作者:凌逆戰
地址:https://www.cnblogs.com/LXP-Never/p/12051532.html
波束成型(Beamforming)又叫波束賦形、空域濾波
作用:對多路麥克風信號進行合并處理,抑制非目標方向 的干擾信號,增強目標方向的聲音信號,
原理:調整相位陣列的基本單元引數,使得某些角度的信號獲得相長干涉,而另一些角度的信號獲得相消干涉,對各個陣元輸出信號加權求和、濾波,最終輸出期望方向的語音信號,相當于形成一個“波束”,
遠場:由于信號源到陣列的距離遠大于陣元間距,不同陣元接收信號的幅度差異較小,因此把不同陣元采集的語音信號的幅值認為都是一樣的,只需對各陣元接收信號的相位差異進行處理即可,
近場:不同陣元接收到的信號幅度受信號源到各陣元距離差異的影響非常明顯,需考慮信號源到達不同陣元的波程差,
問題:
- 通常的陣列處理多為窄帶,使得傳統的窄帶信號處理方法的缺點逐漸顯現出來,語音信號的頻率范圍為300~3400Hz,沒有經過調制程序,且高低頻相差比較大,不同陣元的相位延時與聲源的頻率關系密切,使得現有的窄帶波束形成方法不再適用
- 信噪比比較低和混響影響比較高的環境下難以準確估計波達方向
- 傳統的后置濾波只考慮散射噪聲或只從波束形成后的單通道輸出中估計噪聲不足
根據獲取加權矢量時采用的方法不同,可將波束形成方法分為三類:
- 和參考信號資料無關的波束形成方法,如常規波束形成方法,這種波束形成方法通過加權取平均得到固定的陣列輸出回應,陣列輸出不受信號資料變化的影響;
- 使用最佳權矢量的波束形成方法,這類方法依賴于對陣列接收資料統計特性的估計,如最大信噪比準則;
- 可根據接收資料變化自適應地改變權矢量的波束形成方法,如最小方差無畸變回應(MVDR)波束形成、LMS演算法、遞推最小二乘(RLS)演算法、采樣矩陣求逆(SMI)演算法等,
寬帶波束形成主要分為時域方法和頻域方法,
- 時域方法:對每個支路進行合適的延時,對各陣元上接受信號的時間進行補償,使信號到達基陣時可以等效為是同一波面同時到達各陣元;
- 頻域方法:首先將寬帶信號在頻域分解為若干個子帶,對子帶信號進行窄帶波束形成后,通過合成得到寬帶波束輸出,
由于時域方法受到采樣精度的限制,多用于處理低頻信號,處理高頻信號更多采用頻域方法,
麥克風陣列信號處理通常由 自適應波束形成 和 后置濾波 兩個部分組成,
在自適應波束形成和后置濾波中,準確的估計導向矢量和噪聲功率譜密度十分的關鍵,在導向矢量可估計的條件下,常用的波束形成演算法包括延遲相加、最小方差無失真回應和廣義旁瓣相消器,最簡單的導向矢量估計是利用波達方向資訊,除此之外,S. Gannot利用語音信號的非平穩性計算相對傳遞函式作為導向矢量,A. Krueger使用廣義特征值分解得到的最大特征向量估計傳遞函式作為導向矢量,基于最小均方誤差幅度譜估計和對數幅度譜估計是應用最為廣泛的單通道語音增強演算法之一,準確地跟蹤噪聲可以避免語音失真或噪聲殘余,常用的噪聲跟蹤演算法有最小值跟蹤演算法和最小值控制遞回平均演算法,
基本原理分析
對與麥克風陣列而言,由于各個麥克風的分布位置不同,陣元接收的語音信號會存在一定的時間差,利用這一資訊可以確定聲源的方向和位置,
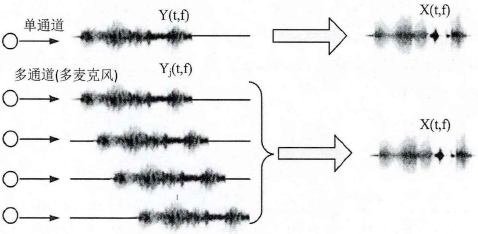
通過對齊各個通道的信號,相位差異可以將干擾部分抵消掉,增強目標語音信號,
常規波束形成演算法研究
麥克風信號以均勻線性模型為例
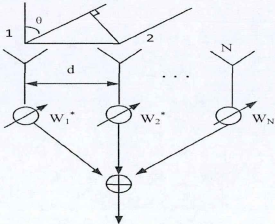
窄帶信號模型表示為
$$\begin{array}{l}{x_{1}(t)=s(t) e^{j \omega t}} \\ {x_{2}(t)=s(t) e^{jwt} d^{j \frac{2 \pi}{\lambda} d \sin \theta}} \\ {\cdots \cdot} \\ {x_{N}(t)=s(t) e^{j \omega t} d^{j \frac{2 \pi}{\lambda}(N-1) d \sin \theta}}\end{array}$$
