運用MapReduce來統計一個文章的重復的字數
1.準備一篇文章,并且上傳到hdfs
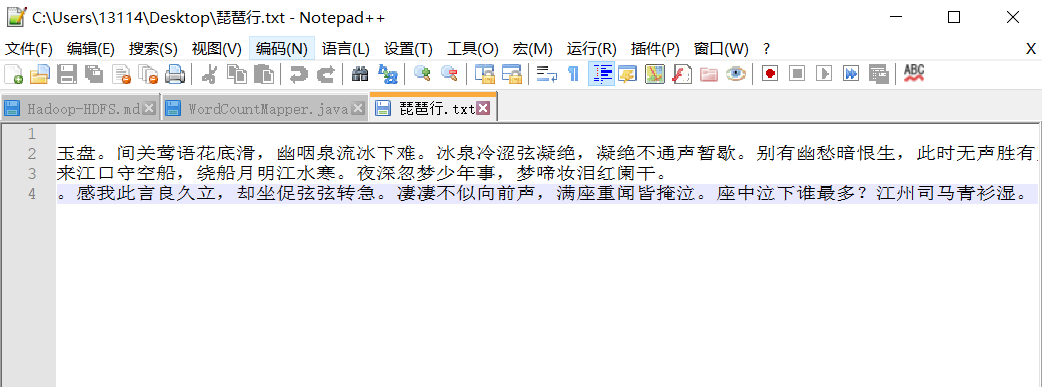
注意編碼是要utf-8 這樣上傳到liunx上面才不會亂碼
先上傳到linux :rz

在上傳到hdfs :hadoop fs -put 琵琶行.txt /

2.寫MapReduce程式
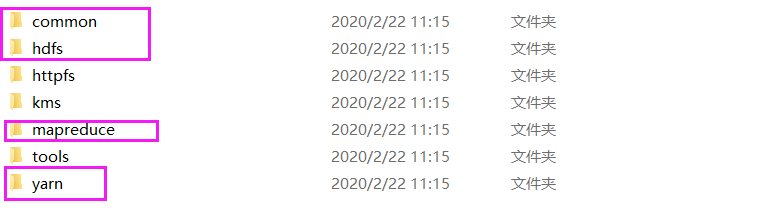
MapReduce基于yarn組件,想要做MapReduce就必須先開啟hdfs和yarn,所以我們需要匯入common包、hdfs包、yarn包和MapReduce包,jar包位置位于hadoop/share/hadoop里,將common、hdfs、yarn、MapReduce檔案夾下的所有jar包及其依賴包匯入到專案中,
Mapper階段:Map必須得繼承Mapper類,并且重寫mapper方法,Map類會輸出成一個檔案temp,之后reduce階段會使用這個檔案,
temp里面的相同的key聚集起來,
/*
* KEYIN 表示我們當前讀取一個檔案[qqq.txt] 讀到多少個位元組了 數量詞
* VALUEIN 表示我們當前讀的是檔案的多少行 逐行讀取 表示我們讀取的一行文字
* KEYOUT 我們執行MAPPER之后 寫入到檔案中KEY的型別
* VALUEOUT 我們執行MAPPER之后 寫入到檔案中VALUE的型別
* */
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException {
//去掉 , , ?
char[] charArray = ivalue.toString().replace(",", "").replace(",", "").replace("?", "").toCharArray();
for (char c : charArray) {
//寫入到一個臨時檔案中
