作者|DR. VAIBHAV KUMAR
編譯|VK
來源|Analytics In Diamag
PyTorch通過提供大量強大的工具和技術,一直在推動計算機視覺和深度學習領域的發展,
在計算機視覺領域,基于深度學習的執行需要處理大量的影像資料集,因此需要一個加速的環境來加快執行程序以達到可接受的精度水平,
PyTorch通過XLA(加速線性代數)提供了這一特性,XLA是一種線性代數編譯器,可以針對多種型別的硬體,包括GPU和TPU,PyTorch/XLA環境與Google云TPU集成,實作了更快的執行速度,

在本文中,我們將在PyTorch中使用TPU演示一種深卷積神經網路ResNet50的實作,
該模型將在PyTorch/XLA環境中進行訓練和測驗,以完成CIFAR10資料集的分類任務,我們還將檢查在50個epoch訓練所花費的時間,
ResNet50在Pytorch的實作
為了利用TPU的功能,這個實作是在Google Colab中完成的,首先,我們需要從Notebook設定下的硬體加速器中選擇TPU,
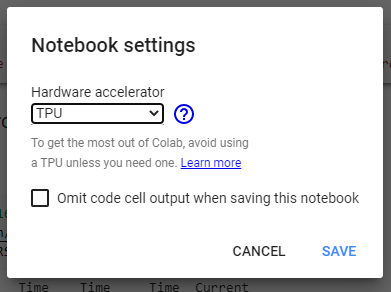
選擇TPU后,我們將使用下面的行驗證環境代碼:
import os
assert os.environ['COLAB_TPU_ADDR']
如果啟用了TPU,它將成功執行,否則它將拋出‘KeyError: ‘COLAB_TPU_ADDR’’,你也可以通過列印TPU地址來檢查TPU,
TPU_Path = 'grpc://'+os.environ['COLAB_TPU_ADDR']
print('TPU Address:', TPU_Path)
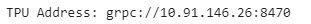
在下一步中,我們將安裝XLA環境以加快執行程序,我們在上一篇文章中實作了卷積神經網路,
VERSION = "20200516"
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSION
現在,我們將在這里匯入所有必需的庫,
from matplotlib import pyplot as plt
import numpy as np
import os
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch_xla
import torch_xla.core.xla_model as xm
import torch_xla.debug.metrics as met
import torch_xla.distributed.parallel_loader as pl
import torch_xla.distributed.xla_multiprocessing as xmp
import torch_xla.utils.utils as xu
import torchvision
from torchvision import datasets, transforms
import time
from google.colab.patches import cv2_imshow
import cv2
匯入庫之后,我們將定義并初始化所需的引數,
# 定義引數
FLAGS = {}
FLAGS['data_dir'] = "/tmp/cifar"
FLAGS['batch_size'] = 128
FLAGS['num_workers'] = 4
FLAGS['learning_rate'] = 0.02
FLAGS['momentum'] = 0.9
FLAGS['num_epochs'] = 50
FLAGS['num_cores'] = 8
FLAGS['log_steps'] = 20
FLAGS['metrics_debug'] = False
在下一步中,我們將定義ResNet50模型,
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_planes,
self.expansion * planes,
kernel_size=1,
stride=stride,
bias=False), nn.BatchNorm2d(self.expansion * planes))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(
3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = torch.flatten(out, 1)
out = self.linear(out)
return F.log_softmax(out, dim=1)
def ResNet50():
return ResNet(BasicBlock, [3, 4, 6, 4, 3])
下面的代碼片段將定義加載CIFAR10資料集、準備訓練和測驗資料集、訓練程序和測驗程序的函式,
SERIAL_EXEC = xmp.MpSerialExecutor()
# 只在記憶體中實體化一次模型權重,
WRAPPED_MODEL = xmp.MpModelWrapper(ResNet50())
def train_resnet50():
torch.manual_seed(1)
def get_dataset():
norm = transforms.Normalize(
mean=(0.4914, 0.4822, 0.4465), std=(0.2023, 0.1994, 0.2010))
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
norm,
])
transform_test = transforms.Compose([
transforms.ToTensor(),
norm,
])
train_dataset = datasets.CIFAR10(
root=FLAGS['data_dir'],
train=True,
download=True,
transform=transform_train)
test_dataset = datasets.CIFAR10(
root=FLAGS['data_dir'],
train=False,
download=True,
transform=transform_test)
return train_dataset, test_dataset
