作者|Marcelo Rovai
編譯|VK
來源|Towards Data Science
免責宣告
本研究是為X光影像中COVID-19的自動檢測而開發的,完全是為了教育目的,由于COVID-19沒有經過專業或學術評估,最終的應用并不打算成為一個準確的用于診斷人類的COVID-19的診斷系統,,
介紹
Covid-19是由一種病毒(SARS-CoV-2冠狀病毒)引起的大流行性疾病,已經感染了數百萬人,在幾個月內造成數十萬人死亡,
據世界衛生組織(WHO)稱,大多數COVID-19患者(約80%)可能無癥狀,約20%的患者可能因為呼吸困難而需要住院治療,在這些病例中,大約5%可能需要支持來治療呼吸衰竭(通氣支持),這種情況可能會使重癥監護設施崩潰,抗擊這一流行病的關鍵是快速檢測病毒攜帶者的方法,
冠狀病毒
冠狀病毒是引起呼吸道感染的病毒家族,這種新的冠狀病毒病原體是在中國登記病例后于1919年底發現, 它會導致一種名為冠狀病毒(COVID-19)的疾病,
1937年首次分離出人冠狀病毒,然而,直到1965年,這種病毒才被描述為冠狀病毒,因為它在顯微鏡下的輪廓看起來像一個樹冠,在下面的視頻中,你可以看到SARS-CoV-2病毒的原子級三維模型:
X光
近年來,基于計算機斷層掃描(CT)的機器學習在COVID-19診斷中的應用取得了一些有希望的成果,盡管這些方法取得了成功,但事實仍然是,COVID-19傳播在各種規模的社區,
X光機更便宜、更簡單、操作更快,因此比CT更適合在更貧困或更偏遠地區作業的醫療專業人員,
目標
對抗Covid-19的一個重大挑戰是檢測病毒在人體內的存在,因此,本專案的目標是使用掃描的胸部X光影像自動檢測肺炎患者(甚至無癥狀或非病人)中Covid-19的病毒,這些影像經過預處理,用于卷積神經網路(CNN)模型的訓練,
CNN型別的網路通常需要一個廣泛的資料集才能正常作業,但是,在這個專案中,應用了一種稱為“遷移學習”的技術,在資料集很小的情況下非常有用(例如Covid-19中患者的影像),
目的是開發兩種分類模型:
-
Covid-19的檢測與胸片檢測正常的比較
-
Covid-19的檢測與肺炎患者的檢測的比較
按冠狀病毒相關論文定義的,所有型別的肺炎(COVID-19病毒引起的除外)僅被認為是“肺炎”,并用Pneumo標簽(肺炎)分類,
我們使用TensorFlow 2.0的模型、工具、庫和資源,這是一個開源平臺,用于機器學習,或者更準確地說,用于深度學習,最后在Flask中開發了一個web應用程式(web app),用于在接近現實的情況下進行測驗,
下圖為我們提供了最終應用程式如何作業的基本概念:
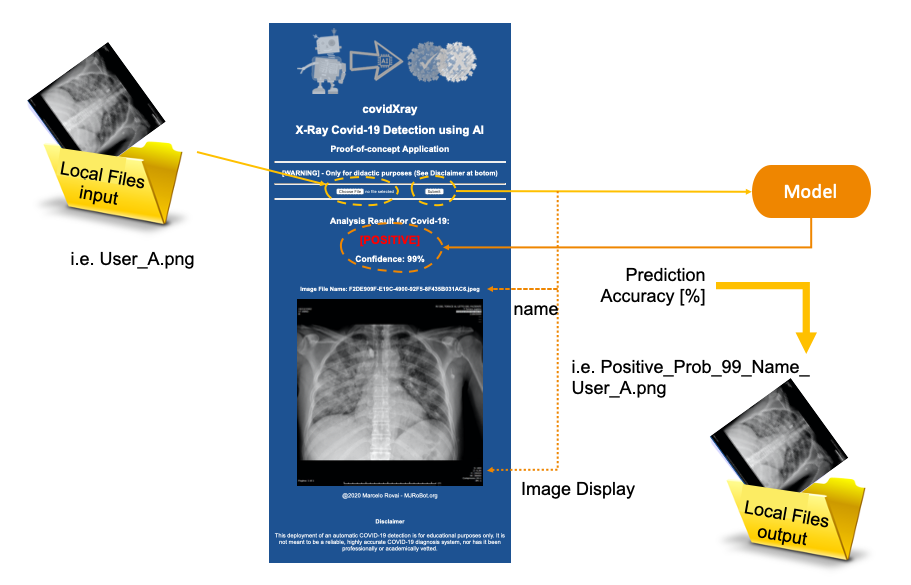
X光掃描胸部影像(User_A.png),應用程式將影像存盤在web應用程式的計算機上,決定影像是否屬于受病毒污染的人(模型預測:[陽性]或[陰性]),在這兩種情況下,應用程式都會通知預測的準確性(模型準確度:X%),
為了避免兩者都出錯,將向用戶顯示原始檔案的名稱及其影像,影像的新副本存盤在本地,其名稱添加一個預測標簽,并且加上準確度,
這項作業分為四個部分:
-
環境設定、資料清洗和準備
-
模型1訓練(Covid/正常)
-
模型2訓練(Covid/肺炎)
-
Web應用的開發與測驗
靈感
該專案的靈感來源于UFRRJ(里約熱內盧聯邦大學)開發的X光COVID-19專案,UFRRJ的XRayCovid-19是一個正在開發的專案,在診斷程序中使用人工智能輔助健康系統處理COVID-19,該工具的特點是易用、回應時間快和結果的有效性高,我希望將這些特點擴展到本教程第4部分開發的Web應用程式中,下面是診斷結果之一的列印螢屏(使用了Covid-19資料集1影像之一):
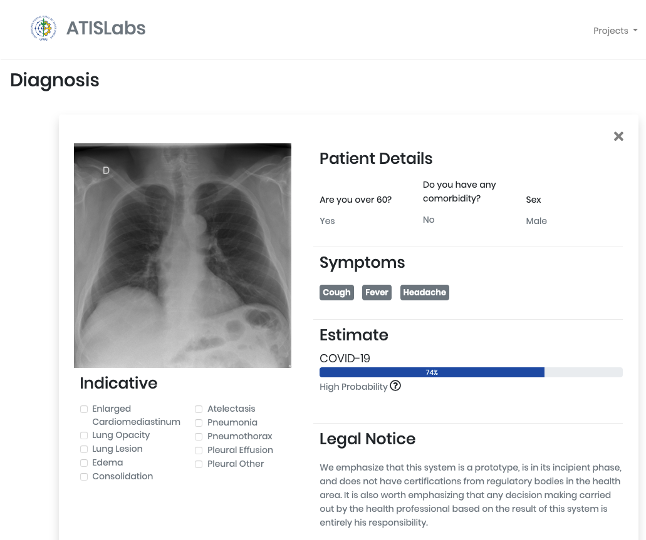
喬杜里等人在論文中闡述了該大學開展這項作業的科學依據,論文地址:https://arxiv.org/abs/2003.13145
另一項作業是Chester,論文:https://arxiv.org/pdf/1901.11210.pdf,由蒙特利爾大學的研究人員開發, Chester是一個免費且簡單的原型,醫療專業人員可以使用它們來了解深度學習工具的實際情況,以幫助診斷胸部X光, 該系統被設計為第二意見,用戶可在其中處理影像以確認或協助診斷,
當前版本的 Chester(2.0)使用DenseNet-121型卷積網路訓練了超過10.6萬張影像,該網路應用程式未檢測到Covid-19,這是研究人員對應用程式未來版本的目標之一, 下面是診斷結果之一的截圖(使用了Covid-19資料集的影像)
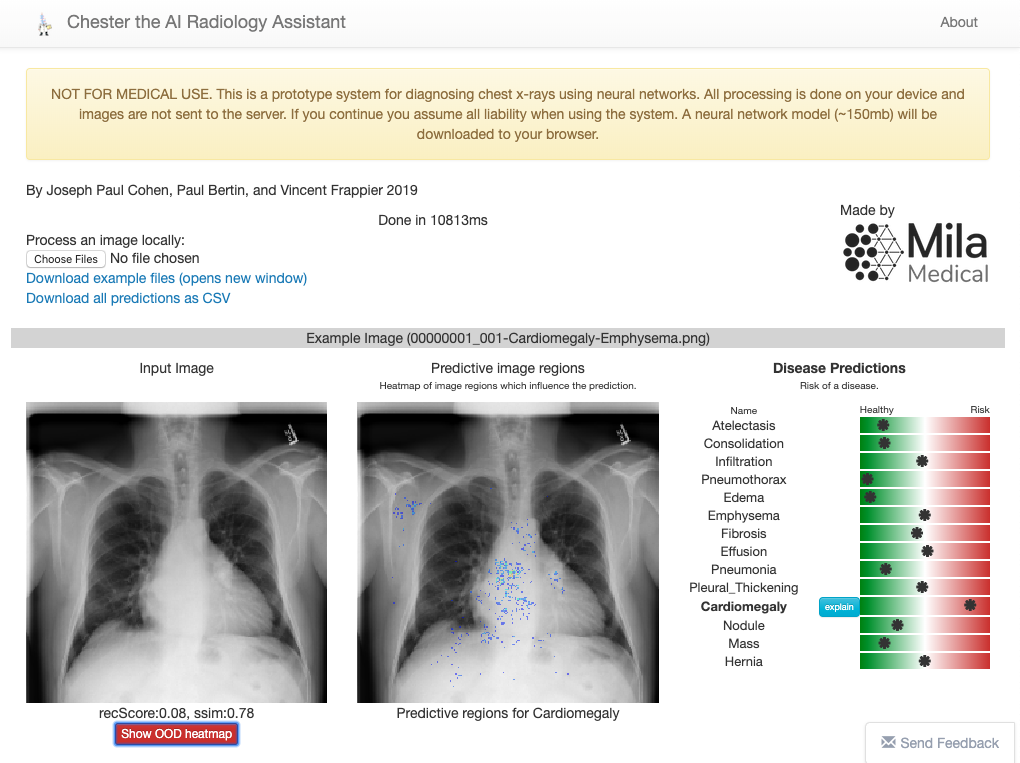
在下面的鏈接中,你可以訪問Chester,甚至下載應用程式供脫機使用:https://mlmed.org/tools/xray/,
感謝
這項作業最初是根據Adrian Rosebrock博士發表的優秀教程開發的,我強烈建議你深入閱讀,此外,我要感謝Nell Trevor,他根據羅斯布魯克博士的作業,進一步提出了如何測驗結果模型的想法,
第1部分-環境設定和資料準備
資料集
訓練模型以從影像中檢測任何型別的資訊的第一個挑戰是要使用的資料量, 原則上,可公開獲取的影像數量越多越好,但是請記住,這種流行病只有幾個月的歷史,所以對于Covid-19檢測專案來說,情況并非如此)
但是,Hall等人的研究,論文:https://arxiv.org/pdf/2004.02060.pdf,證明使用遷移學習技術僅用幾百幅影像就可以獲得令人鼓舞的結果,
如引言所述,訓練兩個模型;因此,需要3組資料:
- 確認Covid-19的X光影像集
- 常規(“正常”)患者的X光影像集
- 一組顯示肺炎但不是由Covid-19引起的X光影像
為此,將下載兩個資料集:
資料集1:COVID-19的影像集
Joseph Paul Cohen和Paul Morrison和Lan Dao COVID-19影像資料收集,arXiv: 2003.11597, 2020
這是一個公開的COVID-19陽性和疑似患者和其他病毒性和細菌性肺炎(MERS、SARS和ARDS)的X光和ct影像資料集,
資料是從公共來源收集的,也可以從醫院和醫生處間接收集(專案由蒙特利爾大學倫理委員會批準,CERSES-20-058-D),以下GitHub存盤庫中提供了所有影像和資料:https://github.com/ieee8023/covid-chestxray-dataset,
資料集2:肺炎和正常人的胸片
論文:Kermany, Daniel; Zhang, Kang; Goldbaum, Michael (2018), “Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images for Classification”
通過深度學習程序,將一組經驗證的影像(CT和胸片)歸類為正常和某些肺炎型別,影像分為訓練集和獨立的患者測驗集,資料可在網站上獲得:https://data.mendeley.com/datasets/rscbjbr9sj/2
胸片的型別
從資料集中,可以找到三種型別的影像,PA,AP和Lateral(L),L的很明顯,但X光的AP和PA視圖有什么區別?簡單地說,在拍X光片的程序中,當X光片從身體的后部傳到前部時,稱為PA(后-前)視圖,在AP視圖中,方向相反,
通常,X光片是在AP視圖中拍攝的,但是一個重要的例外就是胸部X光片,在這種情況下,最好在查看PA而不是AP,但如果病人病得很重,不能保持姿勢,可以拍AP型胸片,
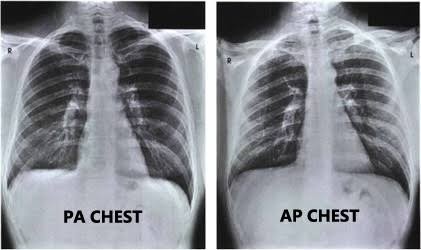
由于絕大多數胸部X光片都是PA型視圖,所以這是用于訓練模型的視圖選擇型別,
定義用于訓練DL模型的環境
理想的做法是從一個新的Python環境開始,為此,使用Terminal定義一個作業目錄(例如:X-Ray_Covid_development),然后在那里用Python創建一個環境(例如:TF_2_Py_3_7):
mkdir X-Ray_Covid_development
cd X-Ray_Covid_development
