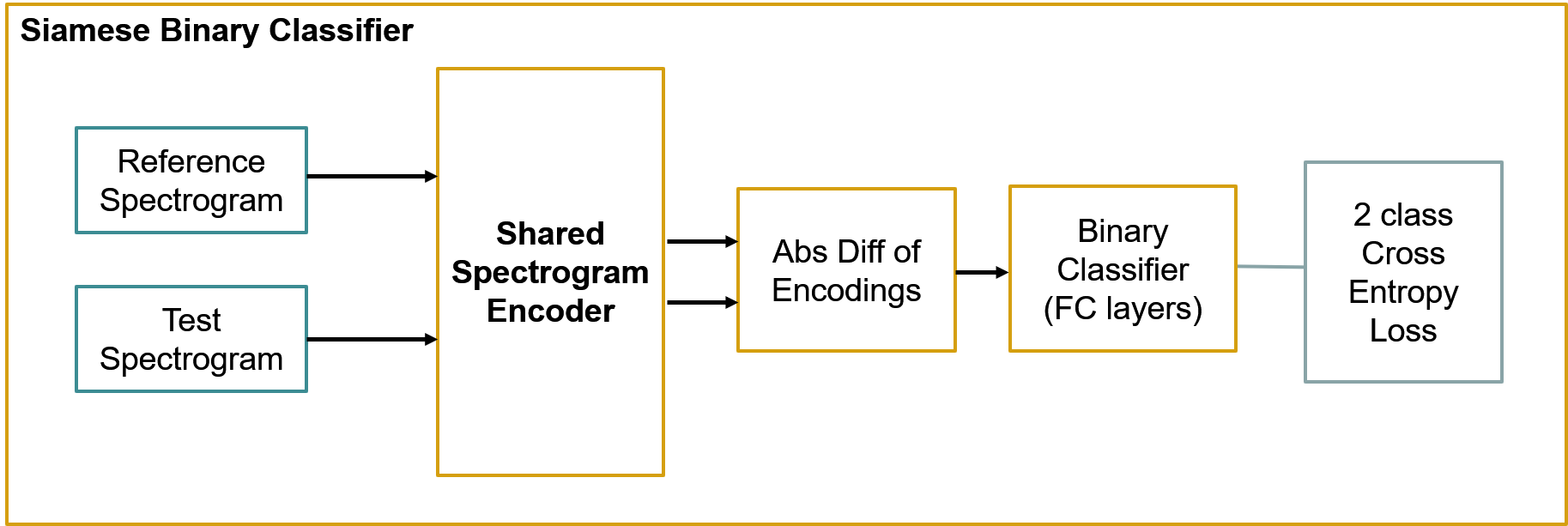
驗證二進制分類器網路 —— 底層編碼器網路是來自對比學習步驟的預訓練編碼器網路,在訓練程序中權重被凍結,
二進制分類器設定為暹羅網路,其中計算了來自輸入對的編碼矢量的絕對差,然后,將二元分類器構建在絕對差異層之上,
模型訓練
學習率回圈:回圈學習率可提高對比學習步驟和二元分類器步驟中的模型準確性,
使用了torch.optim.lr_scheduler.CyclicLR(),其步長(默認)為2000,回圈模式(默認)為“Triangular”,沒有動量回圈(Adam優化器),
學習率的范圍如下:
-
具有對比學習功能的語音編碼器: 0.0001至0.001
-
基本分類器: 0.0001至0.01
模型表現
不出所料,模型性能不如最新模型,我認為,促成因素是:
-
聲譜圖不是我本可以使用的最佳信號轉換,基于小波變換的方法可能會產生更多高質量的聲譜圖“影像”,
-
使用的基本影像模型不是最新的模型,因為我無法在中等大小的GPU(3GB VRAM)上使用超大型模型,也許像ResNet或ResNeXt這樣更強大的模型可能會產生更好的結果,
-
僅使用了一個語音資料集(VoxCeleb1),肯定可以使用大量和各種各樣的資料(但遺憾的是,最后期限迫在眉睫),
以下是可比模型的均等錯誤率(EER):
-
我最好的模型EER 19.74%(VoxCeleb)
-
