作者|Moez Ali
編譯|VK
來源|Towards Data Science
你可能會想知道,GitHub是從什么時候開始涉足自動機器學習業務的,好吧,它其實沒有,但你可以像有一樣的使用它,在本教程中,我們將向你展示如何構建個性化的AutoML軟體,并將其托管在GitHub上,以便其他人可以免費使用或付費訂閱,

我們將使用pycaret2.0,一個開源的、少代碼行數的Python機器學習庫來開發一個簡單的AutoML解決方案,并使用GitHub Action將其部署為Docker容器,
如果你以前沒有聽說過PyCaret,可以在這里閱讀pycaret2.0的官方宣告:https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e,或者查看這里的詳細發行說明:https://github.com/pycaret/pycaret/releases/tag/2.0,
本教程的學習目標
-
了解什么是AutoML,以及如何使用pycaret2.0構建一個簡單的AutoML軟體,
-
了解什么是容器以及如何將AutoML解決方案部署為Docker容器,
-
什么是GitHub Action以及如何使用它們來托管AutoML軟體,
什么是AutoML?
AutoML是一個將耗時、迭代的機器學習任務自動化的程序,它允許資料科學家和分析員在保持模型質量的同時高效地構建機器學習模型,任何AutoML軟體的最終目標都是根據某些性能標準最終確定最佳模型,
傳統的機器學習模型開發程序是資源密集型的,需要大量的領域知識和時間來生成和比較幾十個模型,通過自動化機器學習,你將加快開發生產ML模型所需的時間,并且實作非常容易和高效,
有很多AutoML軟體,付費的和開源的,幾乎所有的演算法都使用相同的變換和基演算法集合,因此,在軟體下訓練的模型的質量和性能基本相同,
付費的AutoML軟體作為一種服務是非常昂貴的,如果你的口袋里如果沒有很多錢,至少在財務上是不可行的,托管機器學習作為一種服務平臺相對來說成本較低,但它們通常很難使用,并且需要特定平臺的知識,