conda create — name TF_2_Py_3_7 python=3.7 -y
conda activate TF_2_Py_3_7
進入環境后,安裝TensorFlow 2.0:
pip install — upgrade pip
pip install tensorflow
從這里開始,安裝訓練模型所需的其他庫,例如:
conda install -c anaconda numpy
conda install -c anaconda pandas
conda install -c anaconda scikit-learn
conda install -c conda-forge matplotlib
conda install -c anaconda pillow
conda install -c conda-forge opencv
conda install -c conda-forge imutils
創建必要的子目錄:
notebooks
10_dataset —
|_ covid [here goes the dataset for training model 1]
|_ normal [here goes the dataset for training model 1]
20_dataset —
|_ covid [here goes the dataset for training model 2]
|_ pneumo [here goes the dataset for training model 2]
input -
|_ 10_Covid_Imagens _
| |_ [metadata.csv goes here]
| |_ images [Covid-19 images go here]
|_ 20_Chest_Xray -
|_ test _
|_ NORMAL [images go here]
|_ PNEUMONIA [images go here]
|_ train _
|_ NORMAL [images go here]
|_ PNEUMONIA [images go here]
model
dataset_validation _
|_ covid_validation [images go here]
|_ non_covidcovid_validation [images go here]
|_ normal_validation [images go here]
資料下載
下載資料集1(Covid-19),并將metadata.csv檔案保存在/input/10_Covid_Images/和/input/10_Covid_Images/Images/下,
下載資料集2(肺炎和正常),并將影像保存在/input/20_Chest_Xray/下(保持原始測驗和訓練結構),
第2部分-模型1-Covid/正常
資料準備
-
從GitHub下載Notebook:https://github.com/Mjrovai/covid19Xray/blob/master/10_X-Ray_Covid_development/notebooks/10_Xray_Normal_Covid19_Model_1_Training_Tests.ipynb,將其存盤在 subdirectory /notebooks中,
-
進入Notebook后,匯入庫并運行支持函式,
構建Covid標簽資料集
從輸入資料集(/input/10_Covid_Images/)創建用于訓練模型1的資料集,該資料集將用于Covid和normal(正常)標簽定義的影像分類,
input_dataset_path = ‘../input/10_Covid_images’
metadata.csv檔案將提供有關/images/檔案中的影像的資訊,
csvPath = os.path.sep.join([input_dataset_path, “metadata.csv”])
df = pd.read_csv(csvPath)
df.shape
metadat.csv檔案有354行28列,這意味著在subdirectory /notebooks中有354個X光影像,讓我們分析它的一些列,了解這些影像的更多細節,
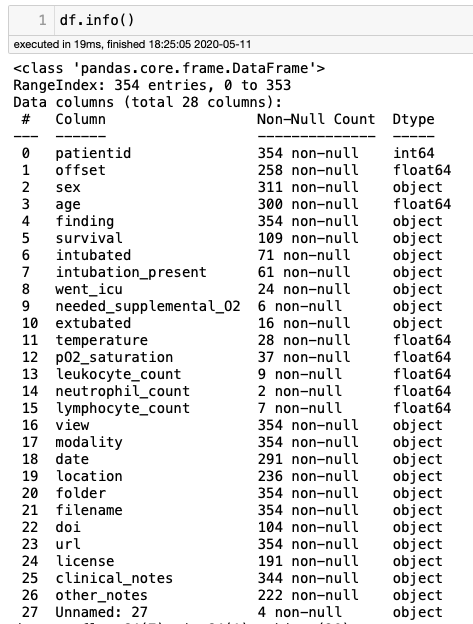
通過df.modality,共有310張X光影像和44張CT影像,CT影像被丟棄,
COVID-19 235
Streptococcus 17
SARS 16
Pneumocystis 15
COVID-19, ARDS 12
E.Coli 4
ARDS 4
No Finding 2
Chlamydophila 2
Legionella 2
Klebsiella 1
從可視化角度看,COVID-19的235張確認影像,我們有:
PA 142
AP 39
AP Supine 33
L 20
AP semi erect 1
如引言中所述,只有142張PA型影像(后-前)用于模型訓練,因為它們是胸片中最常見的影像(最終資料框:xray_cv),
“xray_cv.patiendid”列顯示,這142張照片屬于96個病人,這意味著在某些情況下,同一個病人拍攝了多張X光片,由于所有影像都用于訓練(我們對影像的內容感興趣),因此不考慮此資訊,
根據xray_cv.date,2020年3月拍攝的最新照片有8張,這些影像被分離在一個串列中,從模型訓練中洗掉, 因此,以后將用作最終模型的驗證,
imgs_march = [
‘2966893D-5DDF-4B68–9E2B-4979D5956C8E.jpeg’,
‘6C94A287-C059–46A0–8600-AFB95F4727B7.jpeg’,
‘F2DE909F-E19C-4900–92F5–8F435B031AC6.jpeg’,
‘F4341CE7–73C9–45C6–99C8–8567A5484B63.jpeg’,
‘E63574A7–4188–4C8D-8D17–9D67A18A1AFA.jpeg’,
‘31BA3780–2323–493F-8AED-62081B9C383B.jpeg’,
‘7C69C012–7479–493F-8722-ABC29C60A2DD.jpeg’,
‘B2D20576–00B7–4519-A415–72DE29C90C34.jpeg’
]
下一步將構建指向訓練資料集(xray_cv_train)的資料框,該資料框應參考134個影像(來自Covid的所有輸入影像,用于稍后驗證的影像除外):
xray_cv_train = xray_cv[~xray_cv.filename.isin(imgs_march)]
xray_cv_train.reset_index(drop=True, inplace=True)
而最終的驗證集(xray_cv_val )有8個影像:
xray_cv_val = xray_cv[xray_cv.filename.isin(imgs_march)]
xray_cv_val.reset_index(drop=True, inplace=True)
為COVID訓練影像創建檔案
要記住,在前一項中,只有資料框是使用從原始檔案metada.csv中獲取的資訊創建的,我們知道哪些影像要存盤在最終的訓練檔案中,現在我們需要“物理地”將實際影像(以數字化格式)分離到正確的子目錄(檔案夾)中,
為此,我們將使用load_image_folder support()函式,該函式將元資料檔案中參考的影像從一個檔案復制到另一個檔案:
def load_image_folder(df_metadata,
col_img_name,
input_dataset_path,
output_dataset_path):
img_number = 0
# 對COVID-19的行進行回圈
for (i, row) in df_metadata.iterrows():
imagePath = os.path.sep.join([input_dataset_path, row[col_img_name]])
if not os.path.exists(imagePath):
print('image not found')
