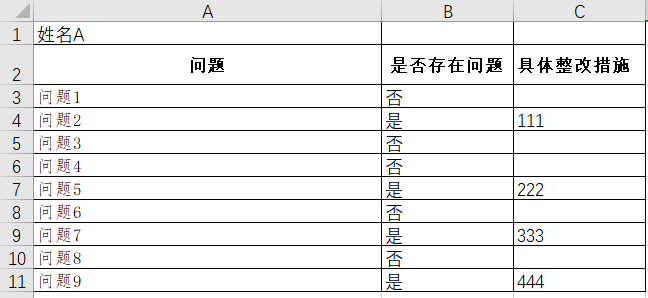
如圖,
有N張不同人物收集回來的excel表,用于統計匯總各個問題
要求:
1、當“是否存在問題”=“是”的時候,由于每個人物的措施都不一樣,應該如何匯總“具體整改措施”
2、如何用Python批量打開N個excel表,再讀取表格內容,然后匯總
小弟flask、GUI、爬蟲寫得多,操作pandas和xlrd這些比較少用,求大神指點
uj5u.com熱心網友回復:
打開N個表格用for 回圈
讀取表格中的相應問題單元格,注意表格xlrd,xlwt只能處理xls檔案
讀取單元格后,對整改措施都放到一個字典或陣列中,再寫到一個匯總里吧,當然,如果字符不多,也可以寫到一個字串里
uj5u.com熱心網友回復:
參考 1 樓 weixin_45903952 的回復: 打開N個表格用for 回圈
對哦,突然有了思維,謝謝你,不過整改措施字符確實挺多了
uj5u.com熱心網友回復:
樓主,你說的這問題,應該比flask,爬蟲之類的簡單多了吧?
-----------------
問題1至問題9都是固定的問題嗎?如果都是固定的話就更簡單了!
為了方便今后的查詢使用,建議分步走:
1.建立資料庫表(你可以完全復制EXCEL需求欄位,也可以只設計你想要的,當然如果保持資料完整性的話,查詢功能將會更加強大和完善)
2.把所有的excel表都放在一個目錄中,利用python遍歷該目錄下的所有檔案
3.利用python回圈讀取第2步的excel檔案,并逐個檔案進行資料處理寫入到資料庫表中
4.利用sql陳述句篩選出自己想要的資料(也可以去建立視圖,更方便查詢)
uj5u.com熱心網友回復:
參考 3 樓 paullbm 的回復: 樓主,你說的這問題,應該比flask,爬蟲之類的簡單多了吧?
對,是固定問題,相當于調查問卷;資料庫也是一個方法,不過好像有點復雜
uj5u.com熱心網友回復:
參考 4 樓 yogo071328 的回復: Quote: 參考 3 樓 paullbm 的回復:
資料庫只是一種存盤方式而已。就算你不用資料庫,假設繼續用excel,代碼量也差不了多少。
如果你不想用資料庫,也不想用excel,那全把資料放在記憶體中?如果資料量大,反而更加沒有優勢!
事實上,使用資料庫的好處是顯而易見的,不僅能讓資料持久化,而且比excel有更強大的查詢功能!
uj5u.com熱心網友回復:
參考 1 樓 weixin_45903952 的回復: 打開N個表格用for 回圈
再請教一下,怎么用for回圈打開excel檔案?
uj5u.com熱心網友回復:
參考 6 樓 yogo071328 的回復: Quote: 參考 1 樓 weixin_45903952 的回復:
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith('.xls'):
uj5u.com熱心網友回復:
如果只是找單一路徑下
for file in os.walk(path):
if file.endswith('.xls'):
uj5u.com熱心網友回復:
import os
用這個吧,是對的
uj5u.com熱心網友回復:
參考 9 樓 weixin_45903952 的回復: import os
thx,可以
uj5u.com熱心網友回復:
參考 9 樓 weixin_45903952 的回復: import os # 打開全部excel
我這樣寫,for回圈是不是嵌套錯了,我現在這樣是分別把N個表全打開輸出了,應該怎樣具體整改措施進行合并?
uj5u.com熱心網友回復:
參考 11 樓 yogo071328 的回復: Quote: 參考 9 樓 weixin_45903952 的回復: import os # 打開全部excel
在打開所有的檔案前,用個list=[]
在中間用個templist,templist.append 分別 i, value[0],value[1],value[2]
然后list.append(templist)
這樣得到到list=[[[1],[2],[3],[4]] ,[[5],[6],[7],[8]]]
再通過回圈寫入excel表
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/78172.html
標籤:腳本語言(Perl/Python)
上一篇:??
下一篇:新手小白求助截圖相關問題(區域)