在這篇文章中,我們將構建一個基于LSTM的Seq2Seq模型,使用編碼器-解碼器架構進行機器翻譯,
本篇文章內容:
- 介紹
- 資料準備和預處理
- 長短期記憶(LSTM) - 背景知識
- 編碼器模型架構(Seq2Seq)
- 編碼器代碼實作(Seq2Seq)
- 解碼器模型架構(Seq2Seq)
- 解碼器代碼實作(Seq2Seq)
- Seq2Seq(編碼器+解碼器)介面
- Seq2Seq(編碼器+解碼器)代碼實作
- Seq2Seq模型訓練
- Seq2Seq模型推理
1.介紹
神經機器翻譯(NMT)是一種機器翻譯方法,它使用人工神經網路來預測一個單詞序列的可能性,通常在一個單一的集成模型中建模整個句子,
對于計算機來說,用一個簡單的基于規則的系統從一種語言轉換成另一種語言是最困難的問題之一,因為它們無法捕捉到程序中的細微差別,不久之后,我們開始使用統計模型,但在進入深度學習之后,這個領域被統稱為神經機器翻譯,現在已經取得了最先進的成果,
這篇文章是針對于初學者的,所以一個特定型別的架構(Seq2Seq)顯示了一個好的開始,這就是我們要在這里實作的,
因此,本文中的序列對序列(seq2seq)模型使用了一種編碼器-解碼器架構,它使用一種名為LSTM(長短期記憶)的RNN,其中編碼器神經網路將輸入的語言序列編碼為單個向量,也稱為背景關系向量,
這個背景關系向量被稱為包含輸入語言序列的抽象表示,
然后將這個向量傳遞到解碼器神經網路中,用解碼器神經網路一個詞一個詞地輸出相應的輸出語言翻譯句子,
這里我正在做一個德語到英語的神經機器翻譯,但同樣的概念可以擴展到其他問題,如命名物體識別(NER),文本摘要,甚至其他語言模型,等等,
2.資料準備和預處理
為了以我們想要的最佳方式獲取資料,我使用了SpaCy(詞匯構建)、TorchText(文本預處理)庫和multi30k dataset,其中包含英語、德語和法語的翻譯序列
讓我們看看它能做的一些程序,
-
訓練/驗證/測驗分割:將資料分割到指定的訓練/驗證/測驗集,
-
檔案加載:加載各種格式(.txt、.json、.csv)的文本語料庫,
-
分詞:把句子分解成一串單詞,
-
從文本語料庫生成一個詞匯表串列,
-
單詞編碼:將單詞映射為整個語料庫的整數,反之亦然,
-
字向量:將字從高維轉換為低維(字嵌入),
-
批處理:生成批次的樣品,
因此,一旦我們了解了torch文本可以做什么,讓我們談談如何在torch text模塊中實作它,在這里,我們將利用torchtext下的3個類,
Fields :這是torchtext下的一個類,在這里我們指定如何在我們的資料庫里進行預處理,
TabularDataset:我們實際上可以定義以CSV、TSV或JSON格式存盤的列資料集,并將它們映射為整數,
BucketIterator:我們可以填充我們的資料以獲得近似,并使用我們的資料批量進行模型訓練,
這里我們的源語言(SRC - Input)是德語,目標語言(TRG - Output)是英語,為了有效的模型訓練,我們還額外增加了兩個令牌“序列開始”和“序列結束”,
!pip install torchtext==0.6.0 --quiet
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import numpy as np
import pandas as pd
import spacy, random
## Loading the SpaCy's vocabulary for our desired languages.
!python -m spacy download en --quiet