# 使用串行執行器可以避免多個行程
# 下載相同的資料,
train_dataset, test_dataset = SERIAL_EXEC.run(get_dataset)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=xm.xrt_world_size(),
rank=xm.get_ordinal(),
shuffle=True)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=FLAGS['batch_size'],
sampler=train_sampler,
num_workers=FLAGS['num_workers'],
drop_last=True)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=FLAGS['batch_size'],
shuffle=False,
num_workers=FLAGS['num_workers'],
drop_last=True)
# 將學習率縮放
learning_rate = FLAGS['learning_rate'] * xm.xrt_world_size()
# 獲取損失函式、優化器和模型
device = xm.xla_device()
model = WRAPPED_MODEL.to(device)
optimizer = optim.SGD(model.parameters(), lr=learning_rate,
momentum=FLAGS['momentum'], weight_decay=5e-4)
loss_fn = nn.NLLLoss()
def train_loop_fn(loader):
tracker = xm.RateTracker()
model.train()
for x, (data, target) in enumerate(loader):
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
tracker.add(FLAGS['batch_size'])
if x % FLAGS['log_steps'] == 0:
print('[xla:{}]({}) Loss={:.2f} Time={}'.format(xm.get_ordinal(), x, loss.item(), time.asctime()), flush=True)
def test_loop_fn(loader):
total_samples = 0
correct = 0
model.eval()
data, pred, target = None, None, None
for data, target in loader:
output = model(data)
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
total_samples += data.size()[0]
accuracy = 100.0 * correct / total_samples
print('[xla:{}] Accuracy={:.2f}%'.format(
xm.get_ordinal(), accuracy), flush=True)
return accuracy, data, pred, target
# 訓練和評估的回圈
accuracy = 0.0
data, pred, target = None, None, None
for epoch in range(1, FLAGS['num_epochs'] + 1):
para_loader = pl.ParallelLoader(train_loader, [device])
train_loop_fn(para_loader.per_device_loader(device))
xm.master_print("Finished training epoch {}".format(epoch))
para_loader = pl.ParallelLoader(test_loader, [device])
accuracy, data, pred, target = test_loop_fn(para_loader.per_device_loader(device))
if FLAGS['metrics_debug']:
xm.master_print(met.metrics_report(), flush=True)
return accuracy, data, pred, target
現在,我們將開始ResNet50的訓練,訓練將在我們在引數中定義的50個epoch內完成,訓練開始前,我們會記錄訓練時間,訓練結束后,我們將列印總時間,
start_time = time.time()
# 啟動訓練流程
def training(rank, flags):
global FLAGS
FLAGS = flags
torch.set_default_tensor_type('torch.FloatTensor')
accuracy, data, pred, target = train_resnet50()
if rank == 0:
# 檢索TPU核心0上的張量并繪制,
plot_results(data.cpu(), pred.cpu(), target.cpu())
xmp.spawn(training, args=(FLAGS,), nprocs=FLAGS['num_cores'],
start_method='fork')
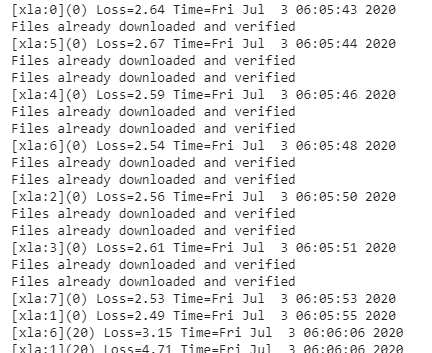
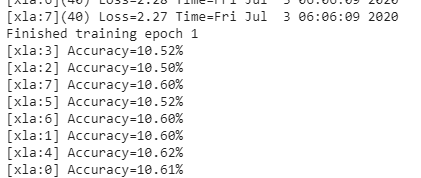
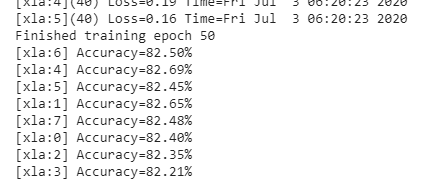
訓練結束后,我們會列印訓練程序所花費的時間,
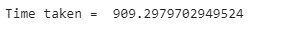
最后,在訓練程序中,我們將模型對樣本測驗資料的預測可視化,
end_time = time.time()
print("Time taken = ", end_time-start_time)

原文鏈接:https://analyticsindiamag.com/hands-on-guide-to-implement-resnet50-in-pytorch-with-tpu/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/85189.html
標籤:其他
上一篇:卷積神經網路 part1