SPARK是一個分布式的基于記憶體的大資料執行引擎,最早由加州伯克利大學AMP Lab主導開發,后來加入apache社區范訓,進而成為apache頂級大資料專案。目前spark在開源社區和工業界非常火爆,堪稱大資料最活躍的開源專案。Spark在大資料領域之所以受到如此青睞,主要源于如下幾方面優勢:
資料集抽象: 提供一個分布式彈式資料集(RDD,ResilientDistributed Dataset)抽象,基于RDD的轉換操作被翻譯為RDD間的有向無環圖(DAG),同時RDD的轉換算子(transformation)的延遲性使得調度器可以對DAG進行流水線優化,這使得SPARK不再如MR僅僅支持map-reduce兩步計算,而是多步的DAG任務。另外RDD提供快取機制,可將資料集快取在記憶體進行重復使用,提升計算性能。
高容錯性: RDD抽象記憶了其“血統”資訊,即自身RDD與父輩RDD的依賴關系,故SPARK提供了基于依賴關系重計算丟失資料的容錯機制,同時也提供checkpoint容錯。
多計算范式支持:SPARK對多計算模型的支持,自從SPARK發布以來,SPARK社區逐步開發sparksql,spark streaming, spark mllib、spark graghx等多個模型庫,從而做到一堆疊式支持了,sql查詢(結構化資料分析)、流計算、機器學習、圖計算等多種計算模型。
高易用性:SPARK簡潔的API和多語言支持,給上層用戶提供了良好的開發體驗。
兼容性:SPARK目前越來越壯大的生態系統,以及與hadoop生態系統的完美融合,促使更多的用戶擁抱SPARK。
基于SPARK的如上優勢,SPARK目前被廣泛的應用于機器學習、ETL、商業智能BI、互動式分析等領域。本文主要介紹Spark(SQL)的應用。
從市場分析結果以及專業咨詢公司的報告資料中可以了解到,無論是在企業領域還是電信領域,當前的大資料應用,至少一半以上的應用是SQL分析/統計類。SPARK生態堆疊內的spark sql組件,由于其先天與spark社區高度融合,支持表列式cache,對接多種資料源對接,兼容hive語法/metastore等優勢,無疑是 sql on hadoop的優選方案。
SPARK SQL的社區現狀
Spark sql 是 spark 社區在 1.0 版本引入的,關于 spark sql 和shark, hive on spark的關系可以參見databricks 博客:
https://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html
spark sql架構圖
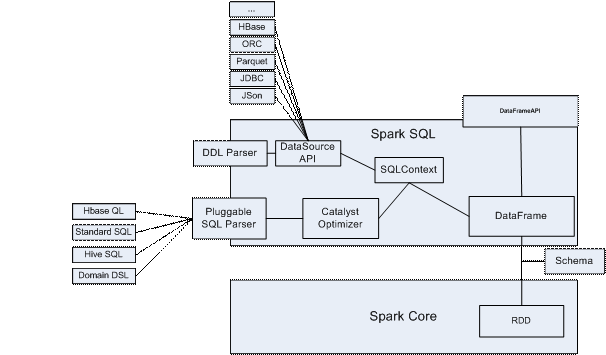
spark sql作為spark社區目前最活躍的組件,已經歷經1.0 -1.4多個版本的迭代,并在1.3 版本從alpha版本畢業,在1.3 后spark sql 提供穩定的API支持,并保證后續版本的前向兼容性。目前社區spark sql版本功能已經相對比較完善,完成的和正在開展的作業主要有:
· 基于函式式的可擴展的sql優化器 catalyst,包括sql決議,分析,優化程序
· 語法方面,支持標準語法并兼容絕大多數hive語法,基本滿足業務使用需求,包括 cube/rollup, window function, 子查詢支持,CTE支持,多join型別支持,動態磁區支持,同時spark sql也包含一些傳統sql支持但hive不支持的語法,比如 non-equal join、join on or condition等。除此之外,spark sql提供插件式的sql parser支持,用戶可以針對自身業務自定義DSL/SQL語法。
· 支持多資料源讀和寫對接支持,目前內置支持的有JDBC, parquet, json,ORC等
· 復雜資料型別的支持,包括array,map,struct等
· Hive 多版本元資料的對接,無需重編譯spark,可做到hive多個版本的元資料切換
· Code generation,提升expression evaluation效率
· 基于堆外記憶體的記憶體管理框架,大大提升spark sql穩定性和性能
· Spark sql定制化序列化器實作,優化spark sql shuffle代價,提升sql性能
· LLVM優化
· DataFrame API,更友好性能更佳的分析型API
總體來看,spark sql已完成功能可用性/易用性相關特性開發,目前主要聚焦于進一步提升spark sql性能和穩定性(https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html)。
SPARK SQL的應用場景
Spark SQL 由于其語法/優化器的可擴展性,以及優良的分析型API的支持,對多種資料源的標準API支持,適用于[Y(1] 如下場景:
· 分析統[Y(2] 計類應用,比如在運營商領域,各種維度計算各類KPI指標;
