在Jupyter notebook中為影像添加標簽,預測新影像并可視化神經網路(并使用Docker Hub共享它們!)
作者|Jenny Huang
編譯|Flin
來源|towardsdatascience
作者:Jenny Huang, Ian Hunt-Isaak, William Palmer
GitHub Repo: https://github.com/ianhi/AC295-final-project-JWI
介紹
在新影像上訓練影像分割模型可能會令人生畏,尤其是當你需要標記自己的資料時,為了使此任務更容易,更快捷,我們構建了一個用戶友好的工具,可讓你在Jupyter notebook中構建整個程序,在以下各節中,我們將向你展示我們的工具如何使你:
-
手動標記自己的影像
-
通過遷移學習建立有效的分割模型
-
可視化模型及其結果
-
以Docker映像形式共享你的專案
該工具的主要優點是易于使用,并且與現有的資料科學作業流程很好地集成在一起,通過互動式小部件和命令提示符,我們構建了一種用戶友好的方式來標記影像和訓練模型,
最重要的是,所有內容都可以在Jupyter notebook上運行,從而快速,輕松地建立模型,而沒有太多開銷,
最后,通過在Python環境中作業并使用Tensorflow和Matplotlib等標準庫,可以將該工具很好地集成到現有的資料科學作業流程中,使其非常適合科學研究等用途,
例如,在微生物學中,分割細胞的顯微鏡影像是非常有用的,然而,隨著時間的推移,跟蹤細胞很可能需要分割成百上千的影像,這可能很難手動完成,在本文中,我們將使用酵母細胞的顯微鏡影像作為資料集,并展示我們如何構建工具來區分背景、母細胞和子細胞,
1.標簽
現有許多工具可以為影像創建帶標簽的掩膜,包括Labelme,ImageJ甚至是圖形編輯器GIMP,這些都是很棒的工具,但是它們無法集成到Jupyter notebook中,這使得它們很難與許多現有作業流程一起使用,
- Labelme:https://github.com/wkentaro/labelme
- ImageJ:https://imagej.net/Welcome
- GIMP:https://www.gimp.org/
幸運的是,Jupyter Widgets使我們能夠輕松制作互動式組件并將其與我們其余的Python代碼連接,
- Jupyter Widgets:https://ipywidgets.readthedocs.io/en/latest/
要在筆記本中創建訓練掩膜,我們要解決兩個問題:
-
用滑鼠選擇影像的一部分
-
輕松在影像之間切換并選擇要標記的類別
為了解決第一個問題,我們使用了Matplotlib小部件后端和內置的LassoSelector,
- LassoSelector:https://matplotlib.org/3.1.1/gallery/widgets/lasso_selector_demo_sgskip.html
LassoSelector會處理一條線以顯示你所選擇的內容,但是我們需要一些自定義代碼來將掩膜繪制為覆寫層:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.widgets import LassoSelector
from matplotlib.path import Path
class image_lasso_selector:
def __init__(self, img, mask_alpha=.75, figsize=(10,10)):
"""
img must have shape (X, Y, 3)
"""
self.img = img
self.mask_alpha = mask_alpha
plt.ioff() # see https://github.com/matplotlib/matplotlib/issues/17013
self.fig = plt.figure(figsize=figsize)
self.ax = self.fig.gca()
self.displayed = self.ax.imshow(img)
plt.ion()
lineprops = {'color': 'black', 'linewidth': 1, 'alpha': 0.8}
self.lasso = LassoSelector(self.ax, self.onselect,lineprops=lineprops, useblit=False)
self.lasso.set_visible(True)
pix_x = np.arange(self.img.shape[0])
pix_y = np.arange(self.img.shape[1])
xv, yv = np.meshgrid(pix_y,pix_x)
self.pix = np.vstack( (xv.flatten(), yv.flatten()) ).T
self.mask = np.zeros(self.img.shape[:2])
def onselect(self, verts):
self.verts = verts
p = Path(verts)
self.indices = p.contains_points(self.pix, radius=0).reshape(self.mask.shape)
self.draw_with_mask()
def draw_with_mask(self):
array = self.displayed.get_array().data
# https://en.wikipedia.org/wiki/Alpha_compositing#Straight_versus_premultiplied
self.mask[self.indices] = 1
c_overlay = self.mask[self.indices][...,None]*[1.,0,0]*self.mask_alpha
array[self.indices] = (c_overlay + self.img[self.indices]*(1-self.mask_alpha))
self.displayed.set_data(array)
self.fig.canvas.draw_idle()
def _ipython_display_(self):
display(self.fig.canvas)
對于第二個問題,我們使用ipywidgets添加了漂亮的按鈕和其他控制元件:

我們結合了這些元素(以及滾動縮放等改進功能)來制作了一個標簽控制器物件,現在,我們可以拍攝酵母的顯微鏡影像并分割母細胞和子細胞:
套索選擇影像標簽演示:
https://youtu.be/aYb17GueVcU
你可以查看完整的物件,它允許你滾動,縮放,右鍵單擊以平移,并在此處(https://github.com/ianhi/AC295-final-project-JWI/blob/2bacc09c06228c1eb49130ec5aaeff660f921033/lib/labelling.py#L152) 選擇多個類,
現在我們可以在notebook上標記少量影像,將它們保存到正確的檔案夾結構中,然后開始訓練CNN!
