目錄
- 1. 步驟
- 2. 要素
- 3. 裝配線調度
- 4. 矩陣鏈乘
- 5. 最長公共子序列(Longest Common Subsequece)
- 6. 最優二叉查找樹(Optimal Binary Search Tree)
1. 步驟
- 描述問題的最優解(optimal solution)結構特征
- 遞回定義最優解值
- 自底向上 計算最優解值
- 從已計算得到的最優解值資訊中構造最優解
2. 要素
最優子結構和重疊子問題
最優子結構性質是指一個問題的最優解中所包含的所有子問題的解都是最優的,
動態規劃避開了遞回時,重復計算相同子問題的程序,對每個子問題只解一次,而后將其保存在一個
表格中,當再次需要的時候,查表獲取,
3. 裝配線調度
-
最優子結構性質:如果問題的解是最優的,則所有子問題的解也是最優的,在這里,描述為最優
路徑的子路徑也是最優的,
最優子結構證明:剪枝法
∵如果子路徑P1從開始到S1,j-1不是最優的,那么一定存在一條從開始到S1,j-1的更優子路徑P2,
當用P2去替換原子路徑P1后,將得到一條比原路徑更優的路線,這與假設從開始到S1,j是一條最
優路線矛盾,
∴子路徑P1一定也是最優的 -
遞回定義最優路線的最快時間
最快時間 f=min(f1[n]+x1,f2[n]+x2)
要得到f值,需要計算fi[j]的每個值
f1[j]=min{f1[j-1]+a(1,j),f2[j-1]+t(2,j-1)+a(1,j)}
f2[j]=min{f2[j-1]+a(2,j),f1[j-1]+t(1,j-1)+a(2,j)}
遞回初始值:f1[1]=e1+a(1,1); f2[1]=e2+a(2,1) -
先確定此問題的底,然后再自底向上計算最優解值,O(n)
-
構造最優解結構(輸出最優路線)
4. 矩陣鏈乘
給定一個矩陣序列<A1,A2,…,An>,其中矩陣Ai的維數為Pi-1×Pi,要求計算A1×A2×…×An矩陣鏈乘的
乘法次數最少?
- 最優子結構
設矩陣A_i 的維數是 P_(i-1) * P_i,輸入序列為P0,P1...Pn,則
假設子問題A_ij的解(A_i*A_(i+1)…A_j)是一個最優解,則在Aij中一定存在一個 最佳分裂點k(i≤k<j),
使得子鏈A_ik和A_k+1,j的解(A_i*A_(i+1)…A_k)和(A_(k+1)…A_j)也是最優的, - 遞回定義最優解值
規模為n^2的輔助結構m[i,j]存放子鏈A_ij=(A_iA_(i+1)…A_j)的乘法次數,m[1,n]表示所有n個矩
陣鏈乘的乘法次數,m[i,j] 的規模為矩陣上三角=O(n^2)
i=j時,m[i,j] = 0
i<j時,m[i,j] = min(m[i,k]+m[k+1,j]+ P_(i-1)*P_k*P_j ),i<=k<j - 自底向上計算最優解值
輔助結構s[i,j]用于記錄最佳分裂點k的位置
遞回計算鏈長分別為2到n的矩陣鏈的最佳組合,長鏈計算依賴短鏈的最佳計算結果,
時間復雜度O(n^3)
matrix-chain-order(P)
n=length[p]-1
for i=1 to n
m[i,i]=0
for l=2 to n //l為鏈長
for i=1 to n-l+1 //具有n-l+1個鏈長為l的組合
j=i+l-1
m[i,j]=∞
for k=i to j-1 //找最佳分裂點k
q=m[i,k]+m[k+1,j]+ P_(i-1)*P_k*P_j
if q<m[i,j]
m[i,j]=q
s[i,j]=k //記錄最佳分裂點
return m and s
- 輸出最優解結構
5. 最長公共子序列(Longest Common Subsequece)
令給定序列X={x1,x2,…xm},另一序列Z={z1,z2,…zk}是X的子序列必須滿足:X的下標中存在一個
嚴格的遞增序i1<i2<…<ik,使得對所有的j均有Xij=Zj(1≤j≤k),換句話說,子序列是原序列洗掉
若干個元素所得,
對于序列X和Y,序列Z如果既是X的子序列又是Y的子序列,則Z是X和Y的公共子序列,
- LCS問題最優子結構性質
令X={x1,x2,…xm},Y={y1,y2,…yn}為二個序列,子序列Z={z1,z2,…zk}是X和Y的一個最長公共
子序列,則:
