本人小白一枚,剛學習爬蟲,遇到下面問題。
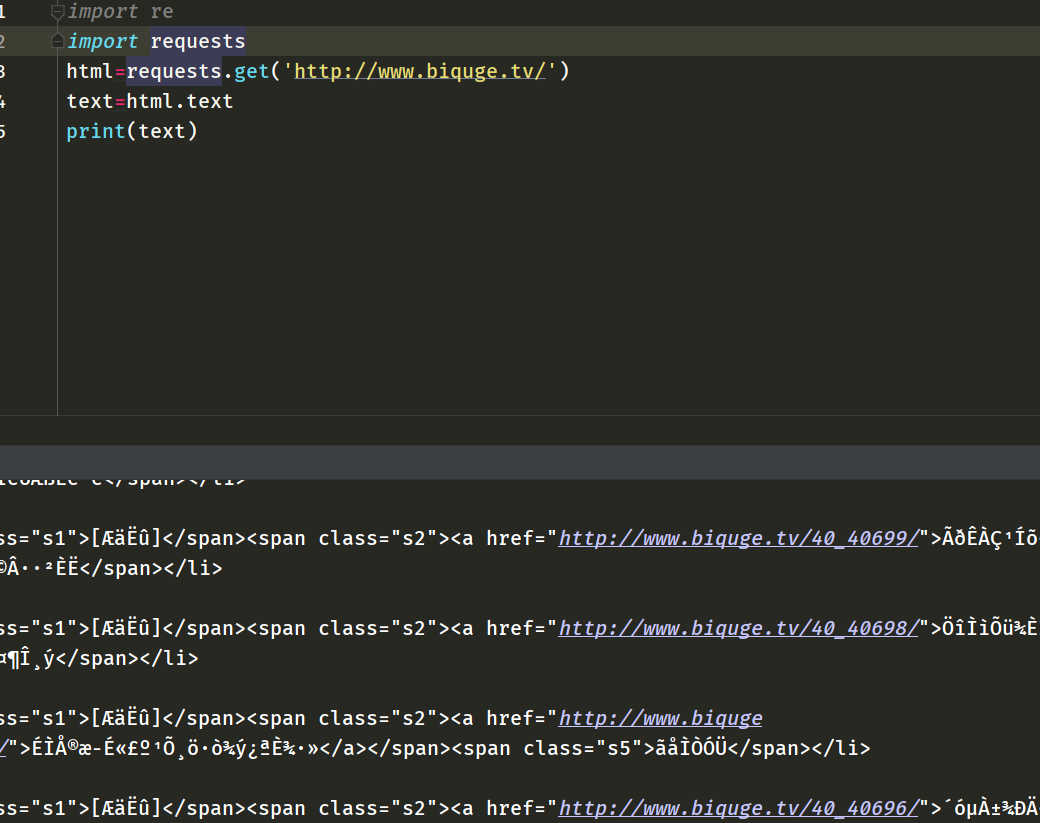
第一次沒有進行轉碼,然后就輸出一堆亂碼。
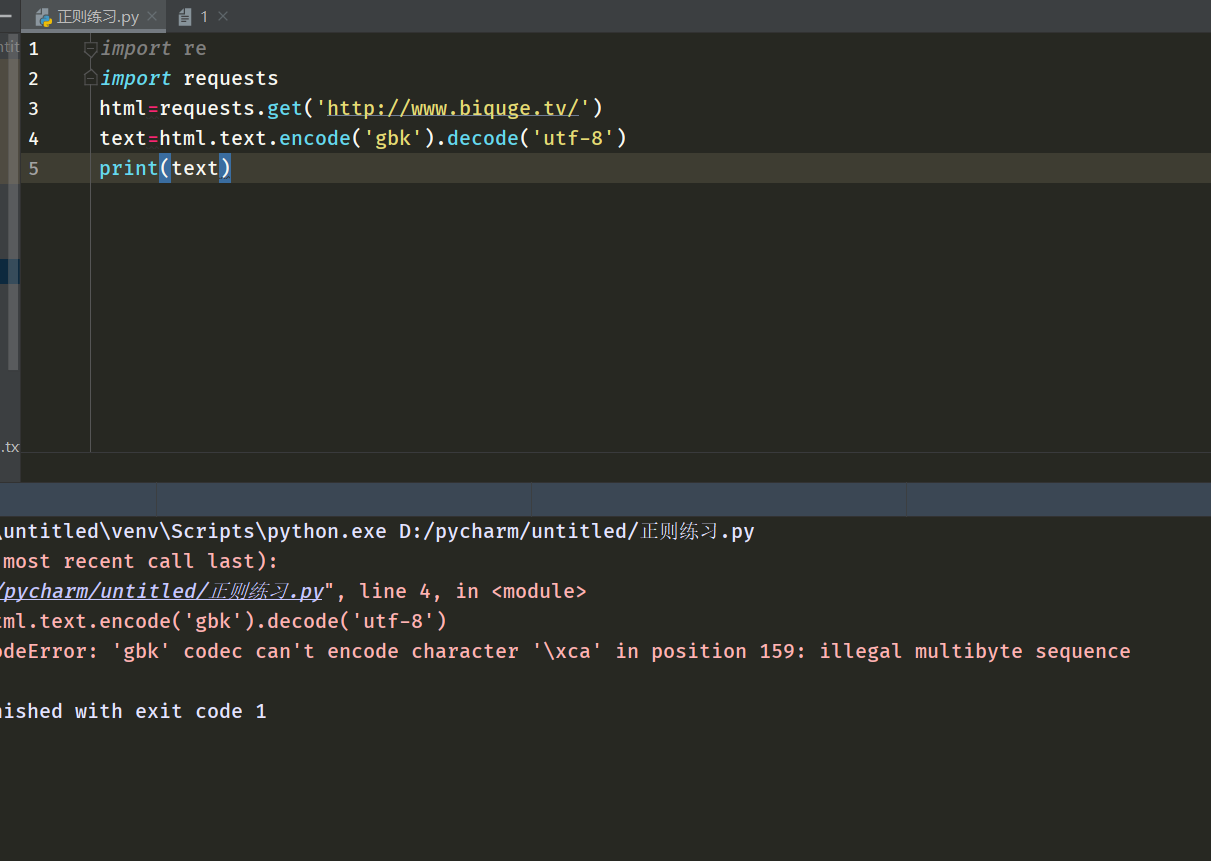
第二次進行encode和decode,然后提示gbk出問題了。
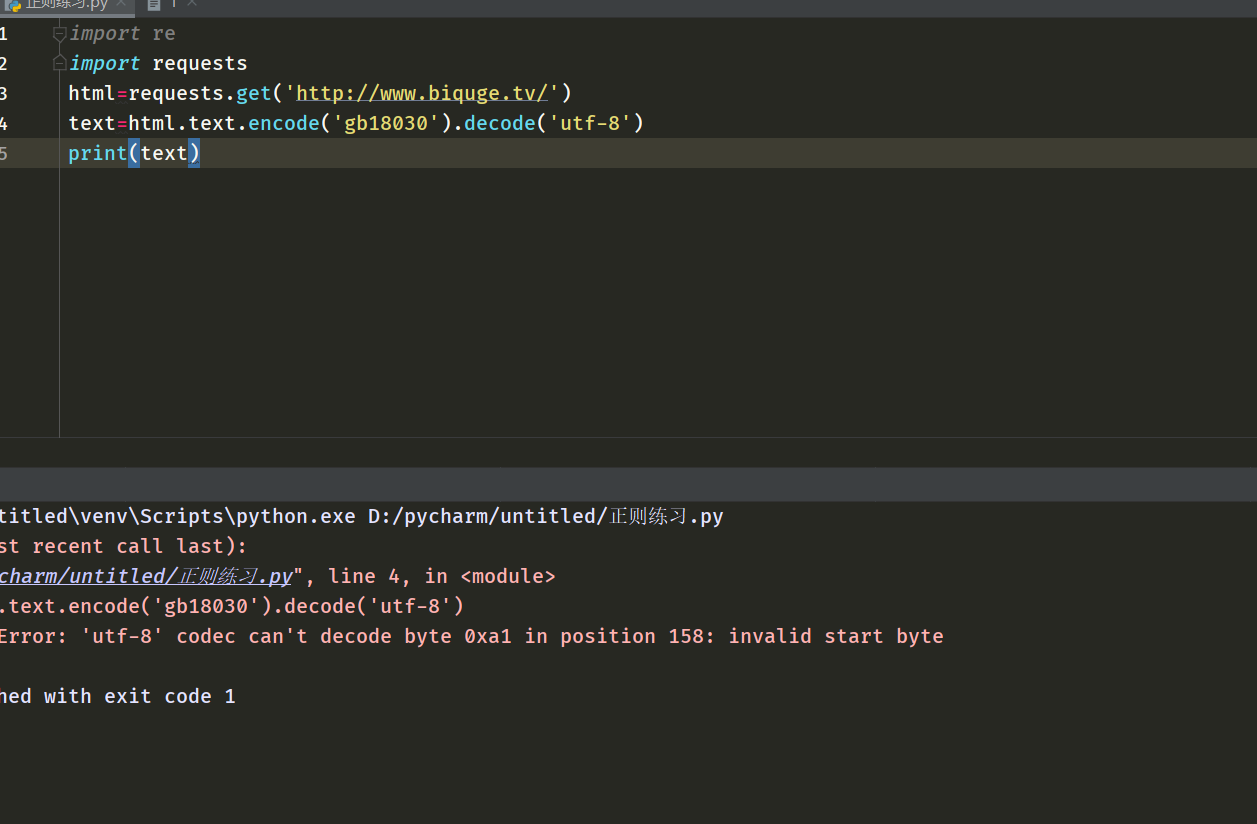
第三次從網上查詢改換成范圍更廣的gb18030,又提示utf-8出問題了。