將上式寫為矩陣形式
$$X(t)=\left[\begin{array}{c}{x_{1}(t)} \\ {x_{2}(t)} \\ {\dots . .} \\ {x_{N}(t)}\end{array}\right]=s(t) e^{j \omega t}\left[\begin{array}{l}{1} \\ {e^{j \frac{2 \pi}{\lambda} d \sin \theta}} \\ {\cdots} \\ {\frac{2 \pi}{\lambda}(N-1) d \sin \theta}\end{array}\right]=s(t) a(\theta)$$
其中,$a(\theta )$為方向矢量或者導向矢量,波束形成后的輸出語音信號$y(t)$為$M$個通道經處理后的接收信號加權之和,
$$y(t)=\sum_{i=1}^{M} w_{i}^{H}(t) x_{i}(t)=w^{H} x=s(t) w^{H} a(\theta)$$
其中,$w=[w_1,w_2,...,w_N]^T$表示波束形成器的權值向量,$T$表示轉置,$H$表示共軛轉置,
因此,多通道波束形成是對各個麥克風通道接收信號進行加權重因子系數調節并相加的程序,對各個陣元來說,信號在一瞬間的幅值相同,使用不同的權矢量$w$作加權處理,一般只做信號的相位調整,不做幅度改變,由此可知,如果空間中僅存在一個$\theta _k$方向的波信號,其導向矢量為$a(\theta_k)$,當權重矢量取$w=a(\theta_k)$時,則輸出信號最大值$y(n)=a(\theta_k)^Ha(\theta_k)=M$,這時陣列各路信號加權相干疊加,為經典的固定波束形成 (Fixed Beamforming),
- 優點:低計算復雜度、易于實作;在非相干噪聲場環境下應用較多,
- 缺點:在相關噪聲場,存在混響等情況下效果不是很好
無論是直接相加還是采用加不同窗函式的形式它們的權系數都是固定的,因此,要達到較好的效果需要依靠増加麥克風數量,這樣會導致成本和資源消耗的增加,而且適應性也比較差,
延遲求和波束形成 (DSB)
延遲求和波束形成 (Delay and Sum Beamforming, DSB)
原理:首先對不同麥克風信號之間的相對延遲進行補償,然后疊加延時后的信號形成一個單一的輸出,
缺點:
- 需要麥克風的數量相對較多,
- 如果噪聲源是相干的,降噪效果會強烈地依賴于噪聲信號的到達方向,延遲求和波束形成在混響環境中的性能往往是不夠好的,
優點:
- 由于可以有效地減輕非相干噪聲,該類波束形成器仍然被廣泛使用,
E. Jan 在延遲求和的基礎上引入濾波求和波束形成器,這種結構的設計考慮了多徑效應,用匹配濾波器代替簡單的延遲補償器,具有更好的效果,
自適應波束形成演算法
最小方差無失真回應波束形成(MVDR)
1969 年,J. Capon 提出了最小方差無失真回應(Minimum Variance Distortionless Response, MVDR)波束形成演算法,該演算法是應用得最為廣泛的自適應波束形成方法之一,
原理:在期望信號無失真的約束條件下,選擇合適的濾波器系數,使得陣列輸出的平均功率最小化,
MVDR的權重優化問題可以表示為
$$\left\{\begin{array}{l}{\min _{w} w^{H} R_{x} w} \\ {\text {s.t. } w^{H} a\left(\theta_{s}\right)=1}\end{array}\right.$$
