Assignment 1: Distributed Naive Bayes for Data Classification
Object: Design a distributed version of Naive Bayes with MapReduce on Hadoop, and apply the designed algorithm for data classification. Your final report should include the following content:
1. The detailed algorithm for distributed Naive Bayes.
2. The source code for the core algorithm.
3. Experimental results: (1) your experimental environments, such as the CPU and Memory of your machines; (2) classification; (3) the computation time; (4) the classification accuracy; (5) other findings.
Schedule:
1. Implement the Distributed Naive Bayes on the fully distributed pattern. (December. 2nd 2015)
Dataset 1: http://archive.ics.uci.edu/ml/datasets.html (Accuracy)
Dataset 2: There are 2 pairs of dataset (Speed).
(1) UCI dataset.
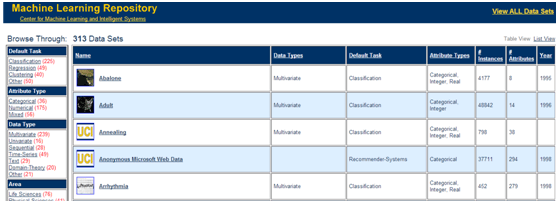
(2) The file “1.txt” as training data set, and the file “2.txt” as the data set to be classified.
The “1.txt” contains 5,000,000 training samples. It contains 102 columns. The first column is ID, the 2nd to the 101th column is the attributes, and the last column is the classification. The “2.txt” contains 500,000 samples to be classified. It contains 101columns, which is the same structure to the “1.txt” file’s first 101columns.

1.txt and 2.txt download from there http://pan.baidu.com/s/1bqYZG
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/84579.html
標籤:云存儲
上一篇:Spark Thriftserver執行SQL查詢結果字串欄位顯示例外問題
下一篇:我同時像 一臺服務器, 發送50個請求,但是總有2到3個很慢。并發100個也是一樣, 總有2到3個很慢, 是什么原因呢?