continue
filename = row[col_img_name].split(os.path.sep)[-1]
outputPath = os.path.sep.join([f"{output_dataset_path}", filename])
shutil.copy2(imagePath, outputPath)
img_number += 1
print('{} selected Images on folder {}:'.format(img_number, output_dataset_path))
按照以下說明,134個選定影像將被復制到檔案夾../10_dataset/covid/,
input_dataset_path = '../input/10_Covid_images/images'
output_dataset_path = '../dataset/covid'
dataset = xray_cv_train
col_img_name = 'filename'
load_image_folder(dataset, col_img_name,
input_dataset_path, output_dataset_path)
為正常影像創建檔案夾
對于資料集2(正常和肺炎影像),不提供包含元資料的檔案,因此,你只需將影像從輸入檔案復制到末尾,為此,我們創建load_image_folder_direct()函式,該函式將許多影像(隨機選擇)從une檔案夾復制到另一個檔案夾:
def load_image_folder_direct(input_dataset_path,
output_dataset_path,
img_num_select):
img_number = 0
pathlist = Path(input_dataset_path).glob('**/*.*')
nof_samples = img_num_select
rc = []
for k, path in enumerate(pathlist):
if k < nof_samples:
rc.append(str(path)) # 路徑不是字串形式
shutil.copy2(path, output_dataset_path)
img_number += 1
else:
i = random.randint(0, k)
if i < nof_samples:
rc[i] = str(path)
print('{} selected Images on folder {}:'.format(img_number, output_dataset_path))
在../input/20_Chest_Xray/train/NORMAL檔案夾重復同樣的程序,我們將隨機復制用于訓練的相同數量的影像 (len (xray_cv_train)),134個影像,這樣,用于訓練模型的資料集是平衡的,
input_dataset_path = '../input/20_Chest_Xray/train/NORMAL'
output_dataset_path = '../dataset/normal'
img_num_select = len(xray_cv_train)
load_image_folder_direct(input_dataset_path, output_dataset_path,
img_num_select)
以同樣的方式,我們分離出20個隨機影像,以供以后在模型驗證中使用,
input_dataset_path = '../input/20_Chest_Xray/train/NORMAL'
output_dataset_path = '../dataset_validation/normal_validation'
img_num_select = 20
load_image_folder_direct(input_dataset_path, output_dataset_path,
img_num_select)
盡管我們沒有用顯示肺炎癥狀的影像(Covid-19)來訓練模型,但是觀察最終模型如何與肺炎癥狀一起作業是很有趣的,因此,我們還分離了其中的20幅影像,以供驗證,
input_dataset_path = '../input/20_Chest_Xray/train/PNEUMONIA'
output_dataset_path = '../dataset_validation/non_covid_pneumonia_validation'
img_num_select = 20
load_image_folder_direct(input_dataset_path, output_dataset_path,
img_num_select)
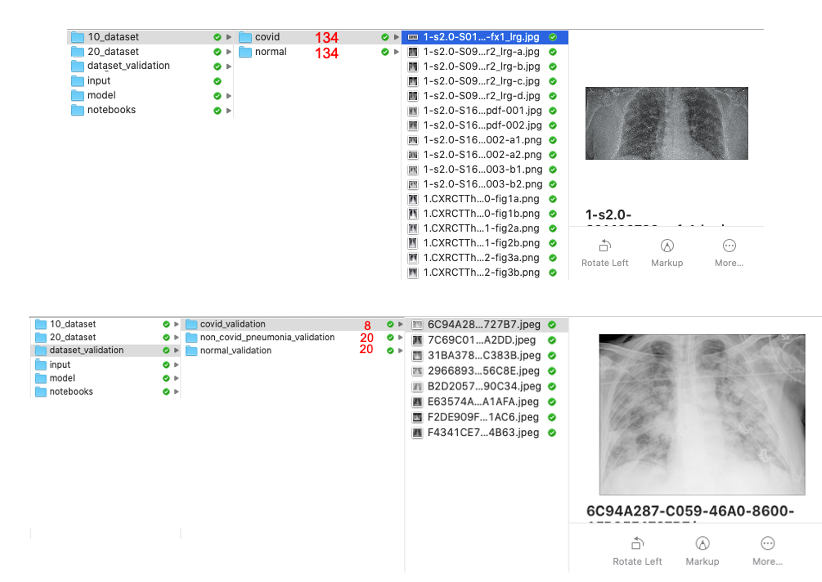
下面的圖片顯示了在這個步驟結束時應該如何組態檔夾(無論如何在我的Mac上),此外,紅色標記的數字顯示檔案夾中包含的x光影像的相應數量,
繪制資料集
由于檔案夾中的影像數量不多,因此可以對其進行可視化檢查,為此,使用 plots_from_files():
def plots_from_files(imspaths,
figsize=(10, 5),
rows=1,
titles=None,
maintitle=None):
"""Plot the images in a grid"""
f = plt.figure(figsize=figsize)
if maintitle is not None:
plt.suptitle(maintitle, fontsize=10)
for i in range(len(imspaths)):
sp = f.add_subplot(rows, ceildiv(len(imspaths), rows), i + 1)
sp.axis('Off')
if titles is not None:
sp.set_title(titles[i], fontsize=16)
img = plt.imread(imspaths[i])
plt.imshow(img)
def ceildiv(a, b):
return -(-a // b)
然后,定義將在訓練中使用的資料集的路徑和帶有要查看的影像名稱的串列:
dataset_path = '../10_dataset'
normal_images = list(paths.list_images(f"{dataset_path}/normal"))
covid_images = list(paths.list_images(f"{dataset_path}/covid"))
通過呼叫可視化支持函式,可以顯示以下影像:
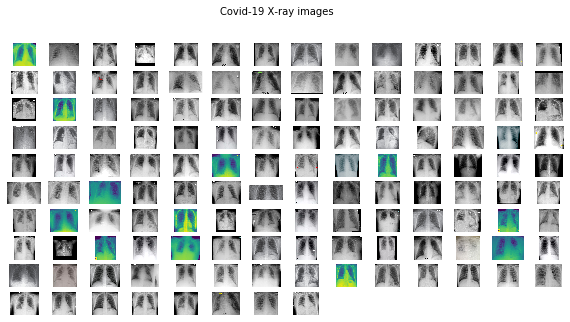
plots_from_files(covid_images, rows=10, maintitle="Covid-19 X-ray images")
plots_from_files(normal_images, rows=10, maintitle="Normal X-ray images")
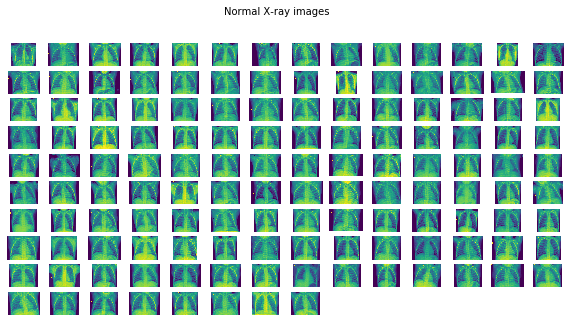
影像看起來不錯,
預訓練的卷積神經網路模型
該模型的訓練是使用預定義的影像進行的,應用了稱為“遷移學習”的技術,
遷移學習是一種機器學習方法,其中為一個任務開發的模型被重用為第二個任務中模型的起點,
Keras應用程式是Keras的深度學習庫模塊,它為幾種流行的架構(如VGG16、ResNet50v2、ResNet101v2、Xception、MobileNet等)提供模型定義和預訓練的權重,
使用的預訓練模型是VGG16,由牛津大學視覺圖形組(VGG)開發,并在論文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中描述,除了在開發公共的影像分類模型時非常流行外,這也是Adrian博士在其教程中建議的模型,