· 分析和挖掘的綜合場景,或者是客戶當前是查詢類分析但有計劃在未來進行挖掘類的應用分析,這主要受益于spark sql自身強大的分析能力以及和mllib的同堆疊整合能力;
· 聯邦查詢,由于sparksql對多資料源的支持,其足以支持從多個資料源查詢資料進行聯邦查詢分析。
華為在SPARK SQL的增強作業
雖然spark sql具備強大的多資料源整合分析能力,以及性能良好用戶友好的API支持,但是spark sql在如下兩類應用中還是略顯不足:
· 大資料資料倉庫應用,這主要受限于spark sql的語法支持度方面,雖然spark sql已基本完成hive語法的兼容性開發,但其在標準語法方面還有較大不足,如子查詢(包括相關子查詢)的支持度,exist,in的支持,很難做到傳統資料庫應用到hadoop的平滑過渡;
· 云化大資料查詢服務,受限于sparksql的安全、權限方面的不足,目前社區在安全、權限的投入很少,這使得spark sql云化受阻。
除此之外,catalyst優化器在多join等復雜sql下的優化規則較弱,容易導致笛卡爾積生成,造成性能的急劇下降甚至根本無法算出最終結果。
華為大資料團隊在社區sparksql上進行了大量插件式的增強,使得增強后的spark sql 足以應對企業用戶從傳統分析資料庫向hadoop大資料系統過渡遷移以及基于spark sql提供云化查詢分析服務。華為大資料團隊在spark sql做的增強有:
· 對hive ql 語法以及標準語法特性增強,包括exist/in 支持, 相關子查詢支持,filter中復雜子查詢支持,不做任何修改可成功運行TPCDS測驗套。如下為華為大資料團隊增強版spark sql與hive語法(https://github.com/hortonworks/hive-testbench)[Y(3] ,標準sql語法(http://www.tpc.org/tpcds/)的兼容性
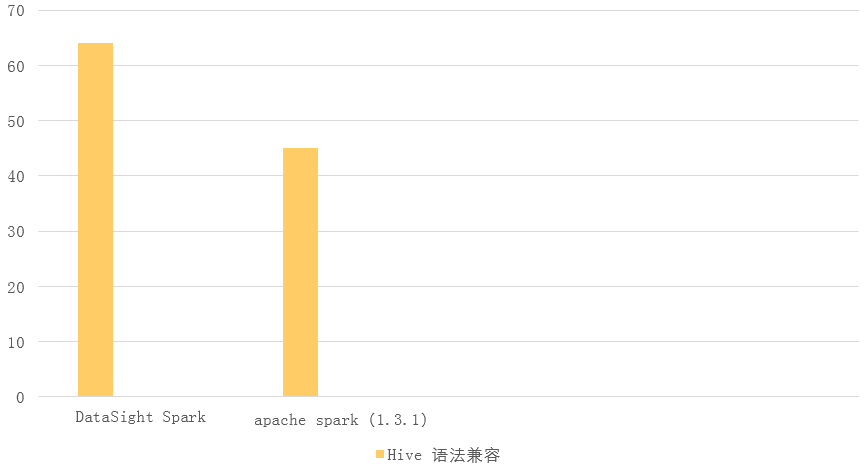

· Sql 并行度支持,并發運行bug修復,支持多session 并發運行sql
· 權限、安全增強,支持角色,可控制用戶的創表,查詢,更新等的權限,同時提供基于列的權限控制
· Catalyst 優化器增強,在社區的優化器的基礎上主要做了如下幾方面增強,
1)joinreordering 和join on or condition優化笛卡爾積,可達到數百倍的性能提升;

2)常數折疊
3)operator reordering減少節點輸入資料和傳輸代價;
4)運算式優化提升運算式求解效率,特別是一些機器生成的sql,用該優化器規則可以顯著提升性能。
5)pre-partial-aggregation,該優化演算法可用于優化聚合函式,同時也可以減少join input size。
6)remove unnecessary exchange 去除沒必要的shuffle程序;
7) [data skipping on fine blocklevel filter feature] 基于work load 的predict 優化;
8)SQL陳述句共享,這對于復雜的sql比較有用,避免重復分析優化的時間代價.
9)動態磁區性能優化,當前社區動態磁區代碼路徑非常耗費記憶體,并且性能不佳,主要原因是每個task需要對每個磁區啟動檔案流寫資料導致系統負載過大。通過資料預先重排可大大減少動態磁區的GC壓力,提升動態磁區性能。
簡而言之,華為的catalyst優化器增強基于客戶真實應用場景,同時針對不同用戶的work load進行資料組織層面的優化建模,從源頭就減少資料讀取量;
· Datasource支持度方面,增加了 orc、hbase,cube等資料源支持
總結
綜上, spark sql的可擴展性使得用戶可以方便的嵌入自己的語法決議器或者添加語法特性,同時允許在業務的理解中不停的添加新的優化規則和資料源。正由于spark sql在架構上的優勢,spark sql在社區熱度不減,擁有數量龐大的貢獻者,值得一提的是華為大資料 spark團隊在社區有10+ 貢獻者,累計貢獻patch 200+,同時我們的發行版本也通過了Databricks官方認證。我們相信隨著后續版本的發布,spark sql在性能和穩定性上都會取得極大的提升,同時華為大資料 spark團隊后續逐步將內部優化特性和語法特性貢獻反饋回社區。
最后,華為大資料 spark團隊期待你的加入,讓我們一起玩轉spark!!!
uj5u.com熱心網友回復:
樓主這是啥?招聘帖?
uj5u.com熱心網友回復:
怎么加入華為大資料spark團隊?
uj5u.com熱心網友回復:
你好,求加入。[email protected]轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/77290.html
標籤:Spark
上一篇:每次執行stop-all.sh都會出現EOFException
下一篇:VCP6.0題庫