在許多其他開放原始碼的AutoML庫中,PyCaret是一個相對較新的庫,并且具有獨特的機器學習方法介面,PyCaret的設計和功能簡單、人性化、直觀,在很短的時間內,PyCaret被全球超過10萬名資料科學家采用,我們是一個不斷增長的開發者社區,
PyCaret是如何作業的
PyCaret是一個用于有監督和無監督機器學習的作業流自動化工具,它被組織成六個模塊,每個模塊都有一組可用于執行某些特定操作的函式,每個函式接受一個輸入并回傳一個輸出,從第二個版本開始提供的模塊包括:
- Classification:https://www.pycaret.org/classification
- Regression:https://www.pycaret.org/regression
- Clustering:https://www.pycaret.org/clustering
- Anomaly Detection:https://www.pycaret.org/anomaly-detection
- Natural Language Processing:https://www.pycaret.org/nlp
- Association Rule Mining:https://www.pycaret.org/association-rules
PyCaret中的所有模塊都支持資料預處理(超過25種以上的基本預處理技術,提供大量未經訓練的模型和支持自定義模型、自動超引數調優、模型分析和可解釋性、自動模型選擇、實驗日志記錄和簡單的云部署選項),

要了解更多關于PyCaret的資訊,請單擊此處閱讀我們的官方發布公告:https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e
如果你想開始使用Python,請單擊此處查看要入門的示例Notebook的庫:https://github.com/pycaret/pycaret/tree/master/examples