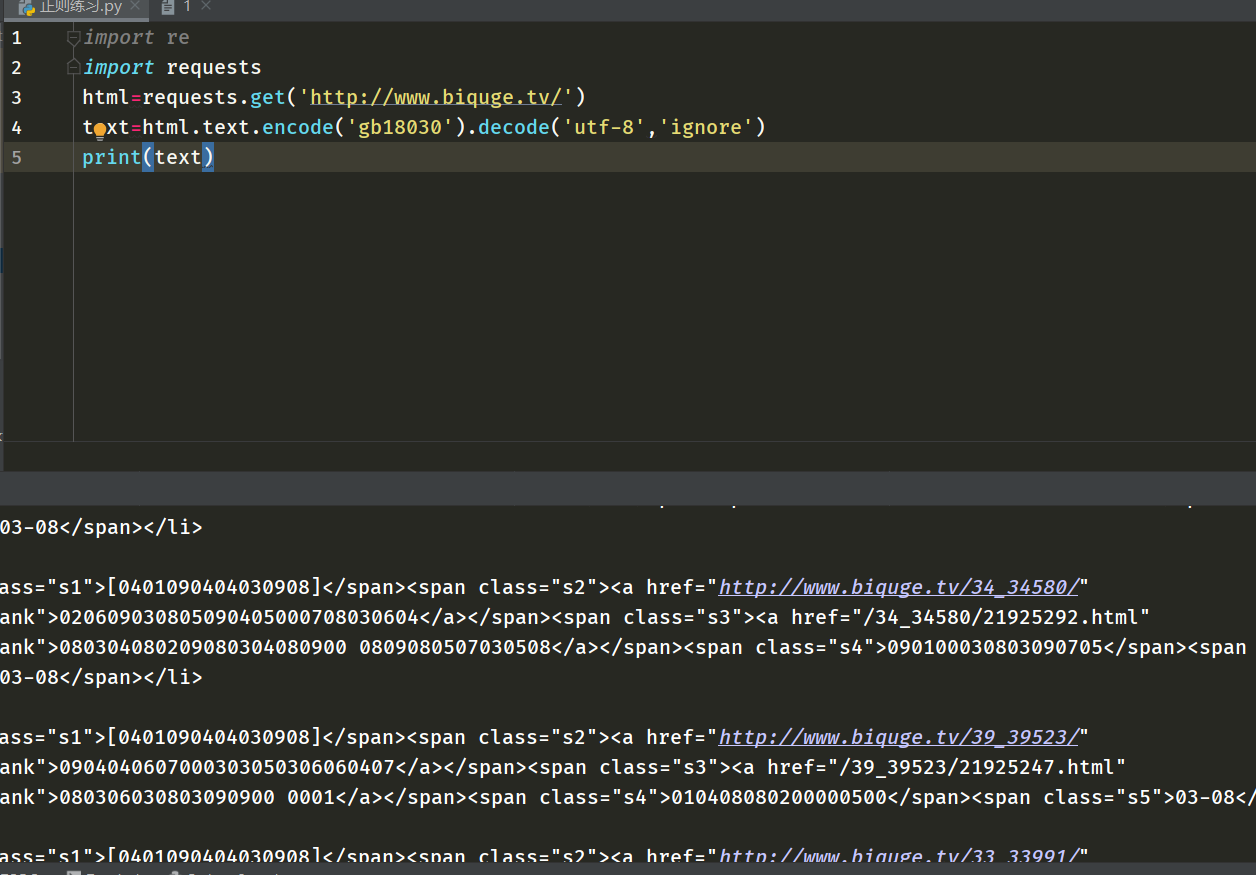
第四次查到用ignore忽略,終于成功了,可原本的中文數字全變成了二進制數字。
OMG,嘗試好多次都不行,哪位大佬教教我啊。
uj5u.com熱心網友回復:
html.content.decode('gbk')uj5u.com熱心網友回復:
謝謝您,問題解決了。如果可以的話,能不能告訴我為什么呢?
uj5u.com熱心網友回復:
意思就是,html的內容已gbk的編碼形式輸出
uj5u.com熱心網友回復:
編碼和解碼都需要使用同一種編碼方式。html使用的charset是哪種,就使用哪種解碼。uj5u.com熱心網友回復:
這個用的是'gbk'編碼查看一下源代碼就知道了。

uj5u.com熱心網友回復:
你這又編碼,又解碼的什么鬼轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/78134.html
下一篇:求助,程式無法運行