有這些東西
- 前言
- 菜雞作者的話
- 正文
- 計算器病毒傳染的必要條件
- 計算機病毒特點
- 光驅
- 除錯借調期(調節器)
- 網關
- Web1.0和Web2.0的區別
- Web1.0
- Web2.0
- 面向物件程式設計
- 計算機指令系統
- 十進制轉二進制小數部分
- 原碼反碼補碼
- BCD碼(8421碼)
- 浮點數
- 兩個網路協議的配對關系
- 網路IP地址
- 一個不能在 Linux 上用的瀏覽器
- 邏輯運算
- 集合運算
- 有重復元素的排列組合問題
- 錯排問題
- 競賽環境
- 競賽推薦語言
- NOIP啥時候不能用Pascal了
- NOI與NOIP的歷史
前言
菜雞作者的話
準備要初賽了,一想起我那菜的說不出話的初賽,我就慌得一批,
于是,我就把一些覺得不會或者因為知識點遺漏錯了的東西收集起來,放在一起,
當然,有一些東西參考了一些其他人的文章,
正文
計算器病毒傳染的必要條件
- 系統運行(這樣它才能“動”)
- 讀寫硬碟(這樣才可以將自身復制到其他程式)(這個好像是最必要的)
計算機病毒特點
傳播性、潛伏性、破壞性與隱蔽性
光驅
電腦用來讀寫光碟內容的機器(光碟驅動器?)
除錯借調期(調節器)
夠對數字信號和模擬信號進行相互轉換的設備
網關
一個在傳輸層上以實作網路互連的東西,
廣域網和局域網都可以用,大多數運行在OSI 7層協議的頂層–應用層,
Web1.0和Web2.0的區別
Web1.0
主要是靠點擊流量來盈利,論壇不算是Web2.0的特征,
例子:谷歌,騰訊,新浪,網易,搜狐,MSM
Web2.0
這個東西里面許多東西是由用戶貢獻出來的,資訊是由每個人貢獻出來的,每個人都是投稿者,
(雖然貢獻的許多內容只是由小部分的人貢獻的)
博客,社區這些東西就是十分鮮明的特征,
例子:Flickr,維基,眾多博客(就比如csdn),
面向物件程式設計
繼承性,封裝性,多型性
面向物件的編程語言的例子:C++,JAVA,C#
(C和pascal是結構化的編程語言)
雛形:Simula 語言
經典:SmallTalk 語言,現在還是面向物件語言的基礎,
面向程序程式才是“自頂向下,逐步求精”,而面向物件程式設計并不是,而是基于問題物件的自底向上的設計方法,
(就是物件是下到上,程序是上到下)
計算機指令系統
計算機直接識別和執行的命令就是指令,
一條指令通常由操作碼和地址碼兩部分組成,
操作碼:這個操作的性質和功能
地址碼:被操作的東西在哪里
十進制轉二進制小數部分
(
0.25
)
10
(0.25)_{10}
(0.25)10?
0.25
×
2
=
0.5
0.25\times 2=0.5
0.25×2=0.5(整數部分為
0
0
0 )
然后不要整數部分,變成
0.5
0.5
0.5
0.5
×
2
=
1.0
0.5\times 2=1.0
0.5×2=1.0(整數部分為
1
1
1 )
然后不要整數部分,變成
0.0
0.0
0.0
結束,順著數,就是
(
0.01
)
2
(0.01)_{2}
(0.01)2?
原碼反碼補碼
(原碼反碼的+為string::operator+)(就是直接在字串前面加一個 0 或者 1 )
原碼:
- x>0:0+x
- x<0:1+x
反碼:
- x>0:x原
- x<0:1+(~x)
(補碼的+為int::operator+)(就是直接普通加減乘除的加)
補碼:
- x>0:x原
- x<0:x反+1
8位二進制原碼、反碼、補碼
| 真值 | 原碼(B) | 反碼(B) | 補碼(B) |
|---|---|---|---|
| +127 | 0 111 1111 | 0 111 1111 | 0 111 1111 |
| +38 | 0 010 0110 | 0 010 0110 | 0 010 0110 |
| +0 | 0 000 0000 | 0 000 0000 | 0 000 0000 |
| -0 | 1 000 0000 | 1 111 1111 | 0 000 0000 |
| -38 | 1 010 0110 | 1 101 1001 | 1 101 1010 |
| -127 | 1 111 1111 | 1 000 0000 | 1 000 0001 |
| -128 | 無法表示 | 無法表示 | 1 000 0000 |
對于最后一個的解釋:
前兩個裝不下,因為有九位,第三個可以裝下是因為當數是 +/-0 的時候,補碼都是 0 000 0000,那就可以用 1 000 0000 來表示,
(所以補碼很nb,但是它區分不了+0和-0)
(但我不太知道把 0 分成 +0 和 -0 是干嘛用的)
BCD碼(8421碼)
用二進制代碼表示的十進制數,就是把每一位拆開,每一個數都變成二進制,然后再拼起來,
浮點數
