# -*- coding: utf-8 -*-
#
import requests
from bs4 import BeautifulSoup
res = requests.get('http://opinion.people.com.cn/GB/8213/353915/353916/index.html')
res.encoding='utf-8'
html = res.text
soup= BeautifulSoup(html,'html.parser')
items = soup.find_all(class_= 't11')
print (items)
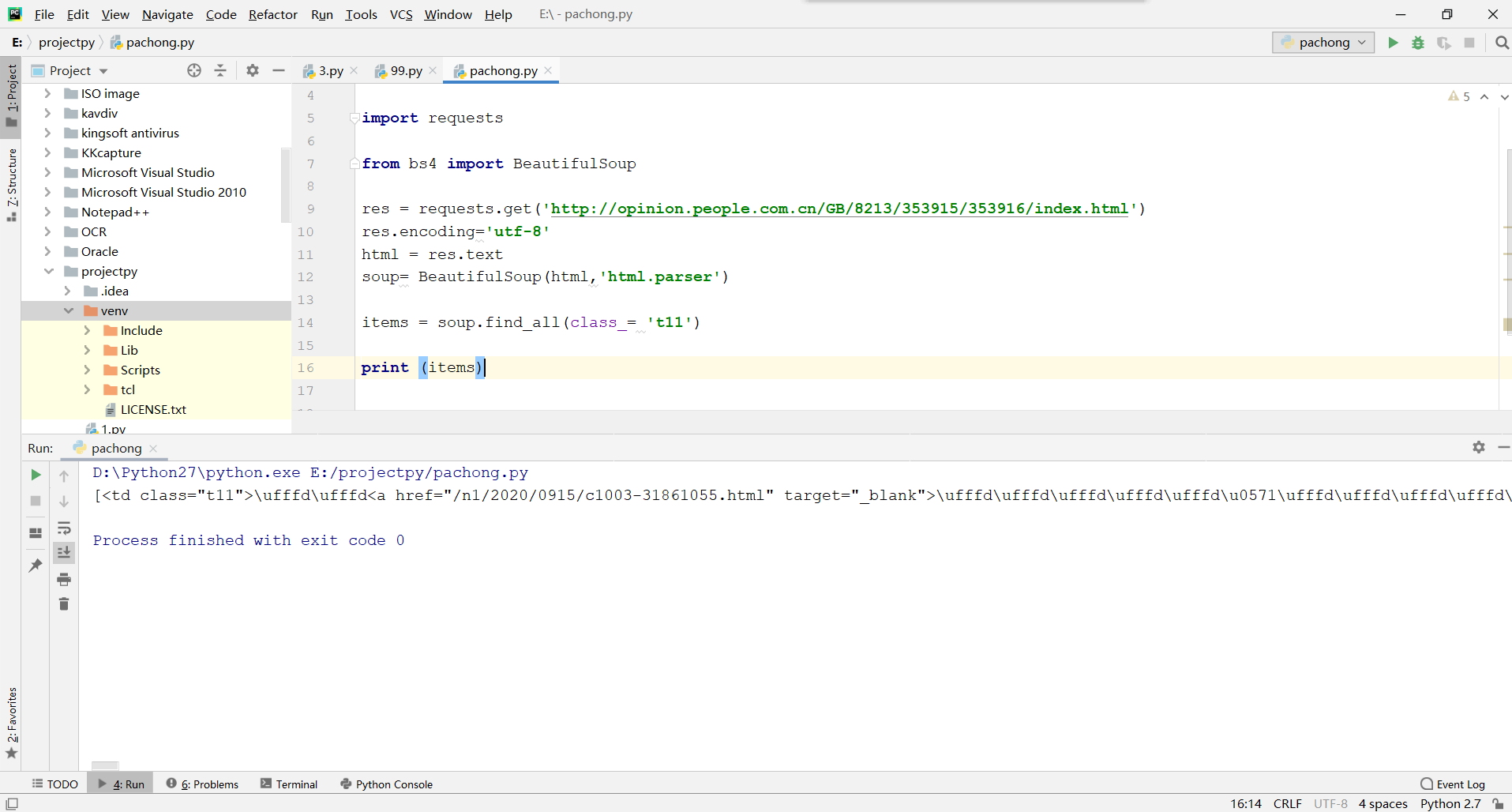
代碼如上,
初步學爬蟲,爬取人民時評的資訊,但是初步輸出來的中文都是十六進制,按照百度搜的設定好的也沒用,配置按照網上說的設定成這樣了也沒用
輸出界面都是十六進制數,請問怎么辦處理,實在想不出辦法了,代碼寫了encoding='utf-8'也沒用

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83792.html
下一篇:目標管理