正則運算式學習筆記
什么是正則運算式 ?
正則運算式是一種被用于從文本中檢索符合某些特定模式的文本,
正則運算式是從左到右來匹配一個字串的,"Regular Expression" 這個詞太長了,我們通常使用它的縮寫 "regex" 或者 "regexp", 正則運算式可以被用來替換字串中的文本、驗證表單、基于模式匹配從一個字串中提取字串等等,
想象一下,您正在撰寫應用程式,并且您希望在用戶選擇用戶名時設定規則,我們希望用戶名可以包含字母,數字,下劃線和連字符, 為了讓它看起來不丑,我們還想限制用戶名中的字符數量,我們可以使用以下正則運算式來驗證用戶名
1. 簡寫字符集
正則運算式為常用的字符集和常用的正則運算式提供了簡寫,簡寫字符集如下:
| 簡寫 | 描述 |
|---|---|
| . | 匹配除換行符以外的任意字符 |
| \w | 匹配所有字母和數字的字符: [a-zA-Z0-9_] |
| \W | 匹配非字母和數字的字符: [^\w] |
| \d | 匹配數字: [0-9] |
| \D | 匹配非數字: [^\d] |
| \s | 匹配空格符: [\t\n\f\r\p{Z}] |
| \S | 匹配非空格符: [^\s] |
| \b | 匹配單詞的開始或結束 |
| \B | 匹配非單詞的開始或結束 |
| ^ | 匹配字串的開始 |
| [^x] | 匹配除了x意外的任意字符 |
| $ | 匹配字串的結束 |
. 匹配除換行符以外的任意字符
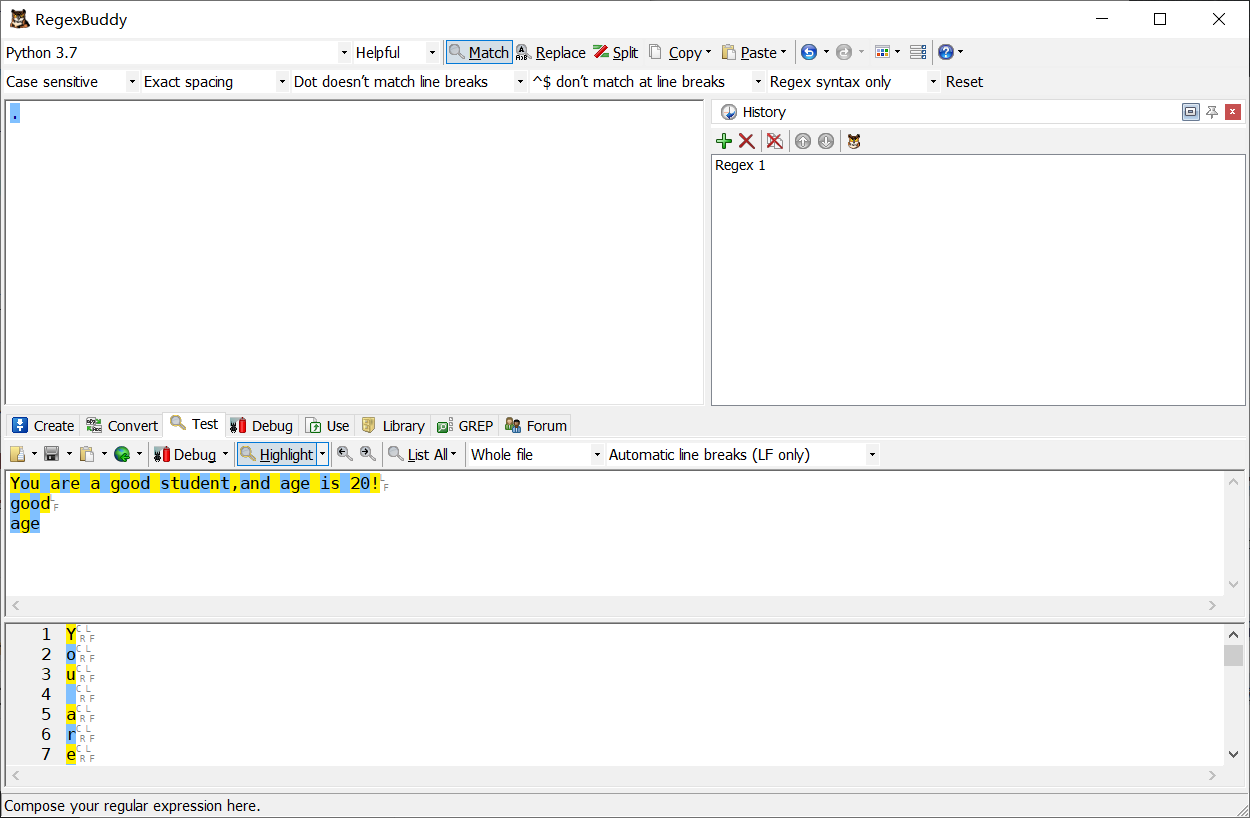