2.模型訓練
模型
U-net是一個卷積神經網路,最初設計用于分割生物醫學影像,但已成功用于許多其他型別的影像,它以現有的卷積網路為基礎,可以在很少的訓練影像的情況下更好地作業,并進行更精確的分割,這是一個最新模型,使用segmentation_models庫也很容易實作,
- segmentation_models庫:https://github.com/qubvel/segmentation_models
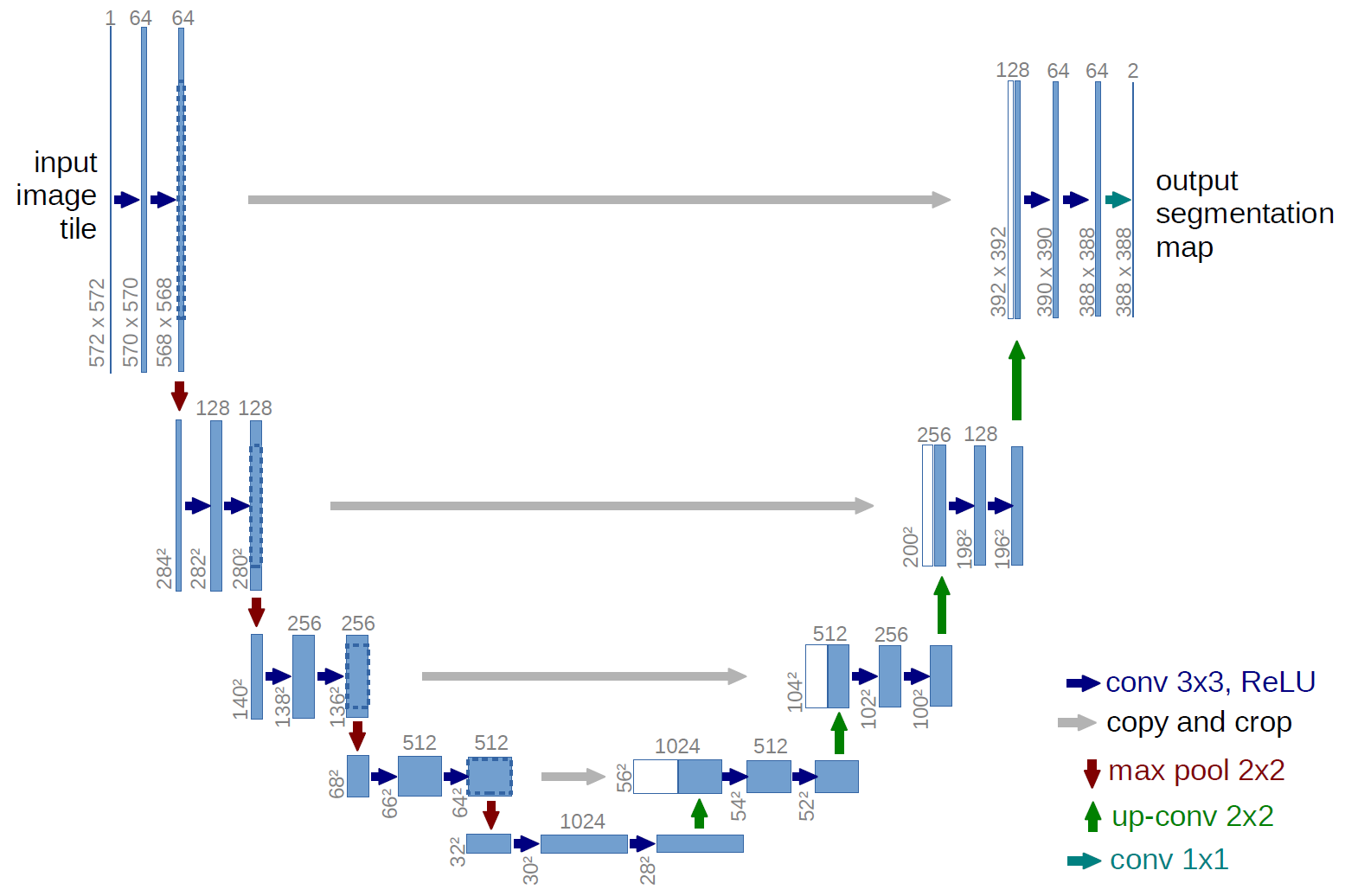
U-net的獨特之處在于它通過交叉連接將編碼器和解碼器結合在一起(上圖中的灰色箭頭),這些跳躍連接從下采樣路徑中的相同大小的部分跨到上采樣路徑,這樣可以提高你對上采樣時輸入到模型中的原始像素的了解,這已被證明可以提高分割任務的性能,
盡管U-net很棒,但是如果我們沒有給它足夠的訓練示例,它將無法正常作業,考慮到手動分割影像的繁瑣作業,我們僅手動標記了13張影像,僅用很少的訓練示例,不可能訓練具有數百萬個引數的神經網路,為了克服這個問題,我們既需要資料擴充又需要遷移學習,
資料擴充
自然,如果你的模型具有很多引數,則需要成比例的訓練示例才能獲得良好的性能,使用影像和掩膜的小型資料集,我們可以創建新影像,這些影像對于模型和原始影像一樣具有洞察力和實用性,
我們該怎么做?我們可以翻轉影像,旋轉角度,向內或向外縮放影像,裁剪,平移影像,甚至可以通過添加噪點來模糊影像,但最重要的是,我們可以將這些操作結合起來以創建許多新的訓練例子,
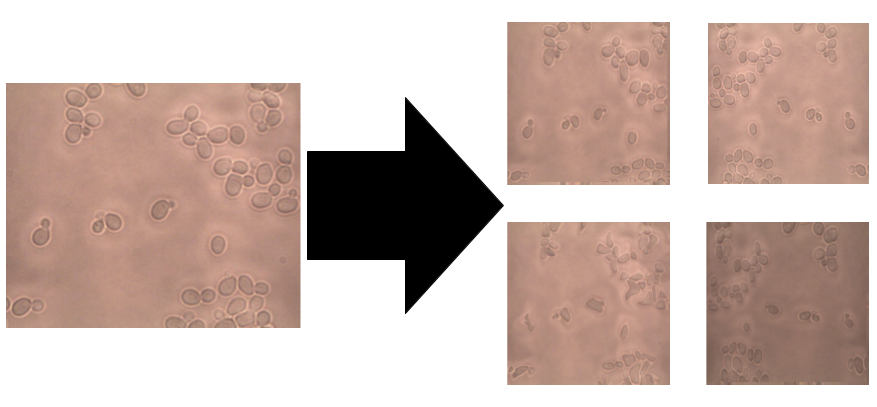
與分類相比,影像資料增強在分割方面具有更多的復雜性,對于分類,你只需要放大影像,因為標簽將保持不變(0或1或2…),但是,對于分割,還需要與影像同步轉換標簽(作為掩膜),為此,我們將albumentations庫與自定義資料生成器一起使用,因為據我們所知,Keras ImageDataGenerator當前不支持組合“Image+mask”,
