作者|Luke Newman
編譯|VK
來源|Towards Data Science
多層感知器
多層感知器(MLP)是由一個輸入層、一個或多個隱藏層和一個稱為輸出層的最終層組成的人工神經網路(ANN),通常,靠近輸入層的層稱為較低層,靠近輸出層的層稱為外層,除輸出層外的每一層都包含一個偏置神經元,并與下一層完全相連,
當一個ANN包含一個很深的隱藏層時,它被稱為深度神經網路(DNN),

在這項調查中,我們將在MNIST時尚資料集上訓練一個深度MLP,并通過指數增長來尋找最佳學習率,繪制損失圖,并找到損失增長的點,以達到85%以上的準確率,對于最佳實踐,我們將實作早期停止,保存檢查點,并使用TensorBoard繪制學習曲線,
你可以在這里查看jupyter Notebook:https://github.com/lukenew2/learning_rates_and_best_practices/blob/master/optimal_learning_rates_with_keras_api.ipynb
指數學習率
學習率可以說是最重要的超引數,一般情況下,最佳學習速率約為最大學習速率(即訓練演算法偏離的學習速率)的一半,找到一個好的學習率的一個方法是訓練模型進行幾百次迭代,從非常低的學習率(例如,1e-5)開始,逐漸增加到非常大的值(例如,10),
這是通過在每次迭代時將學習速率乘以一個常數因子來實作的,如果你將損失描繪為學習率的函式,你應該首先看到它在下降,但過一段時間后,學習率會太高,因此損失會迅速回升:最佳學習率將略低于轉折點,然后,你可以重新初始化你的模型,并使用此良好的學習率對其進行正常訓練,
Keras模型
我們先匯入相關庫
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
PROJECT_ROOT_DIR = "."
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images")
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
import tensorflow as tf
from tensorflow import keras
接下來加載資料集
(X_train, y_train), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train.shape
X_train.dtype
標準化像素
X_valid, X_train = X_train[:5000] / 255.0, X_train[5000:] / 255.0
y_valid, y_train = y_train[:5000], y_train[5000:]
X_test = X_test / 255.0
讓我們快速看一下資料集中的影像樣本,讓我們感受一下分類任務的復雜性:
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
n_rows = 4
n_cols = 10
plt.figure(figsize=(n_cols * 1.2, n_rows * 1.2))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col
plt.subplot(n_rows, n_cols, index + 1)
plt.imshow(X_train[index], cmap="binary", interpolation="nearest")
plt.axis('off')
plt.title(class_names[y_train[index]], fontsize=12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
save_fig('fashion_mnist_plot', tight_layout=False)
plt.show()

我們已經準備好用Keras來建立我們的MLP,下面是一個具有兩個隱藏層的分類MLP:
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
讓我們一行一行地看這個代碼:
-
首先,我們創建了一個Sequential模型,它是神經網路中最簡單的Keras模型,它只由一堆按順序連接的層組成,
-
接下來,我們構建第一層并將其添加到模型中,它是一個Flatten層,其目的是將每個輸入影像轉換成一個1D陣列:如果它接收到輸入資料X,則計算X.reshape(-1,1),因為它是模型的第一層,所以應該指定輸入形狀,或者,你可以添加keras.layers.InputLayer作為第一層,設定其input_shape=[28,28]
-