\w 匹配所有字母和數字的字符: [a-zA-Z0-9_]
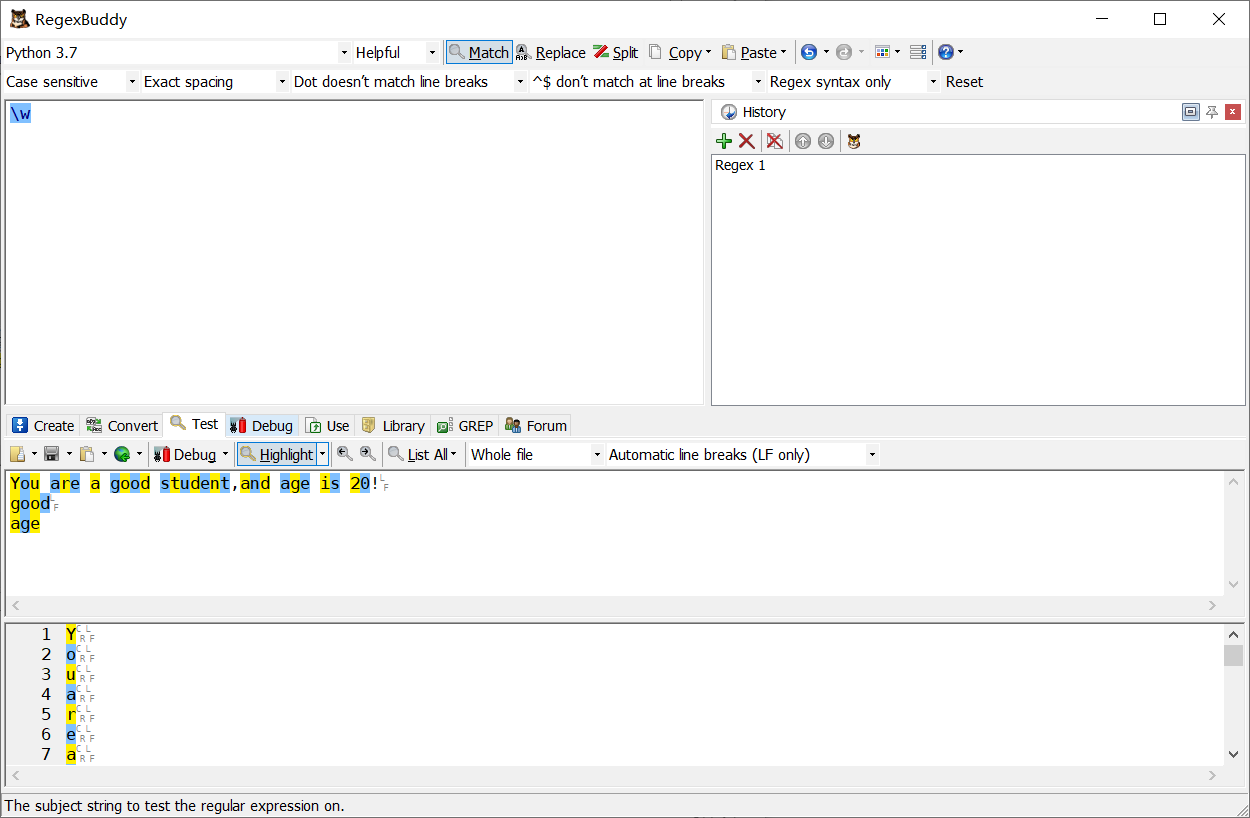
\W 匹配非字母和數字的字符: [^\w]
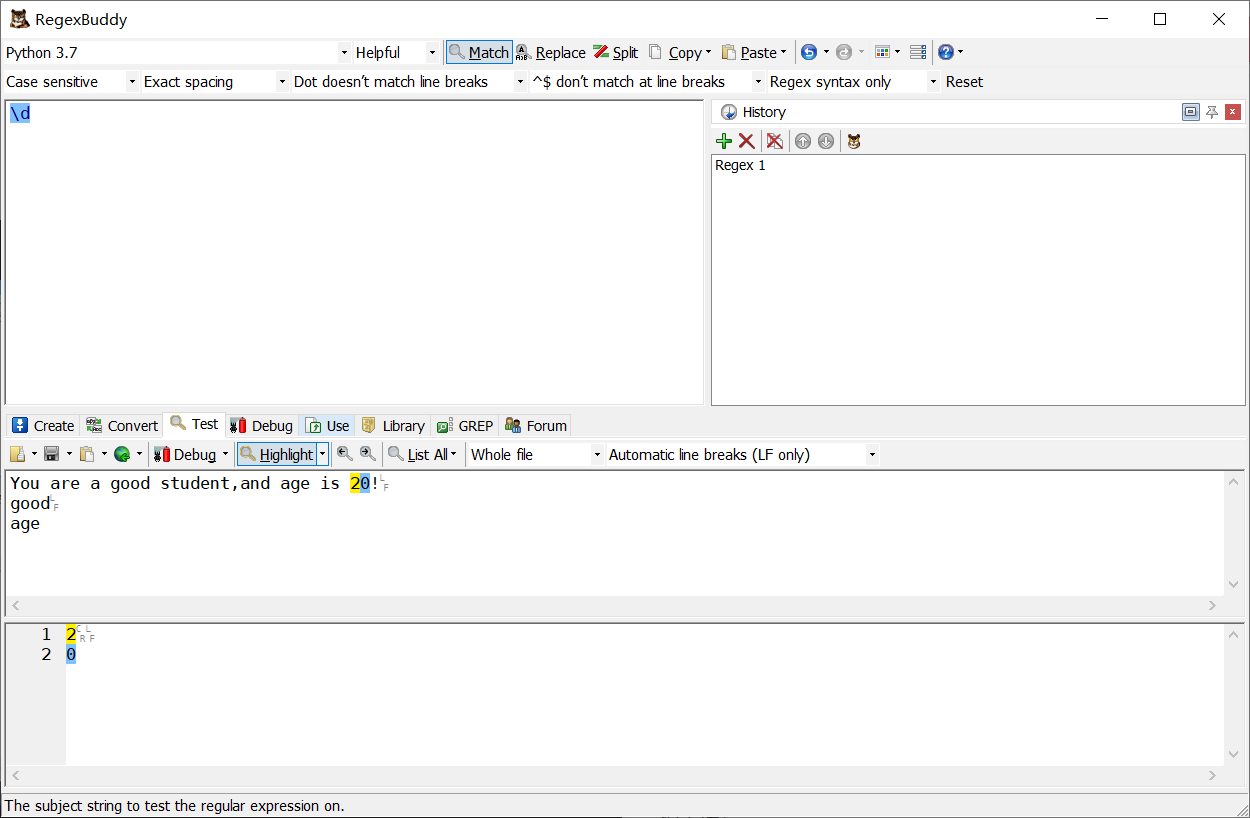
\d 匹配數字: [0-9]
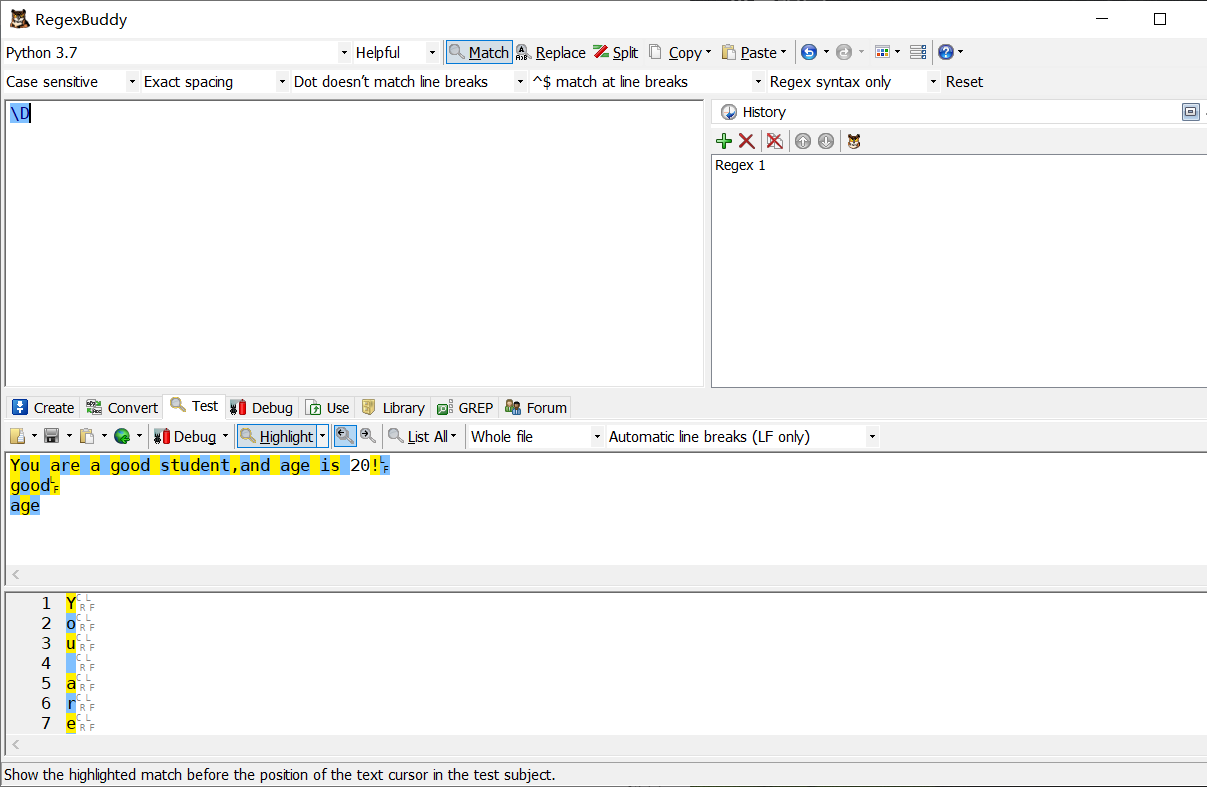
\D 匹配非數字: [^\d]
\s 匹配空格符: [\t\n\f\r\p{Z}]
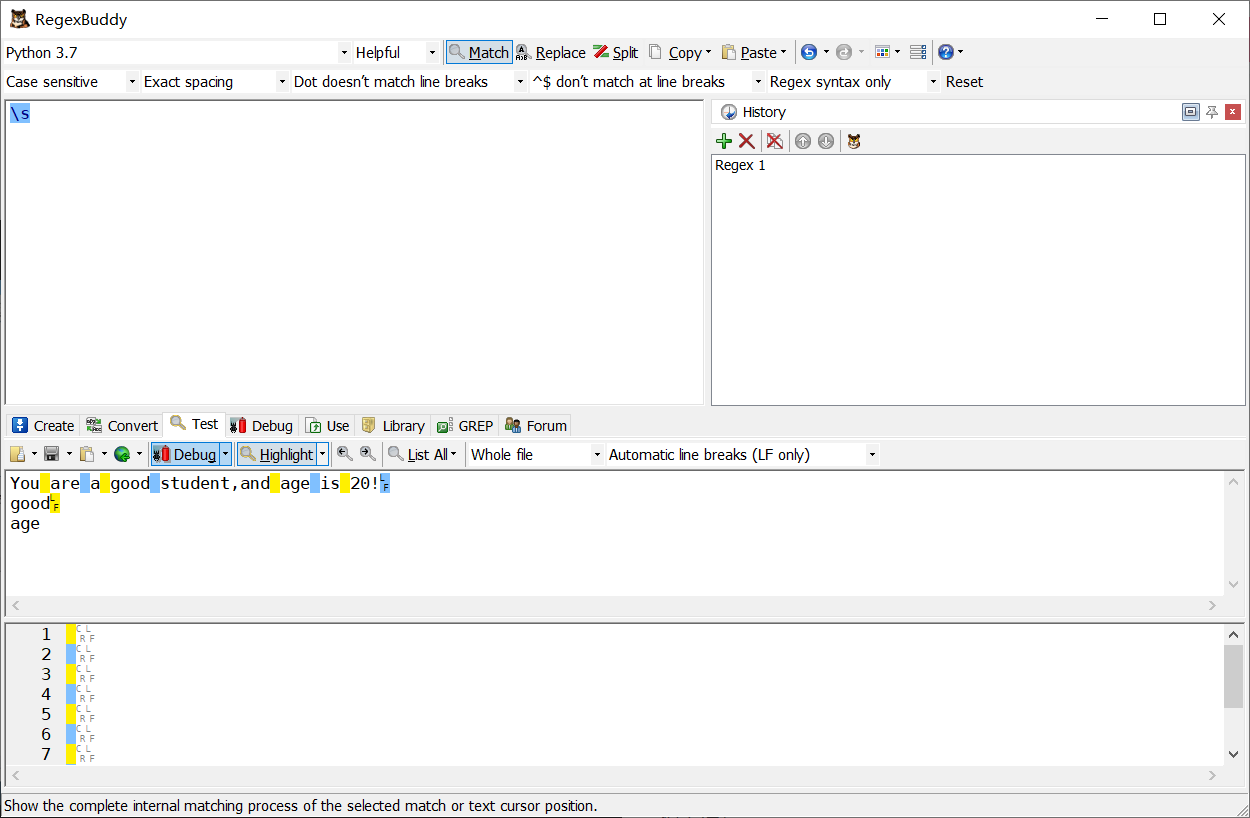
\S 匹配非空格符: [^\s]
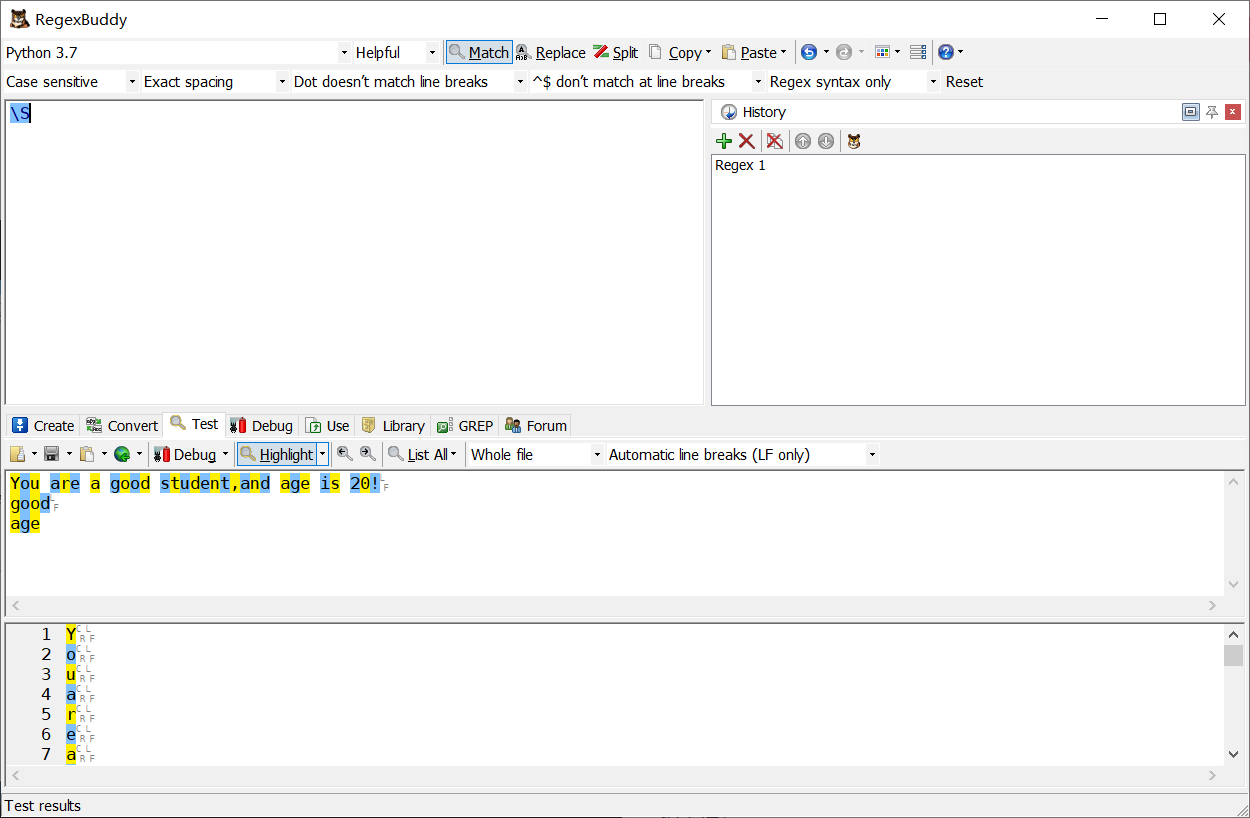
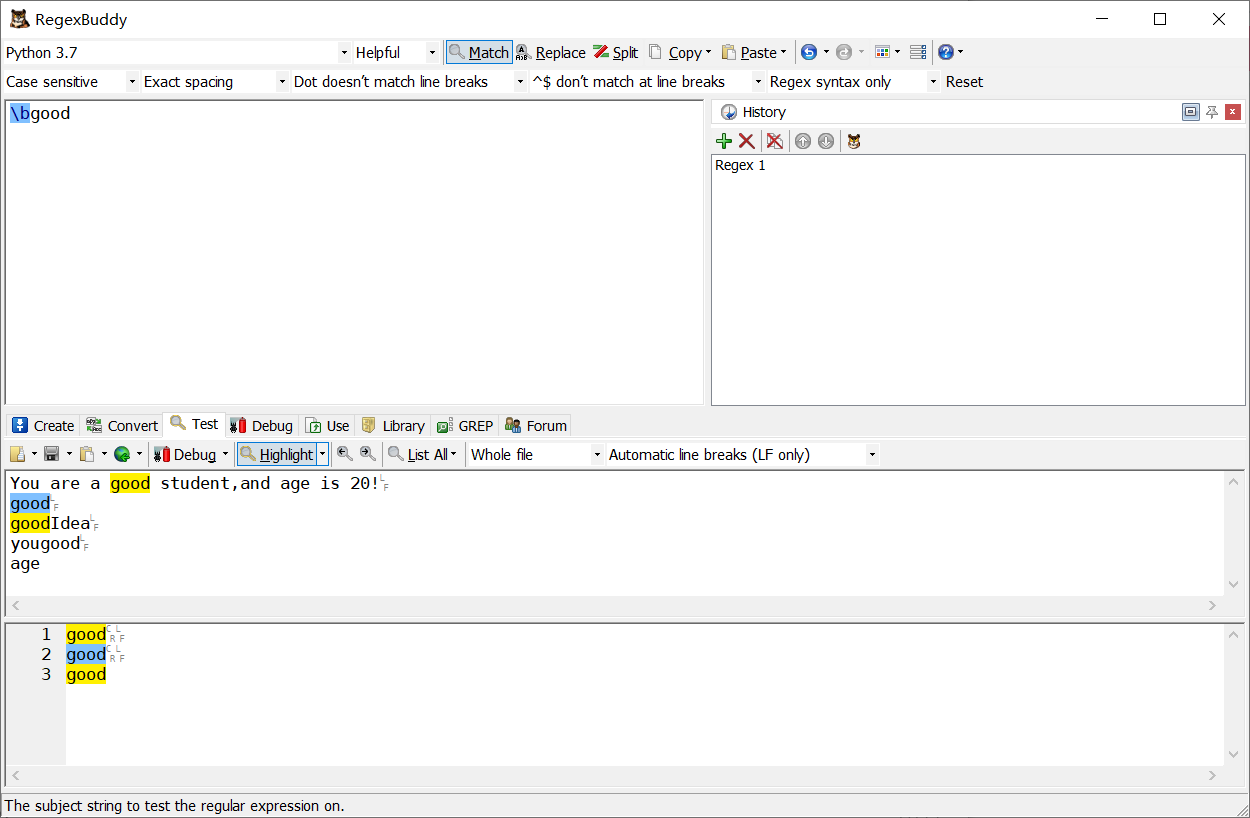
\b 匹配單詞的開始或結束
-
不加\b效果
-
-
加上\b的效果
-
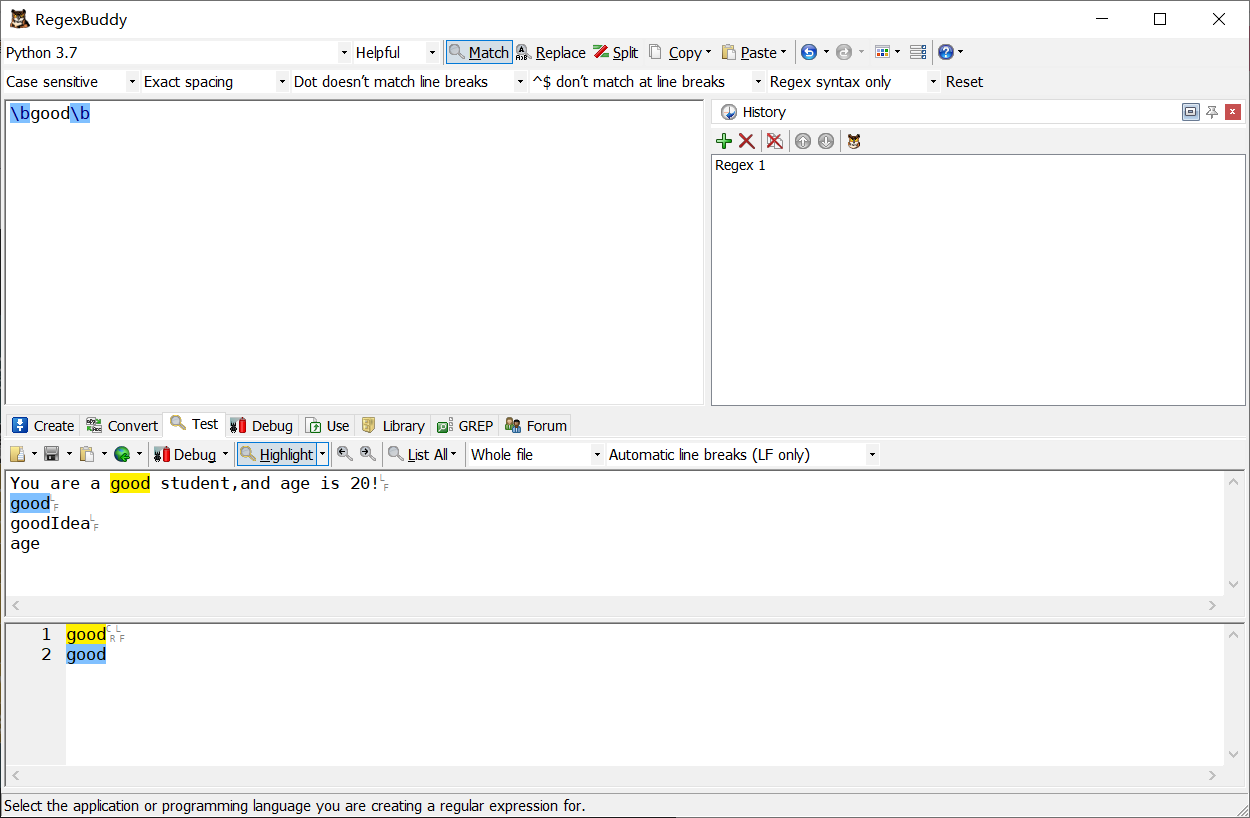
兩邊都加上\b
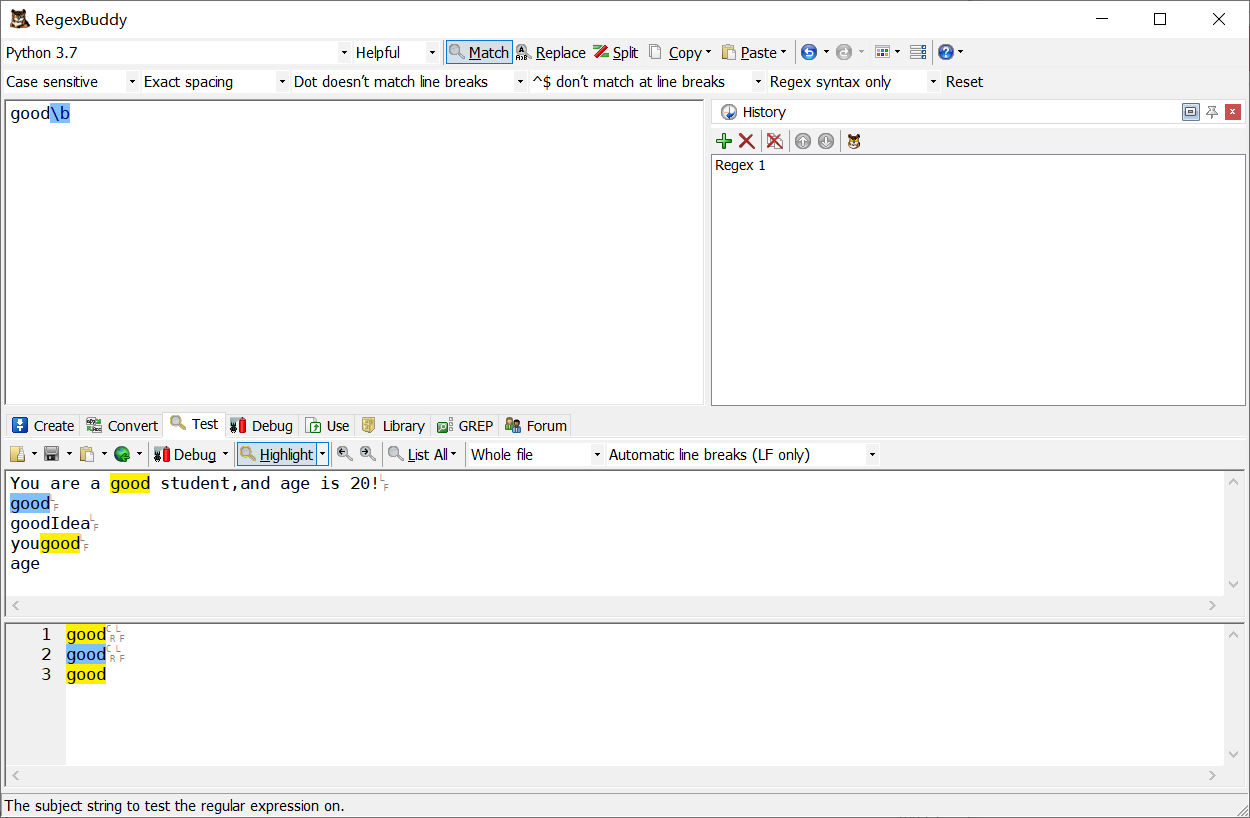
-
前面加上\b
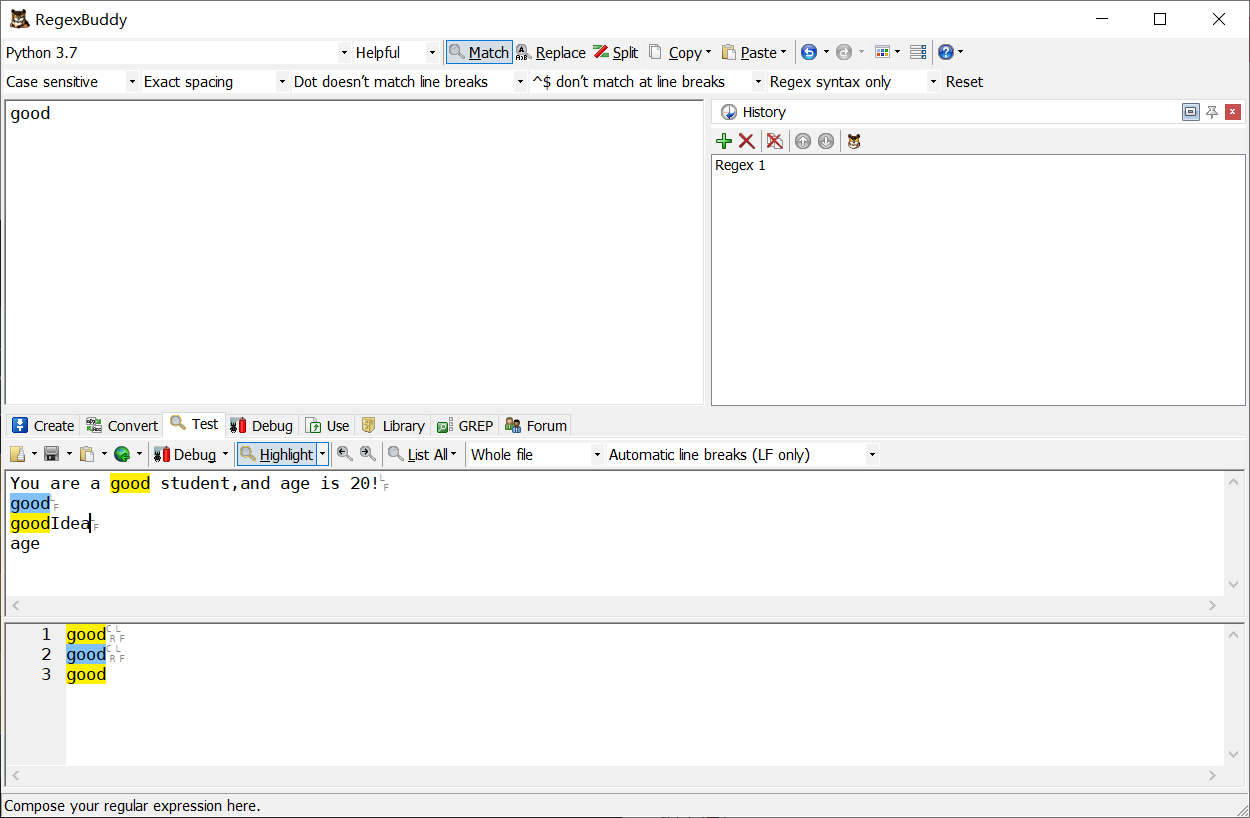
-
后面加上\b
-
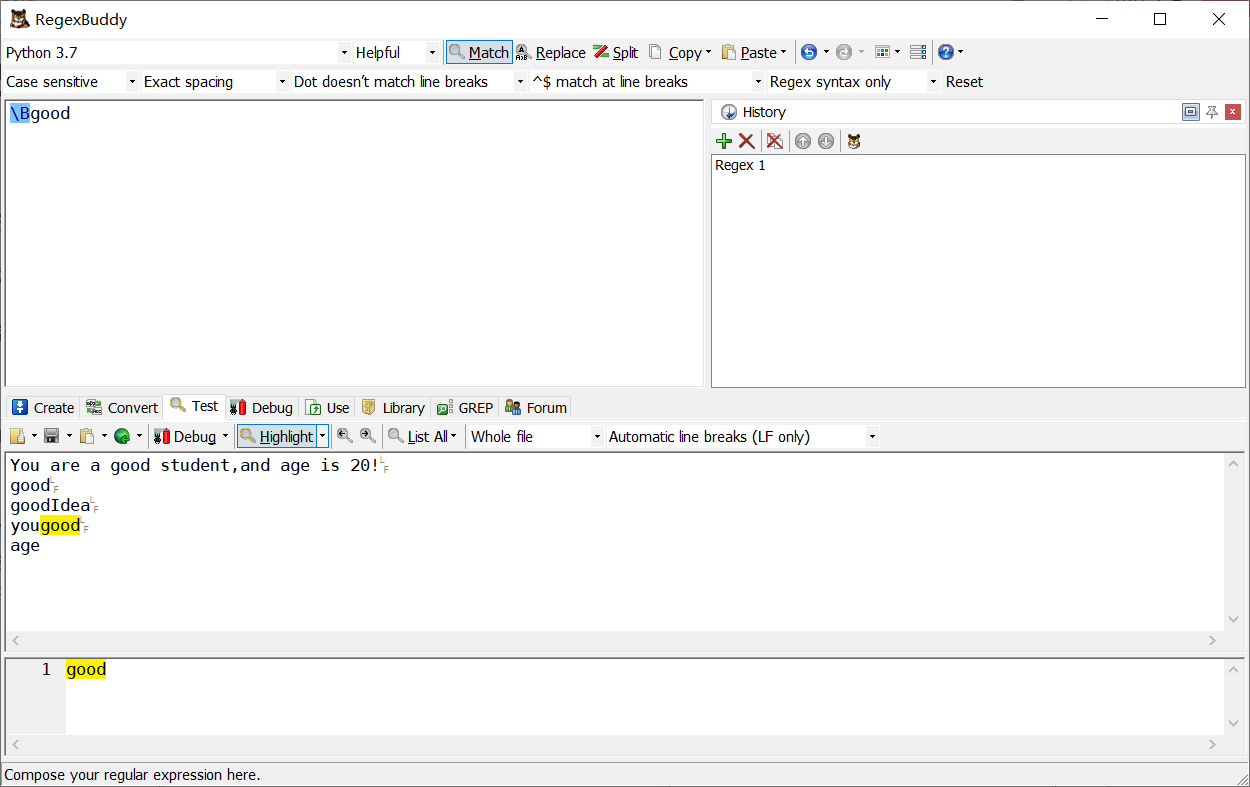
\B 匹配非單詞的開始或結束
-
\B加前面
-
\B加后面
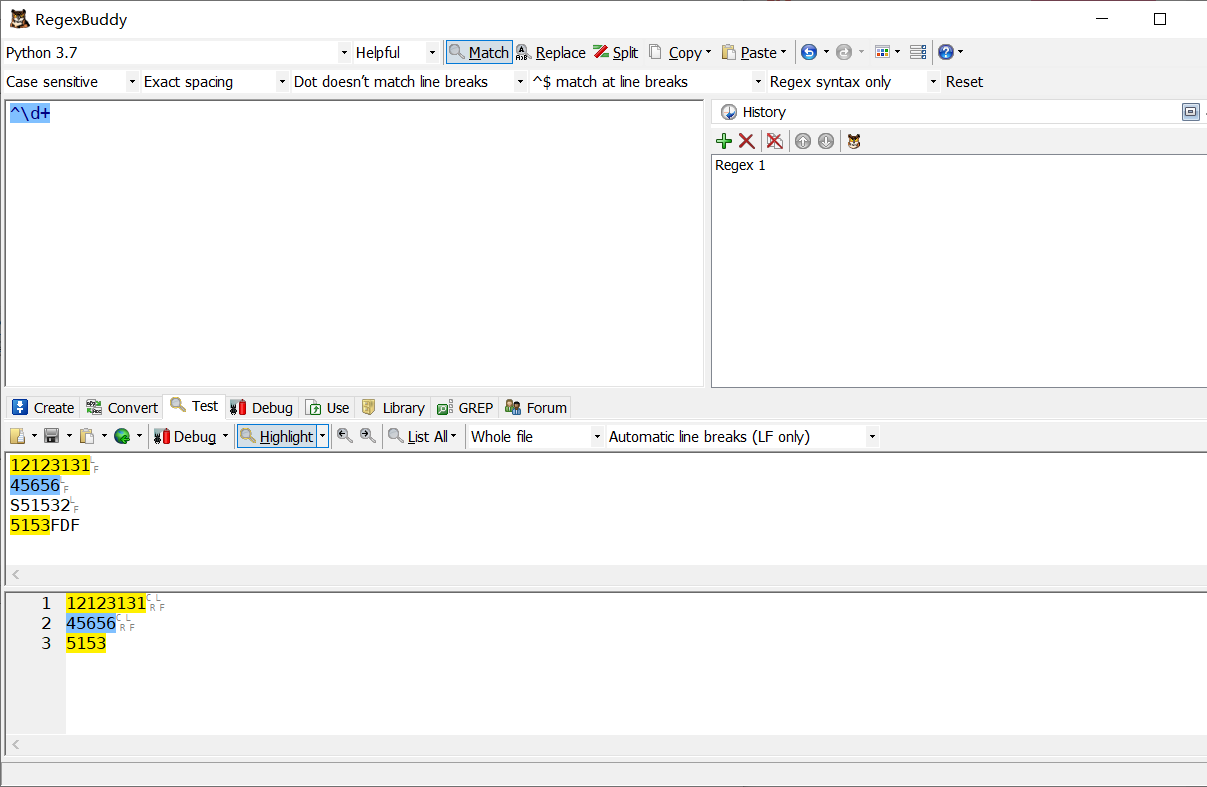
^\d+$
-
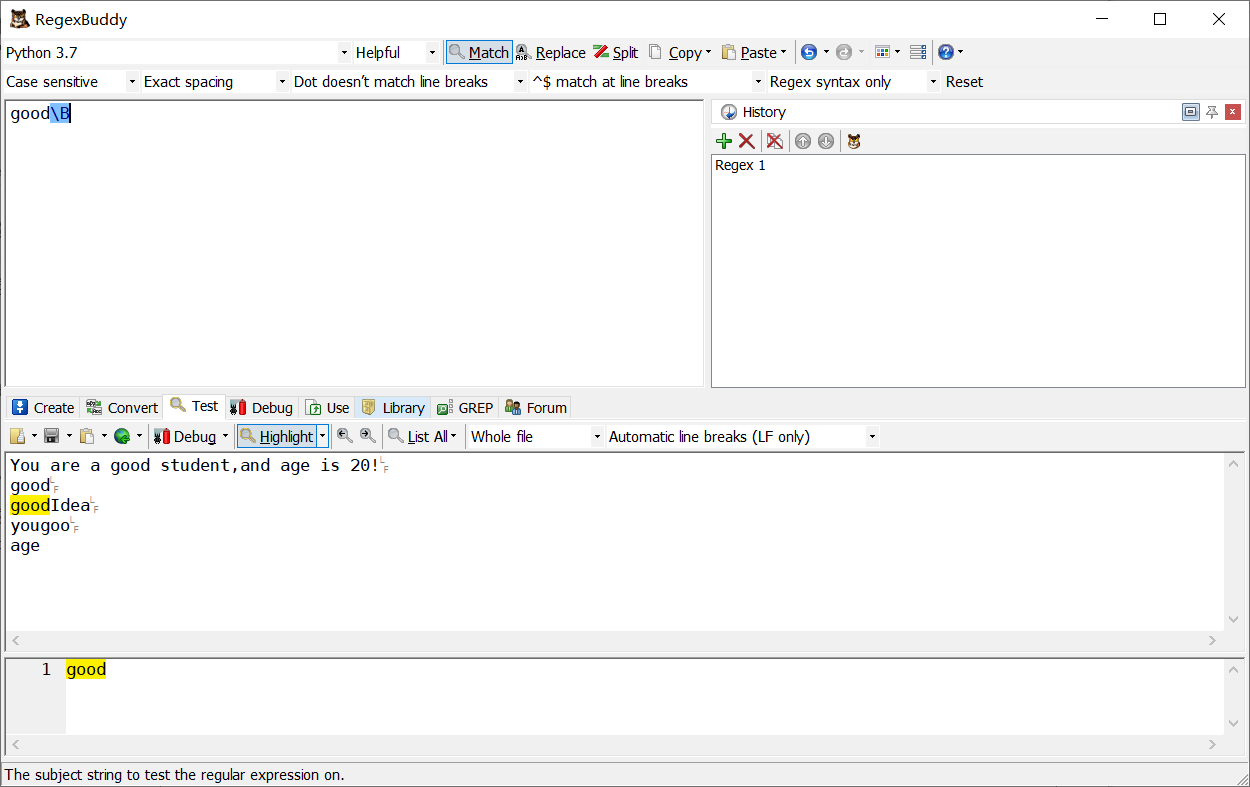