理想的做法是使用幾個模型(例如ResNet50v2、ResNet101v2)進行測驗(基準測驗),甚至創建一個特定的模型(如Zhang等人在論文中建議的模型:https://arxiv.org/pdf/2003.12338.pdf),但由于這項作業的最終目標只是概念上的驗證,所以我們僅探索VGG16,
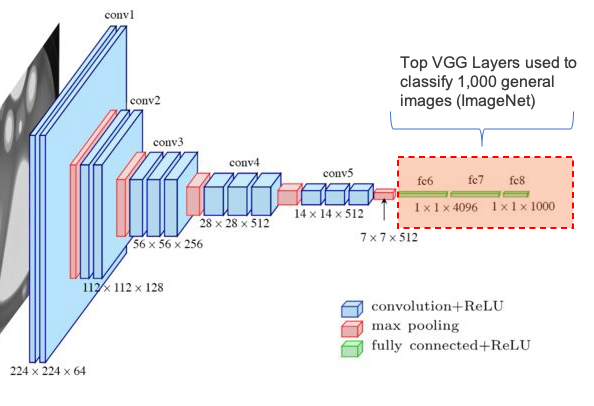
VGG16是一種卷積神經網路(CNN)體系結構,盡管在2014年已經開發出來,但今天仍然被認為是處理影像分類的最佳體系結構之一,
VGG16體系結構的一個特點是,它們沒有大量的超引數,而是專注于卷積層上,卷積層上有一個3x3濾波器(核)和一個2x2最大池層,在整個體系結構中始終保持一組卷積和最大池化層,最后,該架構有2個FC(完全連接的層)和softmax激活輸出,
VGG16中的16表示架構中有16個帶權重的層,該網路是巨大的,在使用所有原始16層的情況下,有將近1.4億個訓練引數,
在我們的例子中,最后兩層(FC1和FC2)是在本地訓練的,引數總數超過1500萬,其中大約有590000個引數是在本地訓練的(而其余的是“frozen(凍結的)”),
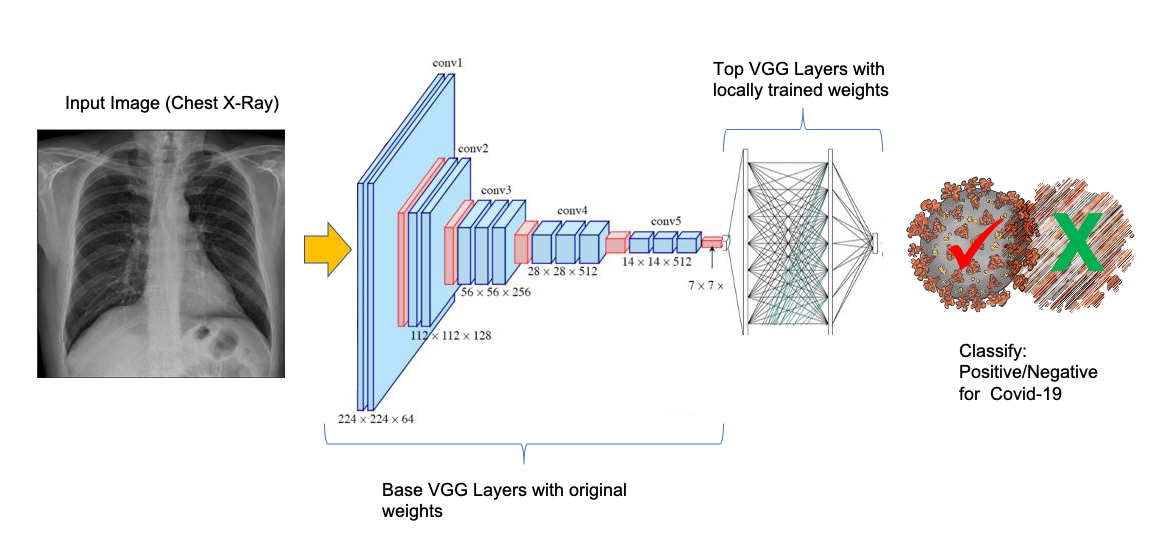
需要注意的第一點是,VNN16架構的第一層使用224x224x3的影像,因此我們必須確保要訓練的X光影像也具有這些維度,因為它們是卷積網路的“第一層”的一部分,因此,當使用原始權重(weights=“imagenet”)加載模型時,我們不保留模型的頂層(include_top=False),而這些層將被我們的層(headModel)替換,
baseModel = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
接下來,我們必須定義用于訓練的超引數(在下面的注釋中,將測驗一些可能的值以提高模型的“準確性”):
INIT_LR = 1e-3 # [0.0001]
EPOCHS = 10 # [20]
BS = 8 # [16, 32]
NODES_DENSE0 = 64 # [128]
DROPOUT = 0.5 # [0.0, 0.1, 0.2, 0.3, 0.4, 0.5]
MAXPOOL_SIZE = (4, 4) # [(2,2) , (3,3)]
ROTATION_DEG = 15 # [10]
SPLIT = 0.2 # [0.1]
然后構建我們的模型,將其添加到基礎模型中:
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=MAXPOOL_SIZE)(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(NODES_DENSE0, activation="relu")(headModel)
headModel = Dropout(DROPOUT)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
headModel被放置在基礎模型之上,成為模型的一部分,進行實際訓練(確定最佳權重),
model = Model(inputs=baseModel.input, outputs=headModel)
重要的是要記住一個預訓練過的CNN模型,如VGG16,被訓練了成千上萬的影像來分類普通影像(如狗、貓、汽車和人),我們現在需要做的是根據我們的需要定制它(分類X光影像),理論上,模型的第一層簡化了影像的部分,識別出其中的形狀,這些初始標簽非常通用(如直線、圓和正方形),因此我們不用再訓練它們,我們只想訓練網路的最后一層,
下面的回圈在基礎模型的所有層上執行,“凍結”它們,以便在第一個訓練程序中不會更新它們,
for layer in baseModel.layers:
layer.trainable = False
此時,模型已經準備好接受訓練,但首先,我們必須為模型的訓練準備資料(影像),
資料預處理
我們先創建一個包含存盤影像的名稱(和路徑)的串列:
imagePaths = list(paths.list_images(dataset_path))
那么對于串列中的每個影像,我們必須:
-
提取影像標簽(在本例中為covid或normal)
-
將BGR(CV2默認值)的影像通道設定為RGB
-
將影像大小調整為224x 224(VGG16的默認值)
data = https://www.cnblogs.com/panchuangai/p/[]
labels = []
for imagePath in imagePaths:
label = imagePath.split(os.path.sep)[-2]
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
data.append(image)
labels.append(label)
資料和標簽被轉換成陣列,每個像素的值從0到255改成從0到1,便于訓練,
data = https://www.cnblogs.com/panchuangai/p/np.array(data) / 255.0
labels = np.array(labels)
標簽將使用一個one-hot編碼技術進行數字編碼,
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
此時,訓練資料集分為訓練集和測驗集(訓練80%,測驗20%):
(trainX, testX, trainY, testY) = train_test_split(data,
labels,
test_size=SPLIT,
stratify=labels,
random_state=42)
最后但并非最不重要的是,我們應該應用“資料增強”技術,
資料增強
如Chowdhury等人所建議,在他們的論文中,三種增強策略(旋轉、縮放和平移)可用于為COVID-19生成額外的訓練影像,有助于防止“過度擬合”:https://arxiv.org/pdf/2003.13145.pdf,

原始胸部X光影像(A),逆時針旋轉45度后影像(B),順時針旋轉45度后影像,水平和垂直平移20%后影像(D),放大10%后影像(E),
使用TS/Keras影像預處理庫(ImageDataGenerator),可以更改多個影像引數,例如:
trainAug = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
一開始,僅應用影像最大旋轉15度來評估結果,
trainAug = ImageDataGenerator(rotation_range=ROTATION_DEG, fill_mode="nearest")
此時,我們已經定義了模型和資料,并準備好進行編譯和訓練,
模型構建與訓練
編譯允許我們給模型添加額外的特性,比如loss函式、優化器和度量,
對于網路訓練,我們使用損失函式來計算網路預測值與訓練資料實際值之間的差異,伴隨著優化器演算法(如Adam)對網路中的權重進行更改,這些超引數有助于網路訓練的收斂,使損失值盡可能接近于零,
我們還指定了優化器(lr)的學習率,在這種情況下,lr被定義為1e-3,如果在訓練程序中注意到“跳躍”的增加,即模型不能收斂,則應降低學習率,以達到最小值,
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
讓我們來訓練模型:
H = model.fit(
trainAug.flow(trainX, trainY, batch_size=BS),
steps_per_epoch=len(trainX) // BS,
validation_data=https://www.cnblogs.com/panchuangai/p/(testX, testY),
validation_steps=len(testX) // BS,
epochs=EPOCHS)

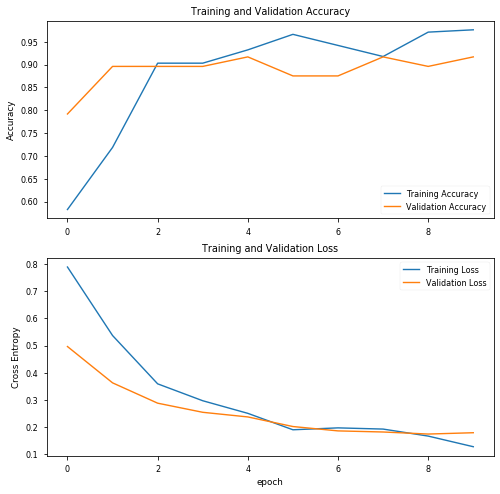
結果看起來已經相當有趣了,驗證資料的精度達到了92%!繪制精度圖表:
評估訓練模型:
看看混淆矩陣:
[[27 0]
[ 4 23]]
acc: 0.9259
sensitivity: 1.0000