在我們開始之前
在開始構建AutoML軟體之前,讓我們先了解以下術語,在這一點上,你所需要的是一些我們在本教程中使用的工具/術語的基本理論知識,如果你想了解更多詳細資訊,本教程末尾有一些鏈接供你稍后探索,
容器
容器(Containers)提供了一個可移植和一致的環境,可以在不同的環境中快速部署,以最大限度地提高機器學習應用程式的準確性、性能和效率,環境包含運行時語言(例如Python)、所有庫和應用程式的依賴項,
Docker
Docker是一家提供軟體(也稱為Docker)的公司,它允許用戶構建、運行和管理容器,雖然Docker的容器是最常見的,但也有其他不太著名的替代品,如LXD和LXC,也提供了容器解決方案,
github
GitHub是一個基于云的服務,用于托管、管理和控制代碼,假設你正在一個大型團隊中作業,其中多人(有時數百人)在同一個代碼庫上進行更改,PyCaret本身就是一個開源專案的例子,在這個專案中,數百名社區開發人員在不斷地為源代碼做貢獻,如果你以前沒有使用過GitHub,你可以注冊一個免費帳戶,
GitHub Action
GitHub操作(Action)可幫助你在存盤代碼和協作處理,實作自動化軟體開發作業流,你可以撰寫單個任務,并將它們組合起來以創建自定義作業流,
作業流是自定義的自動化流程,你可以在存盤庫中設定這些流程,以便在GitHub上構建、測驗、打包、發布或部署任何代碼專案,
目的
訓練和選擇基于資料集中的其他變數(即年齡、性別、bmi、兒童、吸煙者和地區)預測患者費用的最佳回歸模型,
步驟1-開發app.py
這是AutoML的主檔案,也是Dockerfile的入口點(請參見下面的步驟2),如果你以前使用過PyCaret,那么這個代碼你可以自行解釋,
import os, ast
import pandas as pd
dataset = os.environ["INPUT_DATASET"]