\d+
-
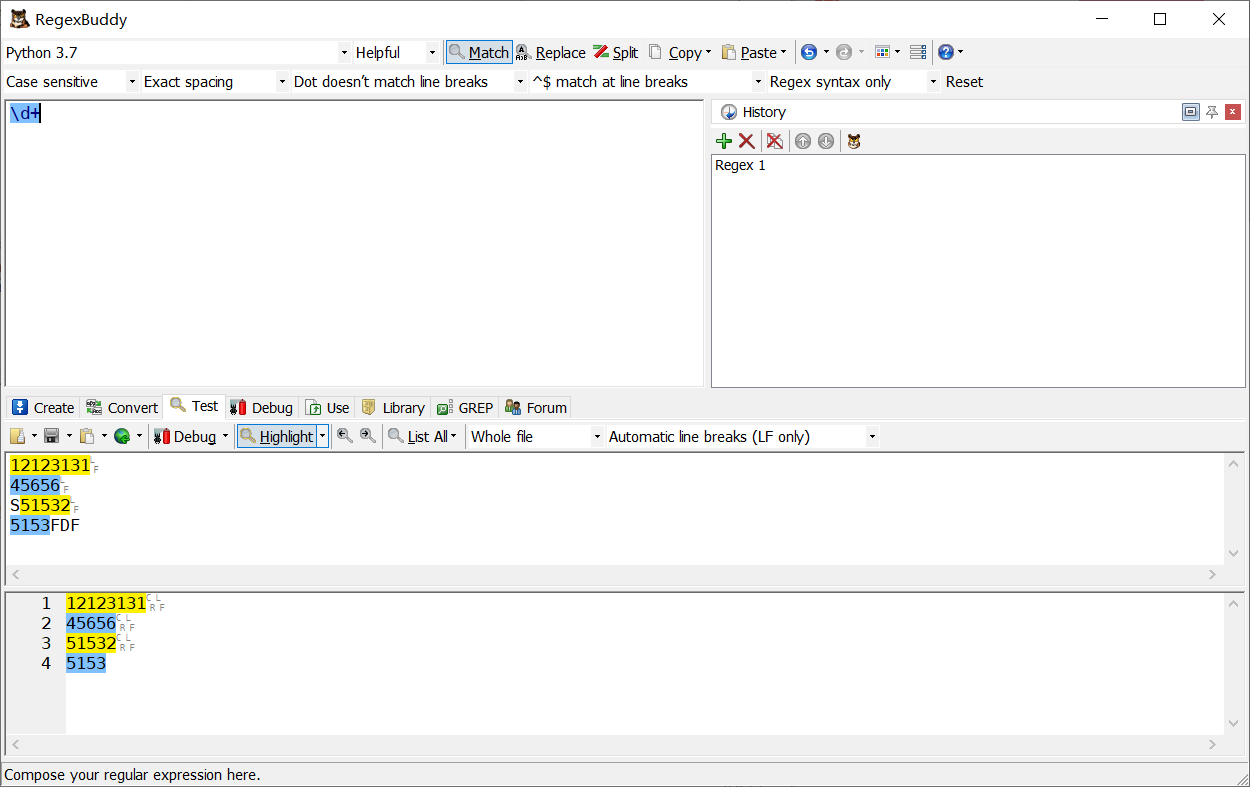
^\d+
-
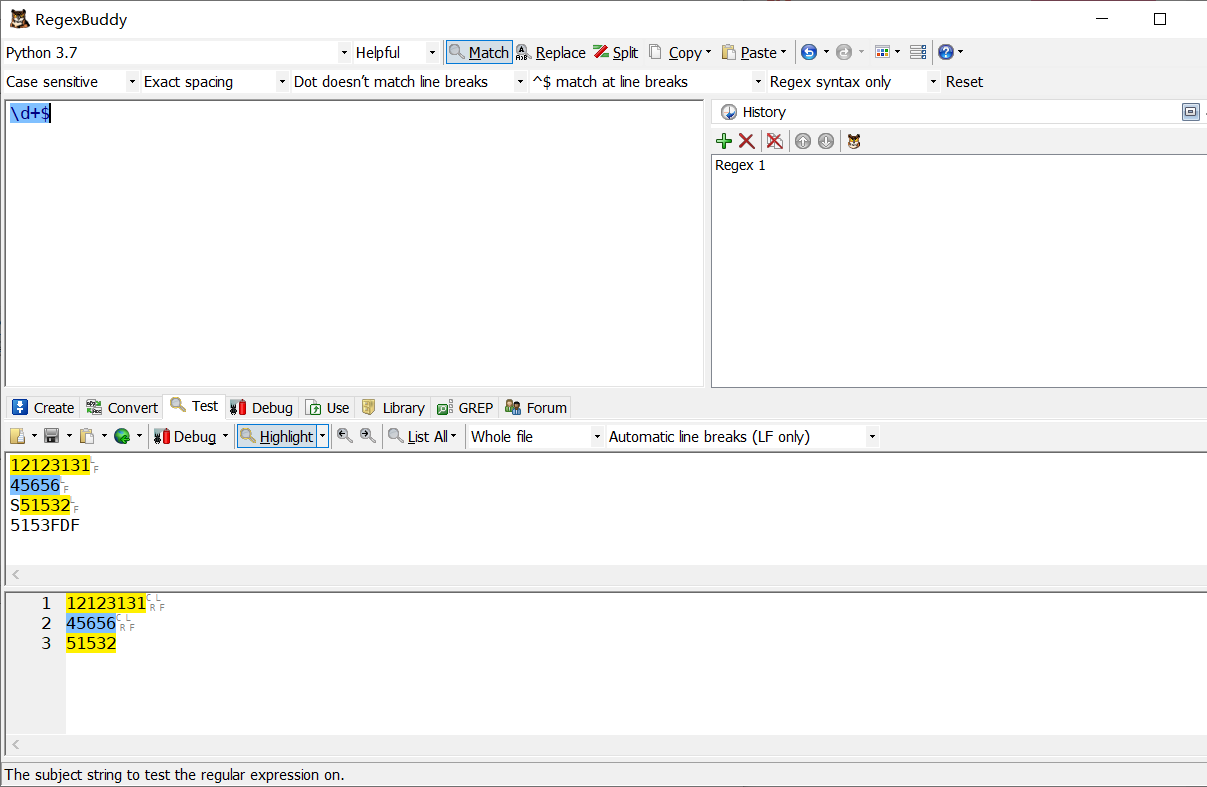
\d+$
-
^\d+$
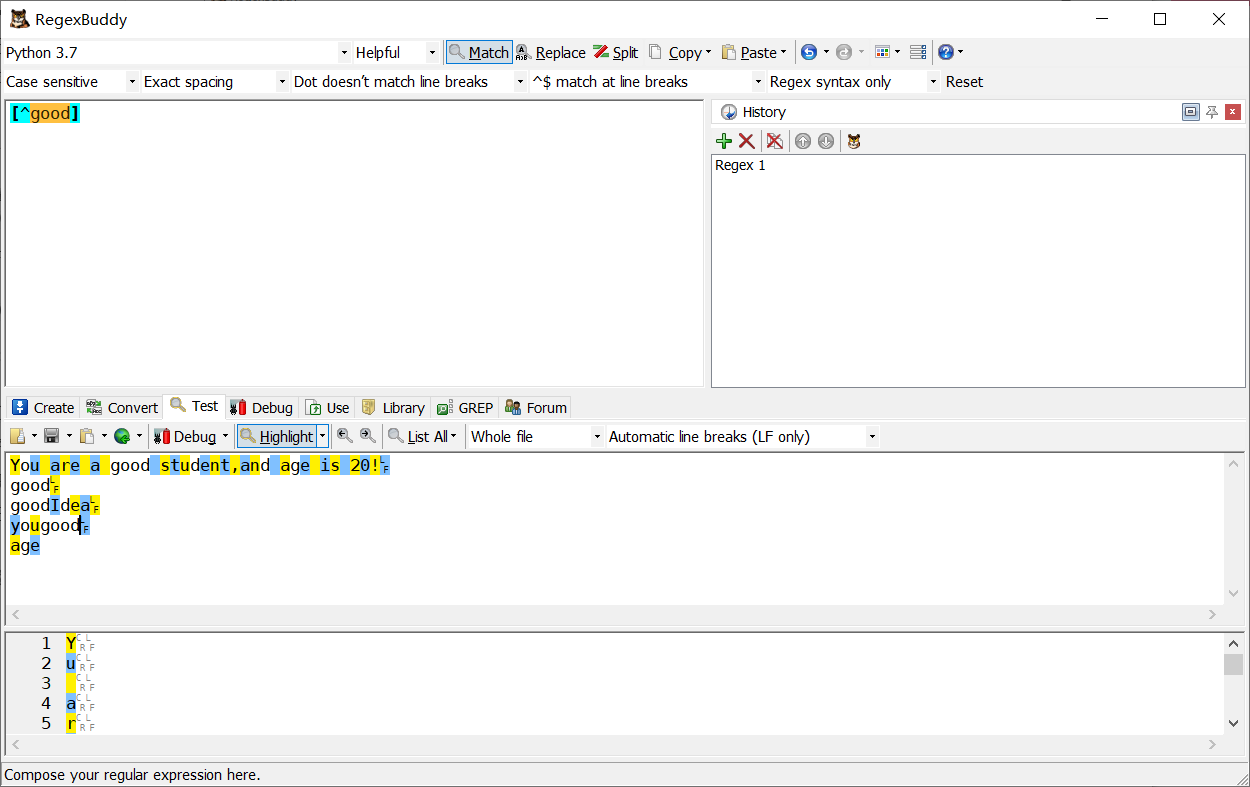
[^good] 匹配除了good以外的任意字符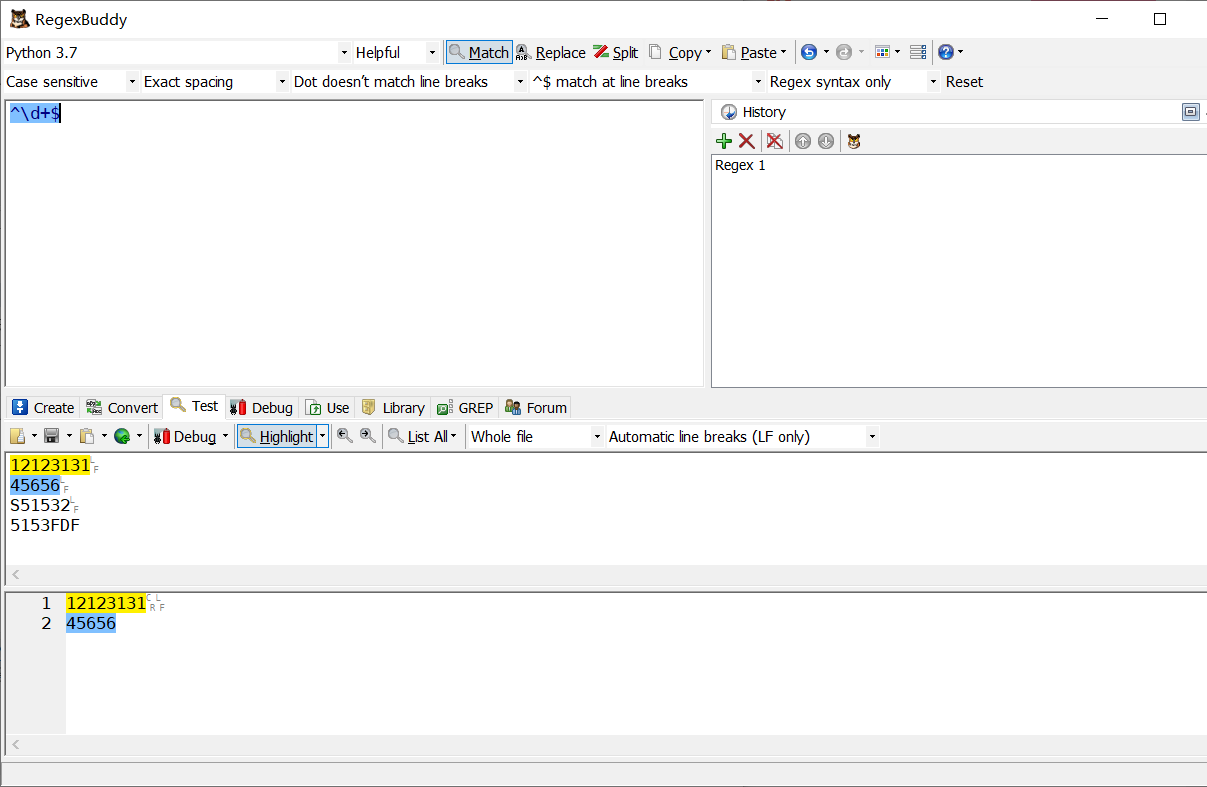
2.字符轉義
正則運算式中使用反斜杠 \ 來轉義下一個字符,這將允許你使用保留字符來作為匹配字符 { } [ ] / \ + * . $ ^ | ?,在特殊字符前面加 \,就可以使用它來做匹配字符, 例如正則運算式 . 是用來匹配除了換行符以外的任意字符,現在要在輸入字串中匹配 . 字符,正則運算式 (f|c|m)at\.?,表示: 小寫字母 f、c 或者 m 后跟小寫字母 a,后跟小寫字母 t,后跟可選的 . 字符,
3. 元字符
元字符是正則運算式的基本組成元素,元字符在這里跟它通常表達的意思不一樣,而是以某種特殊的含義去解釋,有些元字符寫在方括號內的時候有特殊含義, 元字符如下:
| 元字符 | 描述 |
|---|---|
| . | 匹配除換行符以外的任意字符, |
| [ ] | 字符類,匹配方括號中包含的任意字符, |
| [^ ] | 否定字符類,匹配方括號中不包含的任意字符 |
| * | 匹配前面的子運算式零次或多次 |
| + | 匹配前面的子運算式一次或多次 |
| ? | 匹配前面的子運算式零次或一次,或指明一個非貪婪限定符, |