Le and Odobez (2018), Best model from scratch EER 10.31% (VoxCeleb)
-
Jung, et. al. (2017), EER 7.61% (RSR2015 dataset)
其他調查結果
基本模型大小:使用更大的基本模型提高了分類性能(MobileNetV2 vs DenseNet121),
類內方差減少的效果:類內方差減少提高了兩個基本模型的分類性能,事實上,經過方差縮減的mobilenetw2的性能提高到了與DenseNet121相當的水平,
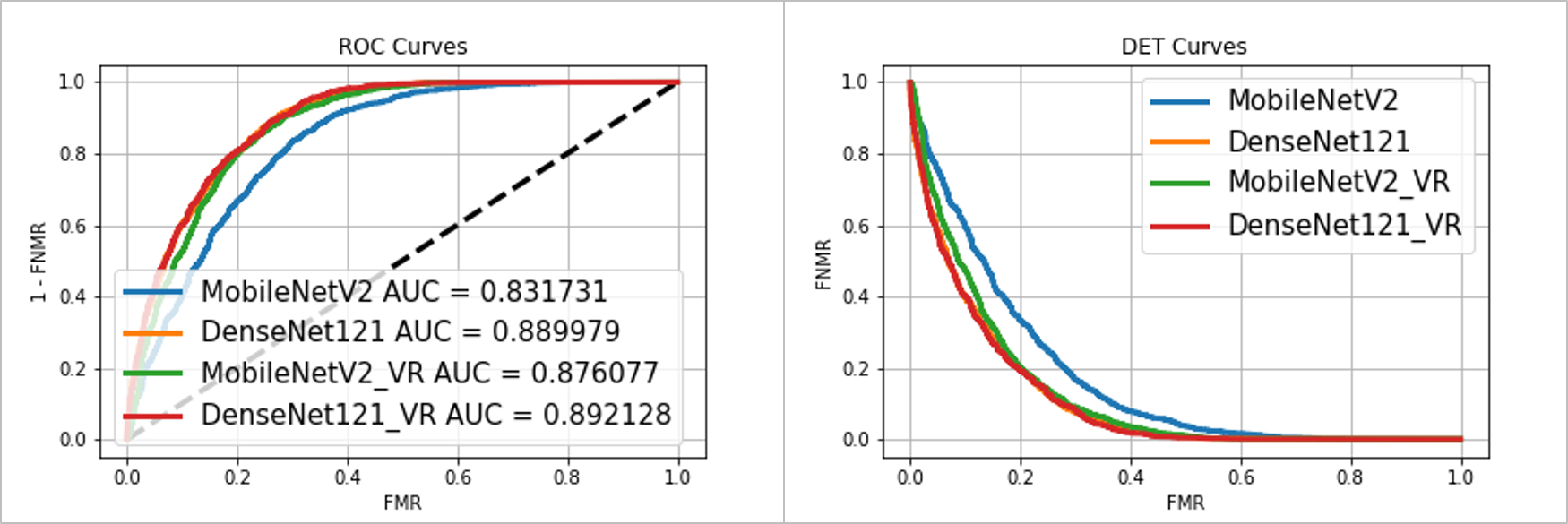
ROC(左)和DET(右)曲線
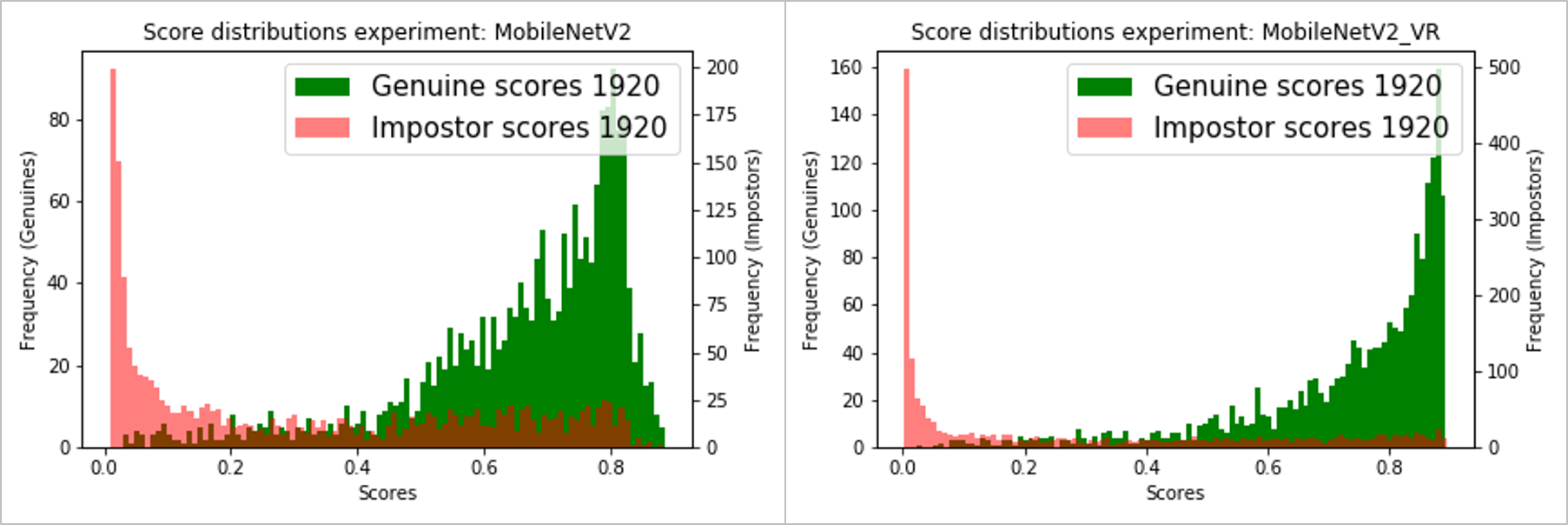
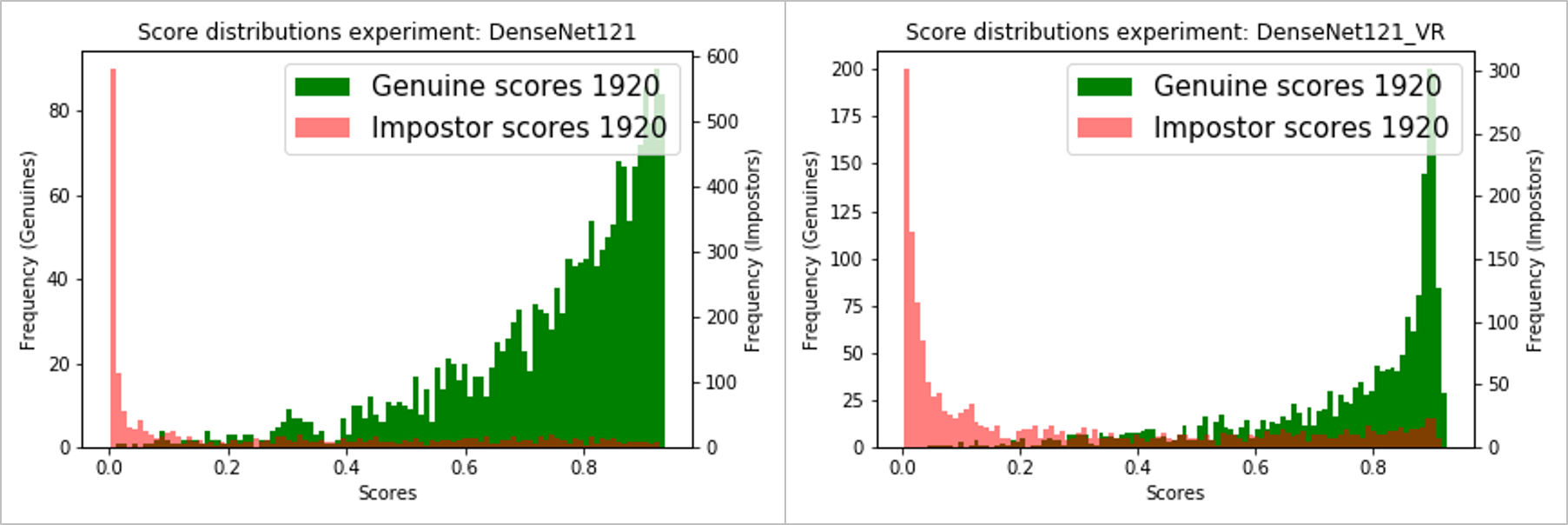
下面是使用MobileNetV2和DenseNet121的二元分類分數分布[P(is_genuine)],包括帶/不帶方差減少,
MobileNetV2基本模型-不帶/帶方差減少(左/右):
DenseNet121基本模型-不帶/帶方差減少(左/右):
參考文獻
Chen, T., Kornblith, S., Norouzi, M. and Hinton, G., 2020. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709
Jung, J., Heo, H., Yang, I., Yoon, S., Shim, H. and Yu, H., 2017, December. D-vector based speaker verification system using Raw Waveform CNN. In 2017 International Seminar on Artificial Intelligence, Networking and Information Technology (ANIT 2017). Atlantis Press.
Le, N. and Odobez, J.M., 2018, September. Robust and Discriminative Speaker Embedding via Intra-Class Distance Variance Regularization. In Interspeech (pp. 2257–2261).
原文鏈接:https://towardsdatascience.com/training-a-rudimentary-speaker-verification-model-with-contrastive-learning-186408a752ce
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/76787.html
標籤:其他
上一篇:Istio 運維實戰系列(2):讓人頭大的『無頭服務』-上
下一篇:通信網技術