import albumentations as A
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
TARGET_SIZE = (224,224)
BATCH_SIZE = 6
def create_augmentation_pipeline():
augmentation_pipeline = A.Compose(
[
A.HorizontalFlip(p = 0.5), # Apply horizontal flip to 50% of images
A.OneOf(
[
# Apply one of transforms to 50% of images
A.RandomContrast(), # Apply random contrast
A.RandomGamma(), # Apply random gamma
A.RandomBrightness(), # Apply random brightness
],
p = 0.5
),
A.OneOf(
[
# Apply one of transforms to 50% images
A.ElasticTransform(
alpha = 120,
sigma = 120 * 0.05,
alpha_affine = 120 * 0.03
),
A.GridDistortion()
],
p = 0.5
)
],
p = 0.9 # In 10% of cases keep same image because that's interesting also
)
return augmentation_pipeline
def create_datagenerator(PATH):
options = {'horizontal_flip': True, 'vertical_flip': True}
image_datagen = ImageDataGenerator(rescale=1./255, **options)
mask_datagen = ImageDataGenerator(**options)
val_datagen = ImageDataGenerator(rescale=1./255)
val_datagen_mask = ImageDataGenerator(rescale=1)
# Create custom zip and custom batch_size
def combine_generator(gen1, gen2, batch_size=6,training=True):
while True:
image_batch, label_batch = next(gen1)[0], np.expand_dims(next(gen2)[0][:,:,0],axis=-1)
image_batch, label_batch = np.expand_dims(image_batch,axis=0), np.expand_dims(label_batch,axis=0)
for i in range(batch_size - 1):
image_i,label_i = next(gen1)[0], np.expand_dims(next(gen2)[0][:,:,0],axis=-1)
if training == True:
aug_pipeline = create_augmentation_pipeline()
augmented = aug_pipeline(image=image_i, mask=label_i)
image_i, label_i = augmented['image'], augmented['mask']
image_i, label_i = np.expand_dims(image_i,axis=0),np.expand_dims(label_i,axis=0)