| {n,m} | 花括號,匹配前面字符至少 n 次,但是不超過 m 次, |
| (xyz) | 字符組,按照確切的順序匹配字符xyz, |
| | | 分支結構,匹配符號之前的字符或后面的字符, |
| \ | 轉義符,它可以還原元字符原來的含義,允許你匹配保留字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 匹配行的開始 |
| $ | 匹配行的結束 |
.和*和?
-
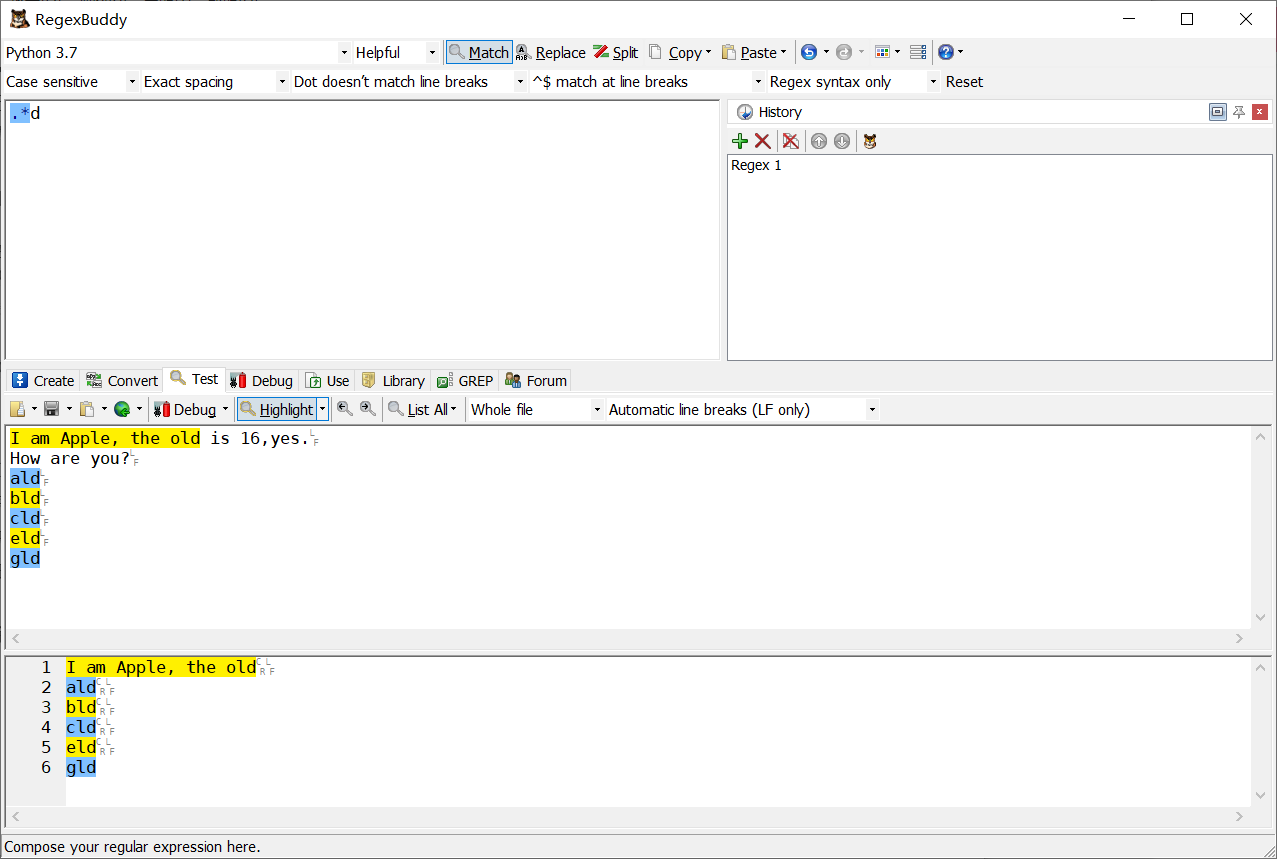
.*d 匹配以d結尾的字符
-
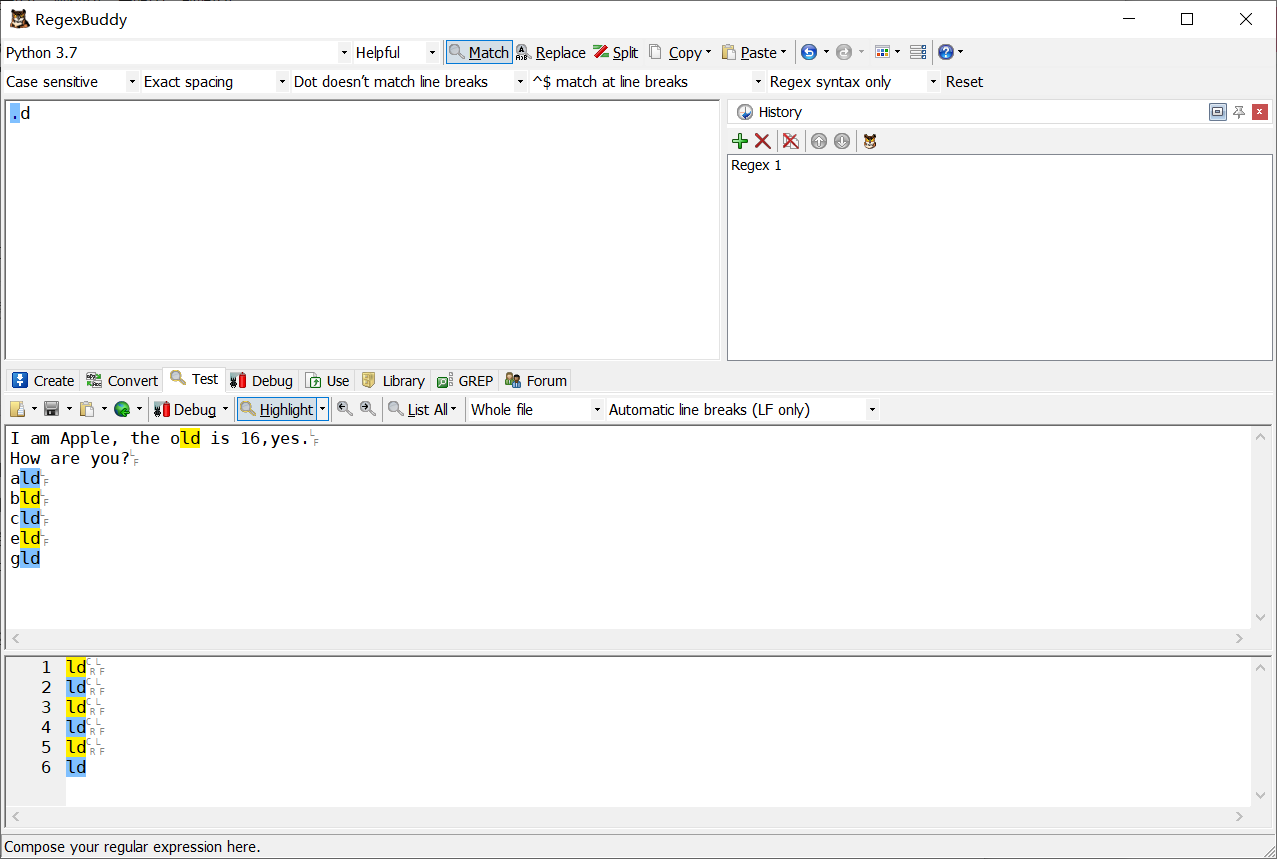
.d 匹配以d結尾的,并且包含他前面的一個字符
-
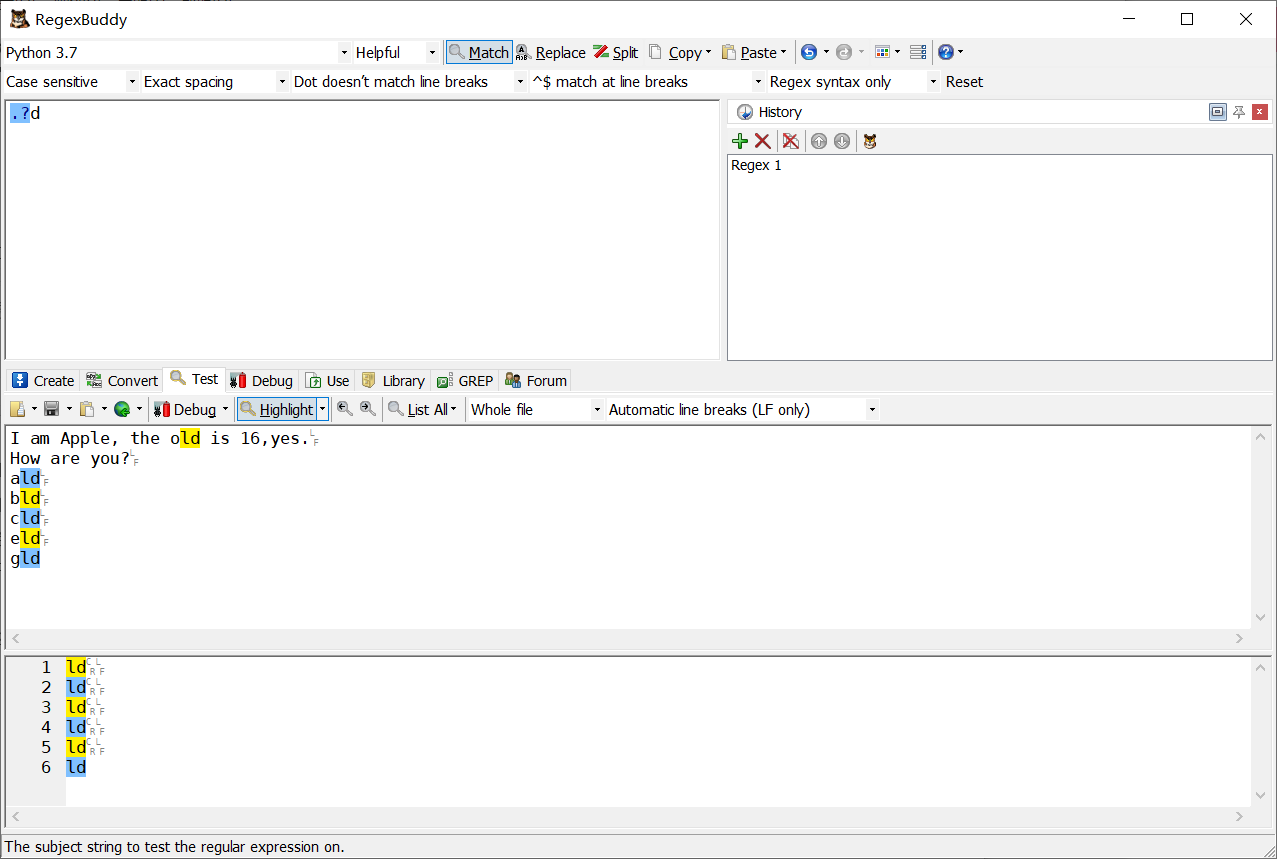
.?d 匹配以d結尾的,并且包含他前面的一個字符
-
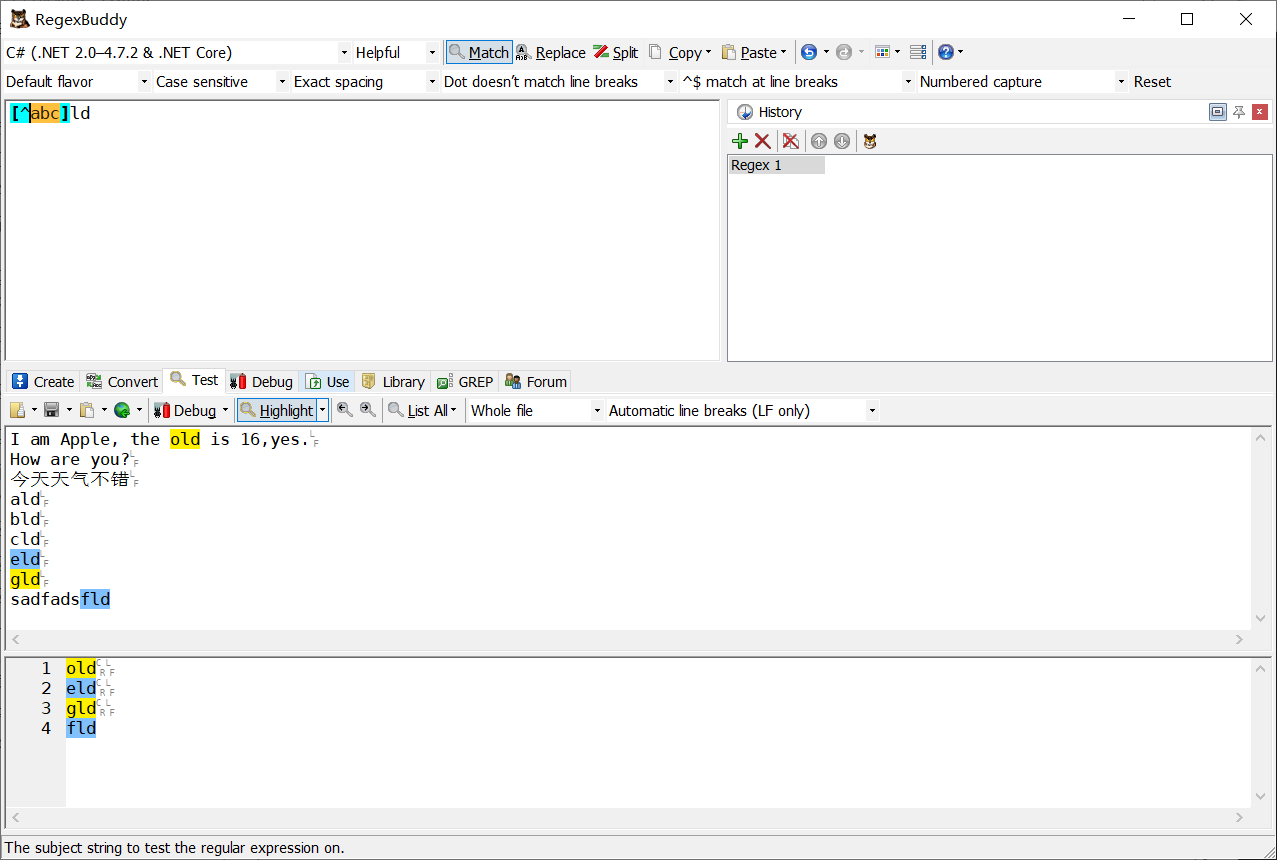
\b.?ld\b
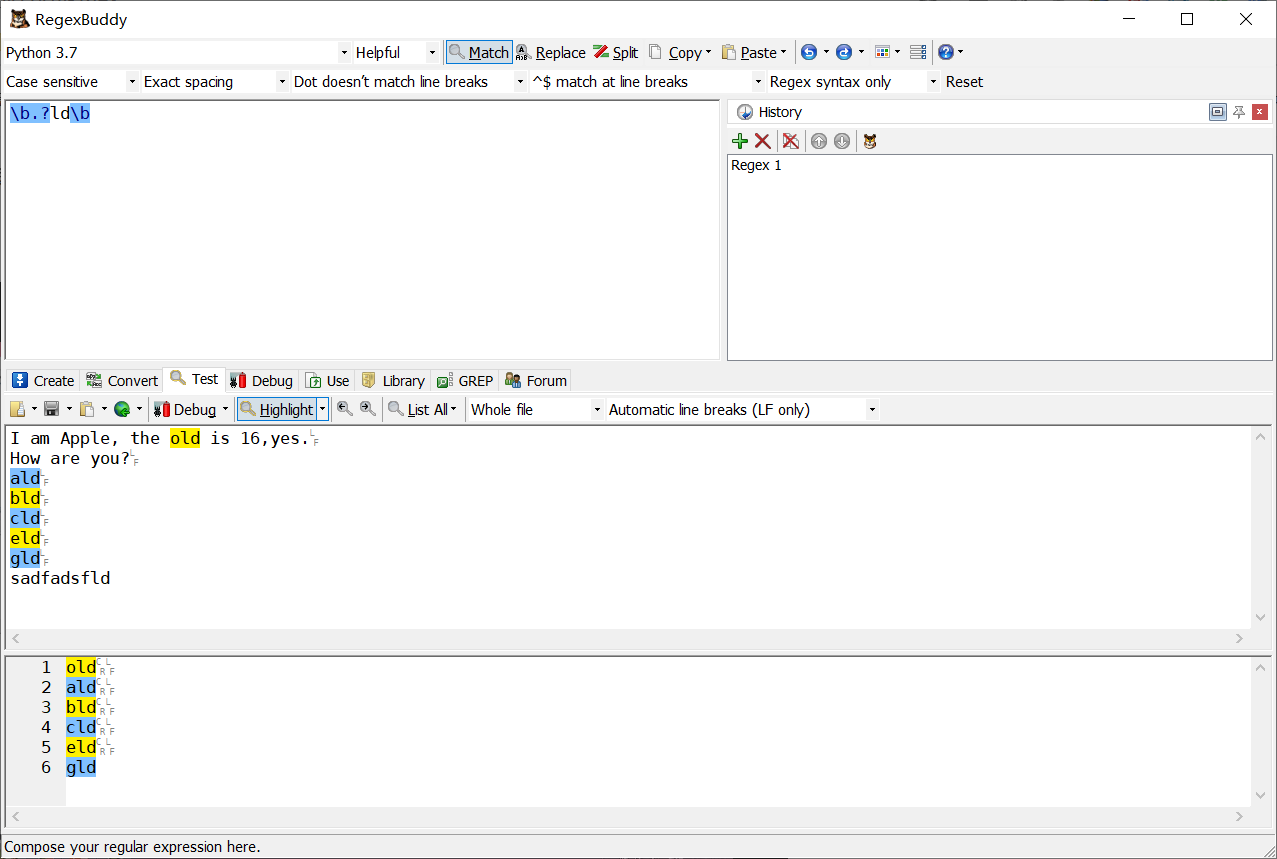
-
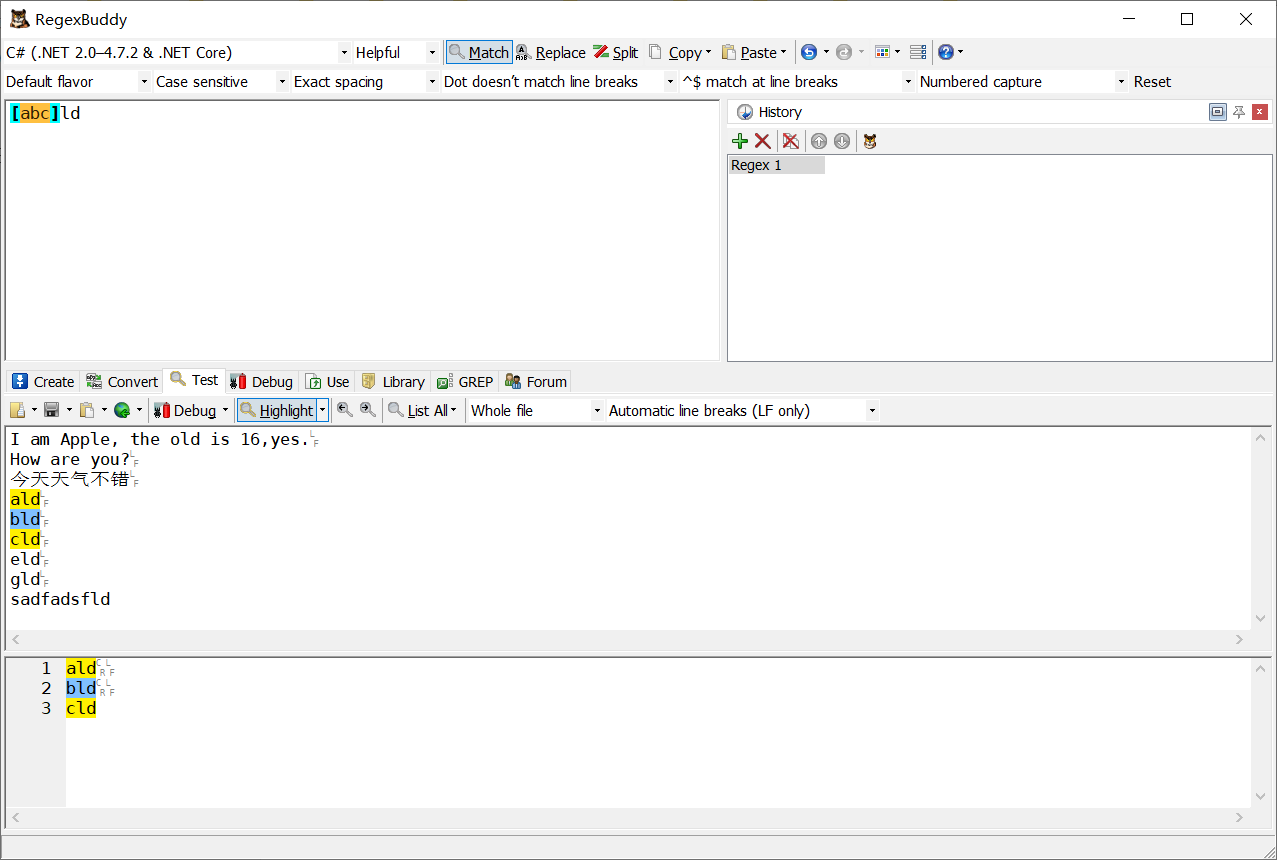
^.?ld$
解讀:^和$z做字符限定,.?ld表示匹配以ld結尾,前面只能有一個字符
[^x]
-
[abc]ld 匹配ld前面是以a、b、c開頭的
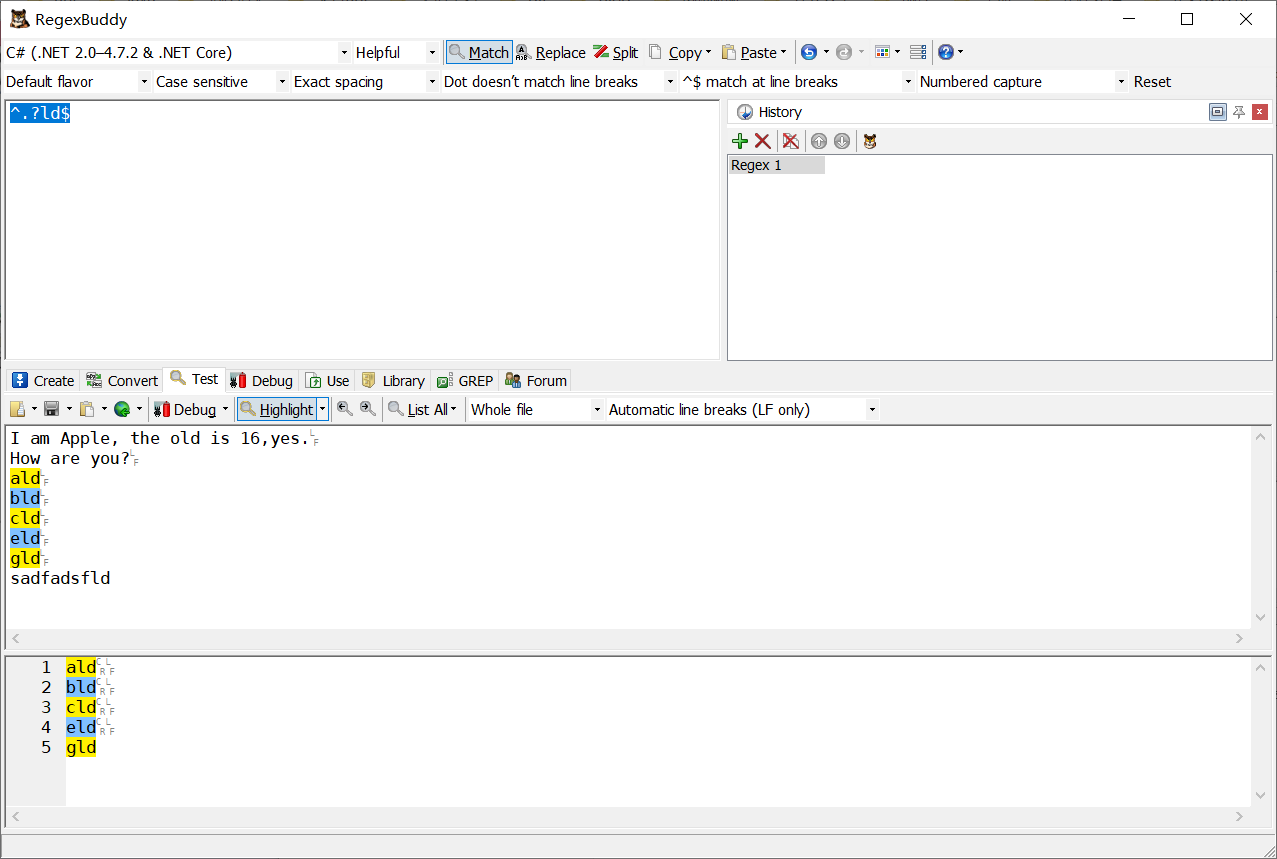
-
[^abc]ld 匹配ld前面是非以a、b、c開頭的
