專欄地址:
MySQL系列文章專欄
文章目錄
- 1. 索引與表的維護
- 2. 使用自增主鍵
- 3. 使用覆寫索引
- 3.1 回表
- 3.2 利用覆寫索引減少回表
- 3.3 InnoDB對回表的優化
- 3.3.1 MRR(Mutil-Range Read)
- 3.3.2 索引下推(Index Condition Pushdown,ICP)
- 4. 使用聯合索引
- 5. 盡量使用普通索引而不是唯一索引
- 5.1 性能對比
- 5.2 如何保證資料不重復插入
- 6. MySQL為什么會選錯索引
- 6.1 影響優化器選擇索引的因素
- 6.1.1 掃描行數
- 6.1.2 二級索引的回表代價
- 6.2 索引選擇例外的處理
- 7. 如何給字串欄位加索引
- 8. 索引的失效場景及優化
- 8.1 索引失效場景
- 8.2 高性能的索引策略
- 9. 如何優化慢查詢
- 參考
1. 索引與表的維護
為什么要重建索引
索引樹會因為洗掉、頁分裂等原因,導致資料頁有了空洞,重建索引會創建一個新的索引,將資料按順序插入,使得,索引更加緊湊,資料頁利用率更高,
場景
假設表T有索引k和主鍵索引id,依次使用drop 和add重新創建索引是否合適?
# 重建索引k
alter table T drop index k;
alter table T add index(k);
# 重建主鍵
alter table T drop primary key;
alter table T add primary key(id);
這種方式重建索引k是合適的,但是不適用于主鍵,無論洗掉主鍵還是創建主鍵,都會導致整個表重建,drop和add導致表重建了兩次,正確的做法是使用alter table T engine=innoDB直接進行重建表,
表空間的回收
InnoDB對行記錄的洗掉并不是真正的物理洗掉,而是對洗掉的行記錄進行標記(delete falg),并將其占用空間放入PAGE_FREE串列中,以便后續復用,若整個頁的記錄都被洗掉掉了,則整個頁都可以復用,
因此洗掉資料不會并使得表空間縮小,同時還會產生資料頁空洞,若要對表空間進行收縮,可以使用alter table命令進行重建表,
2. 使用自增主鍵
追加插入,無頁分裂
自增主鍵追加的插入模式,不會造成頁分裂,也就不需要移動其它記錄,
長度短
自增主鍵一般使用8位元組的bigint,較業務主鍵長度更短:
- 二級索引的葉子節點資料量更短,整體占用空間更少;
- 聚集索引內部更加緊湊,
反例
KV場景,只有一個索引,該索引必須唯一,
3. 使用覆寫索引
3.1 回表
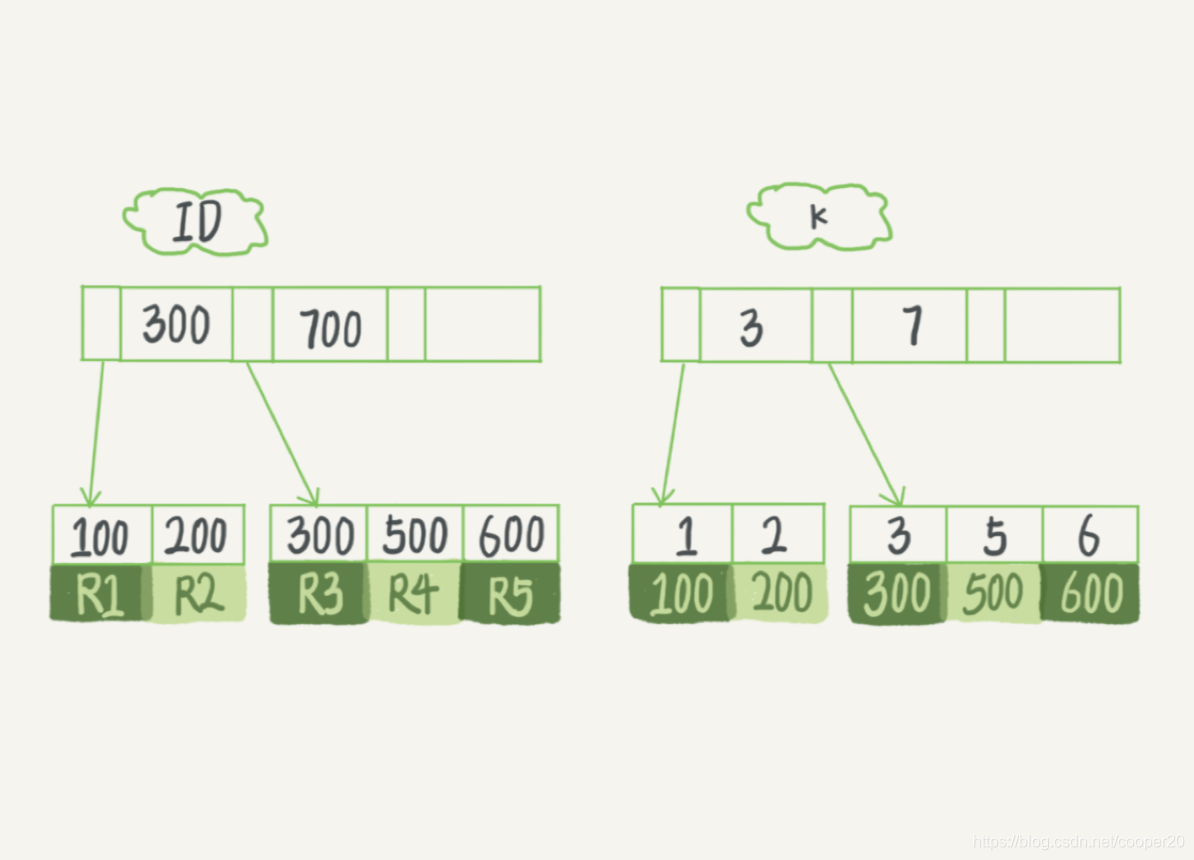
二級索引(輔助索引)的葉子節點保存的是聚簇索引,即主鍵,利用二級索引進行查詢時,若不能獲取到所有需要查詢的欄位,則需要一次額外的回表操作——得到主鍵之后,再到聚簇索引樹中進行查找,
回表操作位于引擎層,Server層和引擎層的互動以行記錄為單位,
SELECT * FROM t WHERE k BETWEEN 5 AND 7;需要執行幾次樹的搜索操作?
對K索引樹執行了1次搜索操作,并依次讀取了3、5、7三個值,對3、5進行了2次回表,搜索了2次聚集索引樹,
3.2 利用覆寫索引減少回表
二級索引已經包含SELECT以及WHERE中所有的列時,稱之為覆寫索引,此時不需要在進行回表操作,
覆寫索引能夠顯著提升性能,是一個常見的優化手段,對于高頻的請求上建立覆寫索引,不需要再進行回表操作查詢整行記錄,減少陳述句的執行時間,
但是索引的維護也是有代價的,在建立冗余索引來支持覆寫索引時就需要權衡考慮,
可以使用覆寫索引的典型場景有:
- 查詢條件是主鍵,SELECT列是主鍵;
- 查詢條件是聯合索引,SELECT列是主鍵或者聯合索引的部分列,
3.3 InnoDB對回表的優化
3.3.1 MRR(Mutil-Range Read)
為了減少回表時的隨機IO,將其轉換成較為順序的磁盤讀取,InnoDB查詢二級索引得到主鍵后,在回表前會對主鍵先進行排序在進行回表,InnoDB并不是得到所有索引后在回表(減少不必要的額外存盤),MRR只能減少回表的隨機IO,此外,即使對主鍵進行排序,也不能保證這些記錄在連續的資料頁上,
回表仍然是一行行的搜索主鍵,但是調整順序可以加速磁盤讀取,
此外,MRR還可以降低快取池中資料頁被替換的次數、批量處理對鍵值的查詢操作,
使用MRR時,EXPLAIN的Extra列會看到Using MRR,
3.3.2 索引下推(Index Condition Pushdown,ICP)
在InnoDB不支持索引下推之前,使用索引查詢時,首先根據索引查找到記錄,然后Server層在根據WHERE條件進行過濾,
MySQL5.6之后對引擎層的介面能力進行了提升,可以將部分的WHERE過濾操作下推到存盤引擎層,大幅降低了回表的次數和SERVER層fetch的記錄數,
