一.簡介
推薦演算法的整體流程是:召回——排序——策略調整
基于協同過濾的推薦演算法有以下基本假設:
1.基于用戶的協同過濾(User-based CF):和你喜歡相同物品的人,他們喜歡的東西你也喜歡
2.基于物品的協同過濾(item-based CF):和你喜歡的物品比較相似的物品,你也可能喜歡
二.協同過濾的具體程序
1.基于用戶的協同過濾
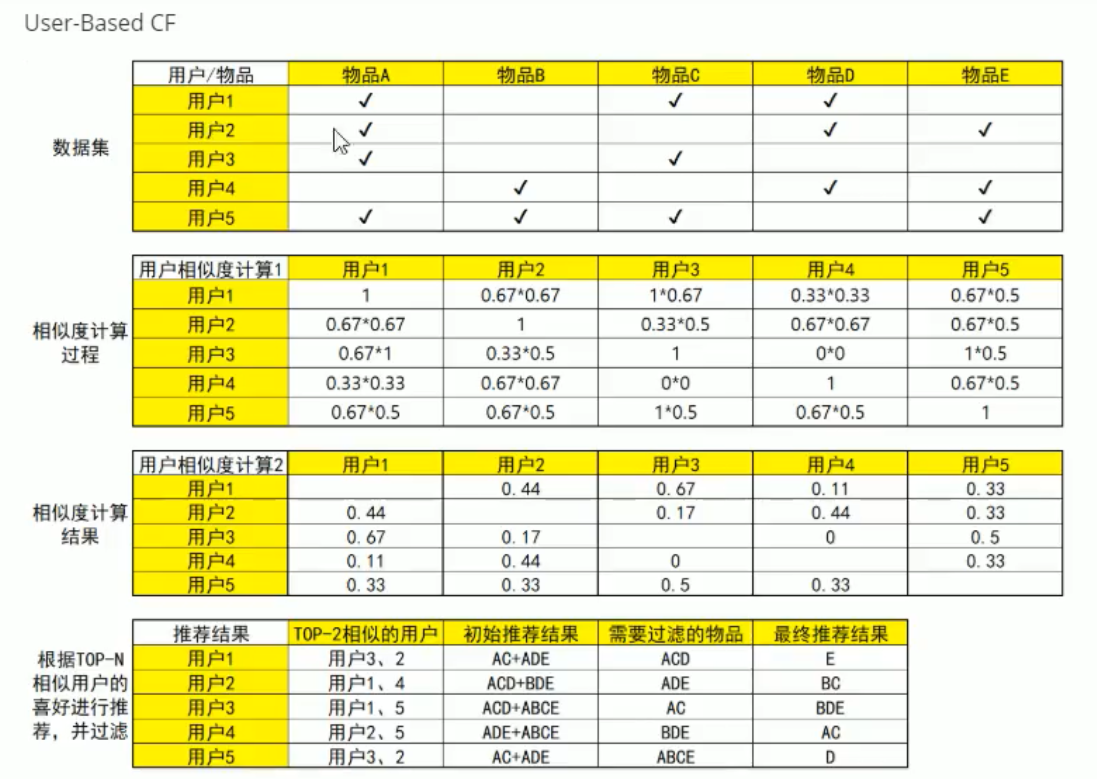
從上面可以看到用戶如果買了一個東西則打鉤,沒有買則不打鉤,假設我們有兩個人,小明和小紅,那么我們怎么計算這兩個人喜歡物品的相似度呢?我們假設:
小明喜歡的東西有:籃球,足球,乒乓球
小紅喜歡的東西有:籃球,足球,乒乓球,羽毛球
那么他們喜歡的相同物品數量是3,因此計算公式為:
3/3 * 3/4==9/12=3/4,這就是小明和小紅兩者之間喜歡物品的相似度,