3.1.重復
以下元字符 +,* 或 ? 用于指定子模式可以出現多少次,這些元字符在不同情況下的作用不同,
3.1.1 星號
該符號 * 表示匹配上一個匹配規則的零次或多次,正則運算式 a* 表示小寫字母 a 可以重復零次或者多次,但是它如果出現在字符集或者字符類之后,它表示整個字符集的重復, 例如正則運算式 [a-z]*,表示: 一行中可以包含任意數量的小寫字母,
"[a-z]*" => The car parked in the garage #21.?
該 * 符號可以與元符號 . 用在一起,用來匹配任意字串 .*,該 * 符號可以與空格符 \s 一起使用,用來匹配一串空格字符, 例如正則運算式 \s*cat\s*,表示: 零個或多個空格,后面跟小寫字母 c,再后面跟小寫字母 a,再再后面跟小寫字母 t,后面再跟零個或多個空格,
"\s*cat\s*" => The fat cat sat on the cat.?
3.1.2 加號
該符號 + 匹配上一個字符的一次或多次,例如正則運算式 c.+t,表示: 一個小寫字母 c,后跟任意數量的字符,后跟小寫字母 t,
"c.+t" => The fat cat sat on the mat.?
3.1.3 問號
在正則運算式中,元字符 ? 用來表示前一個字符是可選的,該符號匹配前一個字符的零次或一次, 例如正則運算式 [T]?he,表示: 可選的大寫字母 T,后面跟小寫字母 h,后跟小寫字母 e,
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.?