specificity: 0.8519
從用最初選擇的超引數訓練的模型中,我們得到:
- 100%的sensitivity(敏感度),也就是說,對于COVID-19陽性(即真正例)的患者,我們可以在100%的時間內準確地將其識別為“COVID-19陽性”,
- 85%的specificity(特異性)意味著在沒有COVID-19(即真反例)的患者中,我們只能在85%的時間內準確地將其識別為“COVID-19陰性”,
結果并不令人滿意,因為15%沒有Covid的患者會被誤診,我們先對模型進行微調,更改一些超引數:
因此,我們有:
INIT_LR = 0.0001 # 曾經是 1e-3
EPOCHS = 20 # 曾經是 10
BS = 16 # 曾經是 8
NODES_DENSE0 = 128 # 曾經是 64
DROPOUT = 0.5
MAXPOOL_SIZE = (2, 2) # 曾經是 (4, 4)
ROTATION_DEG = 15
SPLIT = 0.2
結果
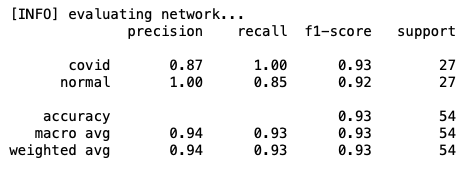
precision recall f1-score support
covid 0.93 1.00 0.96 27
normal 1.00 0.93 0.96 27
accuracy 0.96 54
macro avg 0.97 0.96 0.96 54
weighted avg 0.97 0.96 0.96 54
以及混淆矩陣:
[[27 0]
[ 2 25]]
acc: 0.9630
sensitivity: 1.0000
specificity: 0.9259
結果好多了!現在具有93%的特異性,這意味著在沒有COVID-19(即真反例)的患者中,在93%到100%的時間內我們可以準確地將他們識別為“COVID-19陰性”,
目前看來,這個結果很有希望,讓我們保存這個模型,在那些沒有經過訓練的影像上測驗(Covid-19的8個影像和從輸入資料集中隨機選擇的20個影像),
model.save("../model/covid_normal_model.h5")
在真實影像中測驗模型(驗證)
首先,讓我們檢索模型并顯示最終的體系結構,以檢查一切是否正常:
new_model = load_model('../model/covid_normal_model.h5')
# 展示模型架構
new_model.summary()
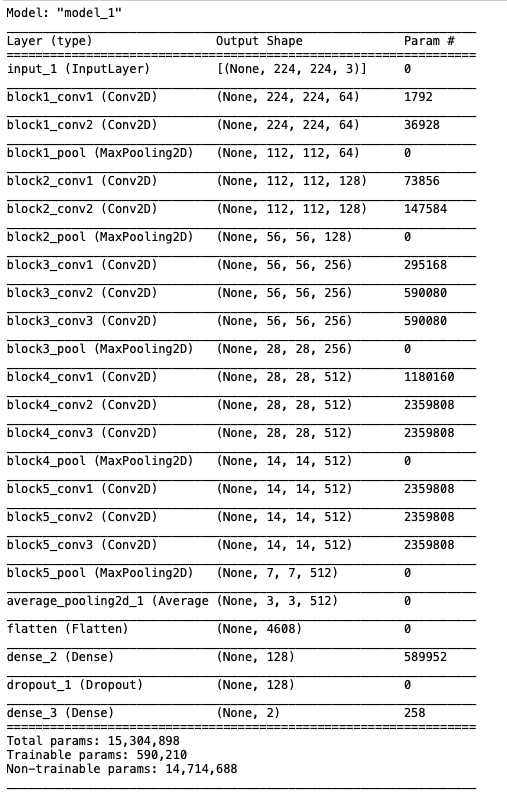
這個模型看起來不錯,是VGG16的16層結構,請注意,可訓練引數為590210,這是最后兩層的總和,它們被添加到引數為14.7M的預訓練模型中,
讓我們驗證測驗資料集中加載的模型:
[INFO] evaluating network...
precision recall f1-score support
covid 0.93 1.00 0.96 27
normal 1.00 0.93 0.96 27
accuracy 0.96 54
macro avg 0.97 0.96 0.96 54
weighted avg 0.97 0.96 0.96 54
很好,我們得到了與之前相同的結果,這意味著訓練的模型被正確地保存和加載,現在讓我們用之前保存的8個Covid影像驗證模型,為此,我們創建了另外一個函式,它是為單個影像測驗開發的
def test_rx_image_for_Covid19(imagePath):
img = cv2.imread(imagePath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, axis=0)
img = np.array(img) / 255.0
pred = new_model.predict(img)
pred_neg = round(pred[0][1]*100)
pred_pos = round(pred[0][0]*100)
print('\n X-Ray Covid-19 Detection using AI - MJRovai')
print(' [WARNING] - Only for didactic purposes')
if np.argmax(pred, axis=1)[0] == 1:
plt.title('\nPrediction: [NEGATIVE] with prob: {}% \nNo Covid-19\n'.format(
pred_neg), fontsize=12)
else:
plt.title('\nPrediction: [POSITIVE] with prob: {}% \nPneumonia by Covid-19 Detected\n'.format(
pred_pos), fontsize=12)
img_out = plt.imread(imagePath)
plt.imshow(img_out)
plt.savefig('../Image_Prediction/Image_Prediction.png')
return pred_pos
在Notebook上,此函式將顯示以下結果:
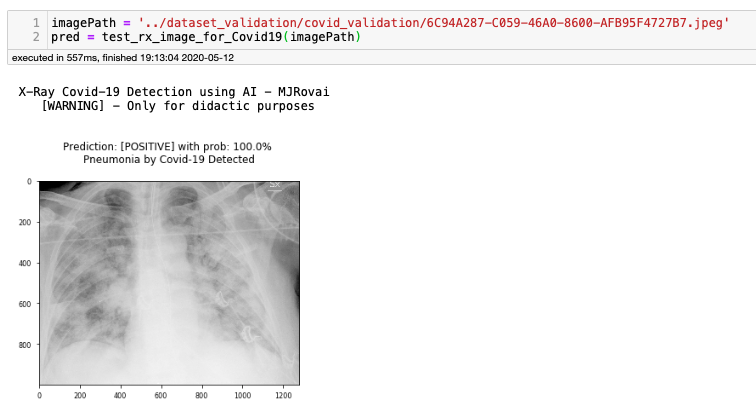
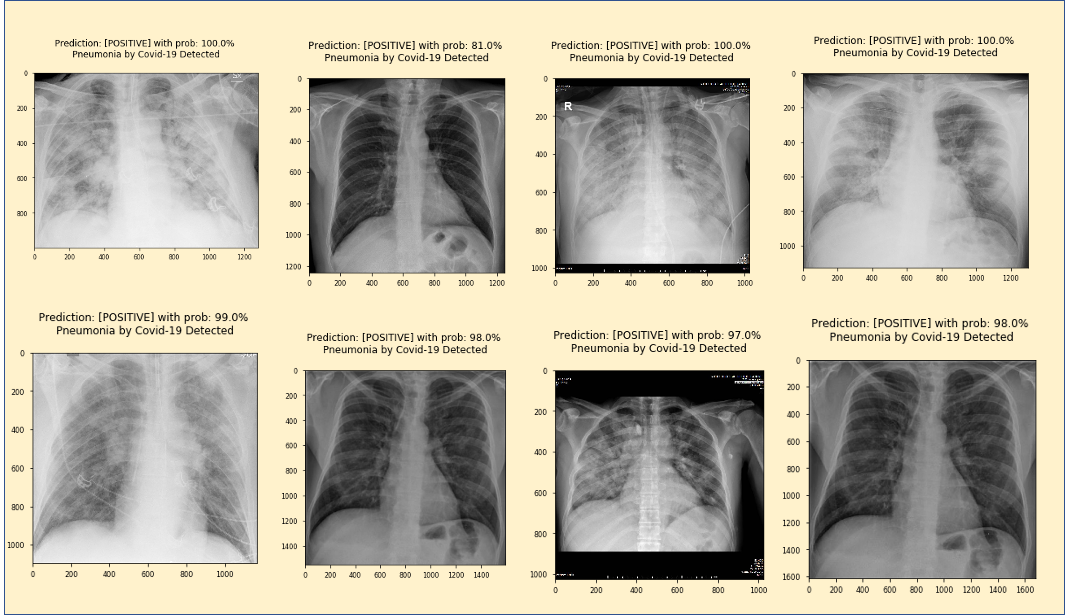
通過更改其余7個影像的imagePath值,我們獲得以下結果:
所有影像均呈陽性,確認100%靈敏度,
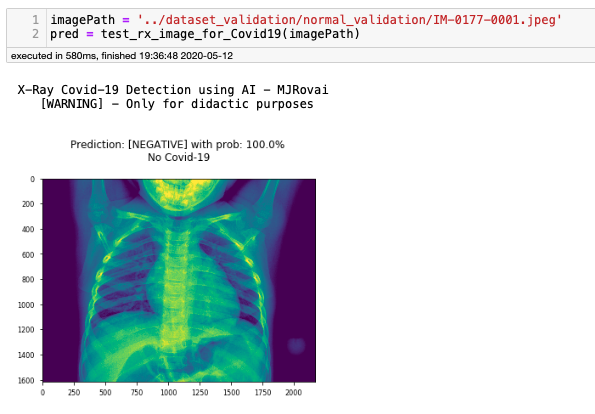
現在讓我們測驗20個單獨的影像,以驗證標記為NORMAL的有效性,Notebook上的第一個應該是:
一個接一個的測驗可以確認預測,但是由于我們有更多的影像,讓我們使用另一個函式來測驗一組影像,一次完成: test_rx_image_for_Covid19_batch (img_lst) ,
批處理測驗影像
讓我們創建包含在驗證檔案夾中的影像的串列:
validation_path = '../dataset_validation'
normal_val_images = list(paths.list_images(
f"{validation_path}/normal_validation"))
non_covid_pneumonia_validation_images = list(paths.list_images(
f"{validation_path}/non_covid_pneumonia_validation"))
covid_val_images = list(paths.list_images(
f"{validation_path}/covid_validation"))
test_rx_image_for_Covid19_batch (img_lst) 函式如下:
def test_rx_image_for_Covid19_batch(img_lst):
neg_cnt = 0
pos_cnt = 0
predictions_score = []
for img in img_lst:
pred, neg_cnt, pos_cnt = test_rx_image_for_Covid19_2(img, neg_cnt, pos_cnt)
predictions_score.append(pred)
print ('{} positive detected in a total of {} images'.format(pos_cnt, (pos_cnt+neg_cnt)))
return predictions_score, neg_cnt, pos_cnt
將該函式應用于我們先前分離的20幅影像:
img_lst = normal_val_images
normal_predictions_score, normal_neg_cnt, normal_pos_cnt = test_rx_image_for_Covid19_batch(img_lst)
normal_predictions_score
我們觀察到,所有20人被診斷為陰性,得分如下(記住,接近“1”代表“陽性”):
0.25851375,
0.025379542,