!python -m spacy download de --quiet
spacy_german = spacy.load("de")
spacy_english = spacy.load("en")
def tokenize_german(text):
return [token.text for token in spacy_german.tokenizer(text)]
def tokenize_english(text):
return [token.text for token in spacy_english.tokenizer(text)]
german = Field(tokenize=tokenize_german, lower=True,
init_token="<sos>", eos_token="<eos>")
english = Field(tokenize=tokenize_english, lower=True,
init_token="<sos>", eos_token="<eos>")
train_data, valid_data, test_data = Multi30k.splits(exts = (".de", ".en"),
fields=(german, english))
german.build_vocab(train_data, max_size=10000, min_freq=3)
english.build_vocab(train_data, max_size=10000, min_freq=3)
print(f"Unique tokens in source (de) vocabulary: {len(german.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(english.vocab)}")
******************************* OUTPUT *******************************
Unique tokens in source (de) vocabulary: 5376
Unique tokens in target (en) vocabulary: 4556
在設定了語言預處理標準之后,下一步是使用迭代器創建成批的訓練、測驗和驗證資料,
創建批是一個詳盡的程序,幸運的是我們可以利用TorchText的迭代器庫,
這里我們使用BucketIterator來有效填充源句和目標句,我們可以使用.src屬性訪問源(德語)批資料,使用.trg屬性訪問對應的(英語)批資料,同樣,我們可以在標記之前看到資料,
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 32
train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch=True,
sort_key=lambda x: len(x.src),
device = device)
# Dataset Sneek peek before tokenizing
for data in train_data:
max_len_ger.append(len(data.src))
max_len_eng.append(len(data.trg))
if count < 10 :
print("German - ",*data.src, " Length - ", len(data.src))
print("English - ",*data.trg, " Length - ", len(data.trg))