例子
-
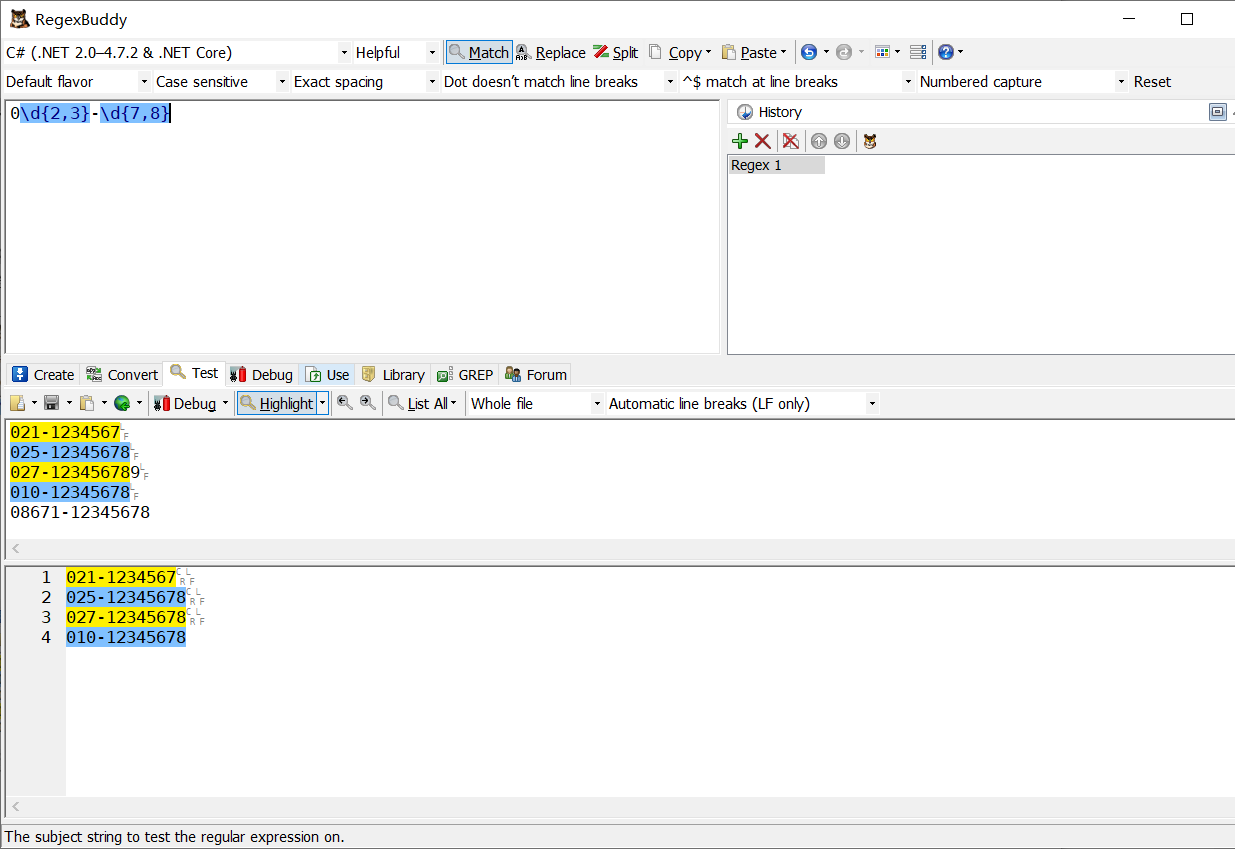
0\d{2,3}-\d{7,8}
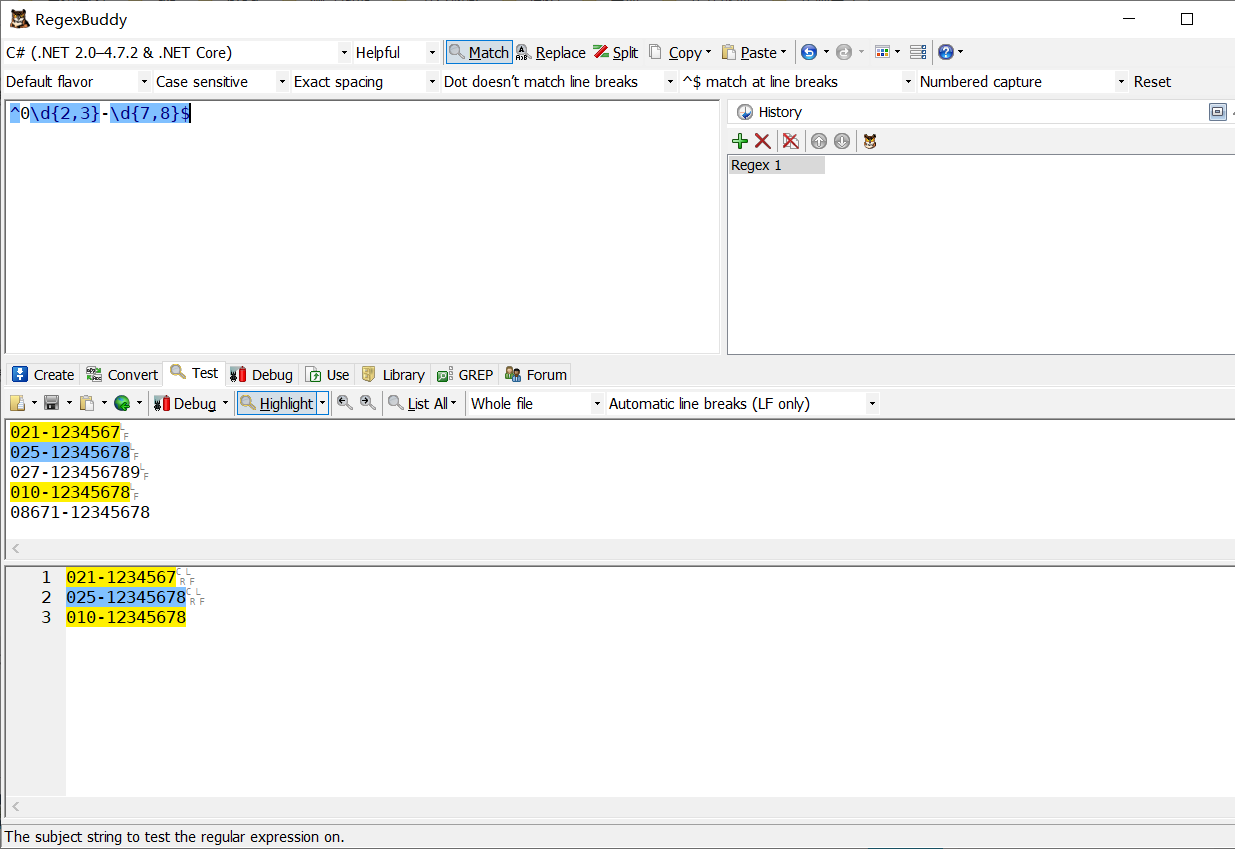
tip:我們會發現匹配的第二個號碼后面還有個9,那么我們該如何加上限定,不讓他匹配后面的呢,就用到了前面學的^和$,來看示例
tip:上面的例子確實匹配到了正確的號碼,但真實生活中的例子往往是每個地區的電話號碼寫法都不一樣,看下圖示例如何解決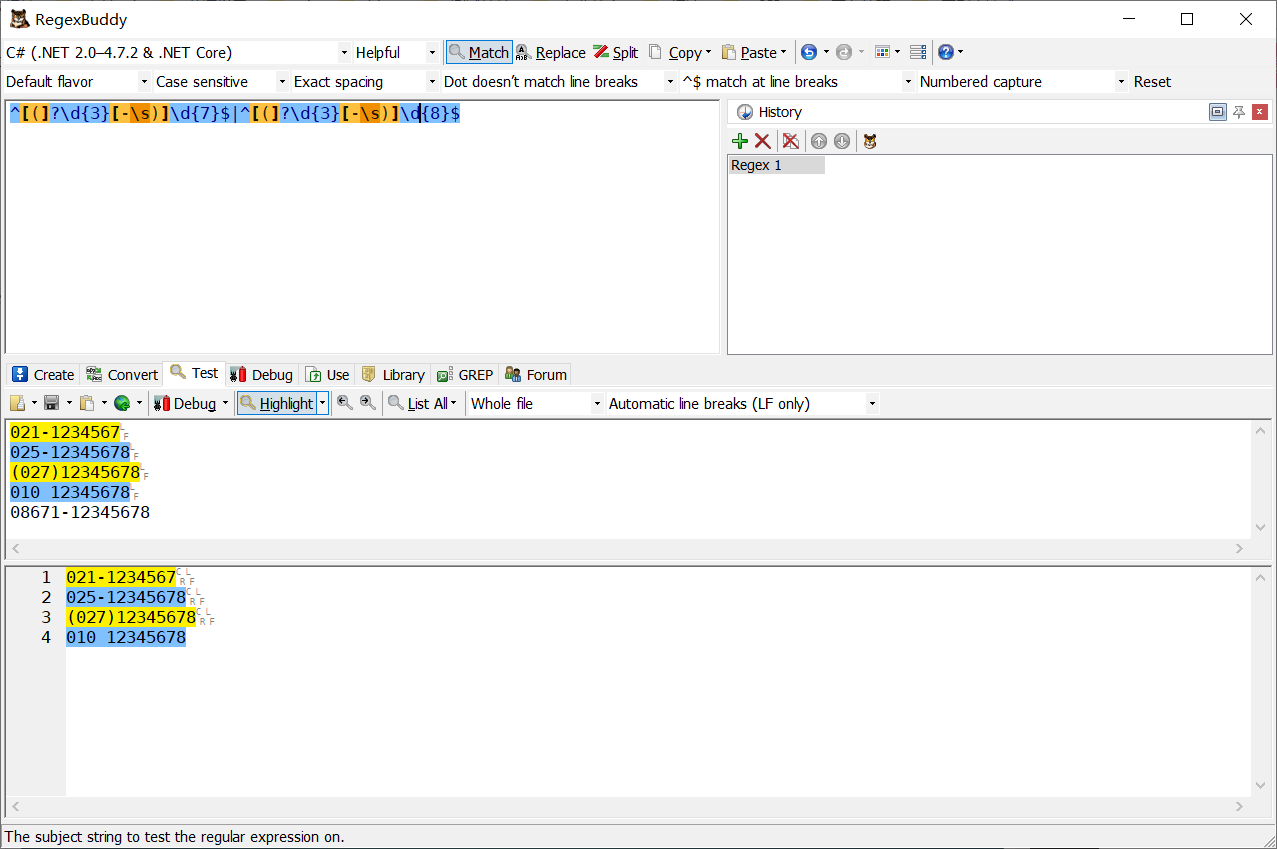
ps:上面的例子很多條件放到了一起,不利于閱讀,我們可以用分支來解決,符合其中任一一種正則即可,看下圖示例
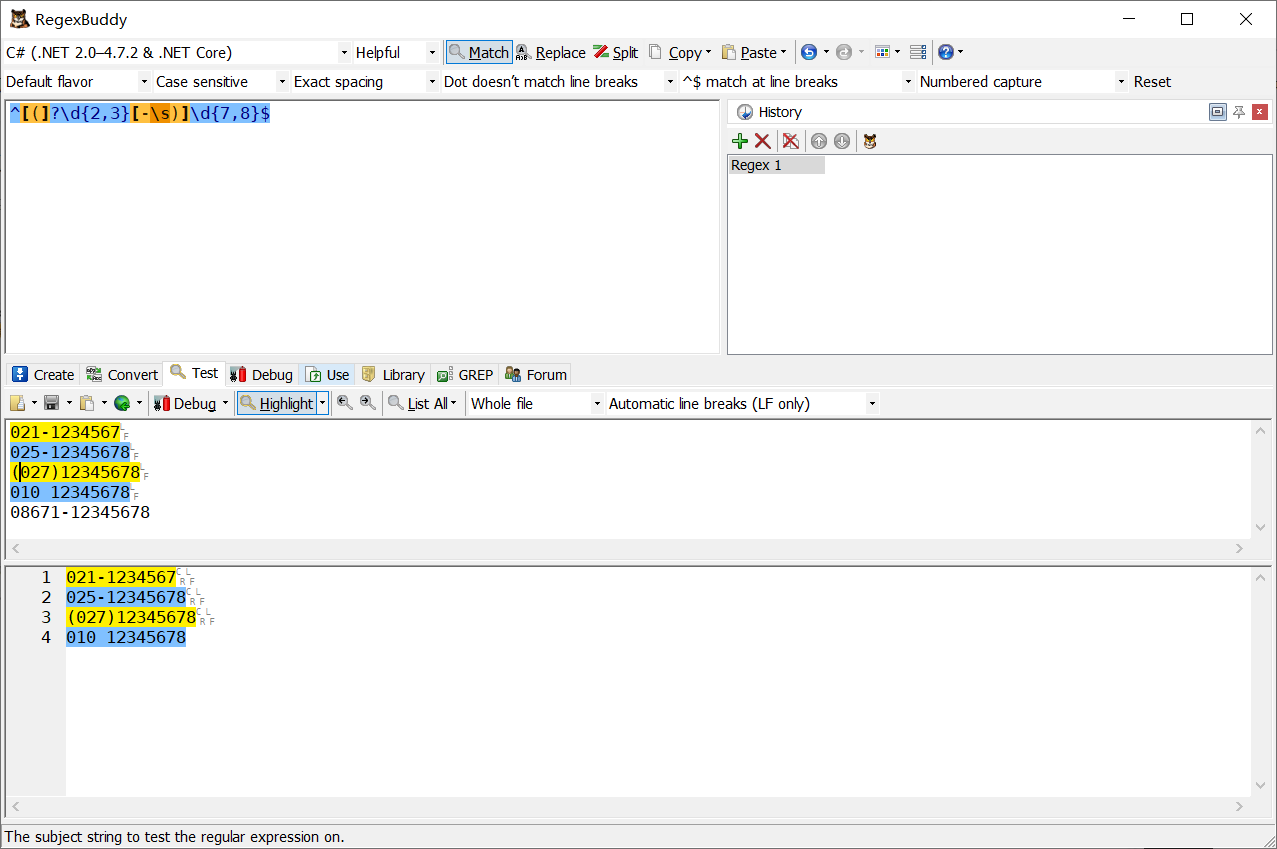
4.分組
將運算式進行做成子集
使用()進行分組
方便match的字串進行劃分
分組的命名:(?<groupname>exp)
(?:exp) 匹配exp,不捕獲匹配的文本,也不給分組分配組號
<div\s+md-end-block md-p">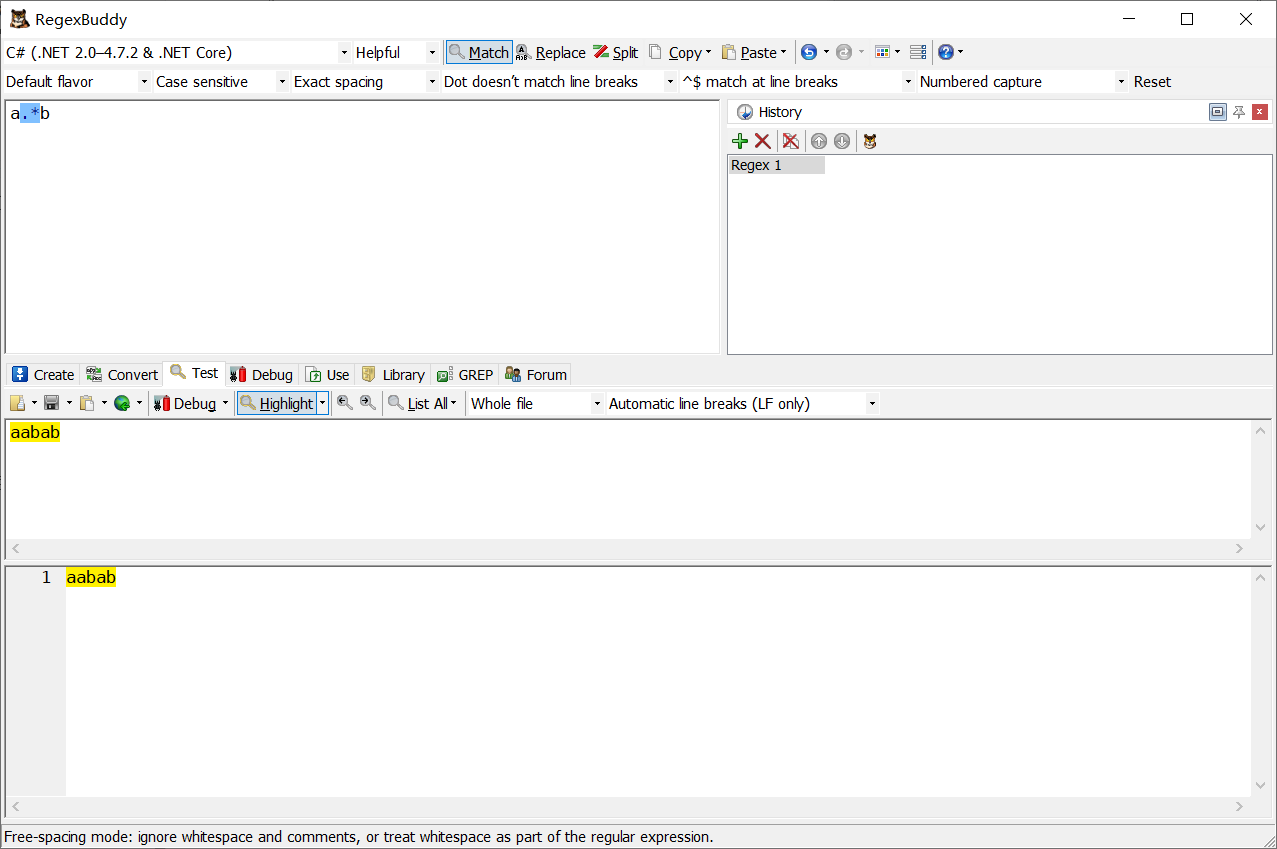
5.貪婪與懶惰
懶惰
語法 說明
*?