0.005824779,
0.0047603976,
0.042225637,
0.025087152,
0.035508618,
0.009078974,
0.014746706,
0.06489486,
0.003134642,
0.004970203,
0.15801577,
0.006775451,
0.0032735346,
0.007105667,
0.001369465,
0.005155371,
0.029973848,
0.014993184
只有2例影像的評估(1-準確度)低于90%(0.26和0.16),
請記住,輸入資料集/input/20_Chest_Xray/有兩個檔案夾,/train和/test,只有/train中的一部分影像用于訓練,并且模型從未看到測驗影像:
input -
|_ 10_Covid_Imagens _
| |_ metadata.csv
| |_ images [used train model 1]
|_ 20_Chest_Xray -
|_ test _
|_ NORMAL
|_ PNEUMONIA
|_ train _
|_ NORMAL [used train model 1]
|_ PNEUMONIA
然后,我們可以利用這個檔案夾測驗所有影像,首先,我們創建了影像串列:
validation_path = '../input/20_Chest_Xray/test'
normal_test_val_images = list(paths.list_images(f"{validation_path}/NORMAL"))
print("Normal Xray Images: ", len(normal_test_val_images))
pneumo_test_val_images = list(paths.list_images(f"{validation_path}/PNEUMONIA"))
print("Pneumo Xray Images: ", len(pneumo_test_val_images))
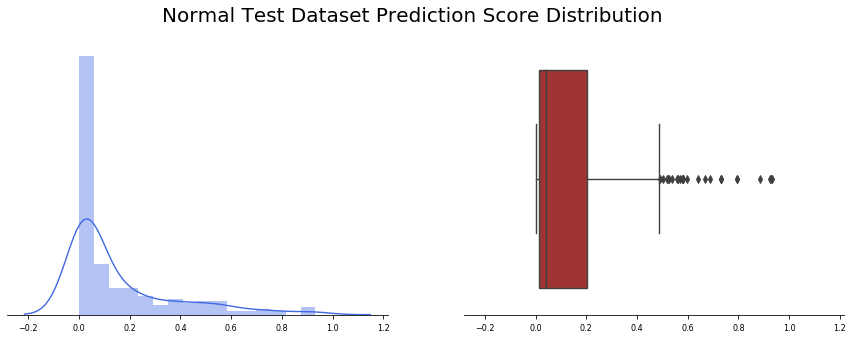
我們觀察了234張診斷為正常的“未公開”圖片(還有390張不是由Covid-19引起的肺炎),應用批處理函式,我們觀察到24幅影像出現假陽性(約10%),讓我們看看模型輸出值是如何分布的,記住函式回傳的值計算如下:
pred = new_model.predict(image)
pred_pos = round(pred[0][0] * 100)
我們觀察到,預測精度的平均值為0.15,并且非常集中于接近于零的值(中值僅為0.043),有趣的是,大多數誤報率接近0.5,少數例外值高于0.6,
除了改進模型外,還值得研究產生假陽性的影像,
測驗不是由Covid引起的肺炎影像
由于輸入資料集也有肺炎患者的X光影像,但不是由Covid引起的,所以讓我們應用模型1(Covid/Normal)來查看結果是什么:
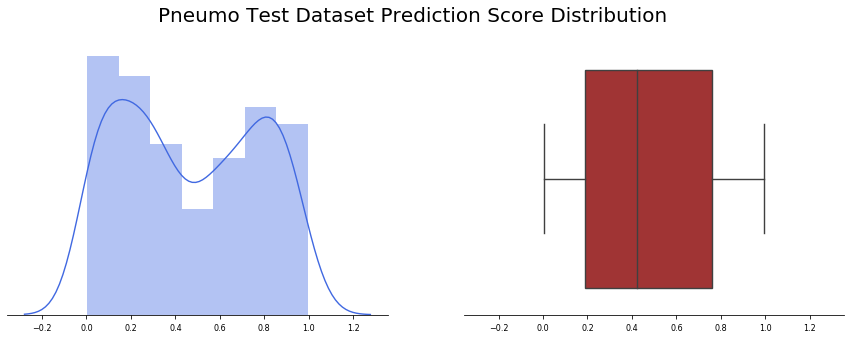
結果非常糟糕,在390張圖片中,185張有假陽性,而觀察結果的分布,發現有一個峰值接近80%,也就是說,這是非常錯誤的!
回顧這一結果在技術上并不令人驚訝,因為該模型沒有經過普通肺炎患者影像的訓練,
不管怎樣,這是一個大問題,因為我認為專家可以用肉眼區分病人是否患有肺炎,然而,也許更難區分這種肺炎是由Covid-19(SARS-CoV-2)、任何其他病毒,甚至是細菌引起的,
將Covid-19引起的肺炎患者與其他型別的病毒或細菌區分開來的模型更有 用,為此,另一個模型將被訓練,現在有感染Covid-19的病人和感染肺炎但不是由Covid-19病毒引起的病人的影像,
第3部分-模型2-Covid/普通肺炎
資料準備
-
從我的GitHub下載Notebook放入subdirectory /notebooks目錄:https://github.com/Mjrovai/covid19Xray/blob/master/10_X-Ray_Covid_development/notebooks/20_Xray_Pneumo_Covid19_Model_2_Training_Tests.ipynb,
-
匯入使用的庫并運行,
模型2中使用的Covid影像資料集與模型1中使用的相同,只是現在它存盤在不同的檔案夾中,
dataset_path = '../20_dataset'
肺炎影像將從檔案夾/input/20_Chest_Xray/train/PNEUMONIA/下載并存盤在/20_dataset/pneumo/中,使用的函式與之前相同:
input_dataset_path = '../input/20_Chest_Xray/train/PNEUMONIA'
output_dataset_path = '../20_dataset/pneumo'
img_num_select = len(xray_cv_train) # 樣本數量與Covid資料相同
這樣,我們呼叫可視化支持函式,檢查得到的結果:
pneumo_images = list(paths.list_images(f"{dataset_path}/pneumo"))
covid_images = list(paths.list_images(f"{dataset_path}/covid"))
plots_from_files(covid_images, rows=10, maintitle="Covid-19 X-ray images")
plots_from_files(pneumo_images, rows=10, maintitle="Pneumony X-ray images"

影像看起來不錯,
預訓練CNN模型及其超引數的選擇
要使用的預訓練模型是VGG16,與模型1訓練相同
baseModel = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
接下來,我們必須定義用于訓練的超引數,我們與模型1的引數相同:
INIT_LR = 0.0001
EPOCHS = 20
BS = 16
NODES_DENSE0 = 128
DROPOUT = 0.5
MAXPOOL_SIZE = (2, 2)
ROTATION_DEG = 15
SPLIT = 0.2
然后,構建模型:
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=MAXPOOL_SIZE)(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(NODES_DENSE0, activation="relu")(headModel)
headModel = Dropout(DROPOUT)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
將headModel模型放在最后,成為用于訓練的真實模型,
model = Model(inputs=baseModel.input, outputs=headModel)
在基礎模型的所有層上執行的以下回圈將“凍結”它們,以便在第一個訓練程序中不會更新它們,
for layer in baseModel.layers:
layer.trainable = False
此時,模型已經準備好接受訓練,但是我們應該首先為模型準備資料(影像),
資料預處理
我們先創建一個包含存盤影像的名稱(和路徑)的串列,然后執行與模型1相同的預處理:
imagePaths = list(paths.list_images(dataset_path))
data = []
labels = []
for imagePath in imagePaths:
label = imagePath.split(os.path.sep)[-2]
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
data.append(image)
labels.append(label)
data = https://www.cnblogs.com/panchuangai/p/np.array(data) / 255.0