print()
count += 1
print("Maximum Length of English Sentence {} and German Sentence {} in the dataset".format(max(max_len_eng),max(max_len_ger)))
print("Minimum Length of English Sentence {} and German Sentence {} in the dataset".format(min(max_len_eng),min(max_len_ger)))
************************************************************** OUTPUT **************************************************************
German - zwei junge wei?e m?nner sind im freien in der n?he vieler büsche . Length - 13
English - two young , white males are outside near many bushes . Length - 11
German - ein mann in grün h?lt eine gitarre , w?hrend der andere mann sein hemd ansieht . Length - 16
English - a man in green holds a guitar while the other man observes his shirt . Length - 15
German - ein mann l?chelt einen ausgestopften l?wen an . Length - 8
English - a man is smiling at a stuffed lion Length - 8
German - ein schickes m?dchen spricht mit dem handy w?hrend sie langsam die stra?e entlangschwebt . Length - 14
English - a trendy girl talking on her cellphone while gliding slowly down the street . Length - 14
German - eine frau mit einer gro?en geldb?rse geht an einem tor vorbei . Length - 12
English - a woman with a large purse is walking by a gate . Length - 12
German - jungen tanzen mitten in der nacht auf pfosten . Length - 9
English - boys dancing on poles in the middle of the night . Length - 11
Maximum Length of English Sentence 41 and German Sentence 44 in the dataset
Minimum Length of English Sentence 4 and German Sentence 1 in the dataset