image_batch = np.concatenate([image_batch,image_i],axis=0)
label_batch = np.concatenate([label_batch,label_i],axis=0)
yield((image_batch,label_batch))
seed = np.random.randint(0,1e5)
train_image_generator = image_datagen.flow_from_directory(PATH+'train_imgs', seed=seed, target_size=TARGET_SIZE, class_mode=None, batch_size=BATCH_SIZE)
train_mask_generator = mask_datagen.flow_from_directory(PATH+'train_masks', seed=seed, target_size=TARGET_SIZE, class_mode=None, batch_size=BATCH_SIZE)
train_generator = combine_generator(train_image_generator, train_mask_generator,training=True)
val_image_generator = val_datagen.flow_from_directory(PATH+'val_imgs', seed=seed, target_size=TARGET_SIZE, class_mode=None, batch_size=BATCH_SIZE)
val_mask_generator = val_datagen_mask.flow_from_directory(PATH+'val_masks', seed=seed, target_size=TARGET_SIZE, class_mode=None, batch_size=BATCH_SIZE)
val_generator = combine_generator(val_image_generator, val_mask_generator,training=False)
return train_generator, val_generator
遷移學習
即使我們現在已經創建了100個或更多的影像,但這仍然不夠,因為U-net模型具有超過600萬個引數,這也是遷移學習發揮作用的地方,
遷移學習可以讓你在一個任務上訓練一個模型,并將其重用于另一項類似任務,它極大地減少了你的訓練時間,更重要的是,即使像我們這樣的小型訓練,它也可以產生有效的模型,例如,諸如MobileNet,Inception和DeepNet之類的神經網路通過訓練大量影像來學習特征空間,形狀,顏色,紋理等,然后,我們可以通過獲取這些模型權重并對其進行稍微修改以激活我們自己的訓練影像中的模式來傳遞所學的內容,
現在我們如何使用U-net的遷移學習呢?我們使用segmentation_models庫來實作這一點,我們使用你選擇的深層神經網路(MobileNet、Inception、ResNet)的各層以及在影像分類(ImageNet)上找到的引數,并將它們用作U-net的前半部分(編碼器),然后,使用自己的擴展資料集訓練解碼器層,
整理
我們將所有這些放到了Segmentation模型類中,你可以在此處找到,
- https://github.com/ianhi/AC295-final-project-JWI/blob/master/lib/Segmentation.py
創建模型物件時,會出現一個互動式命令提示符,你可以在其中自定義U-net的各個方面,例如損失函式,骨干網等:
https://vimeo.com/419423808
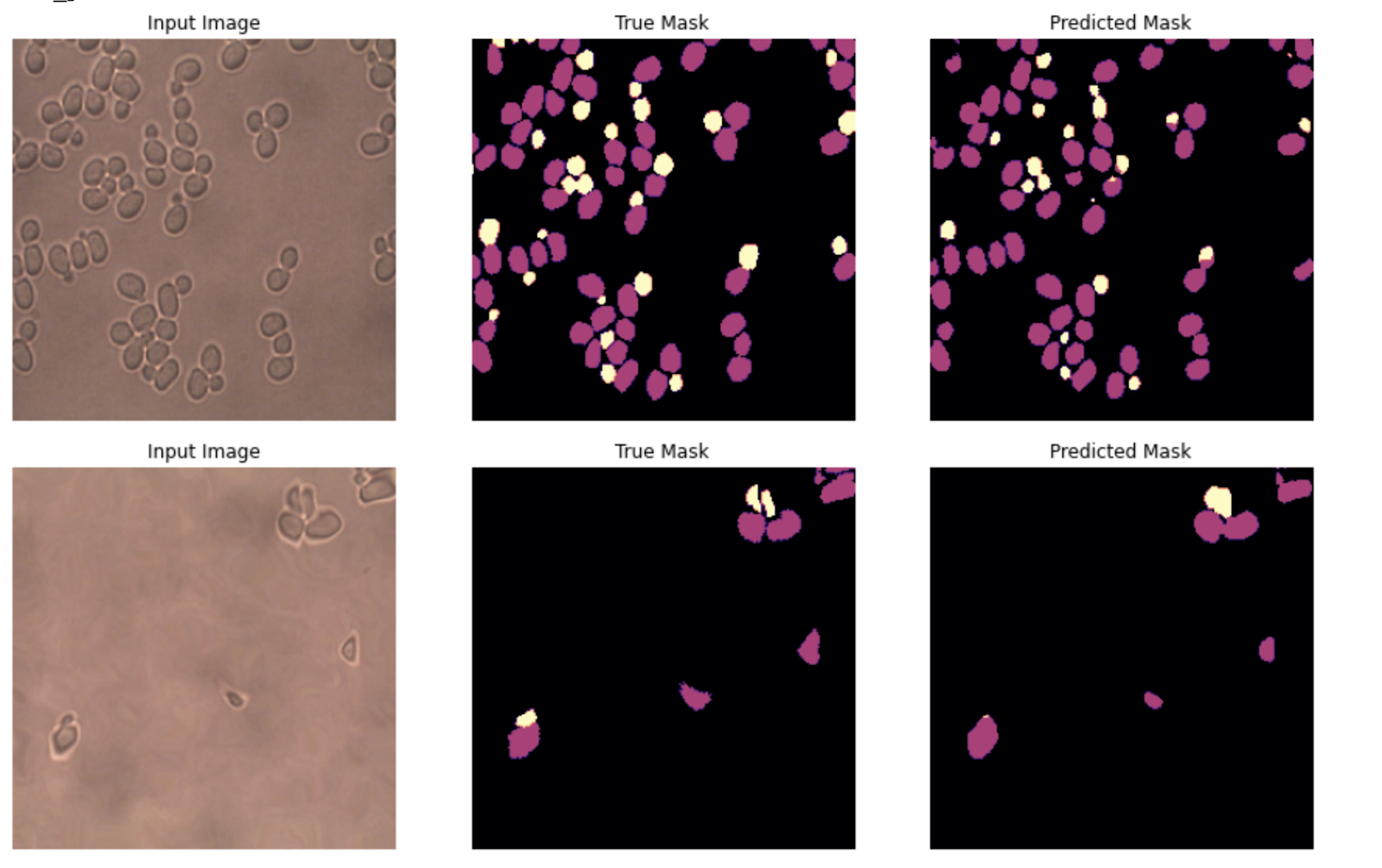
經過30個星期的訓練,我們達到了95%的準確性,請注意,選擇良好的損失函式很重要,我們首先嘗試了交叉熵損失,但是該模型無法區分相貌相似的母細胞和子細胞,并且由于看到的非酵母像素多于酵母像素的類不平衡,因此該模型的性能不佳,