具體而言,在使用聯合索引時,對于WHERE條件中符合最左前綴的部分可以用于進行索引查找,對于不滿足最左前綴的部分(或者主鍵的部分?),也傳遞給存盤引擎,用于進行過濾,
比如,有聯合索引 (name, age),使用SELECT * FROM t WHERE name like '張%' AND age = 10 AND ismale = 1在查找姓張且年齡為10歲的男孩,在沒有索引下推的情況下,需要對每一個張字打頭的記錄進行回表,總共需要回表4次,
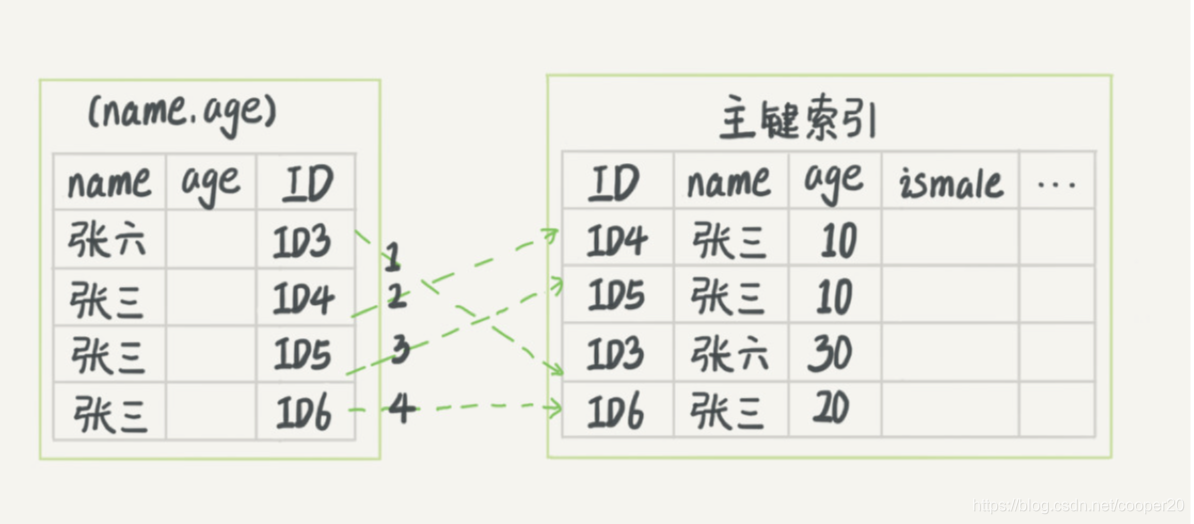
而在有索引下推的情況下,InnoDB對于從二級索引樹上讀取到的記錄,首先對索引中包含的age欄位進行判斷,過濾掉不符合條件的記錄后,再進行回表,總共回表了2次,

PS
對于WHERE中含有多個索引的情況下,MySQL一般只會選擇使用其中的一個索引,但是,MySQL還有索引合并優化,對同一個表的多個索引樹同時進行條件掃描,并將結果進行合并(并集、交集),EXPLAIN中type列為index_merge,
4. 使用聯合索引
聯合索引是對表上的多個列建立一個索引,聯合索引是有序的,索引的鍵值是按照列的順序依次進行排序的,使用聯合索引可以減少索引的個數、減少排序操作,
最左前綴
能夠利用聯合索引進行查詢的前提是,條件要符合最左前綴原則——最左前綴可以是前N個列也可以是前M個字符,
ps
對于二級索引上不符合最左前綴的查詢,比如 ‘%j‘,雖然不能利用該索引進行快速查找,但是可以通過掃描二級索引樹而不是掃描聚集索引樹加快檢索速度,
建立原則
建立聯合索引時,如何安排內部列的順序呢?如果通過調整順序,可以少維護一個索引,那么這個順序往往就是應該優先考慮的,
優點
建立聯合索引可以減少索引的個數,同時由于索引的鍵值是按照列的順序進行列排序,在很多情況下可以減少排序操作,
若業務中存在高頻的需要排序的查詢模式時,可以考慮通過建立冗余的聯合索引來減少排序操作,
比如一個表有 (a, b)聯合索引,同時也對c建立列索引:
PRIMARY KEY (`a`,`b`)
KEY `c` (`c`)
此時,對于如下的查詢模式,是可以走索引的:
WHERE c ORDER BY a
WHERE c ORDER BY b
是否需要建立 ca 和 cb 兩個冗余索引,以減少排序操作?
