寫在前面:博主是一只經過實戰開發歷練后投身培訓事業的“小山豬”,昵稱取自影片片《獅子王》中的“彭彭”,總是以樂觀、積極的心態對待周邊的事物,本人的技術路線從Java全堆疊工程師一路奔向大資料開發、資料挖掘領域,如今終有小成,愿將昔日所獲與大家交流一二,希望對學習路上的你有所助益,同時,博主也想通過此次嘗試打造一個完善的技術圖書館,任何與文章技術點有關的例外、錯誤、注意事項均會在末尾列出,歡迎大家通過各種方式提供素材,
- 對于文章中出現的任何錯誤請大家批評指出,一定及時修改,
- 有任何想要討論和學習的問題可聯系我:zhuyc@vip.163.com,
- 發布文章的風格因專欄而異,均自成體系,不足之處請大家指正,
大資料到底應該如何學?
本文關鍵字:大資料專業、大資料方向、大資料開發、大資料分析、學習路線
文章目錄
- 大資料到底應該如何學?
- 一、食用須知
- 二、大資料的基本概念
- 1. 什么是大資料
- 2. 資料是如何采集的
- 3. 大資料真的能預測嗎
- 三、什么是大資料開發
- 四、什么是大資料分析
- 五、應如何學習大資料
一、食用須知
再更一篇技術雜談類的文章,,,粉絲甲:所以這就是你拖更系列文章和視頻的理由嗎???粉絲乙丙丁:就是!就是!都斷更多久了?我:咳,,,最近雜事纏身,還望恕罪!下面是食用須知:
- 本文適合還不十分了解大資料的你,同樣適合不確定要不要學習大資料的你,將帶你了解行業的需求以及與之相關的崗位,也同樣適合剛剛踏入大資料領域作業的你,歡迎收藏并將文章分享給身邊的朋友,
- 筆者從事大資料開發和培訓多年,曾為多家機構優化完整大資料課程體系,也為多所高校設計并實施大資料專業培養方案,并進行過多次大資料師資培訓、高校骨干教師學習交流,希望自己的一點粗淺認識能夠幫助到大家,
- 本文并不是要將大資料描述成一個萬能的、可以解決所有問題的東西,而是客觀的闡述其作用,能夠解決的一些問題,希望將這一領域盡可能完整的介紹給你,至于如何選擇需要根據自己的實際情況來決定,如果有任何問題可以在評論區留言或加入粉絲群與我直接交流,
二、大資料的基本概念
1. 什么是大資料
要說什么是大資料我想大家多少已經有所了解了,很多落地的案例已經深入到了我們的生活中,大資料具有資料量大、資料型別豐富復雜、資料增長速度快等特點,一切的資料分析必須建立在真實的資料集上才會有意義,而資料質量本身也是影響大資料分析結果的重要因素之一,
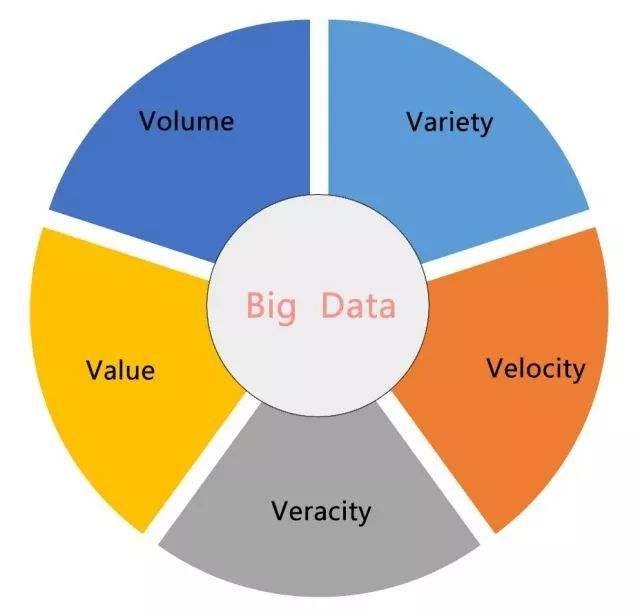
作為學習者,我們關心的應該是大資料能夠解決什么樣的問題,能夠應用在哪些領域,應該學習哪些內容,側重哪一方面,簡單來說,我們需要學習的就是一系列的大資料生態圈技術組件,以及貫穿整個資料分析流程的分析方法和思維,并且思路更加重要一些!只有明確了資料分析場景與流程,我們才能夠確定需要整合哪些大資料組件來解決這一問題,下面我們將一起推開這一領域的大門~
2. 資料是如何采集的
大資料分析的第一步就是對資料的收集和管理,我們需要先來了解一下資料是如何產生的?又是被如何捕獲的?那些看似雜亂的資料真的能被分析嗎?