我們發現使用Dice loss可以獲得更好的結果,Dice loss與IOU相關聯,通常更適合分割任務,因為它可以縮小預測值和真實值之間的差距,
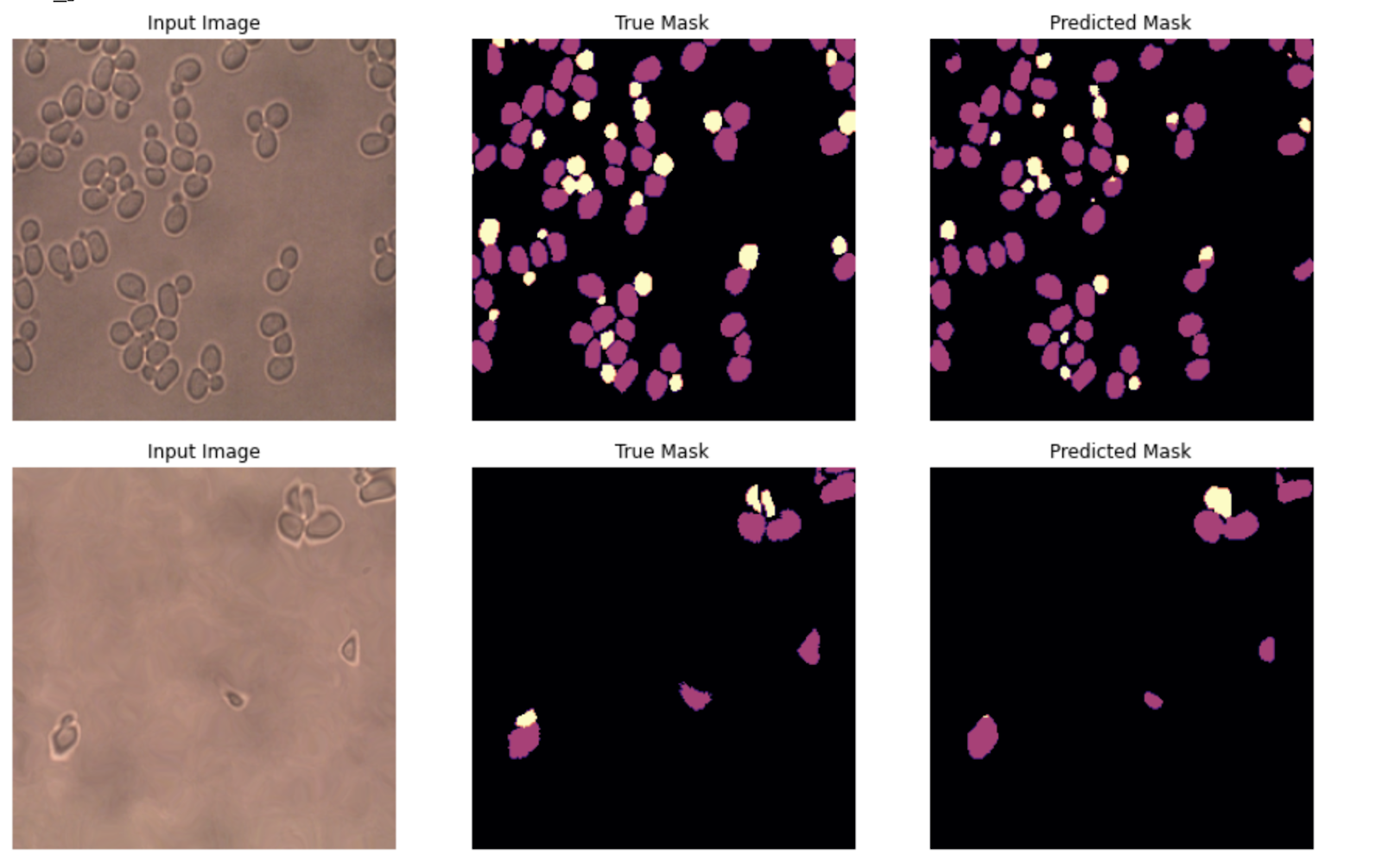
3.可視化
現在我們的模型已經訓練完畢,讓我們使用一些可視化技術來查看其作業原理,
我們按照Ankit Paliwal的教程進行操作,你可以在他相應的GitHub存盤庫中找到實作,在本節中,我們將在酵母細胞分割模型上可視化他的兩種技術,即中間層激活和類激活的熱圖,
- 參考教程:https://towardsdatascience.com/understanding-your-convolution-network-with-visualizations-a4883441533b
- GitHub存盤庫:https://github.com/anktplwl91/visualizing_convnets
中間層激活
第一種技術在測驗影像上顯示網路前向傳播時中間層的輸出,這使我們可以看到輸入影像的哪些特征在每一層都突出顯示,輸入測驗影像后,我們將網路中一些卷積層的前幾個輸出可視化:
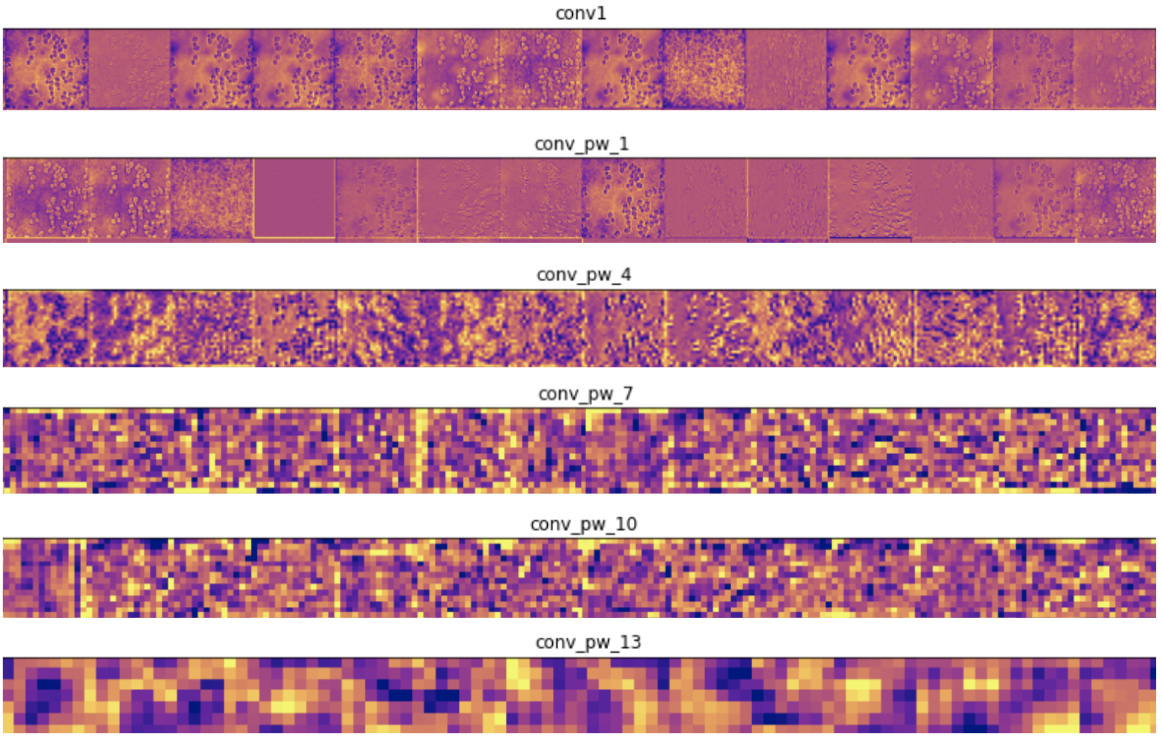
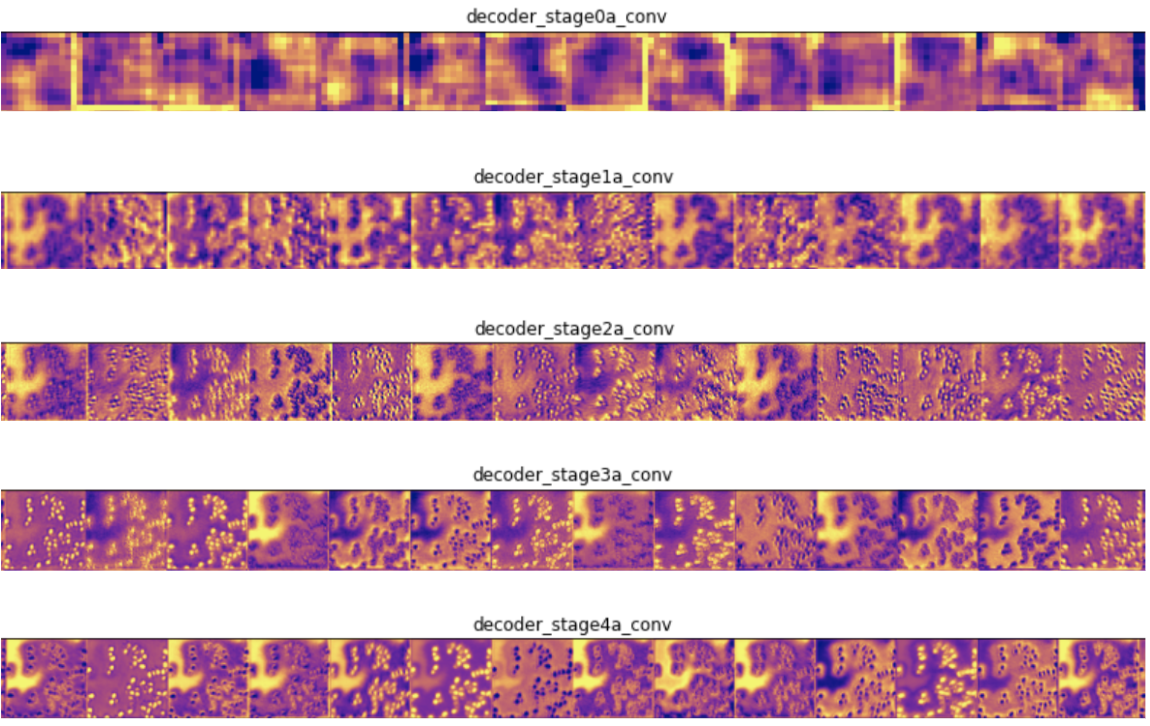
在編碼器層中,靠近輸入的過濾器可檢測更多細節,而靠近模型輸出的過濾器可檢測更一般的特征,這是意料之中的,在解碼器層中,我們看到了相反的模式,即從抽象到更具體的細節,這也是意料之中的,
類激活的熱圖
接下來,我們看一下類激活圖,這些熱圖讓你了解影像的每個位置對于預測輸出類別的重要性,在這里,我們將酵母細胞模型的最后一層可視化,因為類預測標簽在很大程度上依賴于它,
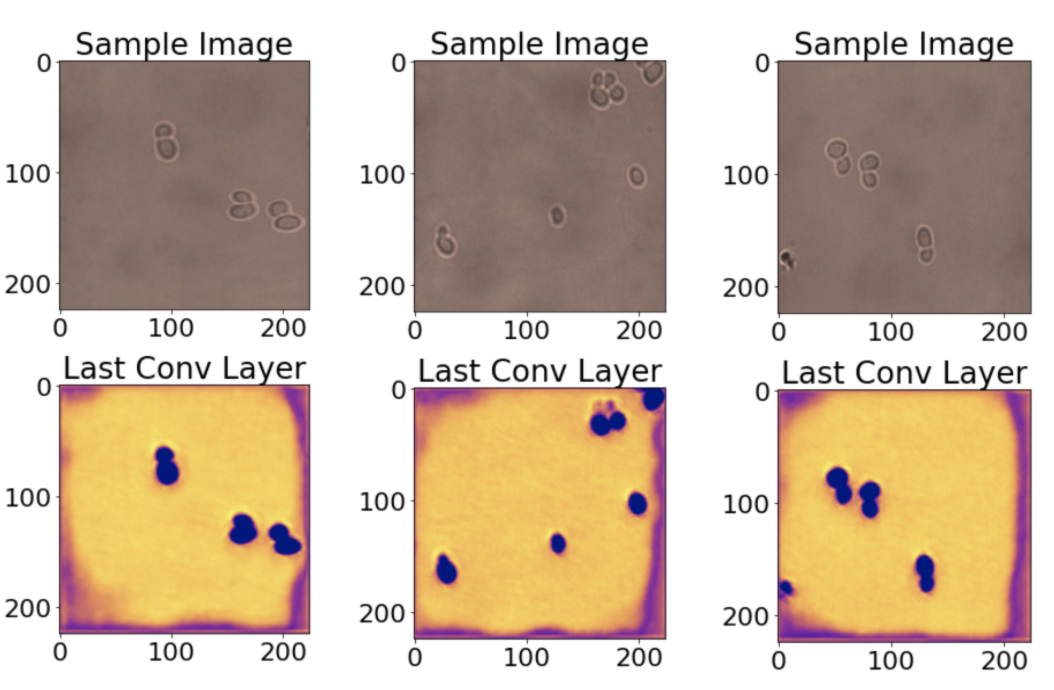