KEY `ca` (`c`, `a`)
KEY `cb` (`c`, `b`)
首先,ca是肯定不需要的,因為主鍵是ab,對于二級索引 c,其葉子節點記錄的主鍵ab是有序的,其排序規則是c a b因此可以支持c、a排序操作,
對于cb,考慮c的選擇性,如果重復率不高,那么排序的成本可以忽略,如果排序較為耗時,那么可以建立冗余索引cb,cb索引樹的排序是c b a,非葉子節點記錄c b并以此排序,葉子節點記錄c b a,
5. 盡量使用普通索引而不是唯一索引
5.1 性能對比
在不影響業務邏輯的前提下,從性能上考慮,普通索引較唯一索引更優,
從查詢上來看,兩者的性能差距微乎其微;在DML操作上,普通索引能夠利用Change Buffer快取寫操作,從而減少隨機IO讀、實作操作合并,具體來說:
查詢操作
對于唯一索引,利用該索引進行檢索時,在二級索引樹上查詢到第一條滿足條件的記錄后,由于唯一索引定義了唯一性,就會停止繼續檢索,
對于普通索引,在查詢到第一條滿足條件的記錄后,需要繼續往下讀取,直到碰到不滿足條件的記錄,
由于InnoDB是按頁讀取的,默認的頁大小是16k,在二級索引樹上,一個資料頁可以存盤上千條記錄(存盤二級索引及主鍵),那么,下一條記錄大概率在同一個資料頁中,而記憶體的一次讀取和比較的開銷幾乎忽略不計,
DML操作
由于InnoDB利用快取池buffer pool來加速資料頁的訪問速度,對資料頁的修改也會先在快取池中進行更新,并在隨后適當的時候對臟頁進行重繪,當待修改的頁不在快取,若將頁先從磁盤中讀取到快取池中再進行修改,會產生較高的隨機IO開銷,為此,InnoDB引入了change buffer,將對非唯一輔助索引(二級索引)的操作快取下來,以此減少隨機讀IO,并達到操作合并的效果,
所以,對于目標頁在快取池的情況,兩者均是記憶體操作,只是唯一索引會多一次唯一性判斷操作,
而對于目標頁不在快取池的情況,唯一索引由于需要判斷唯一性,所以必須將資料頁從硬碟讀取到記憶體,產生了隨機IO讀,而普通索引則直接將更改記錄于change buffer中即可,
5.2 如何保證資料不重復插入
唯一索引
利用唯一鍵保證資料唯一性,在存在邏輯洗掉的場景下,使用 業務欄位 + 時間戳共同組成唯一索引,資料未洗掉時時間戳為-1,洗掉后為洗掉時間,
使用on duplicate key update可以在發生沖突時執行更新操作,
先檢查再插入
在可重復讀的隔離級別下,在同一個事務中,先SELECT..LOCK IN SHARE MODE或者SELECT..FOR UPDATE對將要插入的資料或范圍加鎖,若不存在再執行插入陳述句,主要利用了InnoDB的Nextkey鎖,
分布式鎖
利用Redis等實作分布式鎖來保證插入操作的唯一性,
6. MySQL為什么會選錯索引
在不斷洗掉歷史資料 / 新增資料、長事務中進行洗掉等場景下,會導致統計資訊不準確、存在冗余的洗掉資料頁,影響掃描行數的預估,進而導致優化器選擇錯誤的索引,