labels = np.array(labels)
標簽使用one-hot,
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
此時,我們將把訓練資料集分為訓練和測驗(80%用于訓練,20%用于測驗):
(trainX, testX, trainY, testY) = train_test_split(data,
labels,
test_size=SPLIT,
stratify=labels,
random_state=42)
最后,我們將應用資料增強技術,
trainAug = ImageDataGenerator(rotation_range=ROTATION_DEG, fill_mode="nearest")
我們已經定義了模型和資料,并準備好進行編譯和訓練,
模式2的編譯和訓練
編譯:
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
訓練:
H = model.fit(
trainAug.flow(trainX, trainY, batch_size=BS),
steps_per_epoch=len(trainX) // BS,
validation_data=https://www.cnblogs.com/panchuangai/p/(testX, testY),
validation_steps=len(testX) // BS,
epochs=EPOCHS)
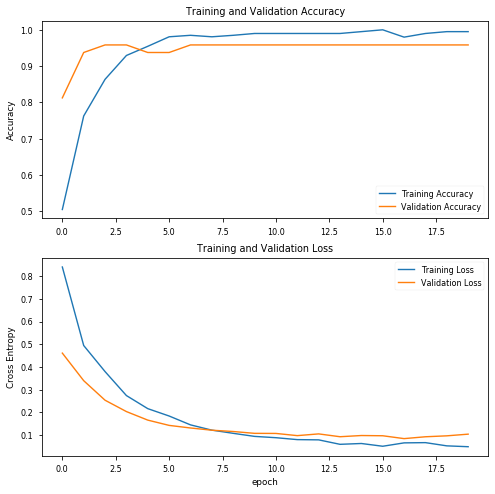
使用20個階段和初始引數,結果看起來非常有趣,驗證資料的精度達到100%!讓我們繪制精度圖表,評估訓練的模型,并查看混淆矩陣:
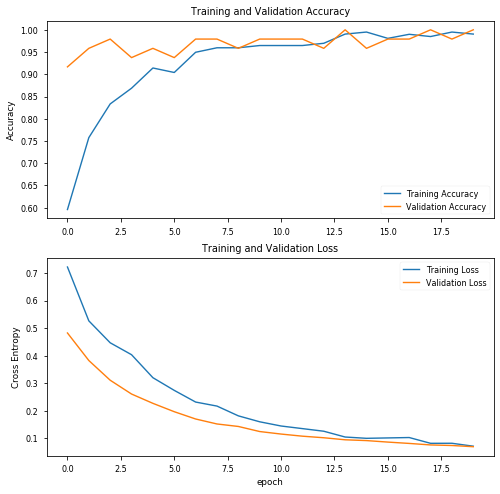
precision recall f1-score support
covid 0.96 1.00 0.98 27
pneumo 1.00 0.96 0.98 27
accuracy 0.98 54
macro avg 0.98 0.98 0.98 54
weighted avg 0.98 0.98 0.98 54
混淆矩陣
[[27 0]
[ 1 26]]
acc: 0.9815
sensitivity: 1.0000
specificity: 0.9630
通過訓練模型(初始選擇超引數),我們得到:
- 100%敏感度,也就是說,對于COVID-19陽性(即真正例)的患者,我們可以在100%的時間內準確地確定他們為“COVID-19陽性”,
- 96%特異性,也就是說,在沒有COVID-19(即真反例)的患者中,我們可以在96%的時間內準確地將其識別為“COVID-19陰性”,
結果完全令人滿意,因為只有4%的患者沒有Covid會被誤診,但與本例一樣,肺炎患者和Covid-19患者之間的正確分類是最有益處的;我們至少應該對超引數進行一些調整,再次進行訓練,
第一件事,我試圖降低最初的lr一點點,這是一場災難,所以我恢復了原值,
我還減少了資料的分割,稍微增加了Covid影像,并將最大旋轉角度更改為10度,這是在與原始資料集相關的論文中建議的:
INIT_LR = 0.0001
EPOCHS = 20
BS = 16
NODES_DENSE0 = 128
DROPOUT = 0.5
MAXPOOL_SIZE = (2, 2)
ROTATION_DEG = 10
SPLIT = 0.1
因此,我們有:
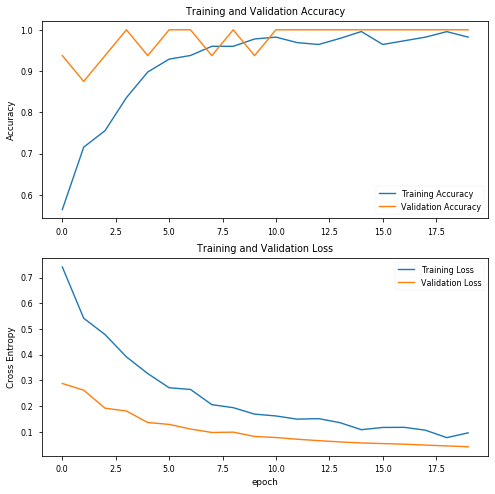
precision recall f1-score support
covid 1.00 1.00 1.00 13
pneumo 1.00 1.00 1.00 14
accuracy 1.00 27
macro avg 1.00 1.00 1.00 27
weighted avg 1.00 1.00 1.00 27
以及混淆矩陣:
[[13 0]
[ 0 14]]
acc: 1.0000
sensitivity: 1.0000
specificity: 1.0000
結果看起來更好,但我們使用了很少的測驗資料!讓我們保存模型,并像以前一樣用大量影像對其進行測驗,
model.save("../model/covid_pneumo_model.h5")
我們觀察到390張標記為非Covid-19引起的肺炎的影像,應用批測驗功能,我們發現總共390張圖片中只有3張出現假陽性(約0.8%),此外,預測精度值的平均值為0.04,并且非常集中于接近于零的值(中值僅為0.02),
總的結果甚至比以前的模型所觀察到的還要好,有趣的是,幾乎所有的結果都在前3個四分位之內,只有很少的例外值有超過20%的誤差,
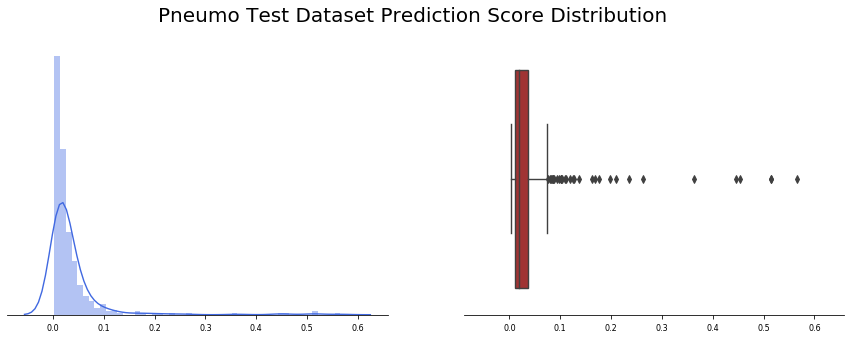
在這種情況下,還值得研究產生假陽性的影像(僅3幅),
用正常(健康)患者的影像進行測驗
由于輸入資料集也有正常患者(未經訓練)的X光影像,讓我們應用模型2(Covid/普通肺炎)看看結果如何
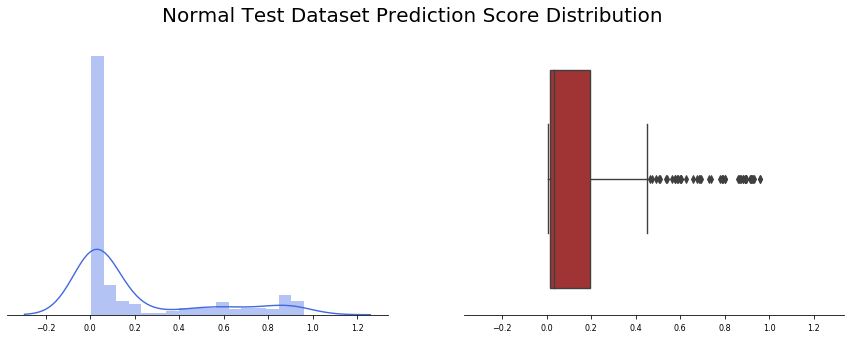
在這種情況下,結果并沒有模型1測驗中看到的那么糟糕,在234幅影像中,有45幅出現了假陽性(19%),
好吧,理想情況是對每種情況使用正確的模型,但是如果只使用一種,那么模型2是正確的選擇,
注:在最后一次測驗中,我做了一個基準測驗,我嘗試改變增強引數,正如Chowdhury等人所建議的,令我驚訝的是,結果并不好,
第4部分-Web應用程式
測驗Python獨立腳本
對于web應用的開發,我們使用Flask,這是一個用Python撰寫的web微框架,它被歸類為微框架,因為它不需要特定的工具或庫來運行,
此外,我們只需要幾個庫和與單獨測驗影像相關的函式,所以,讓我們首先在一個干凈的Notebook上作業,在那里使用已經訓練和保存的模型2執行測驗,
-
從我的GitHub加載:https://github.com/Mjrovai/covid19Xray/blob/master/10_X-Ray_Covid_development/notebooks/30_AI_Xray_Covid19_Pneumo_Detection_Application.ipynb
-
現在只匯入測驗前一個Notebook中創建的模型所需的庫,
import numpy as np
import cv2
from tensorflow.keras.models import load_model
- 然后執行加載和測驗影像的函式:
def test_rx_image_for_Covid19_2(model, imagePath):
img = cv2.imread(imagePath)
img_out = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, axis=0)
img = np.array(img) / 255.0
pred = model.predict(img)
pred_neg = round(pred[0][1]*100)
pred_pos = round(pred[0][0]*100)
if np.argmax(pred, axis=1)[0] == 1:
prediction = 'NEGATIVE'
prob = pred_neg
else:
prediction = 'POSITIVE'
prob = pred_pos
cv2.imwrite('../Image_Prediction/Image_Prediction.png', img_out)
return prediction, prob
- 下載訓練模型
covid_pneumo_model = load_model('../model/covid_pneumo_model.h5')
然后,從上傳一些影像,并確認一切正常:
imagePath = '../dataset_validation/covid_validation/6C94A287-C059-46A0-8600-AFB95F4727B7.jpeg'