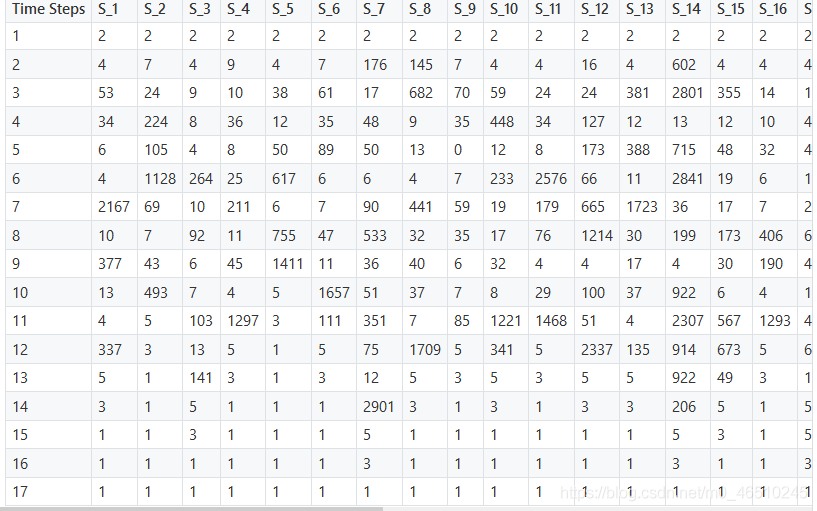
我剛剛試驗了一批大小為32和樣本批如下所示,這些句子被標記成一個單詞串列,并根據詞匯索引,“pad”標記的索引值為1,
每一列對應一個句子,用數字索引,在單個目標批處理中有32個這樣的句子,行數對應于句子的最大長度,短句用1來填充以彌補其長度,
下表包含批處理的數字索引,這些索引稍后被輸入到嵌入的單詞中,并轉換為密集表示,以便進行Seq2Seq處理,
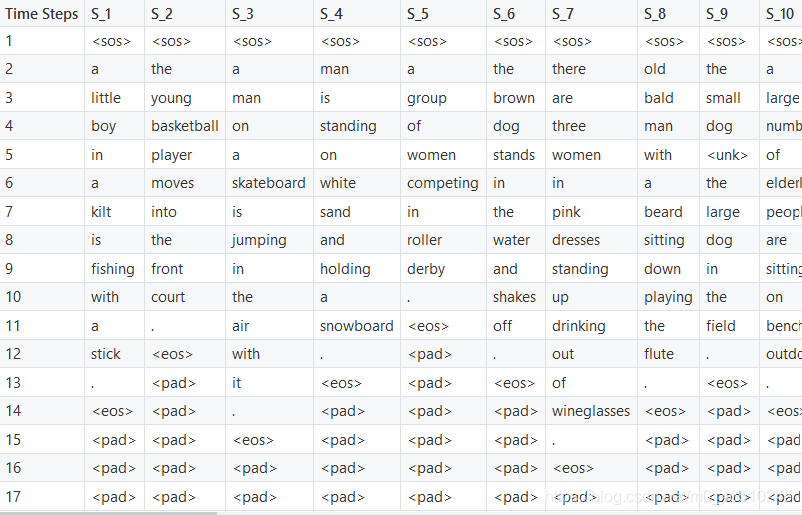
下表包含與批處理的數字索引映射的對應單詞,
3.長短期記憶(LSTM)背景知識
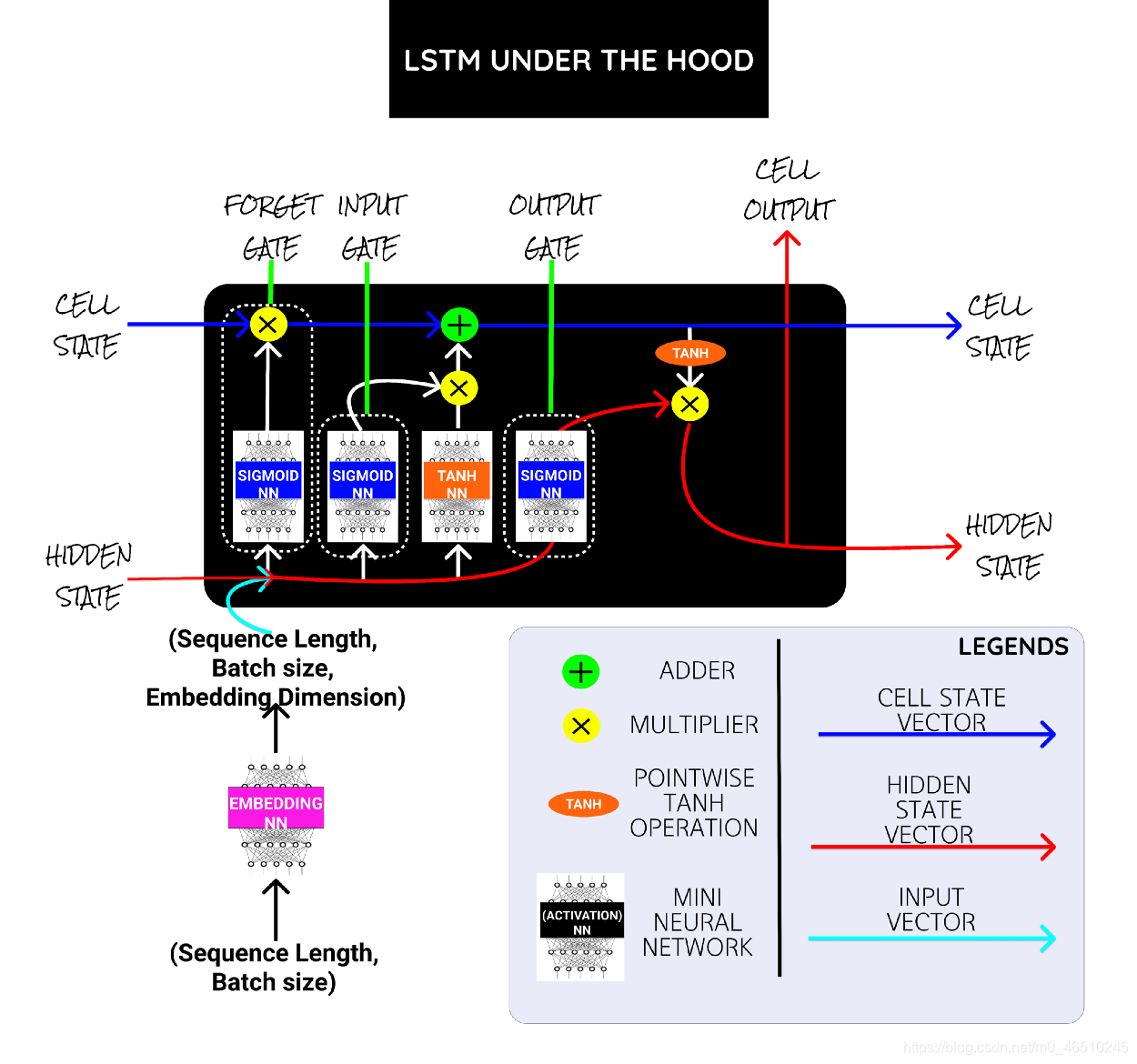
上面的圖片顯示了在單個LSTM單元下的計算,在最后一篇文章中,我將添加一些參考資料來學習更多關于LSTM的知識,以及為什么它適用于長序列,
但簡單地說,傳統RNN和門控(GRU)是無法捕捉的長期依賴性因其自然消失的梯度設計和遭受嚴重的問題,這使得權重和偏置值的變化率可以忽略不計,導致器泛化性的降低,
但是LSTM有一些特殊的單元稱為門(記憶門,忘記門,更新門),這有助于克服前面提到的問題,
在LSTM細胞內,我們有一堆小型神經網路,在最后一層有sigmoid 和TanH激活和少量矢量加法,連接,乘法操作,
Sigmoid NN→壓縮0到1之間的值,說接近0的值表示忘記,而接近1的值表示記住,
EmbeddingNN→將輸入的單詞索引轉換為單詞嵌入,
TanH NN→壓縮-1和1之間的值,有助于調節矢量值,使其免于爆炸至最大值或縮小至最小值,
隱藏狀態和單元狀態在此稱為背景關系向量,它們是LSTM單元的輸出, 輸入則是輸入到嵌入NN中的句子的數字索引,
4.編碼器模型架構(Seq2Seq)
在開始構建seq2seq模型之前,我們需要創建一個Encoder,Decoder,并在seq2seq模型中創建它們之間的介面,
讓我們通過德語輸入序列“ Ich Liebe Tief Lernen”,該序列翻譯成英語“ I love deep learning”,
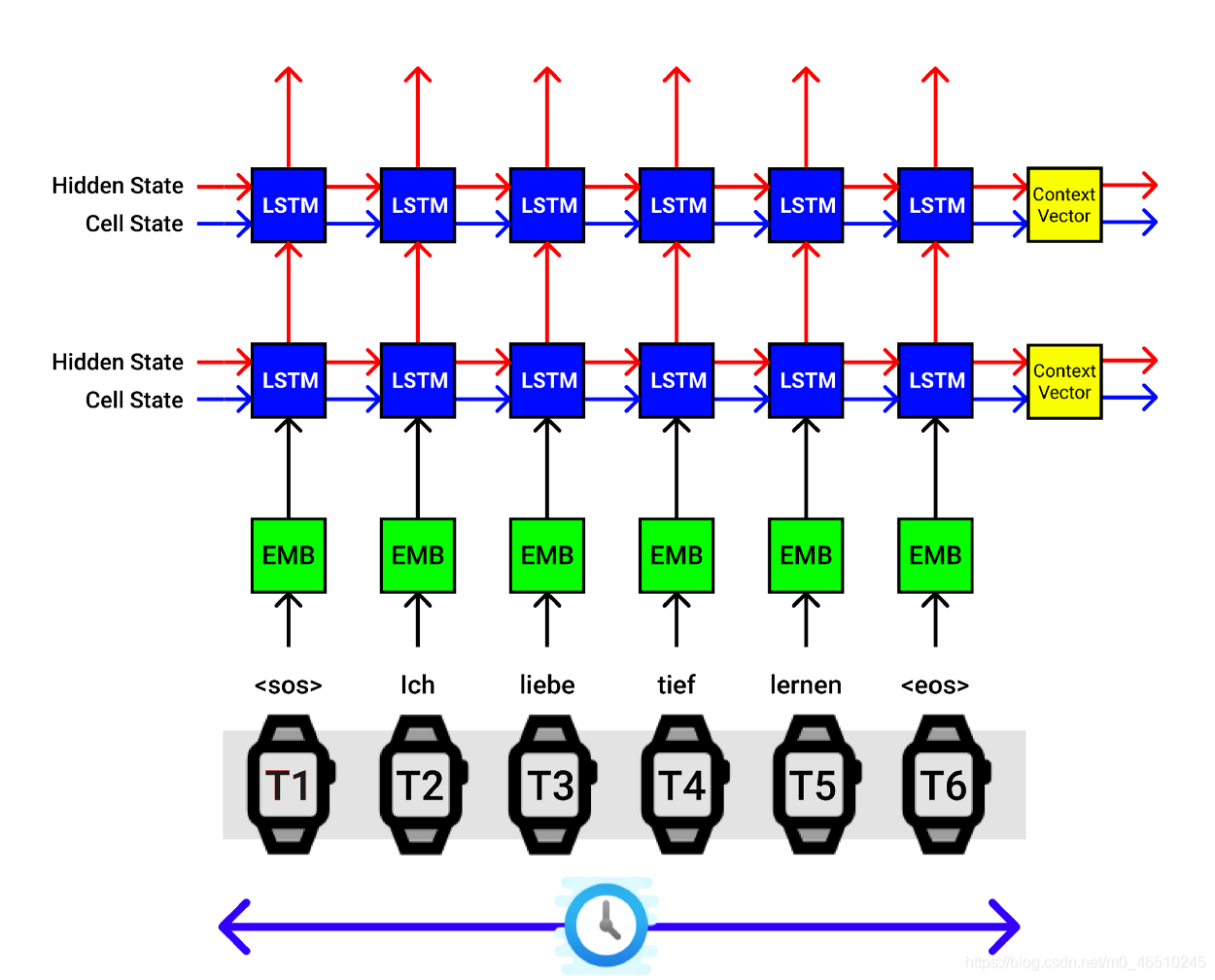
LSTM編碼器體系結構, X軸對應于時間步長,Y軸對應于批量大小
為了便于說明,讓我們解釋上圖中的程序, Seq2Seq模型的編碼器一次只接受一個輸入, 我們輸入的德語單詞序列為“ ich Liebe Tief Lernen”,
另外,我們在輸入句子的開頭和結尾處附加序列“ SOS”的開頭和句子“ EOS”標記的結尾,
因此在
- 在時間步0,發送“ SOS”
- 在時間步1,發送“ ich”
- 在時間步2,發送“ Liebe”
- 在時間步3,發送“ Tief”
- 在時間步4,發送“ Lernen”
- 在時間步5,發送“ EOS”
編碼器體系結構中的第一個塊是單詞嵌入層(以綠色塊顯示),該層將輸入的索引詞轉換為被稱為詞嵌入的密集向量表示(大小為100/200/300),
然后我們的詞嵌入向量被發送到LSTM單元,在這里它與隱藏狀態(hs)組合,并且前一個時間步的單元狀態(cs)組合,編碼器塊輸出新的hs和cs到下一個LSTM單元,可以理解,到目前為止,hs和cs捕獲了該句子的某些矢量表示,
在時間步0,隱藏狀態和單元狀態被完全初始化為零或亂數,
然后,在我們發送完所有輸入的德語單詞序列之后,最侄訓得背景關系向量[以黃色塊顯示](hs,cs),該背景關系向量是單詞序列的密集表示形式,可以發送到解碼器的第一個LSTM(hs ,cs)進行相應的英語翻譯,