重復任意次,但盡可能少重復
+?
重復一次或更多次,但盡可能少重復
??
重復0次或更多次,但盡可能少重復
{n,m}
重復n次到m次,但盡可能少重復
{n,}
重復n次以上,但盡可能少重復
-
貪婪
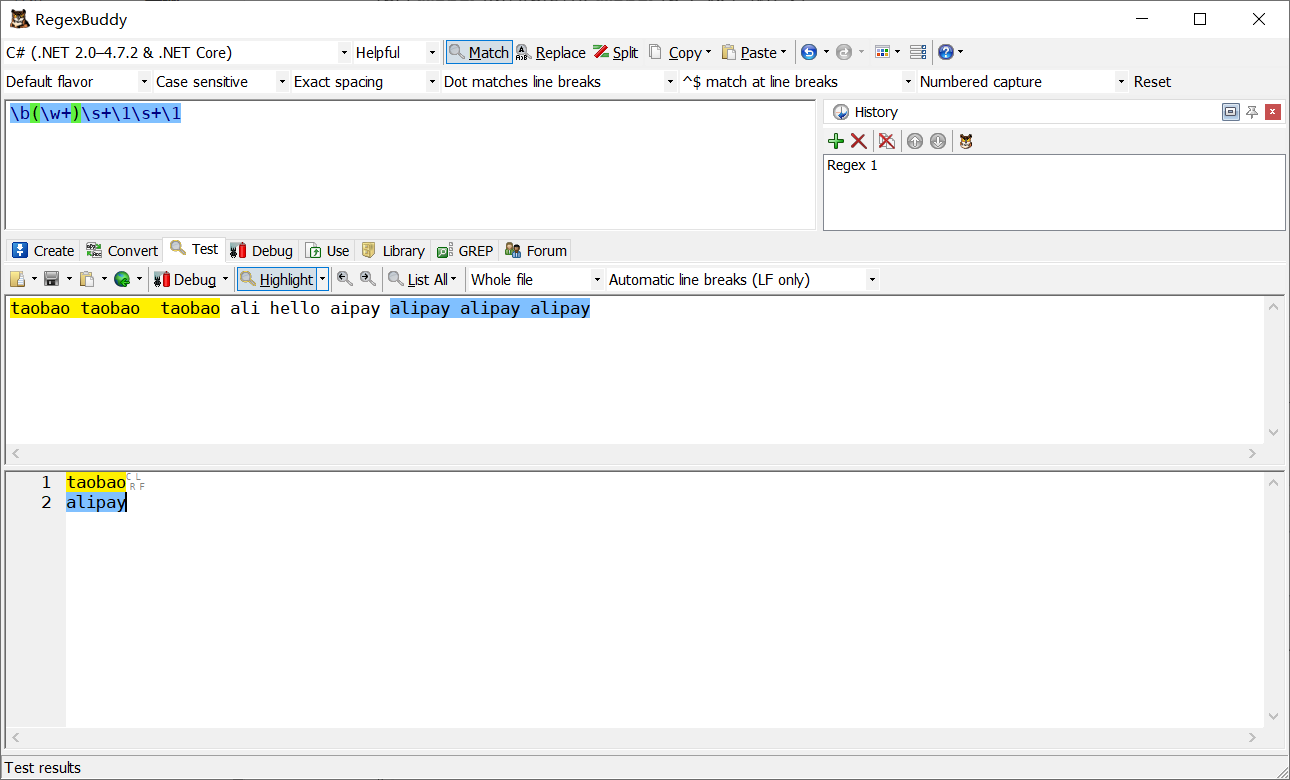
所謂貪婪就是盡可能多的匹配,它遇到第一個b不結束,遇到最后一個b才結束
-
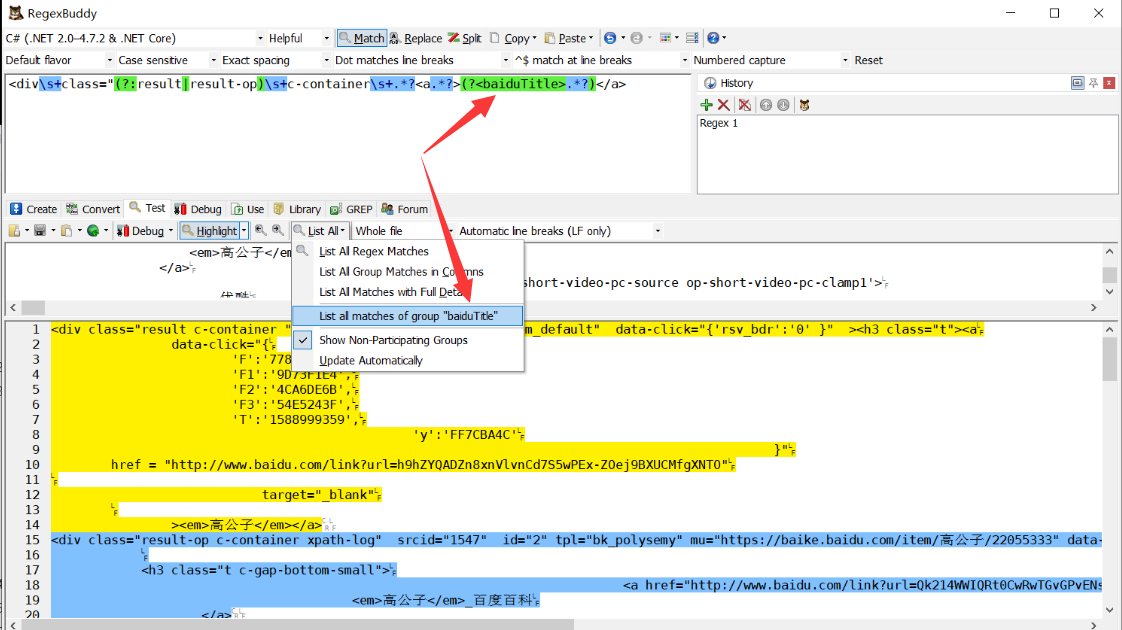
懶惰
遇到個b就匹配成功
6.處理選項
語法 說明
IgnoreCase
匹配時不區分大小寫
Multiline
更改^和$的含義,是它們分別在任意一行的行首和行尾匹配,而不僅僅在整個字串的開頭和結尾匹配,(在此模式下,$的精確的含義是:匹配\n之前的位置以及字串結束前的位置)
Singleline
更改.的含義,使它與每一個字符匹配(包括換行符\n)
IgnorePatternWhitespace
忽略運算式中的非轉義空白并啟用由#標記的注釋
ExplicitCapture
僅捕獲已被顯式命名的組
7.反向參考
匹配taobao taobao,home home 這樣的情況
\b(\w+)\b\s+\1\b
\b(?<Word>\w+)\b\s+\k<Word>\b 命名后的寫法
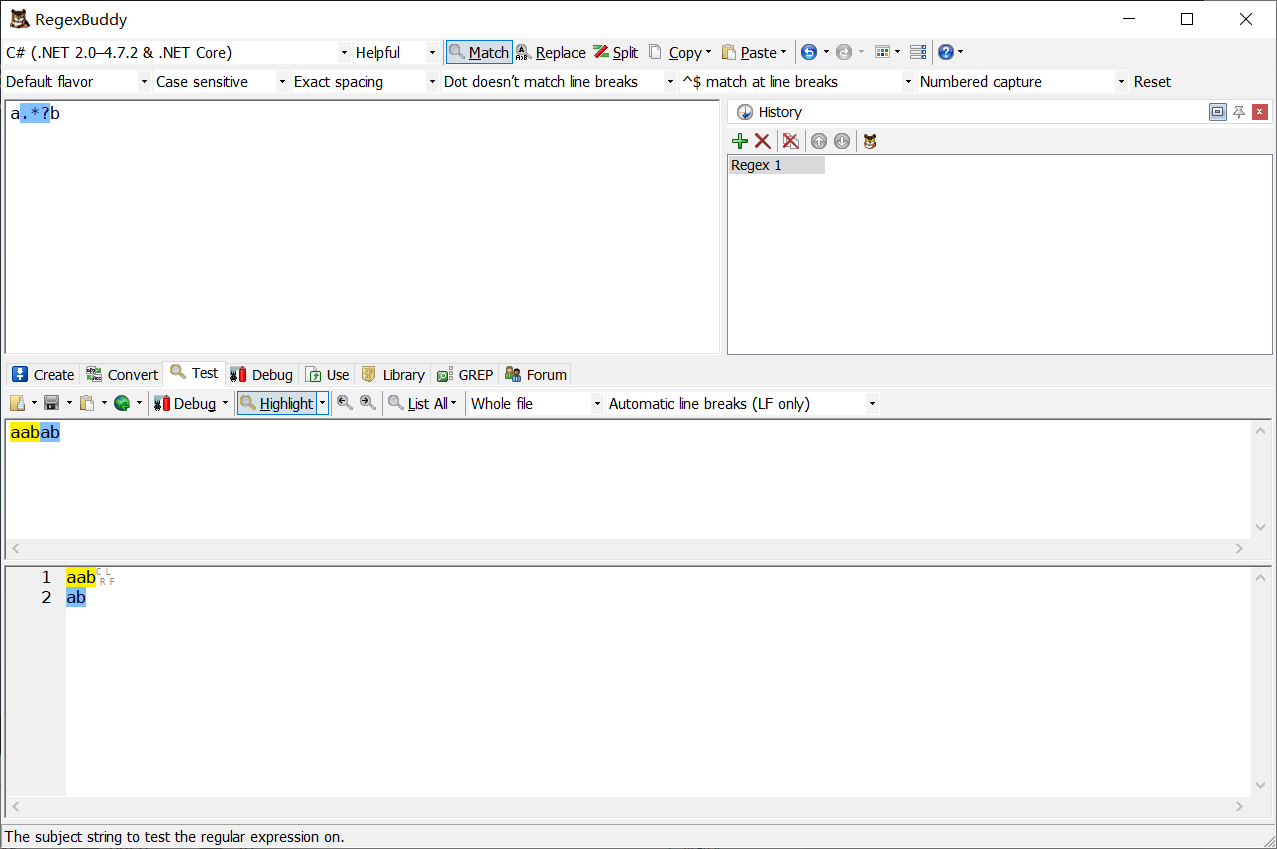
例一:
\b(\w+)\b\s+\1\s+\1
8.零寬斷言
正向零寬斷言
?=exp 零寬度正預測先行斷言,自身出現的位置的后面能匹配運算式
exp
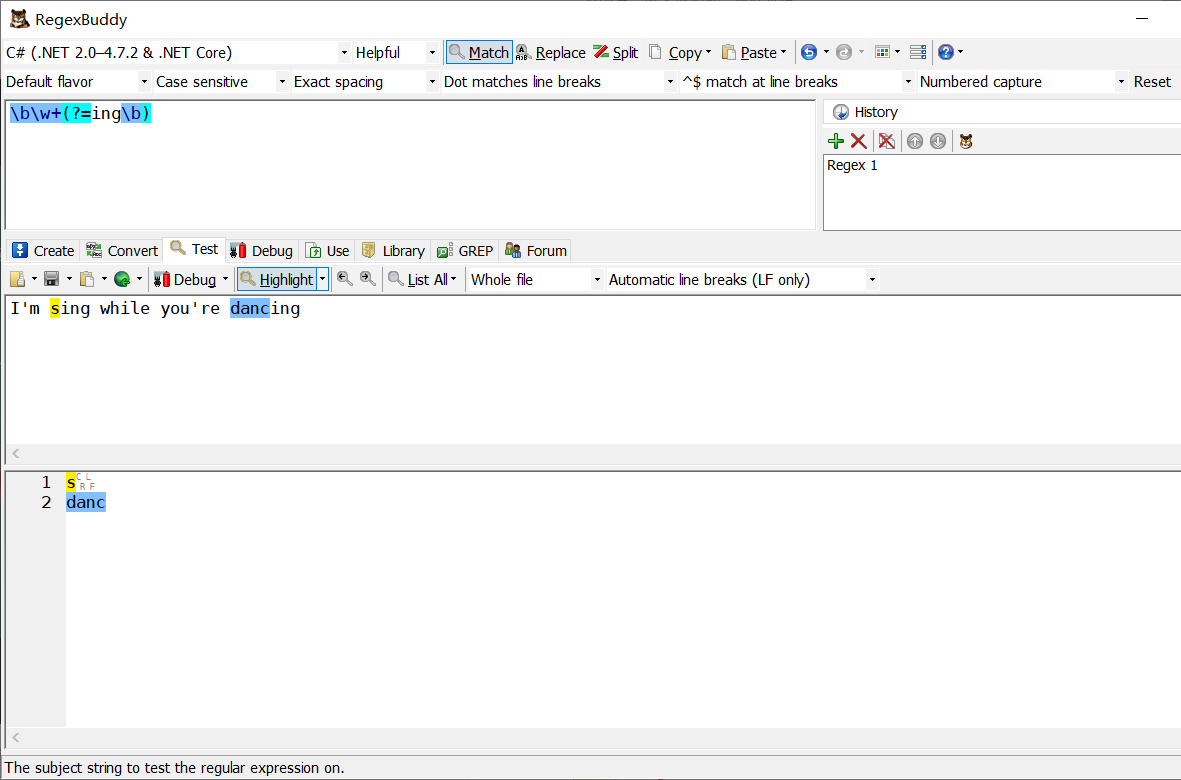