從熱圖可以看出,細胞位置以及部分影像邊界已被正確激活,這有些令人驚訝,
我們還研究了本教程中的最后一項技術,該技術顯示了每個卷積濾波器最大程度地回應哪些影像,但是對于我們特定的酵母細胞模型,可視化效果并不是很有用,
4.制作和共享Docker映像
找到很棒的模型并嘗試運行它,卻發現由于神秘的依賴關系問題,它在你的環境中不起作用,這非常令人沮喪,
我們通過為我們的工具創建一個Docker鏡像來解決這個問題,這使我們可以完全定義運行代碼的環境,甚至是作業系統,
對于此專案,我們基于Jupyter Docker Stacks的jupyter/tensorflow-notebook鏡像建立Docker鏡像,然后,我們僅添加了幾行代碼來安裝所需的庫,并將GitHub存盤庫的內容復制到Docker映像中,
如果你好奇,可以在此處查看我們最終的Dockerfile ,最后,我們將此映像推送到Docker Hub,你可以通過運行以下命令進行嘗試:
sudo docker run -p 8888:8888 ianhuntisaak/ac295-final-project:v3 \
-e JUPYTER_LAB_ENABLE=yes
結論與未來作業
使用此工具,你可以以用戶友好的方式輕松地在新影像上訓練分割模型,雖然有效,但在可用性,自定義和模型性能方面仍有改進的空間,將來,我們希望:
- 通過使用html5畫布構建自定義Jupyter小部件來改善套索工具,以減少手動分割時的滯后
- 探索新的損失函式和模型作為遷移學習的基礎
- 使解釋可視化更加容易,并向用戶建議改善結果的方法
原文鏈接:https://towardsdatascience.com/how-we-built-an-easy-to-use-image-segmentation-tool-with-transfer-learning-546efb6ae98
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/82485.html
標籤:其他