在上圖中,我們使用2層LSTM體系結構,其中將第一個LSTM連接到第二個LSTM,然后獲得2個背景關系向量,這些向量堆疊在頂部作為最終輸出,
我們必須在seq2seq模型中設計相同的編碼器和解碼器模塊,
以上可視化適用于批處理中的單個句子,
假設我們的批處理大小為5,然后一次將5個句子(每個句子帶有一個單詞)傳遞給編碼器,如下圖所示,
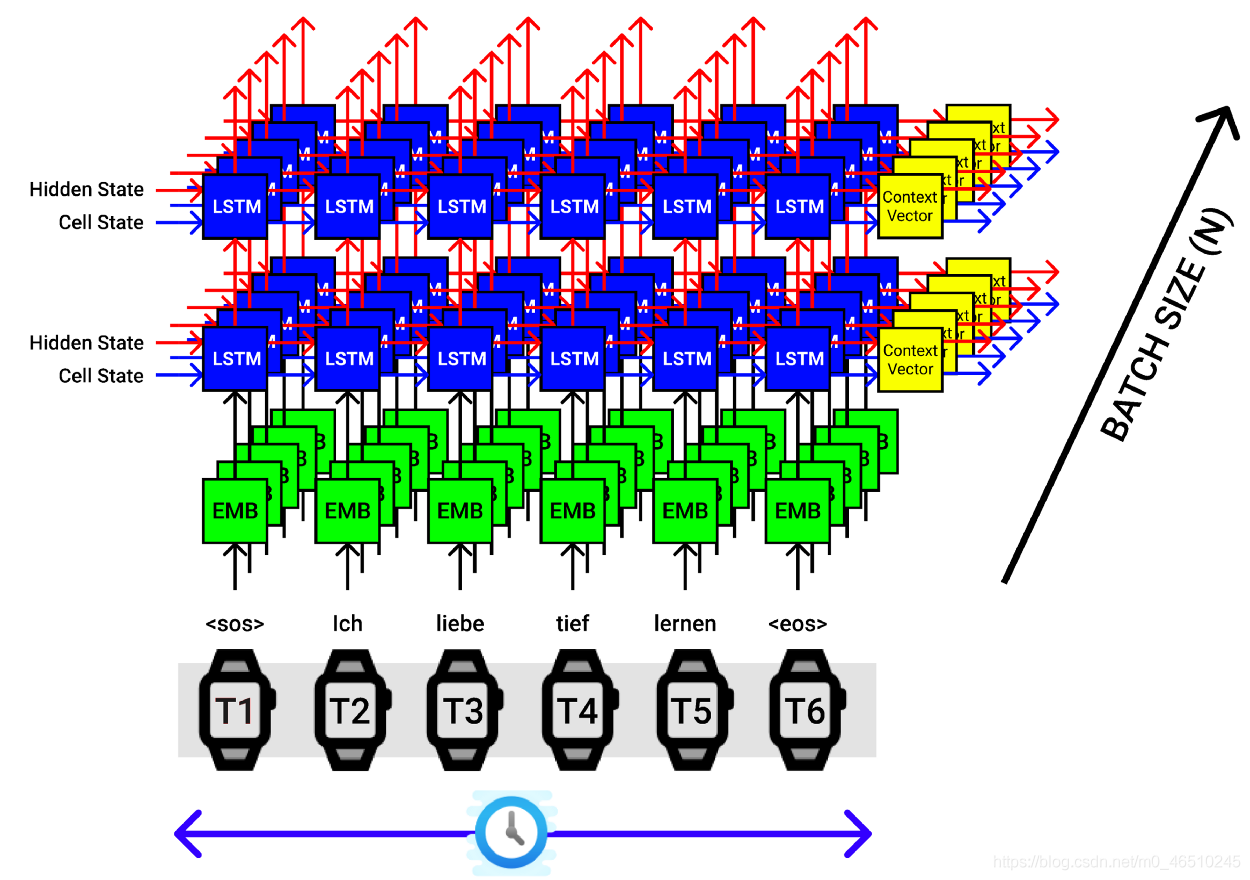
LSTM編碼器的批處理大小為5,X軸對應于時間步長,Y軸對應于批處理大小,
5.編碼器代碼實作(Seq2Seq)
class EncoderLSTM(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, p):
super(EncoderLSTM, self).__init__()
# Size of the one hot vectors that will be the input to the encoder
self.input_size = input_size
# Output size of the word embedding NN
self.embedding_size = embedding_size
# Dimension of the NN's inside the lstm cell/ (hs,cs)'s dimension.
self.hidden_size = hidden_size
# Number of layers in the lstm
self.num_layers = num_layers
# Regularization parameter
self.dropout = nn.Dropout(p)
self.tag = True
# Shape --------------------> (5376, 300) [input size, embedding dims]
self.embedding = nn.Embedding(self.input_size, self.embedding_size)
# Shape -----------> (300, 2, 1024) [embedding dims, hidden size, num layers]
self.LSTM = nn.LSTM(self.embedding_size, hidden_size, num_layers, dropout = p)
# Shape of x (26, 32) [Sequence_length, batch_size]
def forward(self, x):
# Shape -----------> (26, 32, 300) [Sequence_length , batch_size , embedding dims]
embedding = self.dropout(self.embedding(x))
# Shape --> outputs (26, 32, 1024) [Sequence_length , batch_size , hidden_size]
# Shape --> (hs, cs) (2, 32, 1024) , (2, 32, 1024) [num_layers, batch_size size, hidden_size]
outputs, (hidden_state, cell_state) = self.LSTM(embedding)
return hidden_state, cell_state
input_size_encoder = len(german.vocab)
encoder_embedding_size = 300