- if xm=yn then zk=xm=yn且Zk-1是Xm-1和Yn-1的LCS
- if xm≠yn,則有兩個子問題,X_m-1 和 Y的LCS 及 X 和 Y_m-1的LCS,
- 遞回定義LCS值
令C[i,j]存放子序列Xi和Yj的LCS長度,則:
- i or j=0時,C[i,j] = 0
- i,j>0 and xi=yj時, C[i,j] = C[i-1,j-1]+1
- i,j>0 and xi≠yj時, C[i,j] = max{C[i,j-1],C[i-1,j]}
- 自底向上計算LCS值
O(mn)
b[i,j]用于存放xi和yi的LCS是哪種情況,=0表示情況1,=1和-1分別表示X_m-1和Y的LCS及X和Y_m-1的LCS
def LCS_Length(x,y):
m=len(x)
n=len(y)
for i in range(m):
c[i][0]=0
for j in range(n):
c[0][j]=0
for i in range(1,m):
for j in range(1,n):
if x[i]=y[j]:
c[i][j] = c[i-1][j-1] + 1
b[i][j] = 0
elif c[i-1][j]>=c[i][j-1]:
c[i][j]=c[i-1][j]
b[i][j] = 1
else:
c[i][j]=c[i][j-1]
b[i][j] = -1
return c,b
- 根據c和b輸出LCS
改進:直接由x[i] ?= y[j],c[i-1][j],c[i][j-1]判斷,可以取締b[i,j],
def printLcs(c,x,y,i,j)
if i == 0 or j == 0:
return
if x[i] == y[j]:
printLcs(c,x,y,i-1,j-1)
print(x[i])
elif c[i-1][j]>=c[i][j-1]:
printLcs(c,x,y,i-1,j)
else
printLcs(c,x,y,i,j-1)
6. 最優二叉查找樹(Optimal Binary Search Tree)
對于單個關鍵字的查找,在紅黑樹上查找時間為O(lgn),但若查找的是一系列關鍵字且每個關鍵字
的查找頻度值不同,此時從整體來看紅黑樹不能產生最少的時間,
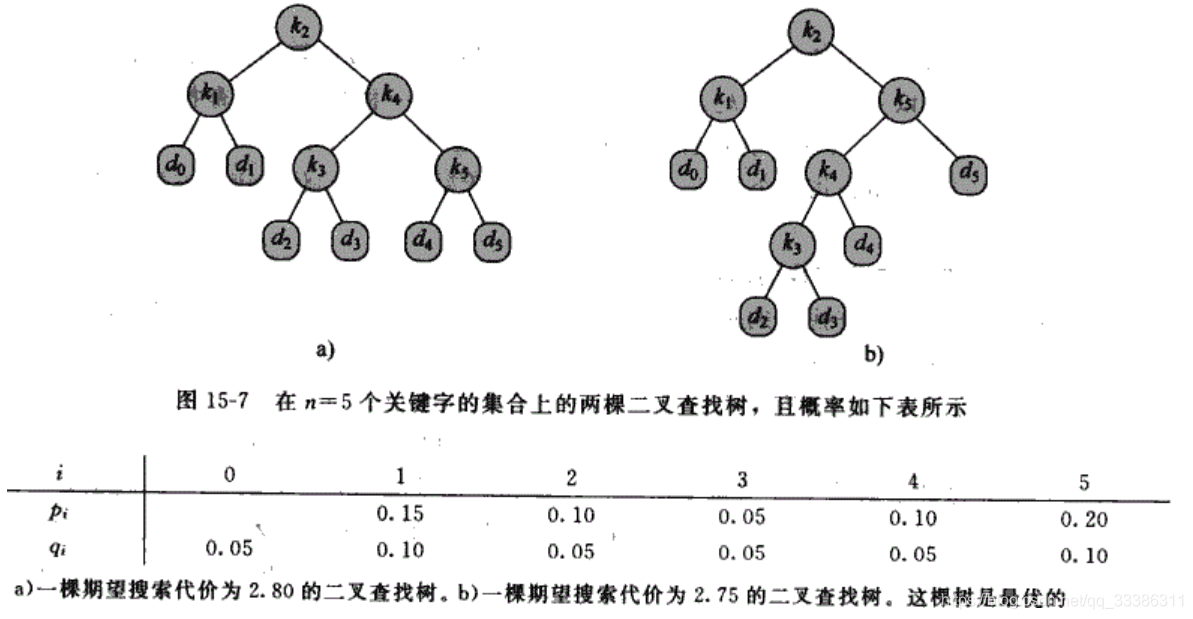
令n個不同的關鍵字集K={k1,k2,...,kn},其中k1<k2<…<kn;
pi:檢索關鍵字ki的概率
令d0,d1,…,dn表示不在關鍵字集K中的虛擬(dummy)關鍵字;
d0:小于k1的所有關鍵字;dn:大于kn的所有關鍵字;
di:介于ki和ki+1之間的所有關鍵字(i=1,2,…,n-1)
qi:檢索關鍵字di的概率
關鍵字檢索只有二種狀態 :成功檢索:找到關鍵字ki,概率為pi; 不成功檢索:找到關鍵字di,概率為qi;
總概率和 pi(i=1->n)+pj(i=0->n)=1.
定義E(搜索代價)= (depth(k_i)+1)*p_i(i=1->n) + (depth(d_i)+1)*q_i(i=0->n) =
1 + depth(k_i)*p_i(求和i=1->n) + depth(d_i)*q_i(求和i=0->n)
E最小的二叉查找樹 稱為 最優BST,
- 最優子結構
如果Tr是一棵以kr為根且包含ki,…,…,kj的OBST,那么包含關鍵字ki,…kr-1的左子樹Tl及包含
關鍵字kr+1,…,kj的右子樹Tr也是OBST,思想類似于找矩陣鏈的最佳分裂點, - 遞回定義最優解值
令e[i,j]為包含關鍵字ki,…,kj的OBST平均檢索代價,則e[1,n]為所求解,其中i≥1,j≤n且j≥i-1
當j=i-1時,e[i,j]=q_i-1
當j>=i時,e[i,j] = min{e[i,r-1]+e[r+1,j]+w(i,j)};其中
w(i,j)=p_k(求和k=i->j)+q_k(求和k=i-1 -> j); - 自底向上計算最優解值
O(n^3)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79579.html
標籤:其他
上一篇:跟我一起學演算法——斐波那契堆
下一篇:跟我一起學演算法——分治法