\b\w+(?=ing\b)
零寬度正回顧后發斷言
?<=exp 零寬度正回顧后發斷言,自身出現的位置的前面能匹配運算式
exp
<?<=\bre>\w+\b
負向零寬斷言
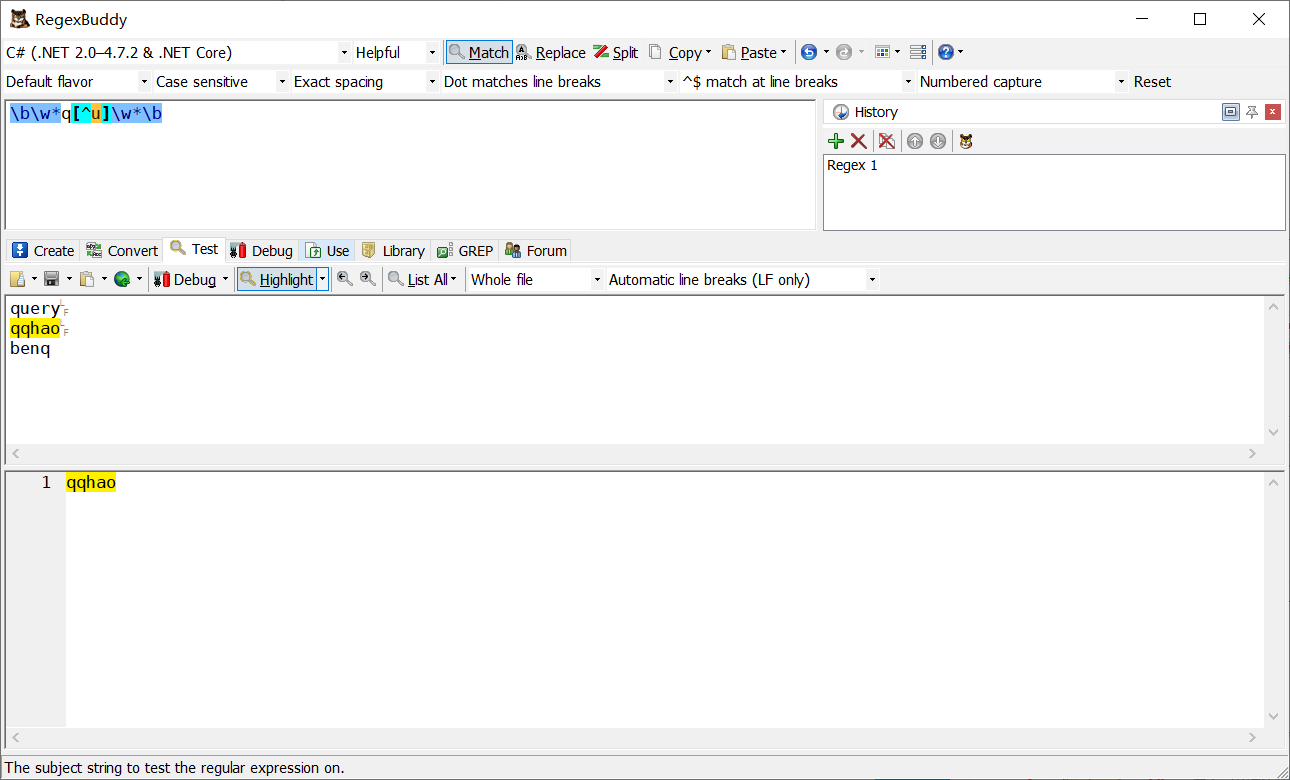
查找這樣的單詞,它里面出現了字母q,但q后面跟的不是字母u
不用斷言的方式
\b\w*q[^]\w*\b
使用斷言 不消費任何字符
例一:
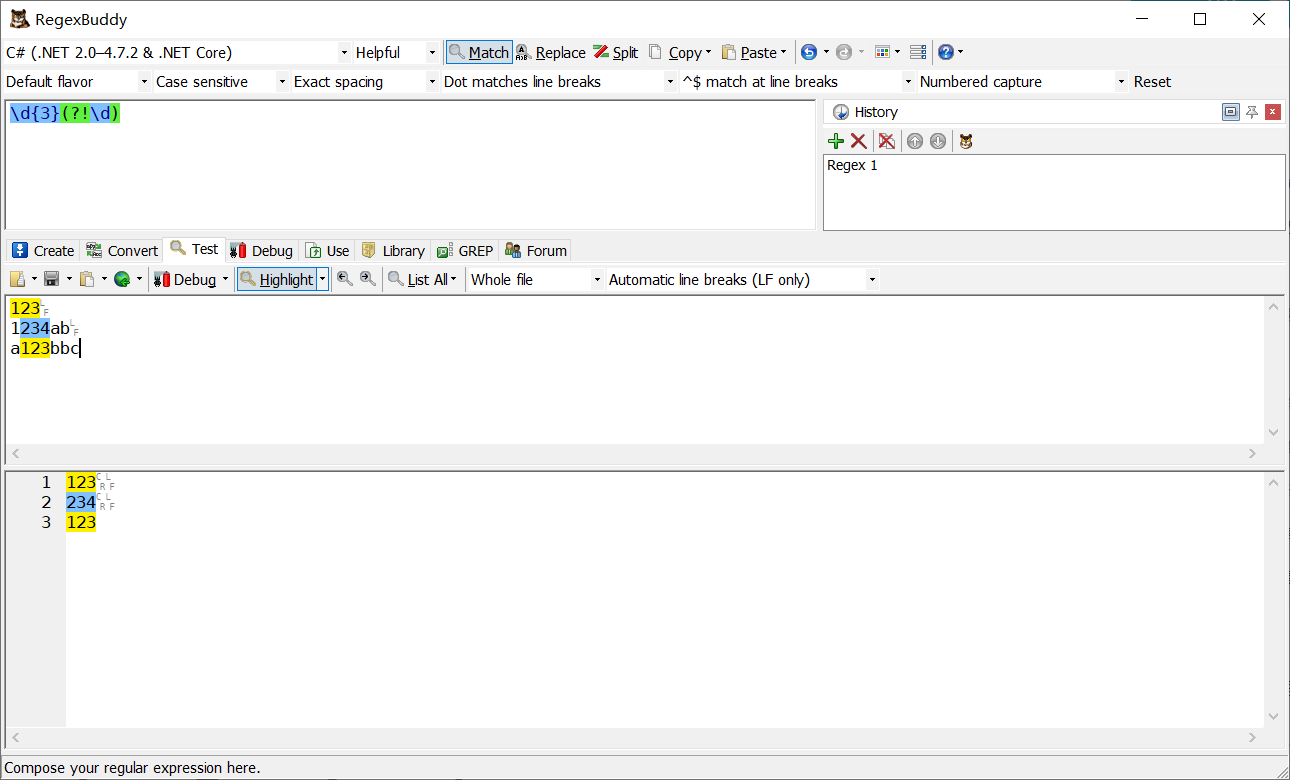
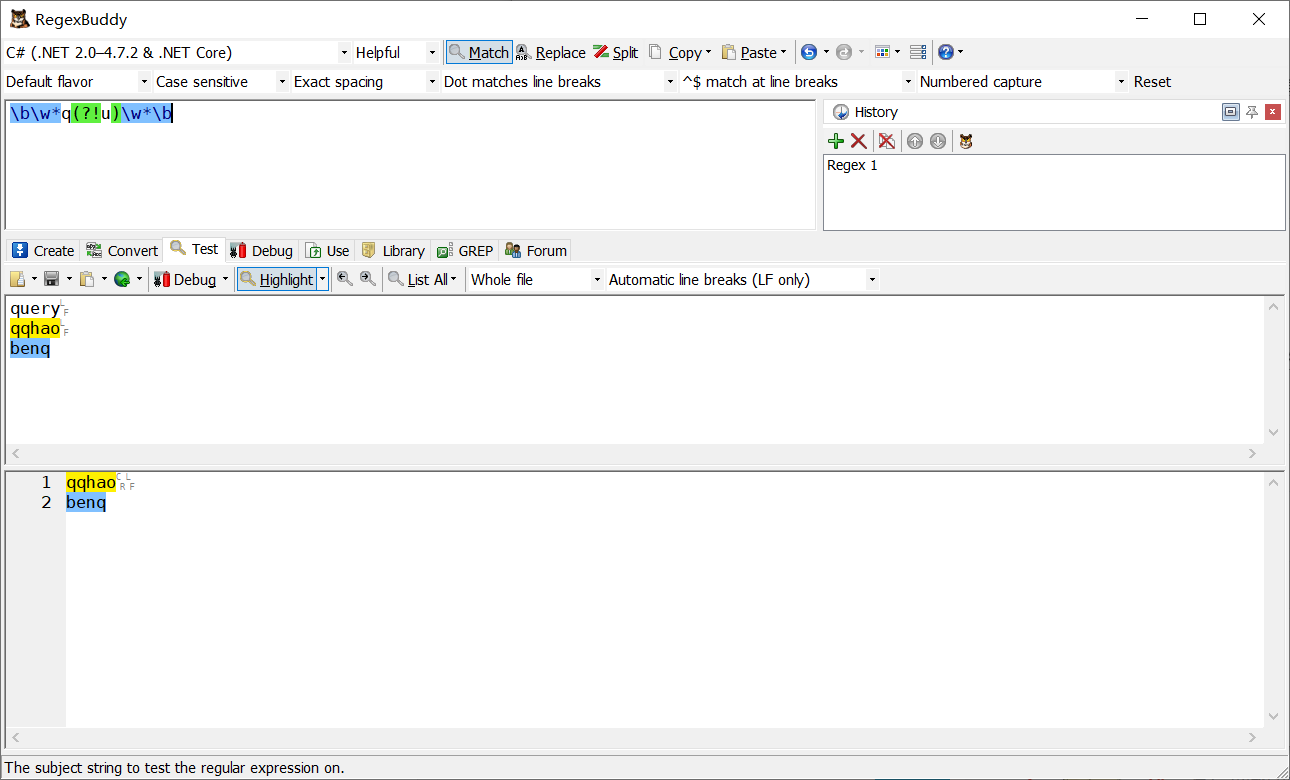
\b\w*q(!u)\w\b
例二:前面三位是數字,后面不能是數字
\d{3}(?!\d)
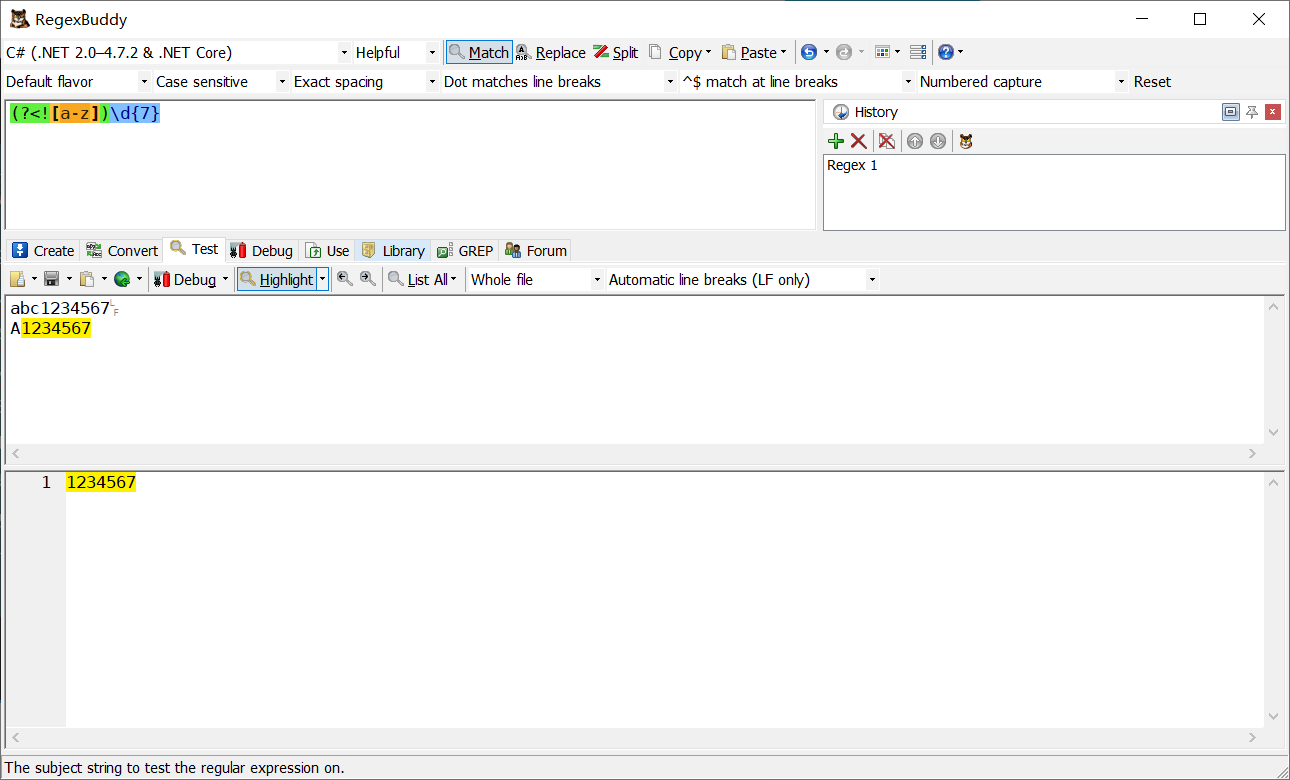
零寬度負回顧后發斷言
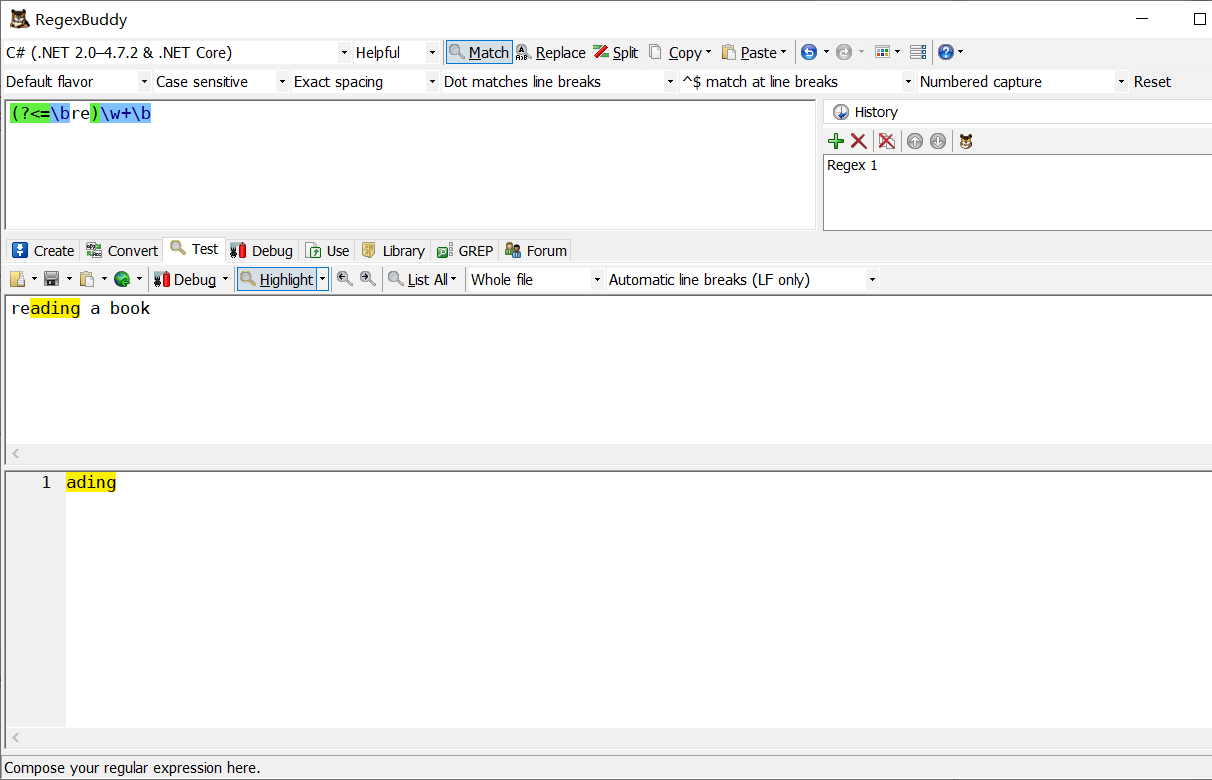
例一:前面不是小寫字母的7位數字
(?<![a-z])\d{7}
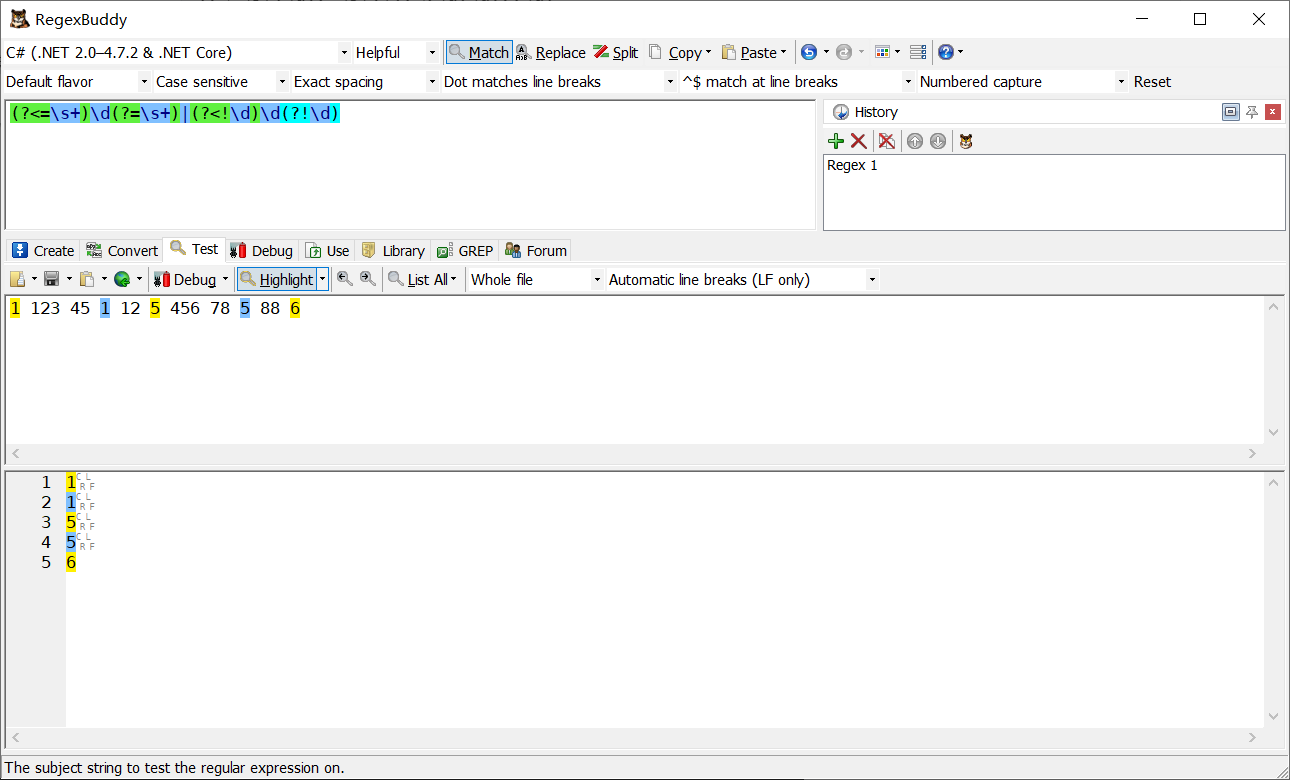
斷言綜合示例
例一:找出所有個位數
(?<=\s+)\d(?=\s+)|(?<!\d)\d(?!\d)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79439.html
標籤:其他
上一篇:大佬們,請教下FPN inference.py程式的多執行緒運行問題。
下一篇:小白求解:Scrapy 問題,scrapy stratproject XXX?知道怎么解決但不懂為什么出現這問題