hidden_size = 1024
num_layers = 2
encoder_dropout = float(0.5)
encoder_lstm = EncoderLSTM(input_size_encoder, encoder_embedding_size,
hidden_size, num_layers, encoder_dropout).to(device)
print(encoder_lstm)
************************************************ OUTPUT ************************************************
EncoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(5376, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
)
6.解碼器模型架構(Seq2Seq)
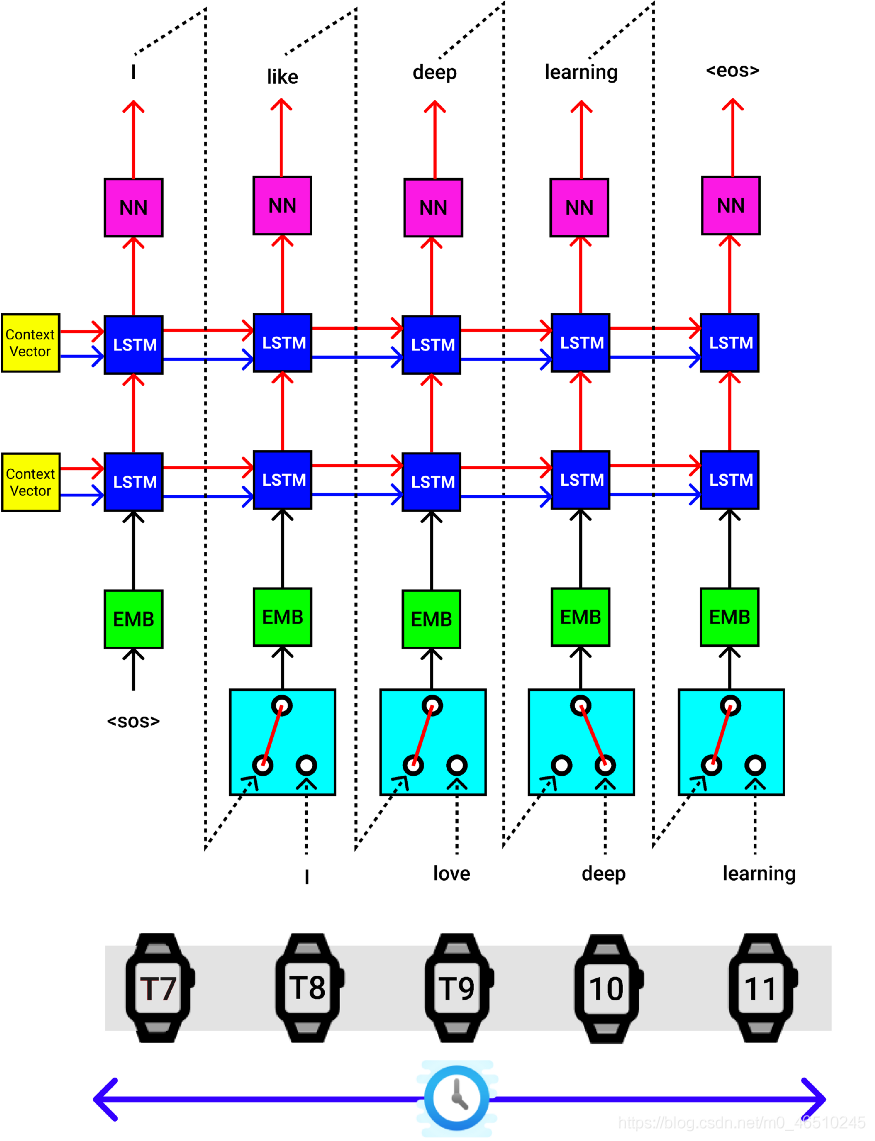
解碼器一次也執行單個步驟,
提供來自編碼器塊的背景關系向量,作為解碼器的第一個LSTM塊的隱藏狀態(hs)和單元狀態(cs),
句子“ SOS”令牌的開頭被傳遞到嵌入的NN,然后傳遞到解碼器的第一個LSTM單元,最后,它經過一個線性層[以粉紅色顯示],該層提供輸出的英語令牌預測 概率(4556個概率)[4556 —如英語的總詞匯量一樣],隱藏狀態(hs),單元狀態(cs),
選擇4556個值中概率最高的輸出單詞,將隱藏狀態(hs)和單元狀態(cs)作為輸入傳遞到下一個LSTM單元,并執行此程序,直到到達句子“ EOS”的結尾 ”,
后續層將使用先前時間步驟中的隱藏狀態和單元狀態,
每個力比:
除其他塊外,您還將在Seq2Seq架構的解碼器中看到以下所示的塊,
在進行模型訓練時,我們發送輸入(德語序列)和目標(英語序列), 從編碼器獲得背景關系向量后,我們將它們和目標發送給解碼器進行翻譯,
但是在模型推斷期間,目標是根據訓練資料的一般性從解碼器生成的, 因此,將輸出的預測單詞作為下一個輸入單詞發送到解碼器,直到獲得令牌,
因此,在模型訓練本身中,我們可以使用 teach force ratio(暫譯教力比)控制輸入字到解碼器的流向,
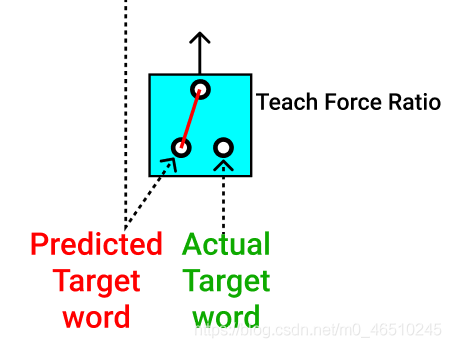
我們可以在訓練時將實際的目標詞發送到解碼器部分(以綠色顯示),
我們還可以發送預測的目標詞,作為解碼器的輸入(以紅色顯示),
發送單詞(實際目標單詞或預測目標單詞)的可能性可以控制為50%,因此在任何時間步長,在訓練程序中都會通過其中一個,
此方法的作用類似于正則化, 因此,在此程序中,模型可以快速有效地進行訓練,
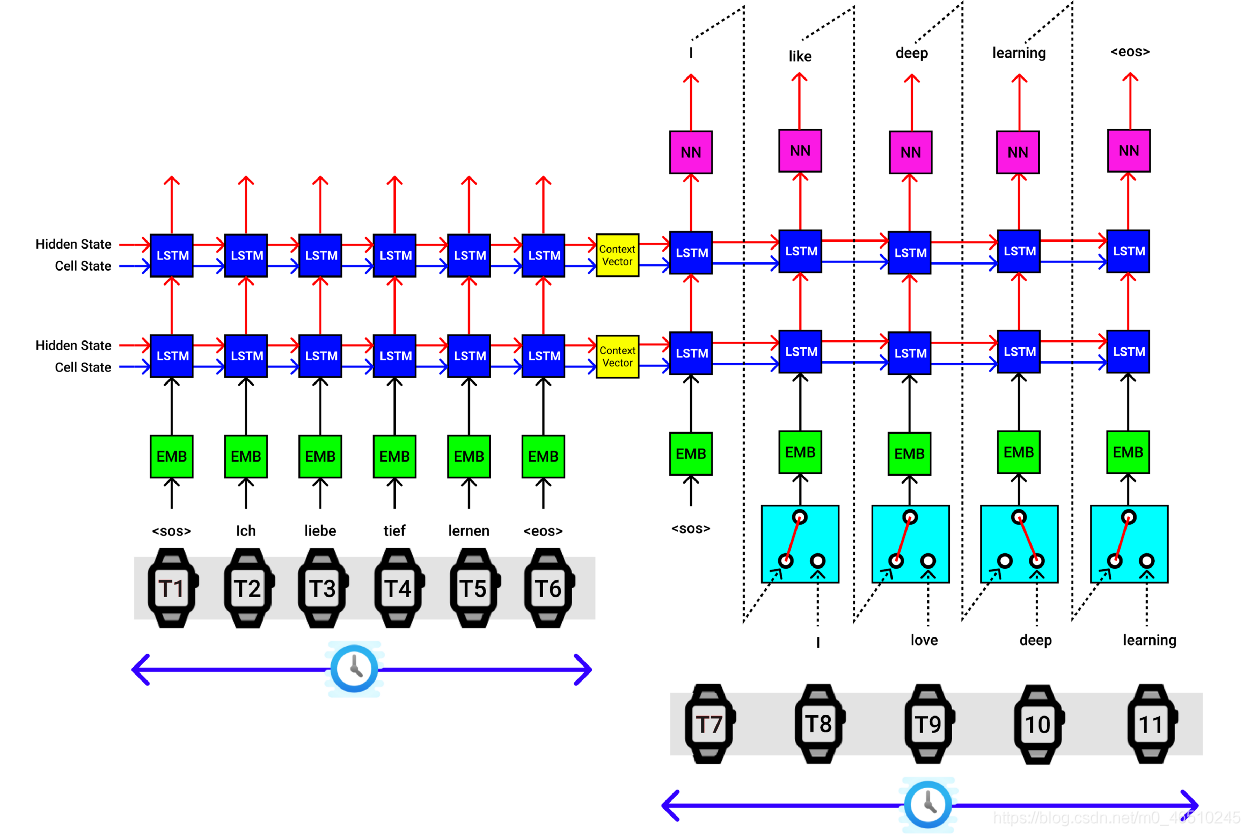
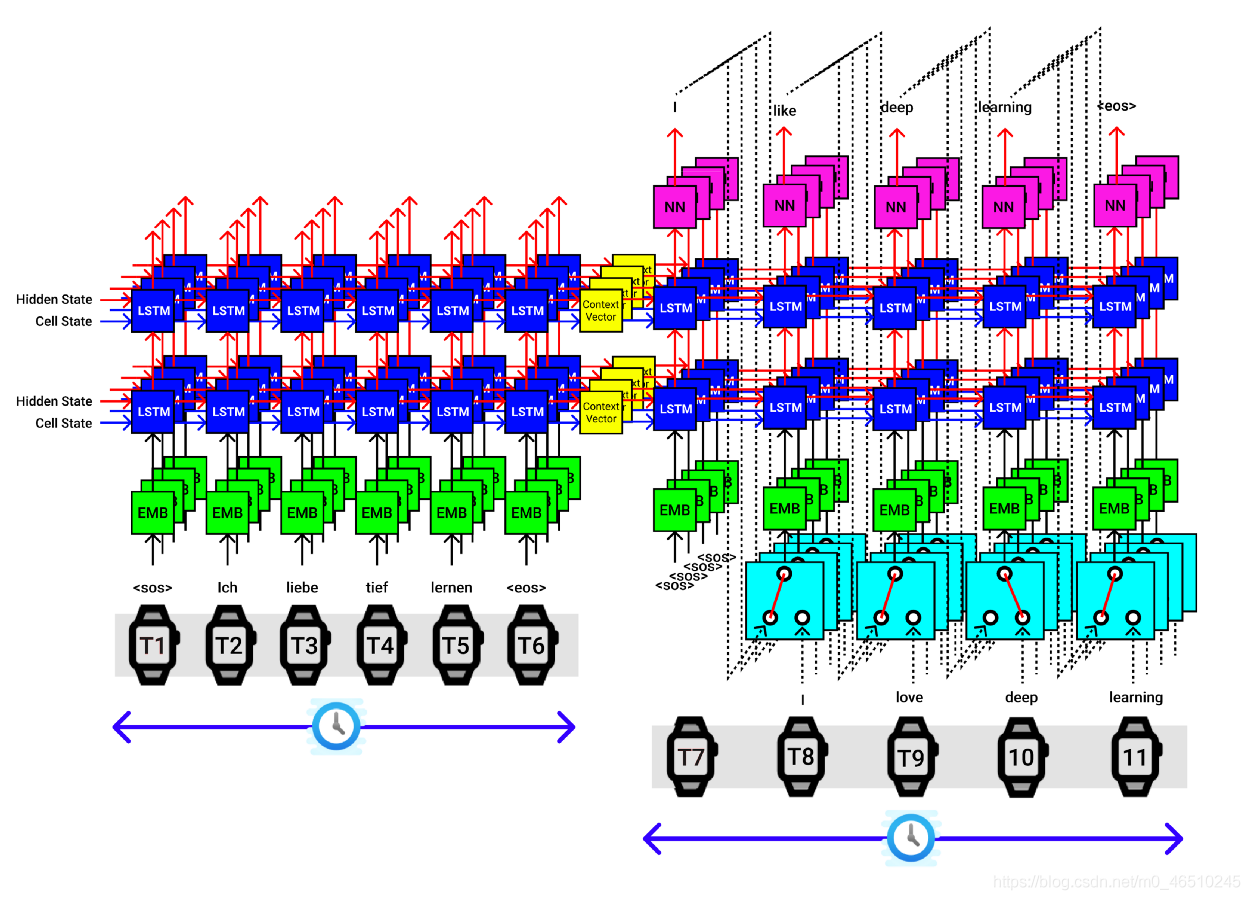
以上可視化適用于批處理中的單個句子, 假設我們的批處理大小為4,然后一次將4個句子傳遞給編碼器,該編碼器提供4組背景關系向量,它們都被傳遞到解碼器中,如下圖所示,
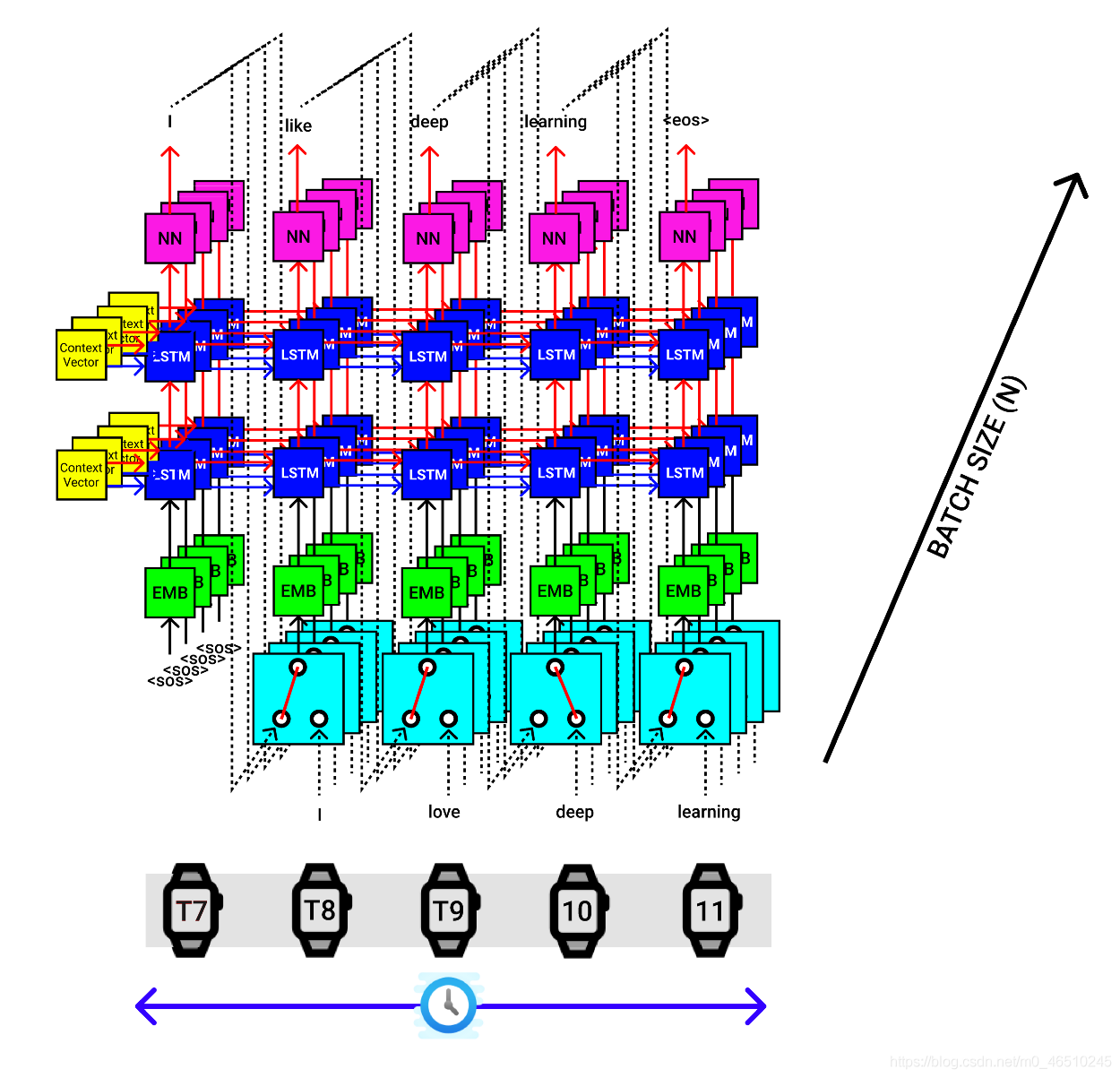
7.解碼器代碼實作(Seq2Seq)
class DecoderLSTM(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, p, output_size):
super(DecoderLSTM, self).__init__()