6.1 影響優化器選擇索引的因素
優化器位于SERVER層,用于生成執行計劃:決定使用哪個索引、各個表連接順序、IN查詢優化(將IN進行排序然后使用二分法判斷記錄是否滿足條件)、等值傳播(WHERE條件同樣適用于與其關聯的列)、使用等價變換規則合并/減少WHERE條件等等,以最小的成本執行查詢,
影響優化器成本計算的因素主要有:掃描行數、是否使用臨時表、是否需要排序以及普通索引的回表代價等等,不準確的統計資訊可能會導致成本計算錯誤,但即使統計資訊準確,MySQL選擇的執行計劃也可能并不是最優的:計算IO成本時,因為Server層并不知道哪些資料頁位于快取池,無法準確知道實際的物理IO次數,也不知道是否為順序讀,此外,優化器對一些特定的查詢優化具有一定的局限性,
6.1.1 掃描行數
什么是掃描行數
EXPLAIN中的rows欄位表示優化器預估的掃描行數,
利用索引基數預估掃描行數
MySQL在真正執行SQL之前并不能準確的知道需要掃描多少條記錄,而只能根據索引的選用情況和統計資料來進行估算,這個統計資訊就是索引基數Cardinality,其表示著索引的區分度,即不同值的個數有多少個,知道了索引的基數,加上當前索引條件,就可以估算出大概有多少條滿足條件的記錄,
使用SHOW INDEX在Cardinality列可以看到每個索引的基數,Cardinality值約接近于行記錄數,說明索引的選擇性越高,
索引基數Cardinality如何統計
Cardinality的統計在引擎層完成,采用條件觸發、采樣統計的方式進行統計,盡量減少統計操作對資料庫造成的壓力,
默認情況下,InnoDB會隨機選擇輔助索引樹8個葉子節點資料頁,統計每個頁不同記錄的個數,然后計算平均值再乘以頁面數就得到了整個索引的Cardinality值,
隨著資料庫表的持續更新,統計資訊也不是固定不變的,但InnoDB并不是在每次發生變更的時候就及時更新,而是在表中的1 / 16的行發生變更的時候才會觸發一次自動更新,
會什么會得到錯誤的掃描行數
一是統計資訊的不準確,造成這種情況的原因是表資料頻繁的修改,可以使用ALALYZE TABLE t重新計算一下統計資訊,
二是在長事務中進行洗掉,若事務未提交,那么其舊的資料(頁)就不能刪掉,多余的資料(頁)會使得掃描行數變多,解決辦法就是減少長事務,
6.1.2 二級索引的回表代價
如果訪問的資料量較小,優化器還是會優先選擇二級索引,但當訪問的資料占據整個表的較大部分,比如20%以上時,優化器會選擇通過聚集索引來查找資料,主要考慮到二級索引的回表操作帶來的隨機IO成本要高于全表掃描的順序IO成本,
雖然InnoDB有MRR,但只能減少回表的隨機IO,而不能避免,
使用覆寫索引以減少回表,
6.2 索引選擇例外的處理
統計資訊不準確導致的問題,使用ALALYZE TABLE t重新計算一下統計資訊,
使用FORCE INDEX來強行選擇一個索引,
考慮修改SQL陳述句,引導MySQL使用我們期望的索引,比如加個ORDER BY,
