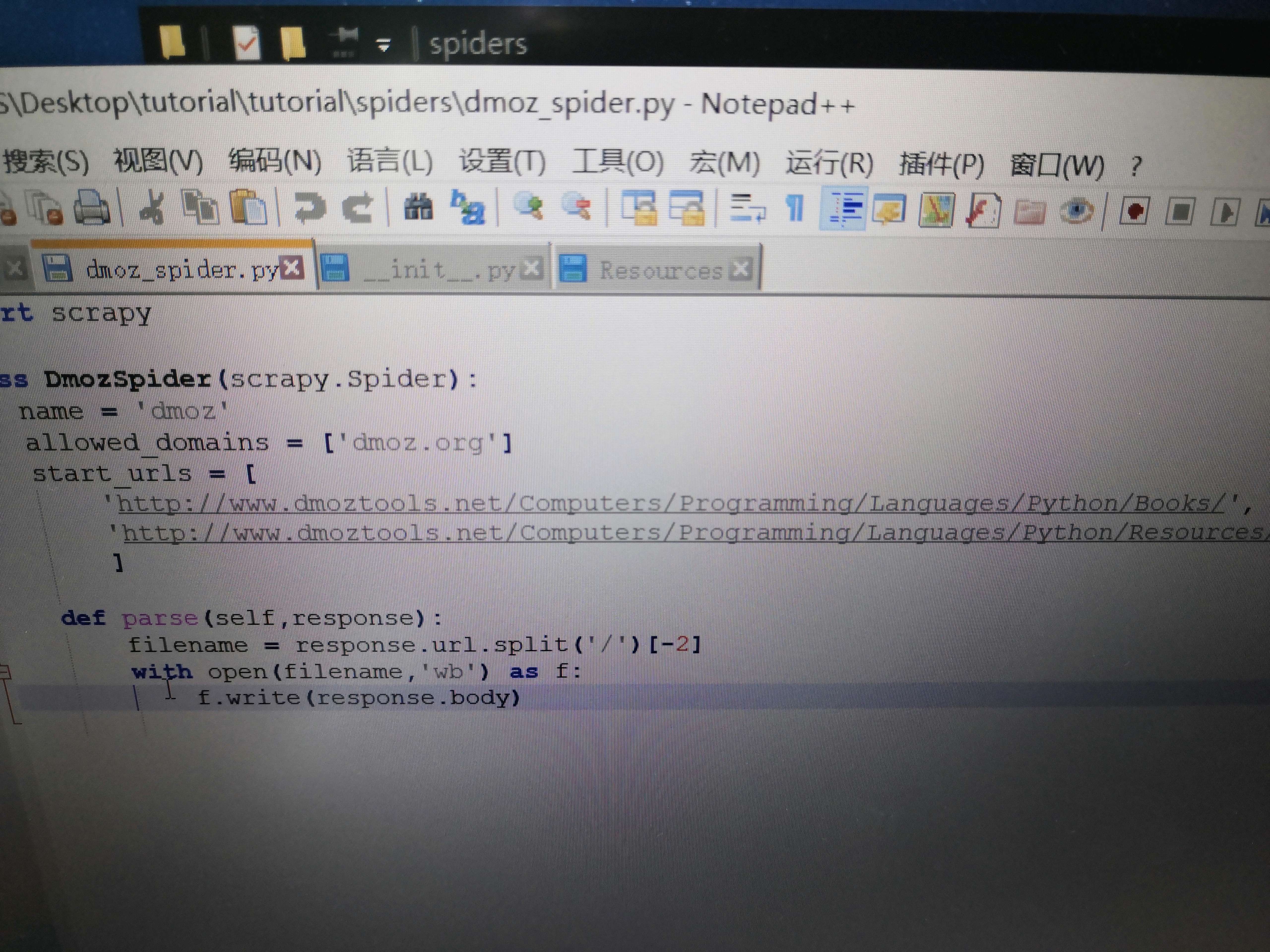
用scrapy爬網站資料,網站為圖一第二個網站。
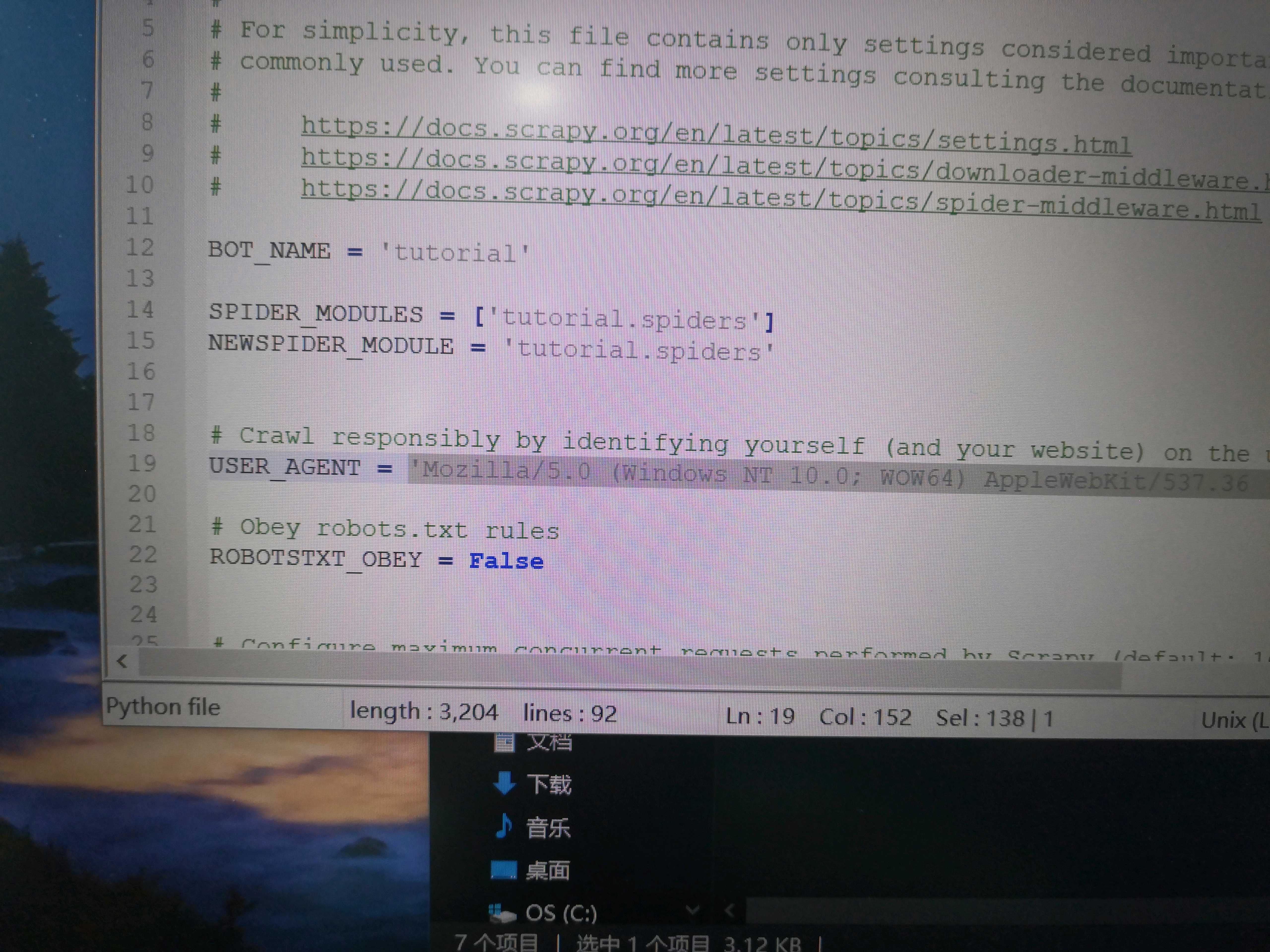
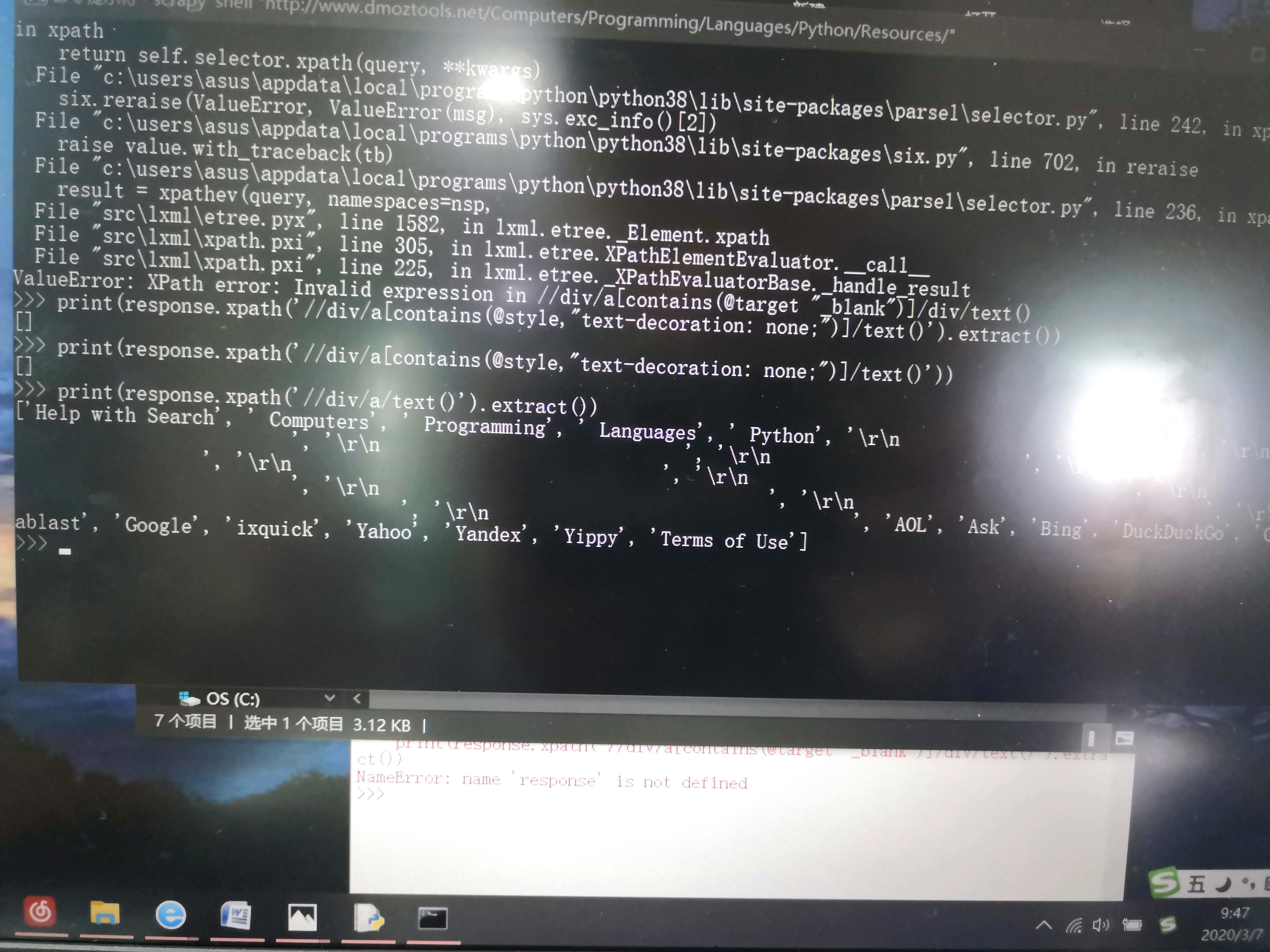
遇到的問題是:我修改了setting的robot協議為False,又將user-agent改了,是可以被服務器認定為正常訪問了吧,然后我打開cmd運行,爬了資料后用scrapy shell 操作抓取我想要的資料,居然看到的是空串列。(在py里爬了一遍整個網頁的資料,發現整個資料都沒有我想要的東西)估計是被認出來了,還是什么問題?希望有大佬包忙看看謝謝。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/81726.html
上一篇:非科班研究生中途轉業突進學習Java,趕上校招末班車成功斬獲美團offer,分享面試經驗!
下一篇:beep問題