# Size of the one hot vectors that will be the input to the encoder
self.input_size = input_size
# Output size of the word embedding NN
self.embedding_size = embedding_size
# Dimension of the NN's inside the lstm cell/ (hs,cs)'s dimension.
self.hidden_size = hidden_size
# Number of layers in the lstm
self.num_layers = num_layers
# Size of the one hot vectors that will be the output to the encoder (English Vocab Size)
self.output_size = output_size
# Regularization parameter
self.dropout = nn.Dropout(p)
self.tag = True
# Shape --------------------> (5376, 300) [input size, embedding dims]
self.embedding = nn.Embedding(self.input_size, self.embedding_size)
# Shape -----------> (300, 2, 1024) [embedding dims, hidden size, num layers]
self.LSTM = nn.LSTM(self.embedding_size, hidden_size, num_layers, dropout = p)
# Shape -----------> (1024, 4556) [embedding dims, hidden size, num layers]
self.fc = nn.Linear(self.hidden_size, self.output_size)
# Shape of x (32) [batch_size]
def forward(self, x, hidden_state, cell_state):
# Shape of x (1, 32) [1, batch_size]
x = x.unsqueeze(0)
# Shape -----------> (1, 32, 300) [1, batch_size, embedding dims]
embedding = self.dropout(self.embedding(x))
# Shape --> outputs (1, 32, 1024) [1, batch_size , hidden_size]
# Shape --> (hs, cs) (2, 32, 1024) , (2, 32, 1024) [num_layers, batch_size size, hidden_size] (passing encoder's hs, cs - context vectors)
outputs, (hidden_state, cell_state) = self.LSTM(embedding, (hidden_state, cell_state))
# Shape --> predictions (1, 32, 4556) [ 1, batch_size , output_size]
predictions = self.fc(outputs)
# Shape --> predictions (32, 4556) [batch_size , output_size]
predictions = predictions.squeeze(0)
return predictions, hidden_state, cell_state
input_size_decoder = len(english.vocab)
decoder_embedding_size = 300
hidden_size = 1024
num_layers = 2
decoder_dropout = float(0.5)
output_size = len(english.vocab)
decoder_lstm = DecoderLSTM(input_size_decoder, decoder_embedding_size,
hidden_size, num_layers, decoder_dropout, output_size).to(device)
print(decoder_lstm)
************************************************ OUTPUT ************************************************
DecoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(4556, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
(fc): Linear(in_features=1024, out_features=4556, bias=True)
)
8.Seq2Seq(編碼器+解碼器)介面
單個輸入陳述句的最終seq2seq實作如下圖所示,
- 提供輸入(德語)和輸出(英語)句子
- 將輸入序列傳遞給編碼器并提取背景關系向量
- 將輸出序列傳遞給解碼器,以及來自編碼器的背景關系向量,以生成預測的輸出序列
以上可視化適用于批處理中的單個句子, 假設我們的批處理大小為4,然后一次將4個句子傳遞給編碼器,該編碼器提供4組背景關系向量,它們都被傳遞到解碼器中,如下圖所示,
9.Seq2Seq(編碼器+解碼器)代碼實作
class Seq2Seq(nn.Module):
def __init__(self, Encoder_LSTM, Decoder_LSTM):
super(Seq2Seq, self).__init__()
self.Encoder_LSTM = Encoder_LSTM
self.Decoder_LSTM = Decoder_LSTM
def forward(self, source, target, tfr=0.5):
# Shape - Source : (10, 32) [(Sentence length German + some padding), Number of Sentences]
batch_size = source.shape[1]
# Shape - Source : (14, 32) [(Sentence length English + some padding), Number of Sentences]
target_len = target.shape[0]
target_vocab_size = len(english.vocab)
# Shape --> outputs (14, 32, 5766)
outputs = torch.zeros(target_len, batch_size, target_vocab_size).to(device)
# Shape --> (hs, cs) (2, 32, 1024) ,(2, 32, 1024) [num_layers, batch_size size, hidden_size] (contains encoder's hs, cs - context vectors)
hidden_state_encoder, cell_state_encoder = self.Encoder_LSTM(source)
# Shape of x (32 elements)
x = target[0] # Trigger token <SOS>
for i in range(1, target_len):
# Shape --> output (32, 5766)
output, hidden_state_decoder, cell_state_decoder = self.Decoder_LSTM(x, hidden_state_encoder, cell_state_encoder)
outputs[i] = output
best_guess = output.argmax(1) # 0th dimension is batch size, 1st dimension is word embedding
x = target[i] if random.random() < tfr else best_guess # Either pass the next word correctly from the dataset or use the earlier predicted word
# Shape --> outputs (14, 32, 5766)
return outputs
print(model)
************************************************ OUTPUT ************************************************
Seq2Seq(
(Encoder_LSTM): EncoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(5376, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