其中,$a(\theta_s)=[a_1(\theta)...a_M(\theta)]^T$為目標信號導向矢量,表示聲源方向和麥克風之間的傳遞函式,可以通過純凈語音信號達到每個麥克風的不同延遲時間$\tau$計算得到,$R_x$為空間信號相關協方差矩陣,根據快拍次數估計得到,當在時間上彼此不相關的$k$個噪聲信號從不同方向到達麥克風陣元時,空間相關協方差矩陣被定義為:
$$R_{x}(\omega)=\sum_{k=1}^{K} a\left(\omega, \theta_{k}\right) a^{H}\left(\omega, \theta_{k}\right)$$
運用拉格朗日乘子法計算得到最優權重為:
$$w_{\mathrm{MVDR}}\left(\omega, \theta_{s}\right)=\frac{R_{x}^{-1}(\omega) a\left(\omega, \theta_{s}\right)}{a^{H}\left(\omega, \theta_{s}\right)^{H} R_{x}^{-1}(\omega) a\left(\omega, \theta_{s}\right)}$$
因為約束條件是純凈語音信號無失真,即純凈語音信號是保持不變的,為了使得輸出的方差最小化,僅僅只需要讓噪聲信號最小化,所以上式信號相關矩陣$R_x$可以用噪聲相關矩陣$R_n$替換,
- 當$R_n$為非相干噪聲場的相關矩陣,則MVDR退化為延遲求和波束形成器,
- 當$R_n$為散射噪聲場的相關矩陣,則MVDR退化為超指向性波束形成器,
補充:MVDR是理論上普遍采用的波束形成典型演算法,在復雜環境下,由于協方差矩陣計算的不精確性演算法會導致性能急劇下降,后來的研究者提出了許多基于對角加載的解決方法,這些方法解決了對角加載值不易確定且無法通過樣本更改自動調整的問題,使協方差矩陣誤差問題得到一定的改善,但是,這些演算法相對比較復雜,效率較低,
線性約束最小方差( LCMV)波束形成器
1972年,L. Frost 提出了線性約束最小方差(Linearly Constrained Minimum Variance, LCMV)波束形成器,LCMV 波束形成在效果上實際是 MVDR 波束形成的擴展形式,它將后者中期望信號不受影響的這一約束擴展為一組約束,即為目標方向無失真同時對其它噪聲干擾方向陷零,隨后 L. Frost 基于約束最小均方自適應濾波器提出了LCMV 演算法的自適應結構,
原理:在滿足一組約束的同時,使波束形成輸出(干擾信號、噪聲)的功率最小化,
LCMV的約束條件可以表示為:
$$\left\{\begin{array}{l}{w_{o p t}=\arg \min w^{H} R_{x} w} \\ {s . t . w^{H} C=f}\end{array}\right.$$
其中,一組線性約束條件可以定位為M*P維的約束矩陣C,其中麥克風數量M需要小于線性約束條件P的個數,$f$表示P*1維的約束矢量,$R_x=E[x(t)x^H(t)]$表示輸出協方差矩陣,
采用拉格朗日乘子法計算,在接收的信號相關矩陣$R_x$存在可逆矩陣的前提下,獲得最優解為
$$w_{LCMT}=R_x^{-1}C(C^HR_x^{-1}C)^{-1}f$$
- 優點:廣義約束
- 缺點:須知信號波達方向
補充:當LCMV方法的約束條件取$w^Ha(\theta )=1$時,演變為最小方差無失真回應波束形成器(MVDR,minimum variance distortionless-response),其原理是在陣列輸出信號能量保持不變的約束條件下,通過調節權重系數使陣列信號輸出總功率(相關功率與非相關功率之和)達到最小,由于目標信號的強度得以保持,而噪聲的方差被最小化,可以說MVDR使陣列輸出信號的信噪比(SNR)達到最大,
廣義旁瓣相消器(GSC)
為了避免約束性自適應演算法,1982 年J. Griffiths 提出了廣義旁瓣相消器,可以證明在純延時條件下 GSC 是 LCMV 的一種等效實作結構,GSC 結構將 LCMV 的約束優化問題轉化為了無約束的優化問題,