下一步,我們添加一個300個神經元的隱藏層,并指定它使用ReLU激活函式,每一個全連接層管理自己的權重矩陣,包含神經元與其輸入之間的所有連接權重,它還管理一個偏置向量,每個神經元一個,
-
然后我們添加了第二個100個神經元的隱藏層,同樣使用ReLU激活函式,
-
最后,我們使用softmax激活函式添加了一個包含10個神經元的輸出層(因為我們執行的分類是每個類都是互斥的),
使用回呼
在Keras中,fit()方法接受一個回呼引數,該引數允許你指定Keras將在訓練開始和結束、每個epoch的開始和結束時,甚至在處理每個batch處理之前和之后要呼叫物件的串列,
為了實作指數級增長的學習率,我們需要創建自己的自定義回呼,我們的回呼接受一個引數,用于提高學習率的因子,為了將損失描繪成學習率的函式,我們跟蹤每個batch的速率和損失,
請注意,我們將函式定義為on_batch_end(),這取決于我們的目標,當然也可以是on_train_begin(), on_train_end(), on_batch_begin(),對于我們的用例,我們希望在每個批處理之后提高學習率并記錄損失:
K = keras.backend
class ExponentialLearningRate(keras.callbacks.Callback):
def __init__(self, factor):
self.factor = factor
self.rates = []
self.losses = []
def on_batch_end(self, batch, logs):
self.rates.append(K.get_value(self.model.optimizer.lr))
self.losses.append(logs["loss"])
K.set_value(self.model.optimizer.lr, self.model.optimizer.lr * self.factor)
現在我們的模型已經創建好了,我們只需呼叫它的compile()方法來指定要使用的loss函式和優化器,或者,你可以指定要在訓練和評估期間計算的額外指標串列,
首先,我們使用“稀疏的分類交叉熵”損失,因為我們有稀疏的標簽(也就是說,對于每個實體,只有一個目標類索引,在我們的例子中,從0到9),并且這些類是互斥的),接下來,我們指定使用隨機梯度下降,并將學習速率初始化為1e-3,并在每次迭代中增加0.5%:
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(lr=1e-3),
metrics=["accuracy"])
expon_lr = ExponentialLearningRate(factor=1.005)
現在讓我們只在一個epoch訓練模型:
history = model.fit(X_train, y_train, epochs=1,
validation_data=https://www.cnblogs.com/panchuangai/p/(X_valid, y_valid),
callbacks=[expon_lr])
我們現在可以將損失繪制為學習率的函式:
plt.plot(expon_lr.rates, expon_lr.losses)
plt.gca().set_xscale('log')
plt.hlines(min(expon_lr.losses), min(expon_lr.rates), max(expon_lr.rates))
plt.axis([min(expon_lr.rates), max(expon_lr.rates), 0, expon_lr.losses[0]])
plt.xlabel("Learning rate")
plt.ylabel("Loss")
save_fig("learning_rate_vs_loss")
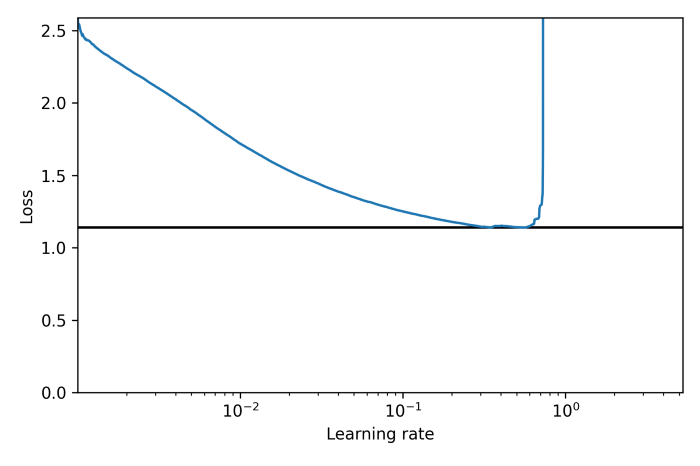
正如我們所期望的,隨著學習率的提高,最初的損失逐漸減少,但過了一段時間,學習率太大,導致損失反彈:最佳學習率將略低于損失開始攀升的點(通常比轉折點低10倍左右),我們現在可以重新初始化我們的模型,并使用良好的學習率對其進行正常訓練,
還有更多的學習率技巧,包括創建學習進度表,我希望在以后的調查中介紹,但對如何手動選擇好的學習率有一個直觀的理解同樣重要,
我們的損失在3e-1左右開始反彈,所以讓我們嘗試使用2e-1作為我們的學習率:
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(lr=2e-1),
metrics=["accuracy"])
使用TensorBoard進行可視化