target = os.environ["INPUT_TARGET"]
usecase = os.environ["INPUT_USECASE"]
dataset_path = "https://raw.githubusercontent.com/" + os.environ["GITHUB_REPOSITORY"] + "/master/" + os.environ["INPUT_DATASET"] + '.csv'
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv(dataset_path)
data.head()
if usecase =='regression':
from pycaret.regression import *
elif usecase == 'classification':
from pycaret.classification import *
exp1 = setup(data, target = target, session_id=123, silent=True, html=False, log_experiment=True, experiment_name='exp_github')
best = compare_models()
best_model = finalize_model(best)
save_model(best_model, 'model')
logs_exp_github = get_logs(save=True)
https://github.com/pycaret/pycaret-git-actions/blob/master/app.py
前五行是關于從環境中匯入庫和變數,接下來的三行用于將資料作為pandas資料幀讀取,第12行到第15行是根據環境變數匯入相關模塊,第17行之后是PyCaret初始化環境、比較基本模型和在設備上保存性能最好的模型的函式,最后一行將實驗日志作為csv檔案下載,
步驟2-創建Dockerfile
Dockerfile只是一個包含幾行指令的檔案,它們保存在專案的檔案夾中,名為“Dockerfile”(區分大小寫,沒有擴展名),
另一種思考Docker檔案的方法是,它就像是你在自己的廚房里發明的食譜,當你和其他人分享這樣的菜譜時,如果他們按照食譜中完全相同的說明來做,他們將能夠以同樣的質量重現同一道菜,
類似地,你可以與其他人共享你的docker檔案,然后其他人可以基于該docker檔案創建鏡像并運行容器,
這個專案的Docker檔案很簡單,只包含6行,見下文:
FROM python:3.7-slim
WORKDIR /app
ADD . /app
RUN apt-get update && apt-get install -y libgomp1
RUN pip install --trusted-host pypi.python.org -r requirements.txt
ENTRYPOINT ["python"]
CMD ["/app/app.py"]
https://github.com/pycaret/pycaret-git-actions/blob/master/Dockerfile
Dockerfile中的第一行匯入python:3.7-slim,接下來的四行代碼創建一個app檔案夾,更新libgomp1庫,并從requirements.txt在本例中只需要pycaret的檔案,最后,最后兩行定義應用程式的入口點;這意味著當容器啟動時,它將執行我們前面在步驟1中看到的app.py檔案,
步驟3-創建action.yml
Docker操作需要元資料檔案,元資料檔案名必須是action.yml或者action.yaml. 元資料檔案中的資料定義操作的輸入、輸出和主入口點,操作檔案使用YAML語法,
name: "PyCaret AutoML Git Action"
description: "A simple example of AutoML created using PyCaret 2.0"