context.write(new Text(String.valueOf(c)), new IntWritable(1));//寫入到臨時檔案當中
}
}
}
Reduce階段:必須得繼承Reducer類,重寫reduce方法
/**
* KEYIN Text
* VALUEIN IntWritbale
* KEYOUT Text 我們Reduce之后 這個檔案中內容的 Key是什么
* VALUEOUT IntWritable 這個檔案中內容Value是什么
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values)
{
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
Job階段:配置資訊
/**
* Driver這個類 用來執行一個任務 Job
* 任務=Mapper+Reduce+HDFS
* 把他們3者 關聯起來
*/
public class WordCountJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.43.61:9000"); //指定使用的hdfs檔案系統
Job job = Job.getInstance(conf, "WordCount"); //任務名
job.setJarByClass(WordCountJob.class); //指定job類
// TODO: specify a mapper
job.setMapperClass(WordCountMapper.class); //指定mapper類
// TODO: specify a reducer
job.setReducerClass(WordCountReduce.class); //指定reduce類
job.setMapOutputKeyClass(Text.class); //指定map輸出的key資料格式
job.setMapOutputValueClass(IntWritable.class); //指定map輸出的value資料格式
// TODO: specify output types
job.setOutputKeyClass(Text.class); //指定reduce輸出的key資料格式
job.setOutputValueClass(IntWritable.class); //指定reduce輸出的value資料格式
// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("/琵琶行.txt")); //指定需要計算的檔案或檔案夾
FileOutputFormat.setOutputPath(job, new Path("/out1/")); //指定輸出檔案保存位置,此檔案夾不得存在
if (!job.waitForCompletion(true))
return;
}
}
3.打成jar包,上傳到linux,
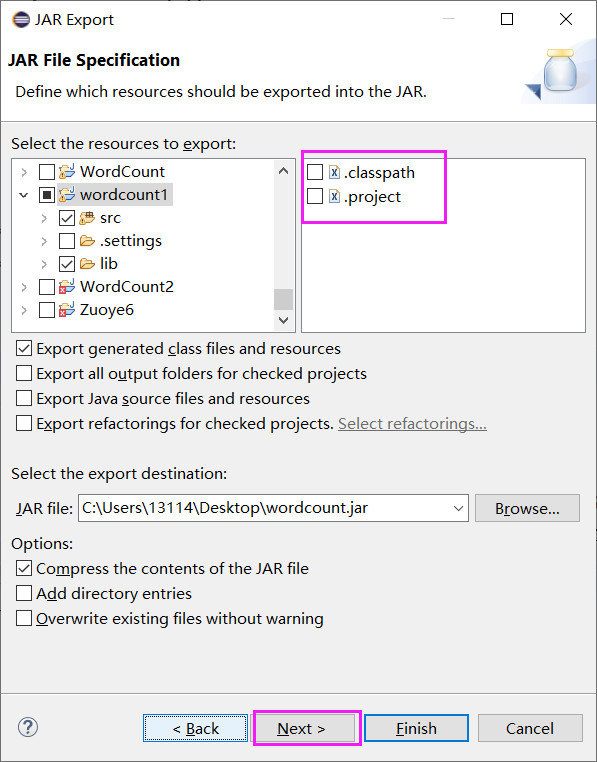
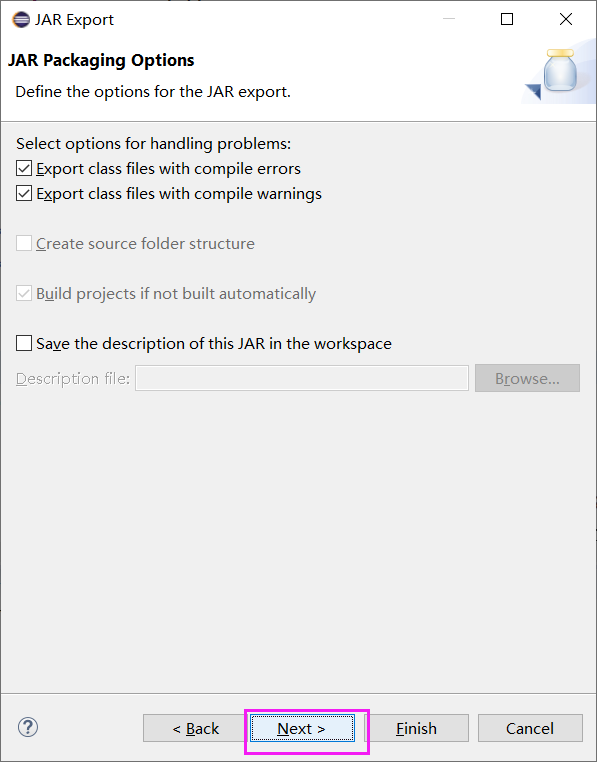
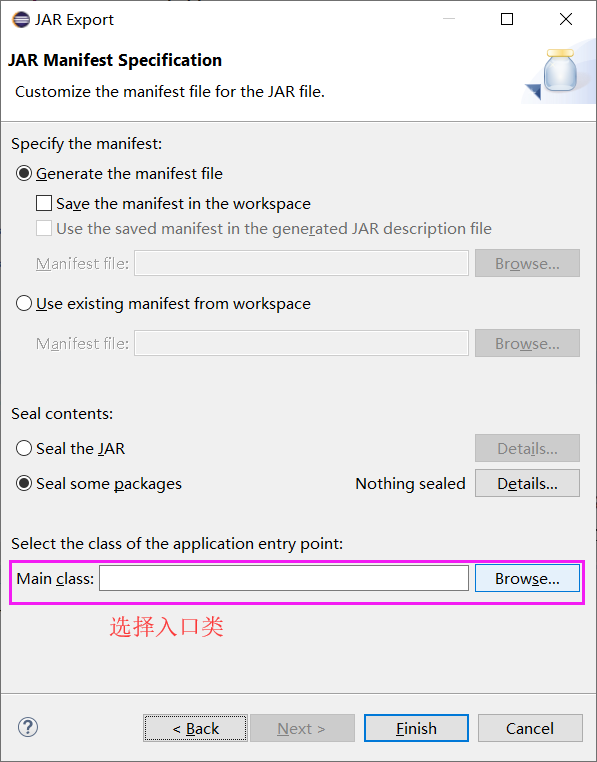
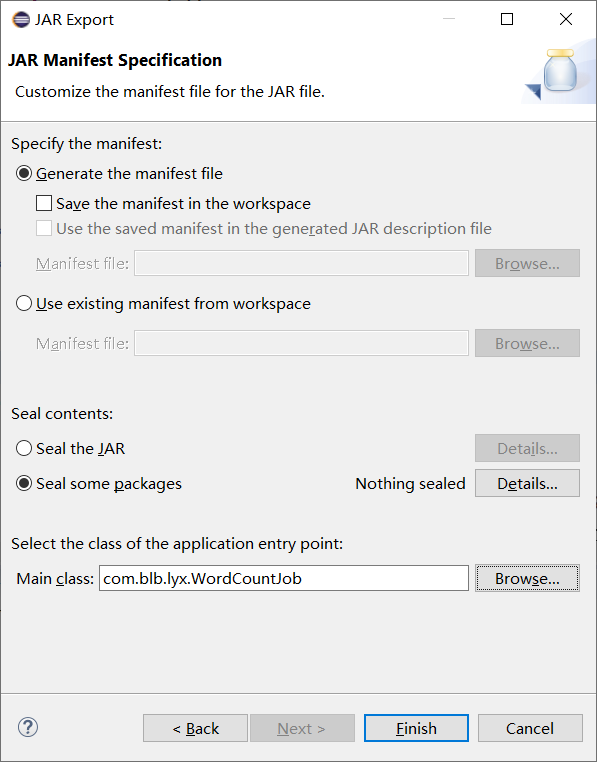
rz 上傳到虛擬機

4.運行jar包:hadoop jar wordcount.jar

運行完成
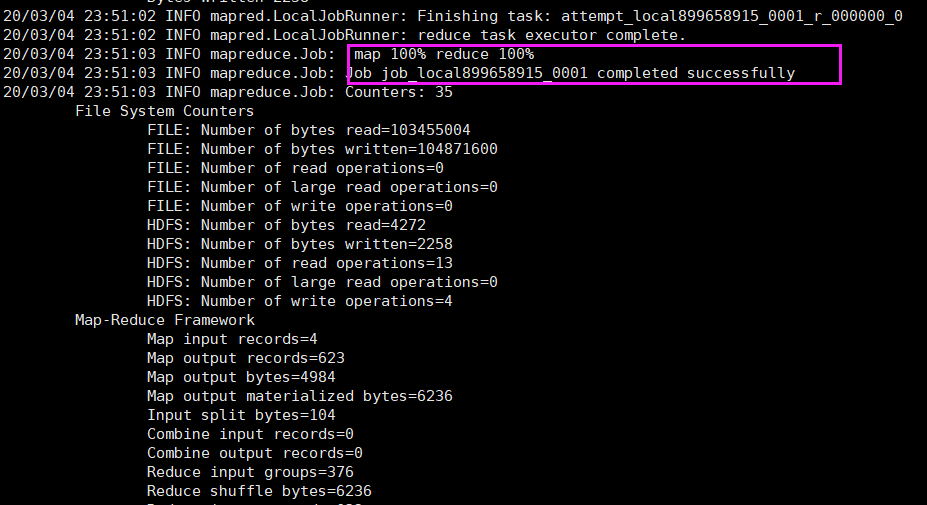
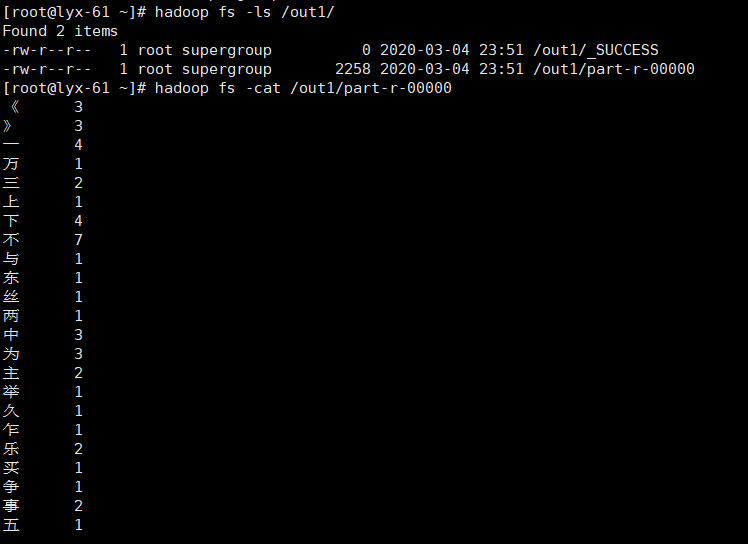
5.查看最后結果檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83361.html
標籤:其他
上一篇:Spark RRD統計操作
下一篇:spark-shell問題