原理:GSC 將LCMV 權重矢量分解為自適應權重和非自適應權重兩個部分,其中自適應權重位于約束空間的正交空間中,非自適應權重位于約束子空間中,
G SC是LCMV的等效實作方式,主要由主路和輔路兩部分組成,目標信號從主路通過,噪聲和干擾從輔路通過,權矢量可表示為
$$w=w_q-Bw_a$$
其中$w_q=(CC^H)^{-1}Cf$為非自適應權重,是權重矢量$w_{LCMV}$在約束子空間上的投影,約束子空間由約束矩陣C表示;$w_a=(B^HR_xB)^{-1}B^HR_xw_q$為自適應權重,是權重矢量$w_{LCMV}$在最小方差子空間上的投影,最小方差子空間由M*(M-P)維的阻塞矩陣B表示,B的作用就是就是保證目標信號不進入輔路,組成B的列矢量處于約束子空間的正互動補空間中,由于約束矩陣和阻塞矩陣是相互正交的所以必須滿足$B^HC=0$,
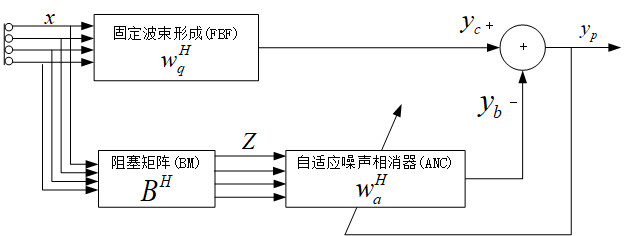
GSC波束形成的結構圖如上圖所示,其主要結構由固定波束形成、阻塞矩陣和自適應噪聲相消器構成,在GSC結構中,上支路由延時求和的固定波束形成器組成,由于是將接收信號投影到約束子空間,因此我們希望只有純凈期望語音通過,下支路由阻塞矩陣和自適應抵消器組成,由于是將接收信號投影到最小方差子空間,阻塞矩陣的輸出希望只有噪聲通過,固定波束形成器的輸出、阻塞矩陣的輸出以及自適應抵消器組成了多通道自適應濾波結構,阻塞矩陣被用來阻塞期望語音信號,令$y_c=w_q^Hx$,$z=B^Hx$,權矢量可以表示為$w_a=R_z^{-1}p_z$,$w_a$是保證主輔路均方誤差最小的維納解,其中,$R_z=B^HRB$是$z$的協方差矩陣,$p_z=B^HRw_q$是$z$和$y_c$的互相關矢量,當$z$支路中包含較少目標信號時,GSC效果較好;但是當聲源移動或者混響比較嚴重時,$z$中包含的目標信號超過一定程度,將會產生期望信號的泄露,在接下來的自適應濾波程序中會造成噪聲信號與上支路期望語音信號相互抵消的現象,導致期望語音的失真,演算法性能下降,
所以1999 年,O. Hoshuyama 等人采用約束自適應濾波的方法代替原來的對齊相減,以及采用當期望語音存在時只更新阻塞矩陣,而當期望語音不存在的時候只更新自適應抵消器的系數來減小期望語音信號的泄露
傳遞函式廣義旁瓣對消器(TF-GSC)
2001 年,S. Gannot 考慮到房間的混響情況,在頻域提出了傳遞函式廣義旁瓣對消器,
TF-GSC 包括三個部分,
- 固定的波束形成器(Fix Beamforming, FBF)用來將目標信號分量對齊,
- 阻塞矩陣(BlockMatrix, BM)用來將目標信號進行阻塞得到噪聲參考信號,
- 多通道自適應噪聲消除器(Adaptive Noise Canceller, ANC)利用噪聲參考信號對固定的波束形成器輸出噪聲進行消除,
為了進一步提升降噪效果,許多改進的方案在波束形成演算法后加入一個頻域濾波器,如維納濾波器或其他最小均方誤差(Minimum Mean Square Error, MMSE)估計器,通過在初始步驟中對信號的統計引數進行估計,然后使用這些引數來執行傳統的單信道降噪演算法,如對數譜幅度估計或譜減法,即有望進一步抑制噪聲,
引數化多通道維納濾波器
引數化多通道維納濾波是多通道維納濾波器的推廣形式,多通道維納濾波器的基本思想是最小化期望信號與輸出信號的均方誤差,但是維納濾波器不能保證輸出的信號是無失真的,通常可以引入一個引數,使得語音失真和噪聲抑制之間取得折中,引數化多通道維納濾波就是引入了一個語音失真加權引數,并在此引數的影響下最小化期望信號與濾波輸出的均方誤差,可以表示如下