TensorBoard是一個很好的互動式可視化工具,你可以使用它查看訓練期間的學習曲線、比較學習曲線、可視化計算圖、分析訓練統計資料、查看模型生成的影像,可視化復雜的多維資料投影到三維和自動聚類,等等!這個工具是在安裝TensorFlow時自動安裝的,所以你應該已經安裝了,
讓我們首先定義將用于TensorBoard日志的根日志目錄,再加上一個小函式,該函式將根據當前時間生成一個子目錄路徑,以便每次運行時它都是不同的,你可能需要在日志目錄名稱中包含額外的資訊,例如正在測驗的超引數值,以便更容易地了解你在TensorBoard中查看的內容:
root_logdir = os.path.join(os.curdir, "my_logs")
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir() # 例如, './my_logs/run_2020_07_31-15_15_22'
Keras api提供了一個TensorBoard()回呼函式,TensorBoard()回呼函式負責創建日志目錄,并在訓練時創建事件檔案和撰寫摘要(摘要是一種二進制資料記錄用于創建可視化TensorBoard),
每次運行有一個目錄,每個目錄包含一個子目錄,分別用于訓練日志和驗證日志,兩者都包含事件檔案,但訓練日志也包含分析跟蹤:這使TensorBoard能夠準確地顯示模型在模型的每個部分(跨越所有設備)上花費了多少時間,這對于查找性能瓶頸非常有用,
early_stopping_cb = keras.callbacks.EarlyStopping(patience=20)
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_fashion_mnist_model.h5", save_best_only=True)
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
history = model.fit(X_train, y_train, epochs=100,
validation_data=https://www.cnblogs.com/panchuangai/p/(X_valid, y_valid),
callbacks=[early_stopping_cb, checkpoint_cb, tensorboard_cb])
接下來,我們需要啟動TensorBoard服務器,我們可以通過運行以下命令在Jupyter中直接執行此操作,第一行加載TensorBoard擴展,第二行啟動埠6004上的TensorBoard服務器,并連接到它:
%load_ext tensorboard
%tensorboard — logdir=./my_logs — port=6004
現在你應該可以看到TensorBoard的web界面,單擊“scaler”選項卡以查看學習曲線,在左下角,選擇要可視化的日志(例如,第一次運行的訓練日志),然后單擊epoch_loss scaler,請注意,在我們的訓練程序中,訓練損失下降得很順利,
你還可以可視化整個圖形、學習的權重(投影到3D)或分析軌跡,TensorBoard()回呼函式也有記錄額外資料的選項,例如NLP資料集的嵌入,
這實際上是一個非常有用的可視化工具,
結論
在這里我們得到了88%的準確率,這是我們可以達到的最好的深度MLP,如果我們想進一步提高性能,我們可以嘗試卷積神經網路(CNN),它對影像資料非常有效,

就我們的目的而言,這就足夠了,我們學會了如何:
-
使用Keras的Sequential API構建深度mlp,
-
通過按指數增長學習率,繪制損失圖,并找到損失重新出現的點,來找到最佳學習率,
-
構建深度學習模型時的最佳實踐,包括使用回呼和使用TensorBoard可視化學習曲線,
如果你想在這里看到演示幻燈片或jupyterNotebook中完整的代碼和說明,請隨時查看Github存盤庫:https://github.com/lukenew2/learning_rates_and_best_practices
額外的資源
https://www.tensorflow.org/tensorboard/get_started
https://towardsdatascience.com/learning-rate-schedules-and-adaptive-learning-rate-methods-for-deep-learning-2c8f433990d1
原文鏈接:https://towardsdatascience.com/learning-rates-and-best-practices-for-deep-learning-e77215a86178
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79670.html
標籤:其他