然后計算小明和不同用戶之間的喜好相似度,使用機器學習當中KNN的思想取最大的相似程度的人做推薦,找到人之后查看他們喜歡的共同物品,過濾掉,然后取另外用戶喜好的物品給這個用戶(小明)進行推薦,這就是基于用戶的協同過濾的基本思想,
2.基于物品的協同過濾(item based CF)
我們用物品來計算相似度,如下圖所示: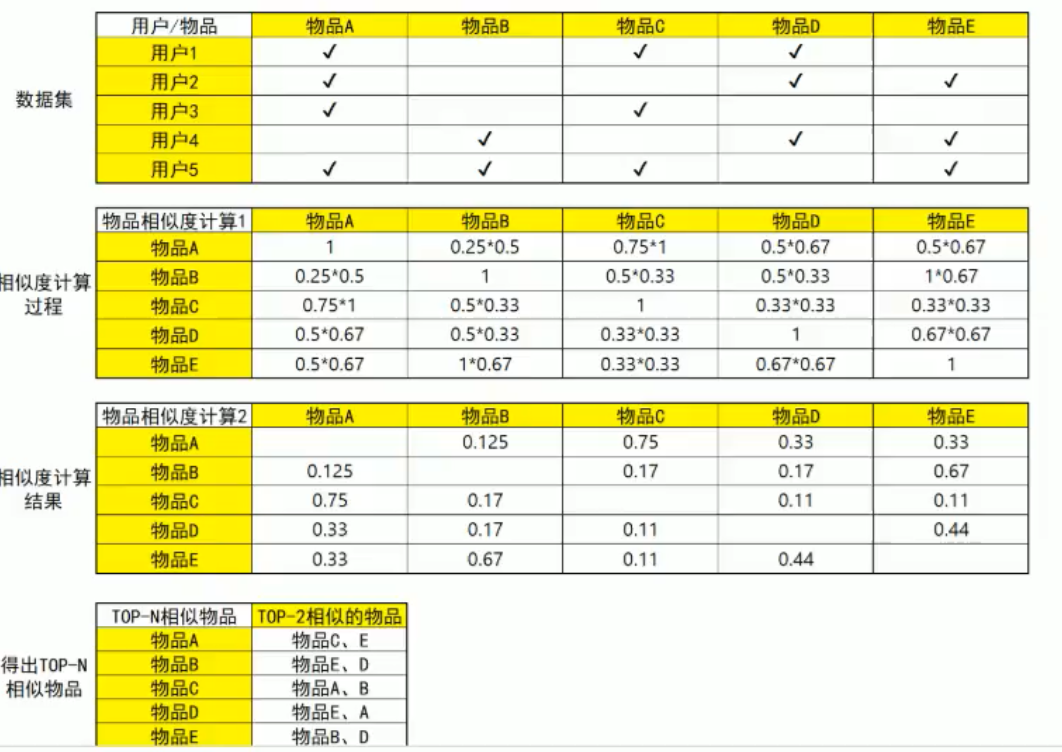
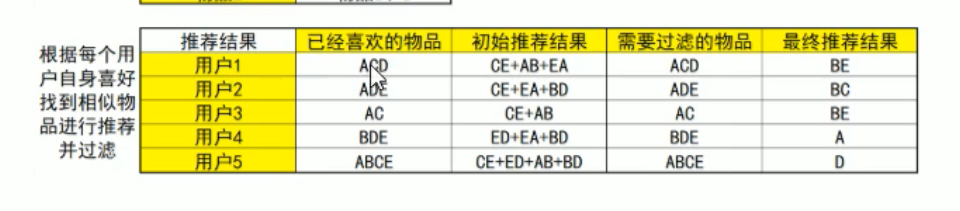
看看圖自然就明白了,思想和基于用戶的協同過濾是相同的,
3.咱們做推薦系統的大致思路如下:
1.首先通過特征工程將用戶-物品評分矩陣創建出來
2.1通過基于用戶的協同過濾
2.2或者用過給予物體的協同過濾
給用戶推薦商品
三.相似度的計算
相似度不僅僅是我們剛剛做的這么簡單,不是只需要比較物品即可,因為我們用戶會對一個物品做出多種反應,評分,收藏,瀏覽次數等等,一般情況下還會使用實數值進行相似度的計算,相似度計算的資料有:
1.實數值(物品的評分情況)
2.布林值(用戶的行為,是否購買,是否收藏)
我們可以通過余玹相似度來計算兩個物品之間的相似度,如下所示:
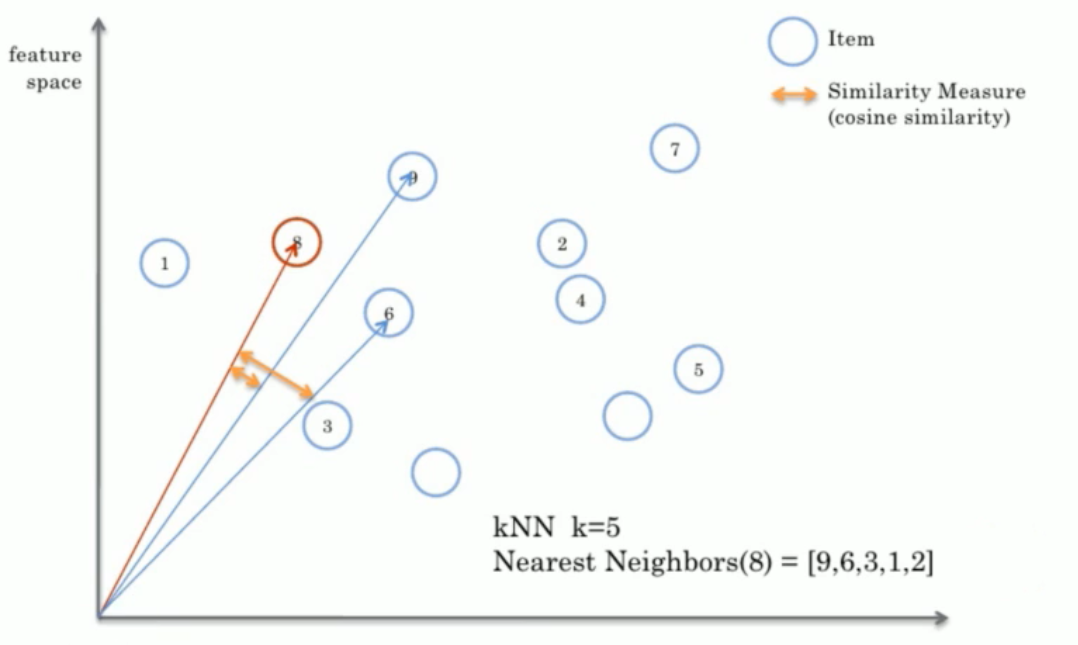
在計算余玹相似度的時候我們只需要考慮兩個物品之間的夾角的值,也就是cos()的值,而不需要關心向量的長短,上圖是一個僅僅具有兩個特征的物品,因此維度是2.
2.我們可以通過皮爾遜相關系數來計算兩個物品之間的相似度,也就是直接使用相關系數r進行運算,計算的公式如下圖所示:
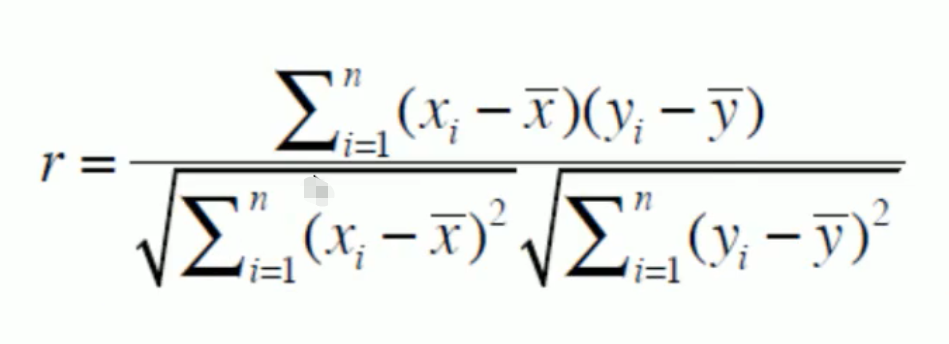
在這個公式當中同時考慮到了長度和角度的影響,當然也就在某些場景下使用的話會更加準確了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79663.html
標籤:其他
上一篇:處理幀數不等的視頻的批處理代碼