$$\min _{\mathbf{w}} R{s s}\left|1-\mathrm{w}^{H} \mathrm{h}\right|^{2}+\mu \mathrm{W}^{H} R{\mathrm{nn}} \mathrm{w}$$
求解得到的波束形成系數為
$$\mathbf{w}_{\mathrm{PMWF}}=\frac{\phi_{s s} \mathbf{R}_{\mathrm{nm}}^{-1} \mathbf{h}}{\mu+\phi_{\mathrm{ss}} \mathbf{h}^{H} \mathbf{R}_{\mathrm{nm}}^{-1} \mathbf{h}}$$
語音失真加權引數$\mu$控制著語音失真與噪聲抑制之間的平衡, $\mu$值越接近于 1 演算法的降噪能力就越強,但語音的失真程度就會越大,且當$\mu=1$時,PMWF 退化為多通道維納濾波器從而不再保證語音的失真程度,$\mu$值越接近于 0 則語音的失真程度就越小,但演算法的降噪能力會越弱,且當$\mu=0$時,PMWF 退化為 MVDR 波束形成器,引數化多通道維納濾波演算法也可以稱為語音失真加權多通道維納濾波演算法(Speech Distortion Weighted Multichannel Wiener Filter, SDW-MWF),在系統模型誤差方面,其相較于標準的 GSC 演算法具有更強的魯棒性,
后置濾波技術
當噪聲干擾信號不是點聲源或有太多的干擾噪聲從不同方向到達麥克風陣列時,波束形成器的降噪能力是有限的,同時非穩定干擾噪聲的存在也會影響自適應波束形成器對噪聲的抑制效果,在自適應波束形成的輸出后接入一個后置濾波器可以有效地抑制殘留噪聲,如非相干噪聲、散射噪聲等,由于指向性波束只能產生有限數量的陷零,這就限制了散射噪聲的抑制程度,短時譜估計的后置濾波演算法基于期望信號與噪聲在時頻域的不同,而非空間位置的不同,所以可以有效地抑制散射噪聲,
維納后置濾波器
在上一節中我們提到的多通道維納濾波實際上可以分解為MVDR波束形成和一個單通道的維納濾波兩部分,如圖下所示,其中$w_i(k)$表示 MVDR 波束形成濾波系數,其分解程序如下所示:
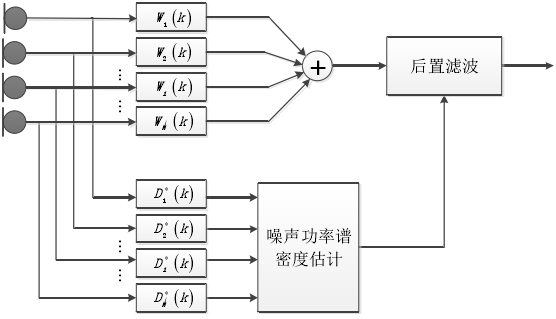
首先我們令 PMWF 中的引數$\mu=1$便得到多通道的維納濾波器
$$\mathbf{w}_{\mathrm{MWF}}=\frac{\phi_{\mathrm{ss}} R{\mathrm{nn}}^{-1} \mathbf{h}}{1+\phi_{\mathrm{ss}} \mathbf{h}^{H} \mathbf{R}_{\mathrm{nm}}^{-1} \mathbf{h}}$$
利用 Woodbury 恒等式可將 MWF 分解為如下形式
$$\mathbf{w}_{\mathrm{MWF}}=\frac{\mathbf{R}_{\mathrm{w}}^{-1} \mathbf{h}}{\mathbf{h}^{H} \mathbf{R}_{\mathrm{nn}}^{-1} \mathbf{h}} \frac{\phi_{\mathrm{ss}}}{\phi_{\mathrm{ss}}+\phi_{\mathrm{nn}}}$$
其中$\phi_{nn}=w_{MVDR}^HR_{nn}W_{MVDR}=(h^HR_{nn}^{-1})^{-1}$,通過上式可以看出,準確的估計期望信號的功率譜或噪聲信號的自相關函式是維納后置濾波演算法的根本,
Zelinski 后置濾波器
Zelinski 后置濾波器在估計$\phi_{ss}$時是基于噪聲在不同麥克風之間是無關的假設,且由不相關噪聲場產生,即$R_{nn}=\sigma _n^2I$;所有麥克風中的噪聲功率譜均相同,即$R_{n_in_i}=R_{nn}$;語音和噪聲是不相關的,由上假設可得
$$R_{y_iy_i}=\phi_{ss}h_ih_i^*+R_{nn}$$