新建一個合適的索引,或是洗掉誤用的索引,如果其用處不大的話,
7. 如何給字串欄位加索引
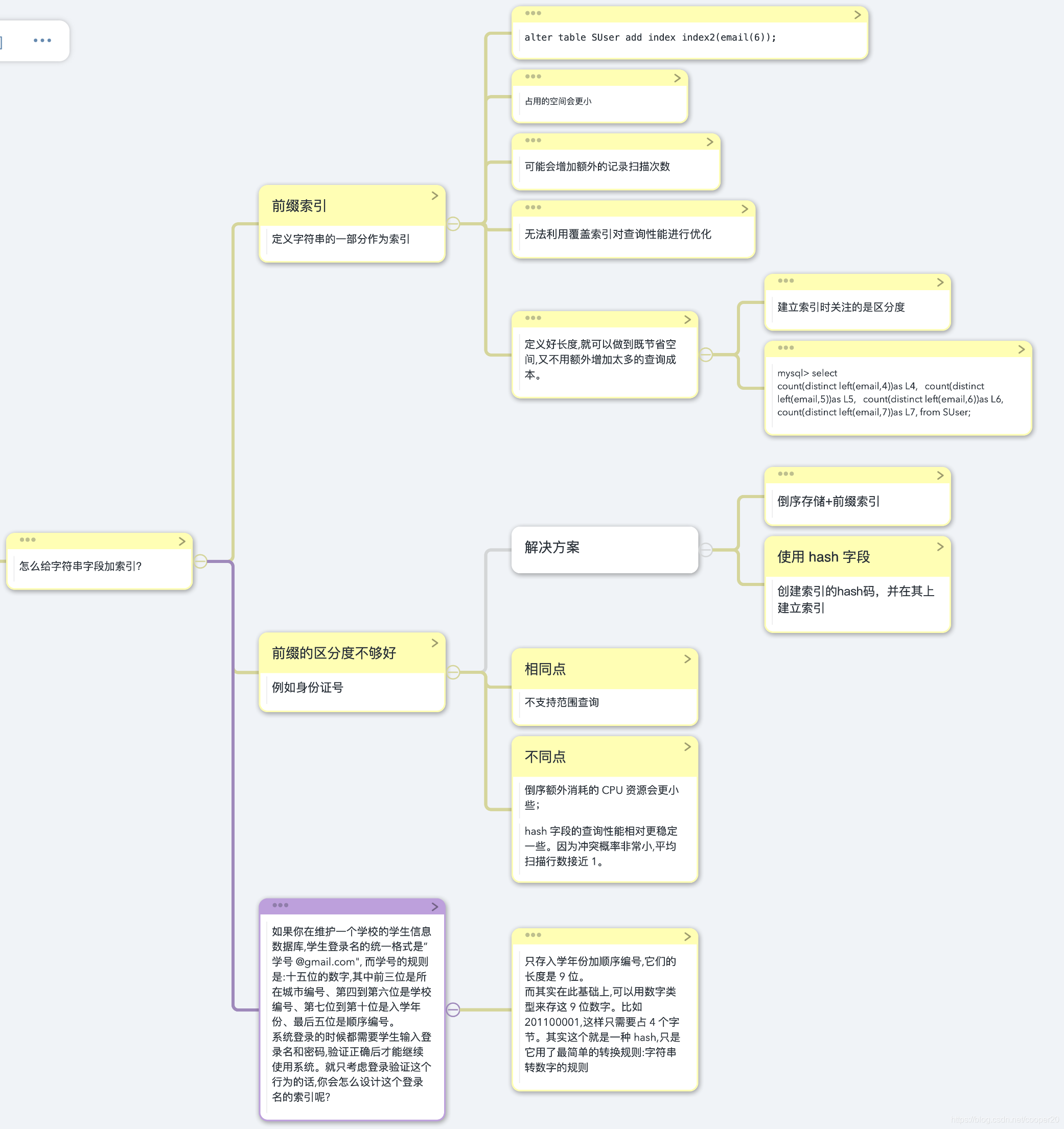
前綴索引
使用前綴索引,占用空間更小,合理設定索引長度以平衡區分度和占用空間,但前綴索引查詢無法使用覆寫索引特性,
若前綴索引區分度不夠高,可以使用hash對欄位進行散列再建立索引;或者可以利用欄位的特性,比如欄位的后半部磁區分度高,那么可以使用倒序存盤,再建立前綴索引,
8. 索引的失效場景及優化
8.1 索引失效場景
此處索引失效指的是無法利用索引進行查找,索引的另一種使用方式是對輔助索引樹進行掃描,其較對聚集索引掃描的成本更低,
聯合索引
不符合最左前綴原則:LIKE模糊查詢以%開頭會導致索引失效;abc索引,查詢條件為ac,索引生效且c下推,
OR
OR兩側不全是索引,
索引操作
在索引上進行計算、型別轉換、使用函式等等,
譬如在字串索引未增加引號、關聯查詢中兩個表字符集不一樣導致的被驅動表索引增加函式操作,
8.2 高性能的索引策略
索引和鎖
索引可以讓查詢鎖定更少的行,降低鎖開銷、提高并發度,
獨立的列
索引不能是函式或者運算式的一部分,
前綴索引和區分度
合理設定索引長度以平衡區分度和占用空間,
查詢頻率和區分度
在區分度高和區分度低但查詢頻繁的列上建立索引,
聯合索引和欄位順序
合理設定聯合索引及其順序以減少索引數量、排序操作,
使用自增主鍵
長度短,追加的插入模式不會造成資料頁分裂,
使用覆寫索引
減少不必要的回表,
使用普通索引
利用Change Buffer減少隨機IO讀,
利用索引進行排序
最好的索引既可以用于查找同時也可以用于排序,
避免使用多個范圍查詢
MySQL只能使用其中一個索引
ORDER BY列增加聯合索引
避免排序
MySQL的排序有兩種演算法,請求的列較少時,則將所有欄位放入快取中進行快排,記憶體不夠時,使用檔案進行歸并排序;請求的列較多時,則只將排序需要的列放入快取,排序完成后,在進行回表得到所有列,
9. 如何優化慢查詢
不要請求不必要的資料
不必要的記錄、不必要的列,
掃描行數
掃描行數和回傳行數比率應盡量接近于1,一般在1:1到1:10之間,
訪問型別
EXLPAIN中的type串列示訪問型別,從全表掃描、索引掃描、索引范圍掃描、索引查找到常量參考,性能從差到好,
拆分查詢
減少鎖定的資料(譬如資料結轉)、事務大小,
拆解關聯查詢
在程式中關聯,快取更高效、減少鎖競爭
優化特定型別的查詢
- 優化limit查詢:覆寫索引+延遲關聯
- 關聯查詢:在第二個表的ON列上建立索引
參考
《MySQL實戰45講》
《MySQL技術內幕(InnoDB存盤引擎)》
《高性能MySQL》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/78646.html
標籤:其他
上一篇:各位大佬怎么用AD 軟體畫單片機的電源電路呢?謝謝各位大佬
下一篇:JAVA JDBC