- 主動的資料產生與用戶行為資料收集
主動產生的資料比較好理解,在我們使用互聯網或者各種應用的程序中,通過填寫提交表單就會產生資料,類似的,我們在線下環境中,比如銀行開卡、紙質表格的填寫,最終都會變成電子資料流入到系統中,通常,我們會將這一類行為歸為用戶注冊,通常會是產生資料的起點,(當然,有些時候我們分析的資料也可能并不關心用戶自身的資訊,)除此之外,通過使用一些平臺的功能,用戶會上傳和發布各種型別的資料,如文本類資訊、音頻、視頻等,這都是資料產生和積累的方式,
對于用戶行為資料更多的來自于應用埋點和捕獲,因為用戶使用應用必須通過滑鼠點擊或者手指觸碰來和用戶界面進行互動,以網頁應用(網站)為例,對于滑鼠的所有行為基本上都可以通過事件監聽的方式來捕獲,滑鼠在某個區域停留的時間、是否進行點擊,我們甚至可以根據用戶的行為資料刻畫出整個頁面的熱力圖,
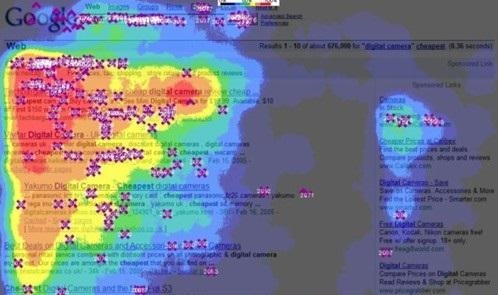
在不同的應用場景中,我們可以對行為型別、功能模塊、用戶資訊等維度進一步的劃分,做更加深入的分析,
- 結構化資料與非結構化資料
最常見的結構化資料就是存盤在關系型資料庫中的資料,如MySQL、Oracle等,這些資料都具備一個特點,就是十分規范,因為關系型資料庫屬于寫時模式,也就是說不符合預先設定的資料型別和規范的資料不會通過校驗,存不到資料庫中,除資料庫中的資料以外,那些能直接匯入到資料庫中的資料檔案我們也可以把它們視為結構化的資料,如:CSV格式,這些資料通常需要具備統一的列分隔符、行分隔符,統一的日期格式等等,
對于非機構化的資料指的就是除結構化資料以外的另一大類資料,通常沒有預期的資料機構,存盤在非關系型資料庫中,如:Redis、MongoDB,使用NoSQL來進行操作,也可能是非文本型別的資料,需要特別對應的手段來處理和分析,
3. 大資料真的能預測嗎
問起大資料到底能不能預測,倒不如來說一說大資料是如何預測的,如果結合人工智能領域來說的話就比較復雜了,就說比較簡單的場景:用統計分析的方法進行輔助決策,或者用經典資料挖掘演算法進行模型的訓練,既然是預測,那就有可能準確,也有可能不準確,分析者需要做的就是合理的使用各種資料維度,結合相應的演算法或統計分析方法,去訓練或擬合出一個潛在的規律,這個程序就好比,給了我們三個點(1,1)、(2,2)、(3,3),我們可以大概猜到它的函式式有可能為 y=x 一樣,當然,實際的分析程序要比這復雜的多得多,畢竟有很多函式式都可以滿足這三個點,但到底哪一個是我想要的規律呢?這就需要理論知識與行業經驗并重,不斷的打磨和優化才能夠得到一個可靠的模型,
但是我們可以明確的一點是,大資料的預測也好、推薦也好,都是基于演算法的,是數學的,也是科學的,但并不會百分之百的準確,
三、什么是大資料開發
了解了什么是大資料,接下來介紹一下大資料開發這一崗位,先直接上崗位描述(JD:Job Description)給大家感受一下,然后來說明一下大資料開發工程師的主要作業,最后再來總結一下需要掌握的技能,
- 京東大資料開發工程師JD:

- 小米大資料開發工程師JD:

- 滴滴大資料開發工程師JD:

- 主要作業
從上面的崗位描述中我們可以發現大資料開發工程師一般會與業務進行對接,要么是基于某一個場景進行有針對性的資料處理,要么是打造一個大資料產品,在這里我們也需要糾正一個小小的概念,可能有些小伙伴認為有大資料崗位需求的公司一定是一個自身具備大量資料、有著大量用戶積淀的公司,其實不然,除了分析公司自身業務資料以外,同樣可以打造一款通用的大資料產品,大家可以參考我的另一篇文章:如何用開源組件“攢”出一個大資料建模平臺,所以大資料的崗位雖然不像普通的開發工程師那么多,但是需求依然存在,
如果是分析公司自身的業務資料,一般會更偏重于使用大資料組件和演算法庫,構建出一個可行的資料分析方案,大家可以看出,現在完全不涉及演算法的大資料崗位已經比較少了,這里的演算法指的并不是資料結構,而是指機器學習庫,與資料挖掘相關的演算法,至少要知道如何控制演算法的輸入與輸出,演算法能夠解決的問題,可能不會涉及到親自建模,在大資料分析的小節中會詳細介紹,

如果是開發一個大資料產品,比如建模平臺,或者是致力于解決資料采集、資料可視化的解決方案,那么這比較適合從開發工程師轉行大資料開發工程師的小伙伴,相當于在開發一個應用的基礎上又增加了底層的大資料組件,這就要求我們既需要懂得原始的服務端框架的那一套,又能夠駕馭大資料開發API,
- 掌握技能
從事大資料開發需要掌握的技能可以概括為以下幾個方面:
- 作業系統:Linux(基本操作、軟體維護、權限管理、定時任務、簡單Shell等)
- 編程語言:Java(主要)、Scala、Python等
- 資料采集組件及中間件:Flume、Sqoop、Kafka、Logstash、Splunk等
- 大資料集群核心組件:Hadoop、Hive、Impala、HBase、Spark(Core、SQL、Streaming、MLlib)、Flink、Zookeeper等
- 素養要求:計算機或大資料相關專業
四、什么是大資料分析
說到資料分析師,這不是本文的重點,因為門檻相對較高,另一方面更偏數學、統計學方向,更多的是與資料、演算法打交道,編程的產物通常不是應用,而是一個演算法模型,我們還是先來看一看相關的JD:
- 小紅書資料分析師JD:

- 京東資料分析師JD:

- 新浪微博資料分析師:

- 主要作業:
如果說大資料開發的崗位需求是一條一條的話,,,那么資料分析師的崗位需求大概率是一篇一篇的,,,從上面的要求的中可以看到,每一個崗位都講業務場景介紹的很詳細,畢竟,資料分析師的主要作業之一是建立演算法模型,這是垂直領域的深耕,通常我們無法直接使用那些已經存在的演算法,必須要進行評估、優化、或是組合使用,除此之外,你還必須擁有這一領域的業務經驗,才能夠很好的勝任,
- 掌握技能:
演算法工程師需要掌握的技能可以概括為以下幾個方面:
- 編程語言:Python、R、SQL等
- 建模工具:MATLAB、Mathematica等
- 熟悉機器學習庫及資料挖掘經典演算法
- 數學、統計學、計算機相關專業,對資料敏感
五、應如何學習大資料
上面介紹了和大資料相關的兩個主要作業崗位,其實與大資料相關的崗位還有很多,真正歸納起來,ETL工程師也可以說擦邊,因為隨著資料量的不斷增大,無論是銀行內部還是大資料服務公司都在從傳統ETL工具向大資料集群進行過渡,
涉及到了這么多的技術點,如何學習才更加高效呢?首先好入門的自然是大資料開發,對于Linux的作業系統和編程語言的部分沒什么過多說明的,不要覺得有些東西沒用就跳過,有些時候編程思想和解決問題的方法同樣很重要,課本上有的一定要扎實,對于和大資料相關的組件,看上去十分的繁雜,很多小伙伴可能都是鉆研于每個組件的用法、算子、函式、API,這當然沒有錯,但是同時一定不要忘記埋在其中的主線,那就是:完整的資料分析流程,在學習的程序中一定要了解各組件的特點、區別和應用的資料場景,
- 離線計算
在離線計算場景下,使用的都是歷史資料,也就是不會再發生改變的資料,在資料源確定以后,這些資料不會再增加、也不會再更新,比較適合對實時性要求不高的場景,大多數情況下是周期性的計算某一個指標或執行一個Job,運算耗時基本上可以控制在分鐘級,
- 資料源:資料檔案、資料庫中的資料等
- 資料采集:Sqoop、HDFS資料上傳、Hive資料匯入等
- 資料存盤:HDFS
- 資料分析:MapReduce、Hive QL
- 計算結果:Hive結果表(HiveJDBC查詢)、匯出至關系型資料庫
- 實時計算
實時計算所面對的資料是不斷的流入的,要能夠使用合適的組件處理實時流入的資料,有些時候單位時間內的資料流入會比較多,消費的比較慢,有些時候單位時間內的資料流入會比較少,消費的會比較快,所以在采集資料時一方面要保證資料不丟失,同時還需要有中間件來管理好資料,在進行實時計算時可以使用微批次的方式也可以使用其他方式,同時要處理好計算結果合并的問題,實時展示最新的結果,
- 資料源:日志檔案增量監聽等
- 資料采集:Flume
- 中間件:Kafka
- 資料分析:Spark-Streaming,Flink等
- 計算結果:HBase
以上只是簡單的列舉了一些實作不同場景資料流程的組件整合方案,詣在告訴大家一定要善于發現和總結不同組件的特點,把合適的組件放在合適的位置,這也是面試官經常喜歡問的場景題目,其實每個組件的使用方法和呼叫API并沒有很復雜,重點還是在于流程化、一體化、把組件之間連接起來,不斷的滲透和強化資料分析和處理的思路,能夠把一個需求直接翻譯成資料分析方案,這才是學習的重點,
本文的所有內容都只是個人的一點粗淺的認識,只適合剛入門學習或剛從事相關作業的小伙伴進行參考,有任何不對的地方希望大家包涵,如果有任何的疑問,歡迎掃描二維碼,加入粉絲群,


 CSDN認證博客專家
全堆疊開發工程師
大資料高級開發
大資料金牌講師
CSDN認證博客專家
全堆疊開發工程師
大資料高級開發
大資料金牌講師
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/80375.html
標籤:其他