$$R_{y_iy_j}=\phi_{ss}h_ih_j^*$$
平滑后觀測信號的自相關功率譜密度和互相關功率譜密度,可以如下遞回估計
$$\hat{R}_{y_iy_i}(t, f) =\alpha \hat{R}_{y_iy_i}(t-1, f)+(1-\alpha) y_{i}^{*} y_{i}$$
$$\hat{R}_{y_iy_j}(t, f) =\alpha \hat{R}_{y_iy_j}(t-1, f)+(1-\alpha) y_{i}^{*} y_{j}$$
$\alpha$為接近 1 的固定平滑因子,Zelinski 后置濾波器最后可以表達成為
$$w_{\mathrm{Zelinski}}=\frac{\frac{2}{M(M-1)} \sum_{i=1}^{M-1} \sum_{j=i+1}^{M} \operatorname{Re}\left\{\hat{R}_{x_i, y_{j}}(t, f)\right\}}{\frac{1}{M} \sum_{i=1}^{M} \hat{R}_{y_iy_i}(t, f)}$$
其中 Re(·)表示復數的取實部操作,應用于上式是為了確保語音的功率譜密度估計是實數,
缺點:由于 Zelinski后置濾波器在估計噪聲時并沒有考慮到前面波束形成的降噪作用,使得噪聲被過估計,因此Zelinski后置濾波器在理論上是次優的,
U. Simmer為了解決噪聲過估計的問題,在 Zelinski 濾波的基礎上提出了另外一種后置濾波器,在同樣的非相干噪聲場假設條件下,Simmer 后置濾波器將波束形成后輸出的自相關功率譜密度代替 Zelinski 后置濾波器的分母部分,由于在分母部分使用了波束形成輸出的自相關功率譜密度,Simmer后置濾波器被證明是在不相干噪聲信號條件下理論最優的維納后置濾波器,
問題:Zelinski 后置濾波器和 Simmer 后置濾波器僅僅只解決了在非相干噪聲場中不相關噪聲信號的抑制問題,但在實際生活中純非相干噪聲場的使用場景比較少,我們一般對常見的擴散噪聲場更感興趣,
Mc Cowan 后置濾波器
McCowan 后置濾波并沒有假設不同麥克風之間的噪聲是不相關的,考慮到麥克風之間接收噪聲的相關性,且假設噪聲是已知的散射噪聲場,用噪聲相關函式${\Gamma _y}(f)$表示,由以上假設,麥克風接收信號的自相關和互相關噪聲功率譜密度可表示為
$$R_{y_iy_i}=\phi_{ss}h_ih_i^*+R_{nn}$$
$$R_{y_iy_j}=\phi_{ss}h_ih_j^*+\Gamma_{ij}R_{nn}$$
根據上式,Mc Cowan 后置濾波器最后可以表達成為
$$w_{\text {Mecowan }}=\frac{\frac{2}{M(M-1)} \sum_{i=1}^{M-1} \sum_{j=i+1}^{M} \hat{R}_{s s}^{i j}(t, f)}{\frac{1}{M} \sum_{i=1}^{M} \hat{R}_{y_{i} y_{i}}(t, f)}$$
其中
$$\hat{R}_{s s}^{i j}(t, f)=\frac{\operatorname{Re}\left\{\hat{R}_{y y, y}(t, f)\right\}-\frac{1}{2} \operatorname{Re}\left\{\Gamma_{i j}(f)\right\}\left[\hat{R}_{y y, t}(t, f)+\hat{R}_{y, y}(t, f)\right]}{1-\operatorname{Re}\left\{\Gamma_{i y}(f)\right\}}$$
同樣是由于噪聲過估計問題,Mc Cowan 后置濾波器是理論次優的,