author: "Moez Ali"
inputs:
DATASET:
description: "Dataset for Training"
required: true
default: "juice"
TARGET:
description: "Name of Target variable"
required: true
default: "Purchase"
USECASE:
description: "Use-case Classification or Regression"
required: true
default: "classification"
outputs:
myOutput:
description: "Output from the action"
runs:
using: "docker"
image: "Dockerfile"
branding:
icon: 'box'
color: 'blue'
https://github.com/pycaret/pycaret-git-actions/blob/master/action.yml
環境變數dataset、target和usecase分別在第6、9和14行宣告,參見第4-6行,
步驟4-在GitHub上發布
此時,專案檔案夾應如下所示:
點擊“Releases”:

起草新版本:

填寫詳細資訊(標簽、發布標題和說明),然后單擊“Publish release”:
發布后,單擊“release”,然后單擊“Marketplace”:
單擊“Use latest version”:
保存此資訊,這是軟體的安裝詳細資訊,在任何公共GitHub存盤庫上安裝此軟體時,你需要這樣做:
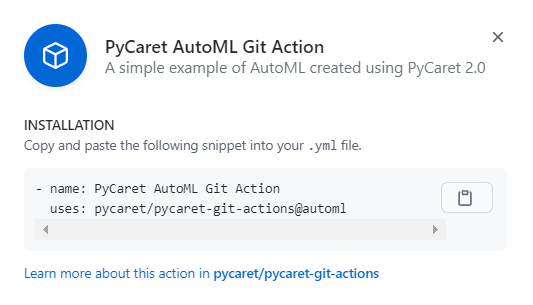
步驟5-在GitHub存盤庫上安裝軟體
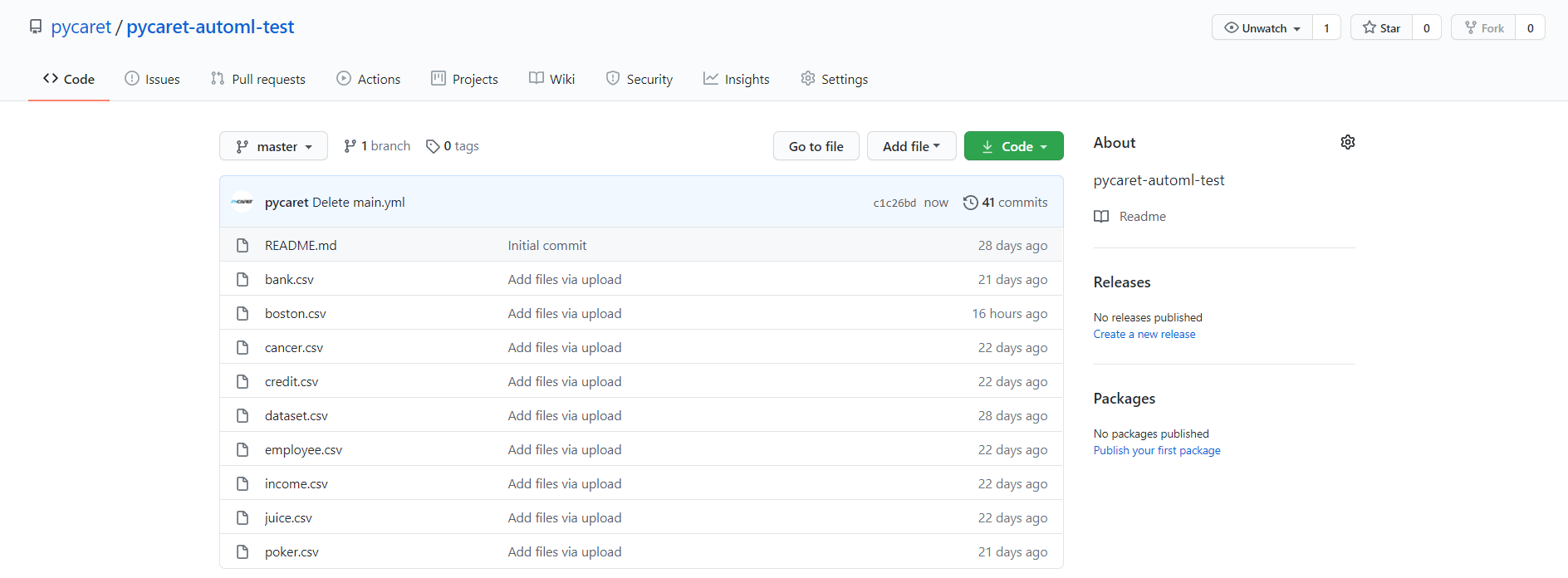