test_rx_image_for_Covid19_2(covid_pneumo_model, imagePath)
結果是:(‘POSITIVE’, 96.0)
imagePath = '../dataset_validation/normal_validation/IM-0177–0001.jpeg'
test_rx_image_for_Covid19_2(covid_pneumo_model, imagePath)
結果是: (‘NEGATIVE’, 99.0)
imagePath = '../dataset_validation/non_covid_pneumonia_validation/person63_bacteria_306.jpeg'
test_rx_image_for_Covid19_2(covid_pneumo_model, imagePath)
結果是:(‘NEGATIVE’, 98.0)
到目前為止,所有的開發都是在Jupyter Notebook上完成的,我們應該做最后的測驗,讓代碼作為python腳本運行在最初創建的開發目錄中,名稱為:covidXrayApp_test.py,
# 匯入庫和設定
import numpy as np
import cv2
from tensorflow.keras.models import load_model
# 關閉資訊和警告
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def test_rx_image_for_Covid19_2(model, imagePath):
img = cv2.imread(imagePath)
img_out = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, axis=0)
img = np.array(img) / 255.0
pred = model.predict(img)
pred_neg = round(pred[0][1]*100)
pred_pos = round(pred[0][0]*100)
if np.argmax(pred, axis=1)[0] == 1:
prediction = 'NEGATIVE'
prob = pred_neg
else:
prediction = 'POSITIVE'
prob = pred_pos
cv2.imwrite('./Image_Prediction/Image_Prediction.png', img_out)
return prediction, prob
# 載入模型
covid_pneumo_model = load_model('./model/covid_pneumo_model.h5')
# ---------------------------------------------------------------
# 執行測驗
imagePath = './dataset_validation/covid_validation/6C94A287-C059-46A0-8600-AFB95F4727B7.jpeg'
prediction, prob = test_rx_image_for_Covid19_2(covid_pneumo_model, imagePath)
print (prediction, prob)
讓我們直接在終端上測驗腳本:

一切作業完美
創建在Flask中運行的環境
第一步是從一個新的Python環境開始,為此,使用Terminal定義一個作業目錄(covid19XrayWebApp),然后在那里用Python創建一個環境
mkdir covid19XrayWebApp
cd covid19XrayWebApp
conda create --name covid19xraywebapp python=3.7.6 -y
conda activate covid19xraywebapp
進入環境后,安裝Flask和運行應用程式所需的所有庫:
conda install -c anaconda flask
conda install -c anaconda requests
conda install -c anaconda numpy
conda install -c conda-forge matplotlib
conda install -c anaconda pillow
conda install -c conda-forge opencv
pip install --upgrade pip
pip install tensorflow
pip install gunicorn
創建必要的子目錄:
[here the app.py]
model [here the trained and saved model]
templates [here the .html file]
static _ [here the .css file and static images]
|_ xray_analysis [here the output image after analysis]
|_ xray_img [here the input x-ray image]
從我的GitHub復制檔案并將其存盤在新創建的目錄中
Githhub:https://github.com/Mjrovai/covid19Xray/tree/master/20_covid19XrayWebApp
執行以下步驟
-
在服務器上負責后端執行的python應用程式稱為app.py,必須位于主目錄的根目錄下
-
在/template中,應該存盤index.html檔案,該檔案將是應用程式的前端
-
在/static將是style.css檔案,負責前端(template.html)的樣式,
-
在/static下,還有接收待分析影像的子目錄,以及分析結果(其原始名稱以及診斷和準確性百分比),
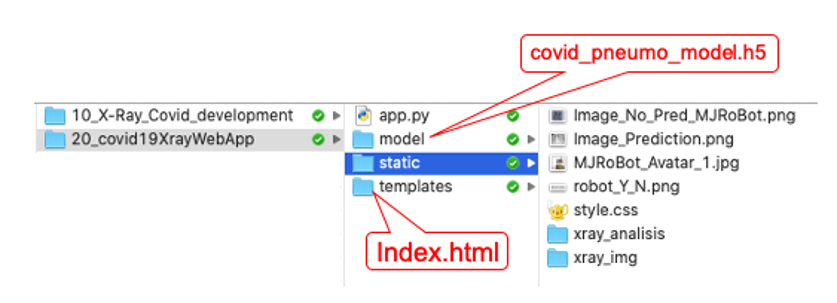
所有檔案安裝到正確的位置后,作業目錄如下所示:
在本地網路上啟動Web應用
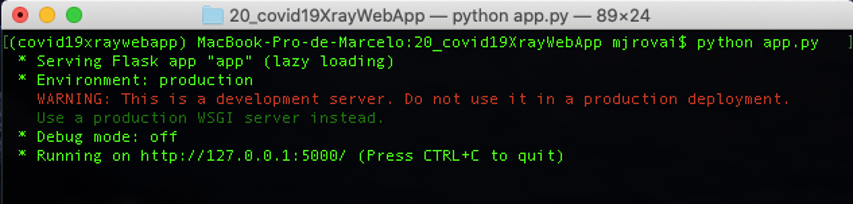
將檔案安裝到檔案夾中后,運行app.py,這是我們的web應用程式的“引擎”,負責接收存盤在用戶計算機的影像,
python app.py
在終端我們可以觀察到:
在瀏覽器上,輸入:
http://127.0.0.1:5000/
應用程式將在你的本地網路中運行:

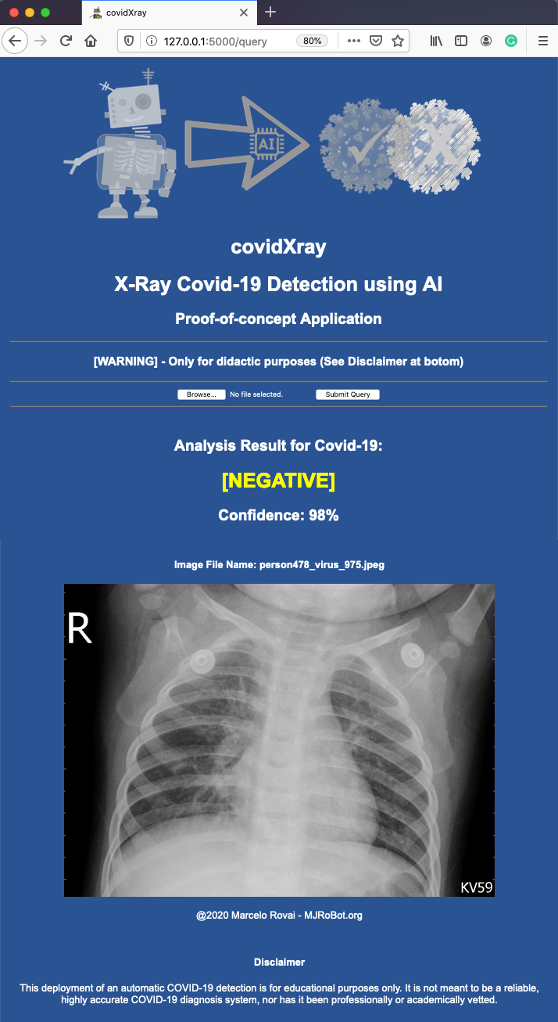
使用真實影像測驗web應用程式
我們可以選擇啟動一個Covid的X光影像,它已經在開發程序中用于驗證,
步驟順序如下:
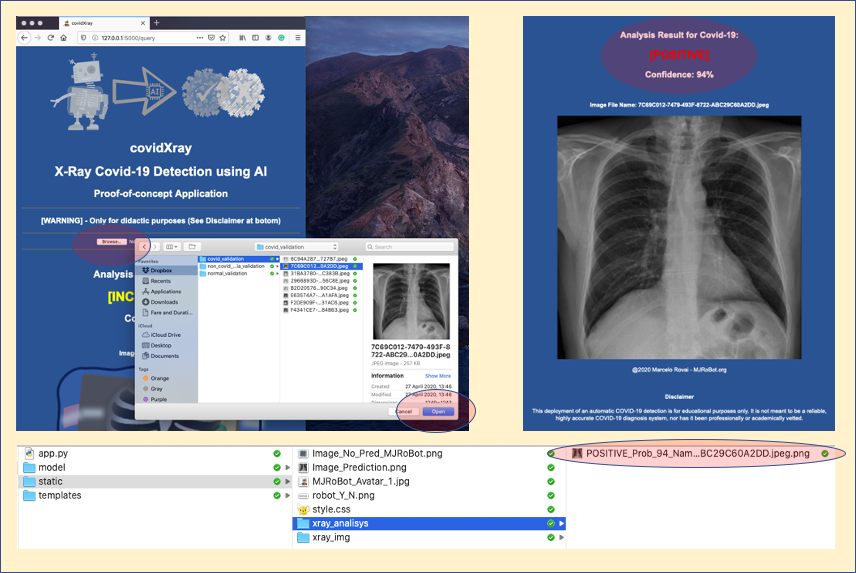
對其中一張有肺炎但沒有Covid-19的圖片重復測驗:
建議
正如導言中所討論的,本專案是一個概念證明,證明了在X光影像中檢測Covid-19的病毒的可行性,要使專案在實際情況中使用,還必須完成幾個步驟,以下是一些建議:
-
與健康領域的專業人員一起驗證整個專案
-
尋找最佳的預訓練模型
-
使用從患者身上獲得的影像訓練模型,患者最好是來自應用程式將要使用的同一區域,
-
使用Covid-19獲取更廣泛的患者影像集
-
改變模型的超引數
-
測驗用3個類標(正常、Covid和肺炎)訓練模型的可行性
-
更改應用程式,允許選擇更適合使用的模型(模型1或模型2)
本文中使用的所有代碼都可以Github倉庫下載:https://github.com/Mjrovai/covid19Xray,
原文鏈接:https://towardsdatascience.com/applying-artificial-intelligence-techniques-in-the-development-of-a-web-app-for-the-detection-of-9225f0225b4
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83534.html
標籤:其他