)
(Decoder_LSTM): DecoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(4556, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
(fc): Linear(in_features=1024, out_features=4556, bias=True)
)
)
10.Seq2Seq模型訓練
epoch_loss = 0.0
num_epochs = 100
best_loss = 999999
best_epoch = -1
sentence1 = "ein mann in einem blauen hemd steht auf einer leiter und putzt ein fenster"
ts1 = []
for epoch in range(num_epochs):
print("Epoch - {} / {}".format(epoch+1, num_epochs))
model.eval()
translated_sentence1 = translate_sentence(model, sentence1, german, english, device, max_length=50)
print(f"Translated example sentence 1: \n {translated_sentence1}")
ts1.append(translated_sentence1)
model.train(True)
for batch_idx, batch in enumerate(train_iterator):
input = batch.src.to(device)
target = batch.trg.to(device)
# Pass the input and target for model's forward method
output = model(input, target)
output = output[1:].reshape(-1, output.shape[2])
target = target[1:].reshape(-1)
# Clear the accumulating gradients
optimizer.zero_grad()
# Calculate the loss value for every epoch
loss = criterion(output, target)
# Calculate the gradients for weights & biases using back-propagation
loss.backward()
# Clip the gradient value is it exceeds > 1
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Update the weights values using the gradients we calculated using bp
optimizer.step()
step += 1
epoch_loss += loss.item()
writer.add_scalar("Training loss", loss, global_step=step)
if epoch_loss < best_loss:
best_loss = epoch_loss
best_epoch = epoch
checkpoint_and_save(model, best_loss, epoch, optimizer, epoch_loss)
if ((epoch - best_epoch) >= 10):
print("no improvement in 10 epochs, break")
break
print("Epoch_Loss - {}".format(loss.item()))
print()
print(epoch_loss / len(train_iterator))
score = bleu(test_data[1:100], model, german, english, device)
print(f"Bleu score {score*100:.2f}")
************************************************ OUTPUT ************************************************
Bleu score 15.62
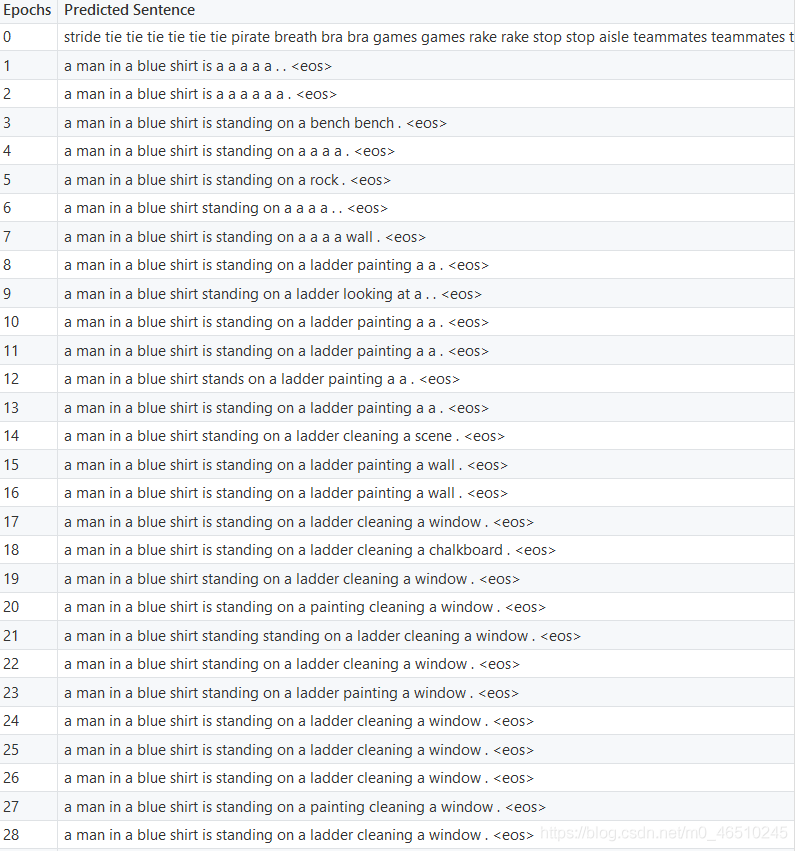
例句訓練進度:
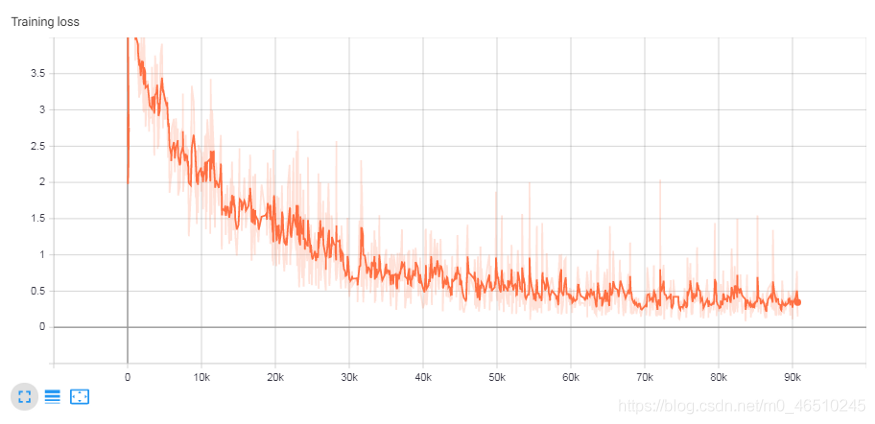
訓練損失:
11.Seq2Seq模型推理
現在,讓我們將我們訓練有素的模型與SOTA Google Translate的模型進行比較,
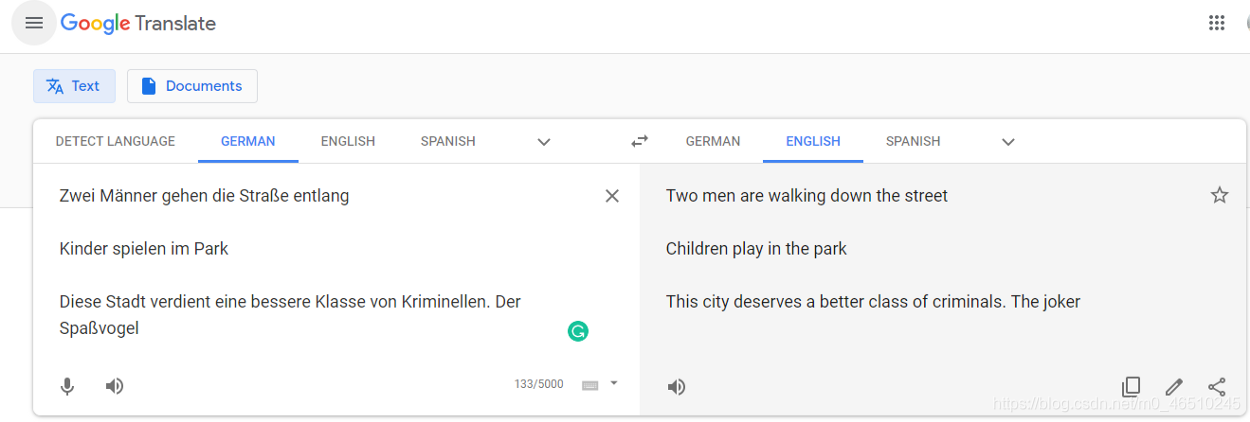
model.eval()
test_sentences = ["Zwei M?nner gehen die Stra?e entlang", "Kinder spielen im Park.",
"Diese Stadt verdient eine bessere Klasse von Verbrechern. Der Spa?vogel"]
actual_sentences = ["Two men are walking down the street", "Children play in the park",
"This city deserves a better class of criminals. The joker"]
pred_sentences = []
for idx, i in enumerate(test_sentences):
model.eval()
translated_sentence = translate_sentence(model, i, german, english, device, max_length=50)
progress.append(TreebankWordDetokenizer().detokenize(translated_sentence))
print("German : {}".format(i))
print("Actual Sentence in English : {}".format(actual_sentences[idx]))
print("Predicted Sentence in English : {}".format(progress[-1]))
print()
******************************************* OUTPUT *******************************************
German : "Zwei M?nner gehen die Stra?e entlang"
Actual Sentence in English : "Two men are walking down the street"
Predicted Sentence in English : "two men are walking on the street . <eos>"
German : "Kinder spielen im Park."
Actual Sentence in English : "Children play in the park"
Predicted Sentence in English : "children playing in the park . <eos>"
German : "Diese Stadt verdient eine bessere Klasse von Verbrechern. Der Spa?vogel"
Actual Sentence in English : "This city deserves a better class of criminals. The joker"
Predicted Sentence in English : "this <unk>'s <unk> from a <unk> green team <unk> by the sidelines . <eos>"
不錯,但是很明顯,該模型不能理解復雜的句子, 因此,在接下來的系列文章中,我將通過更改模型的體系結構來提高上述模型的性能,例如使用雙向LSTM,添加注意力機制或將LSTM替換為Transformers模型來克服這些明顯的缺點,
希望我能夠對Seq2Seq模型如何處理資料有一些直觀的了解,在評論部分告訴我您的想法,
作者:Balakrishnakumar V
本文代碼:https://github.com/bala-codes/Natural-Language-Processing-NLP/blob/master/Neural%20Machine%20Translation/1.%20Seq2Seq%20%5BEnc%20%2B%20Dec%5D%20Model%20for%20Neural%20Machine%20Translation%20%28Without%20Attention%20Mechanism%29.ipynb
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/81524.html
標籤:其他
下一篇:阿里云棲大會的第一天,看見未來