這個完全很懵,看了很久才勉強知道一點,
我看的是這個博客的第八點吧:
點
我
查
看
點我查看
點我查看
至于怎么轉換出浮點數,我說不清楚,理解就行了,就不寫了,直接看這位大佬的博客吧,
我就放一點我覺得要背的東西吧:
一個規格化的32位浮點數x的真值為:
x=(-1)s×(1.M)×2^(E-127)
一個規格化的64位浮點數x的真值為:
x=(-1)s×(1.M)×2^(E-1023)
然后有一些特殊的數,這個是 32 位浮點數的表示方法
零值:E=0 & M=0 若sgn>0,+0 若sgn<0,-0 規定:+0=-0
無窮值:E=11111111(2) & M=0 若sgn>0,+∞ 若sgn<0,-∞
NAN:E=0 & M≠0
( sgn 就是看函式的值是正的還是負的)
兩個網路協議的配對關系
| OSI | TCP/IP |
|---|---|
| 應用層 | 應用層 |
| 表示層 | |
| 會話層 | |
| 傳輸層 | 傳輸層 |
| 網路層 | 網路層 |
| 資料鏈路層 | 網路介面 |
| 物理層 |
除此之外還有 Netbeui 和 IP 這兩個協議,
網路IP地址
為Internet中的每一臺主機分配一個在全球范圍唯一地址
四個數字,用 “.” 分開,每個數字范圍是 0 ~ 255 0\sim 255 0~255 ,
A類:0.0.0.0 - 127.255.255.255
(標準子網掩碼:255.0.0.0 或 /8)
B類:128.0.0.0 - 191.255.255.255
(標準子網掩碼:255.255.0.0 或 /16)
C類:192.0.0.0 - 223.255.255.255
(標準子網掩碼:255.255.255.0 或 /24)
(/8 這個就是說換成二進制之后左邊有 8 個 1,其它也是這個道理)
關于地址資訊還有其它定位的劃分方式:
- A類網路以0開頭,網路號碼是7位,主機號碼是24位(大型網路)
- B類網路以10開頭,網路號碼是14位,主機號碼是16位(中型網路)
- C類網路以110開頭,C類網路的網路號碼是21位,主機號碼是8位(小型網路)
- D類地址以1110開頭,E類地址以11110開頭,
一個不能在 Linux 上用的瀏覽器
微軟和LINUX不太相好(好像是),所以不能用 IE(Internet Explore) ,
邏輯運算
與:and :
∧
∧
∧ 或者
?
·
?
或:or :
∨
∨
∨ 或者
+
+
+
異或:xor:
⊕
⊕
⊕
非:not : ? 或者 ¬
非
>
>
> 與
>
>
> 或和異或
集合運算
并:∪
交:∩
補: ^ 或
~
\sim
~ 或著這樣表示:
差: -
有重復元素的排列組合問題
- 排列:
m
m
m 種不同元素,每種有
n
i
n_i
ni? 個,答案就是這個:
( n 1 + n 2 + . . . + n m ) ! n 1 ! ? n 2 ! ? . . . ? n m ! \frac{(n_1+n_2+...+n_m)!}{n_1!*n_2!*...*n_m!} n1?!?n2?!?...?nm?!(n1?+n2?+...+nm?)!? - 組合:
n
n
n 種不同元素選
m
m
m 個,允許有重復元素,答案是這個:
C n + m ? 1 m C^{m}_{n+m-1} Cn+m?1m?
錯排問題
遞推,式子是
f
(
n
)
=
(
n
?
1
)
?
(
f
(
n
?
1
)
+
f
(
n
?
2
)
)
f(n)=(n-1)*(f(n-1)+f(n-2))
f(n)=(n?1)?(f(n?1)+f(n?2)) ,
初始化為
f
(
1
)
=
0
,
f
(
2
)
=
1
f(1)=0,f(2)=1
f(1)=0,f(2)=1
就是第
n
n
n 個數和其他錯排完的
n
?
1
n-1
n?1 任意一個交換,或者第
n
n
n 個數先和任意一個其他的數交換,剩下的再錯排,
有一個奇妙的計算公式,我不知道是怎么弄出來的:
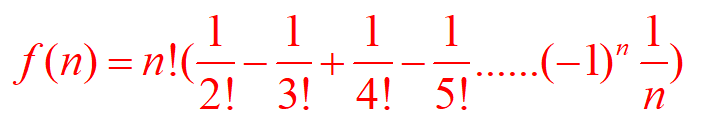
競賽環境
點 我 查 看 點我查看 點我查看
競賽推薦語言
Visual C++不是競賽推薦語言
不是的還有 TP7 和 TC ,
Lazarus 是(pascal類),RHIDE 也是(C++類),
NOIP啥時候不能用Pascal了
2019 和 2022 以及 2020 之后,
(2019 是因為這一年沒有NOIP)
NOI與NOIP的歷史
第一屆 NOI :1984年,鄧小平:“計算機的普及要從娃娃做起,”
第一屆 NOIP :1995年
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/80403.html
標籤:其他
上一篇:C++形參帶默認值的函式