為了安裝和測驗我們剛剛創建的軟體,我們創建了一個新的存盤庫pycaret-automl-test:https://github.com/pycaret/pycaret-automl-test,并上傳了一些用于分類和回歸的示例資料集,
要安裝我們在上一步中發布的軟體,請單擊“Actions”:
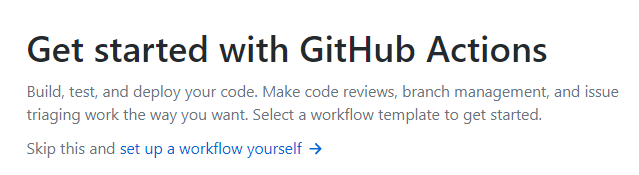
單擊“set up a workflow yourself”并將你的腳本復制到編輯器中,然后單擊“Start commit”,
開始提交后,單擊“actions”:
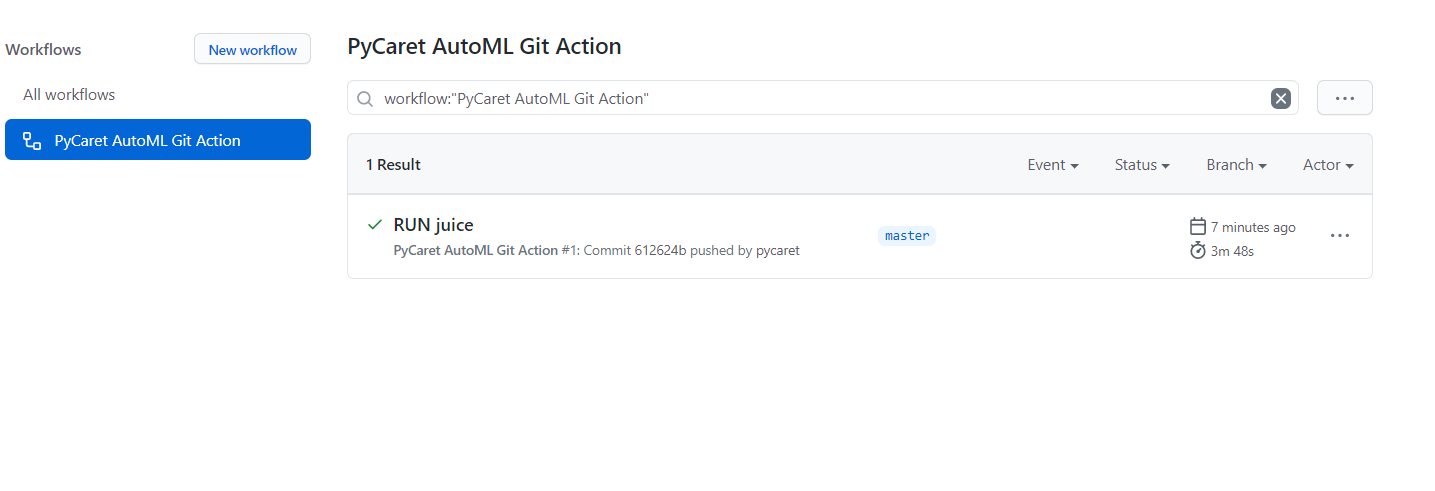
在這里,你可以在生成時監視生成的日志,并且一旦作業流完成,你也可以從此位置收集檔案,
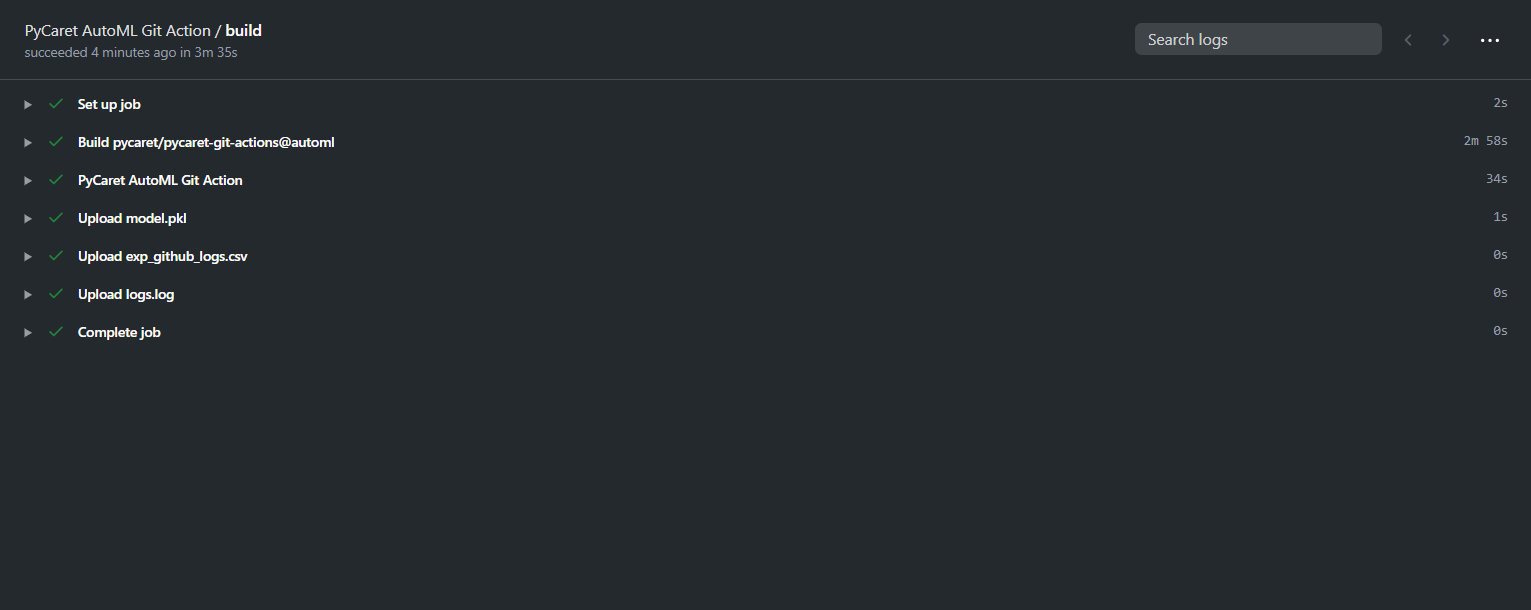
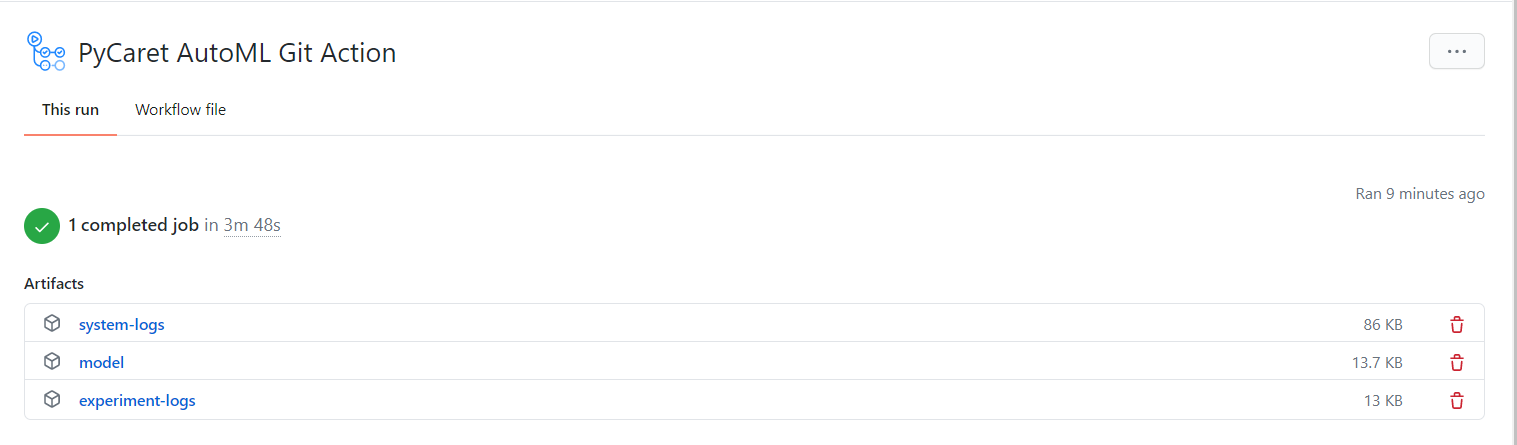
你可以下載這些檔案并將其解壓縮到你的設備上,
檔案:model
這是最終模型的.pkl檔案以及整個轉換管道,你可以使用此檔案使用predict_model函式在新資料集上生成預測,要了解更多資訊,請單擊此處:https://www.pycaret.org/predict-model
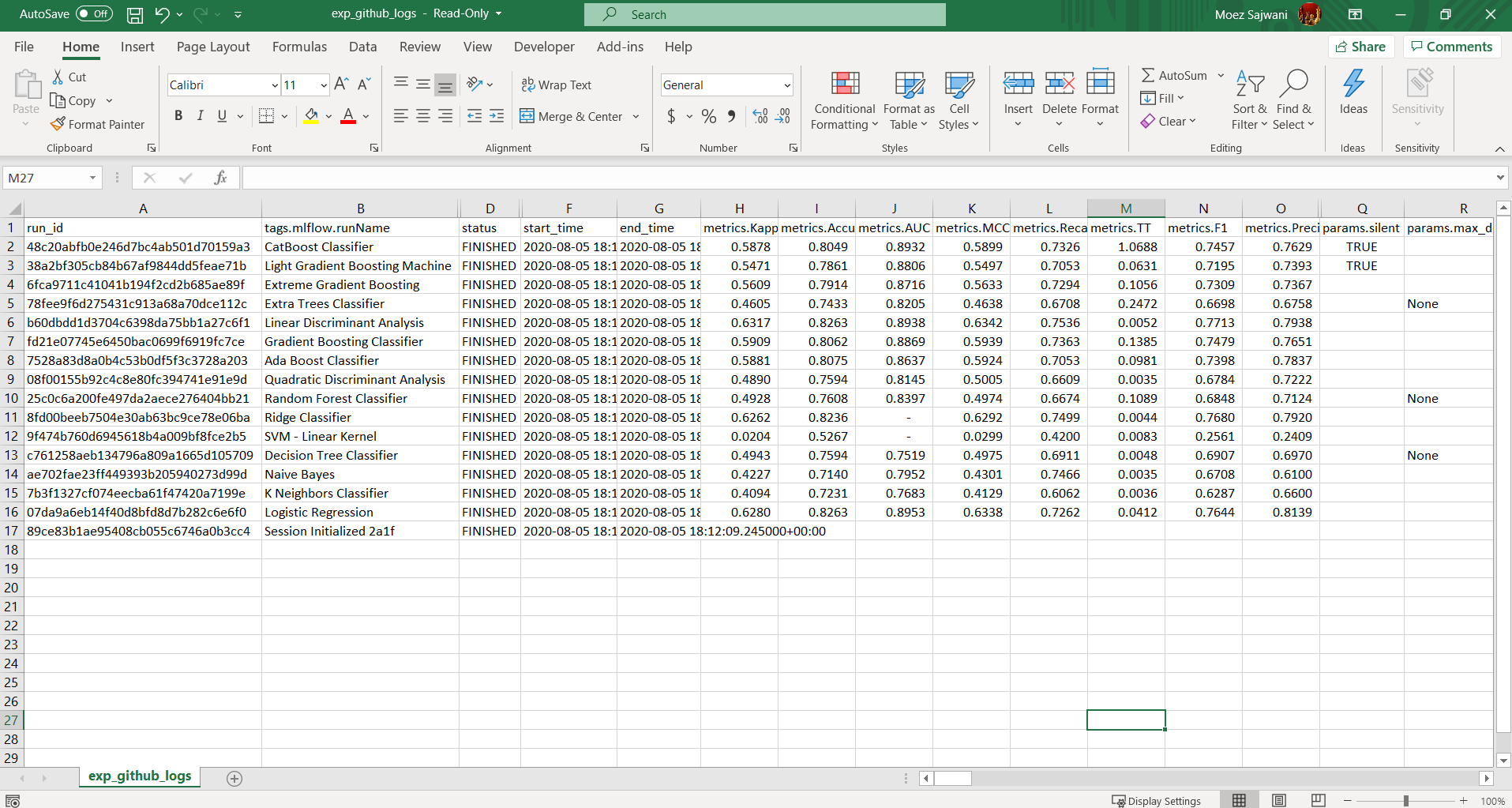
檔案:experiment-logs
這是一個.csv檔案,其中包含了模型所需的所有詳細資訊,它包含了在app.py中所有接受過訓練的模型,它們的性能指標,超引數和其他重要的元資料,
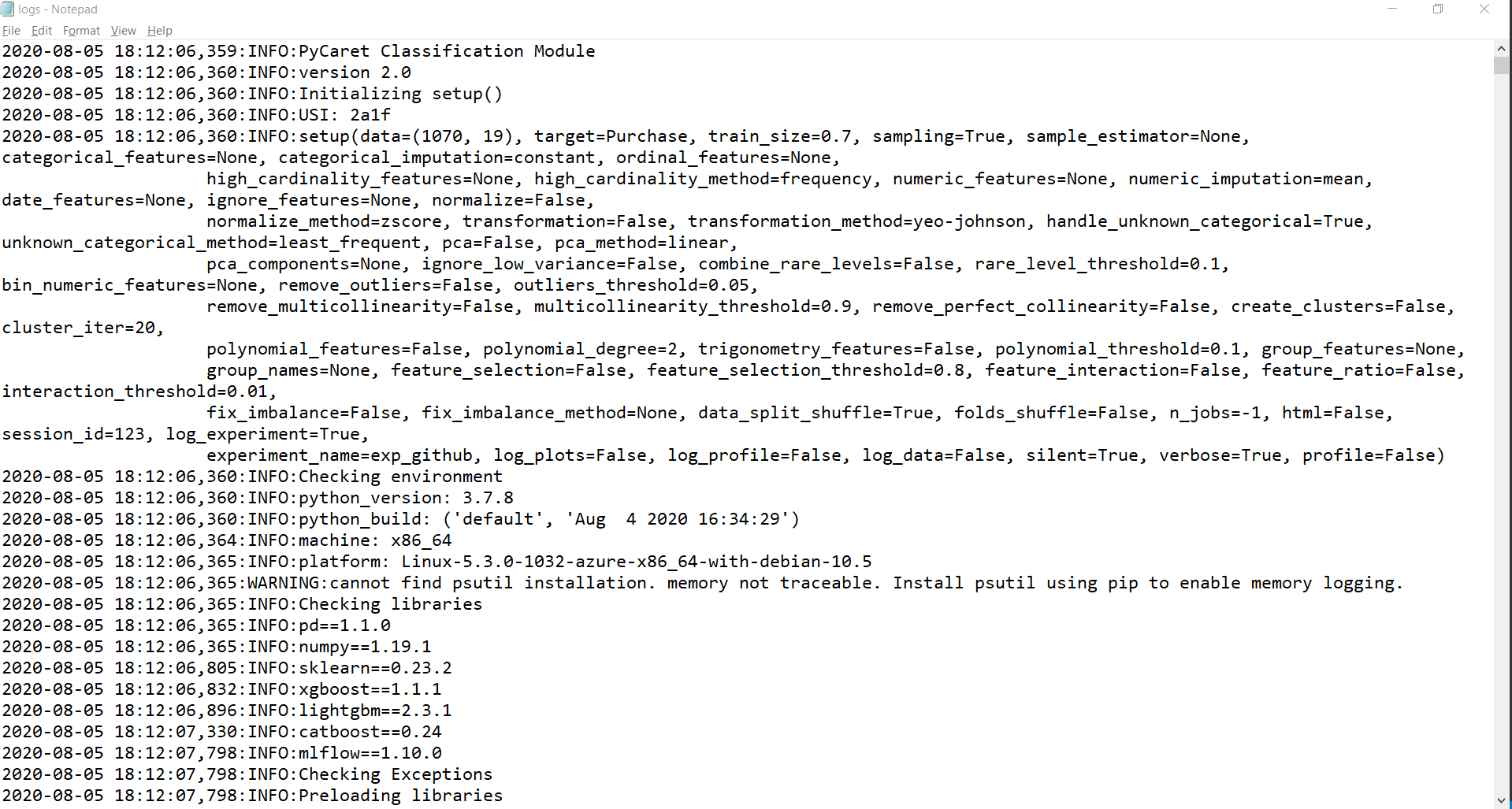
檔案:system-logs
這是PyCaret生成的系統日志檔案,這可用于審核流程,它包含重要的元資料資訊,對于解決軟體中的錯誤非常有用,
本教程中使用的存盤庫:
https://github.com/pycaret/pycaret-git-actions
https://github.com/pycaret/pycaret-automl-test
在Python中使用這個輕量級的作業流自動化庫可以實作的目標沒有限制,如果你覺得這個有用,請別忘了給我們我們的github專案star??,
想了解更多關于PyCaret的資訊,請訪問LinkedIn和Youtube,
LinkedIn:https://www.linkedin.com/company/pycaret/
Youtube:https://www.youtube.com/channel/UCxA1YTYJ9BEeo50lxyI_B3g
如果你想了解更多關于PyCaret 2.0的資訊,請閱讀本公告,如果你以前使用過PyCaret,那么你可能會對當前版本的發行說明感興趣,
想了解特定模塊嗎
單擊下面的鏈接查看檔案和作業示例,
- Classification:https://www.pycaret.org/classification
- Regression:https://www.pycaret.org/regression
- Clustering:https://www.pycaret.org/clustering
- Anomaly Detection:https://www.pycaret.org/anomaly-detection
- Natural Language Processing:https://www.pycaret.org/nlp
- Association Rule Mining:https://www.pycaret.org/association-rules
原文鏈接:https://towardsdatascience.com/github-is-the-best-automl-you-will-ever-need-5331f671f105
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/79684.html
標籤:其他