S. Lefkimmiatis采用了與 U. Simmer 相同的方法解決噪聲過估計問題,同樣是考慮到使用波束形成濾波后的輸出估計噪聲信號的自相關功率譜密度,Lefkimmiatis 后置濾波器被證明是在擴散噪聲相干函式條件下理論最優的維納后置濾波器,
最優修正對數譜幅度后置濾波器
維納濾波器基于均方誤差準則,并不能得到最優的頻譜,更合適的方法是基于譜幅度的均方誤差或對數譜幅度的均方誤差,基于這兩個準則,Y. Ephraim 提出了短時譜幅度估計器(Short-Time Spectral Amplitude, STSA) 和對數譜幅度估計器 (Log Spectral Amplitude, LSA) ,I. Cohen 在對數譜幅度估計器的基礎上結合語音的存在概率提出了最優修正對數譜幅度估計器(Optimal Modified Log-Spectral Amplitude, OM-LSA),在期望語音信號和噪聲信號經過離散傅里葉變換后,假設其傅里葉系數的實部和虛部均滿足均值為零的高斯分布,在此條件下基于對數短時譜幅度最小均方誤差的估計器可以分解為MVDR自適應波束形成器后接入一個單通道的對數短時譜幅度后置濾波器,
I. Cohen 率先將最優修正對數譜幅度估計器用于麥克風陣列后置濾波部分,其運算式如下所示
$$w_{\mathrm{OM}-\mathrm{LSA}}=\left(\frac{\xi(t, f)}{1+\xi(t, f)} \exp \left(\frac{1}{2} \int_{v(t, f)}^{\infty} \frac{e^{-t}}{t} d t\right)\right)^{p(t, f)} \cdot G_{\mathrm{min}}^{1-p(t, f)}$$
其中$\xi(t, f)$為先驗信噪比,$\gamma (t,f)$為后驗信噪比,$v(t,f)=\frac{\gamma (t,f)\xi(t, f)}{1+\xi(t, f)}$,$p(t,f)$為語音存在概率,$G_{min}$為語音不存在時濾波器的增益下限,不同于傳統的單通道OM-LSA 演算法,作為麥克風陣列后置濾波器的 OM-LSA 演算法,其語音存在概率的估計融合了空間資訊,所以結果更準確,
解決方案
《基于特征值分解的自適應波束形成及后置濾波》
1. 首先利用期望最大化演算法估計期望語音信號在時頻點上存在的概率,
2. 然后推導了基于最大特征值向量的導向矢量估計和基于最小特征值向量的噪聲功率
譜密度估計,
思路:為了更穩定地估計導向矢量和更精確地估計殘留噪聲,提出了基于特征值分解的自適應波束形成和后置濾波演算法,基于最大特征向量的導向矢量估計不需要麥克風陣列的幾何位置資訊,信號相關矩陣的主成分將會指向最大輸出功率方向,這樣就可以避免對目標信號方向進行直接估計,且對于混響信號具有很好的魯棒性,同時我們將使用信號相關矩陣最小特征值對應的特征向量對噪聲功率譜密度進行估計,利用多通道信號估計的噪聲功率譜密度相較于單通道的噪聲跟蹤更加準確,
超指向性波束形成演算法(SBF)研究
對于麥克風陣列,最關鍵的問題之一是如何處理噪聲環境中的有效信號捕獲,信號在空間中大量的反射往往會形成接近球形的各向同性噪聲場,因此,本論文在最小無失真回應(MVDR)演算法的基礎上,利用各向同性散射噪聲場矩陣代替MVDR演算法中的噪聲空間相關協方差矩陣,對語音信號做波束形成降噪處理,
所有關于波束形成演算法設計的主要性能指標是各類噪聲場矩陣相關函式,所謂的“超指向性”(Superdirective)是指通過最優相關函式處理,抑制來自所有方向噪聲對目標信號的影響,輸出比常規波束形成具有更高“方向性”的陣列增益信號,從而改善降噪處理效果,
參考文獻
麥克風陣列的語音增強演算法研究——王曉雪
2017麥克風陣列自適應波束形成及后置濾波技術研究_夏杰
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79558.html
標籤:其他